連休中のSLOを決めてみた


はじめに
Iさんと一緒にSREチームとして活動しているMです。初めまして。
2022年の年末年始、みんせつSREチームが初めて迎える連休でした。
これまでみんせつ連休中のシステム対応は、人力駆動で障害を検知しトリアージする運用となっていました。そのため対応基準が明確でないという問題があり、手始めとして年末年始期間のSLOを定めてみてはどうか?という提案を上司のT郎さんからいただきました。
今回はSLOって何?というところから、Iさんと私の2人で手探りでSLOを定めた過程と、連休を終えて実際そのSLOはどうだったか?を振り返っていきたいと思います。
SLOとは?
サービスレベル目標ことSLOとは、サービスレベルに関する目標基準を定めたものになります。
うーんわかるようで、わからない・・この説明では設定する目標の具体的なイメージが沸かなかったため、各社のSLOを眺めてみることにしました。
その結果、”このサービスの可用性はこれくらいです”といった、サービスの信頼性を数値的に表した目標のことなのだなと私たちは解釈しました。
連休中のSLOを考えてみる
まず初めに考えたのは、連休中にサービスとして満たしておきたい基準はどんなことか?です。この基準をもとに、稼働して対応する・しないを決められるようにしたいなと。
休みの期間ということを踏まえ、サービスとして最低限のラインをは何かを考えたところ「サイトにアクセスした時にサービスが落ちていないこと」つまり動いていることが、最低条件になるんじゃないかと考えました。
そこでまず最初に私たちが定義したのは、「ログインページにアクセスした際に正常系のレスポンスを100%の確率で返すこと」です。
この目標設定を上司のT郎さんに見せたところ、以下のような点でアドバイスをいただきました。
- DBへの接続が担保できない(接続できなくても正常系のレスポンスが返ってくる)
- 正常系100%は高すぎる(優れた SLO を策定するには : CRE が現場で学んだこと なども参照)
特に後者に関しては、可用性100%ということは、つまり障害の発生率を0%にすることになります。絶対に落ちないシステムはないので、100%の可用性担保は現実的ではありませんでした。
このフィードバックを元に、「ログイン後の特定ページにアクセスした際のリクエスト成功率XX%」に修正しました。ログインできるということはつまりDBと正常に通信していることが確認できるということです。
そして次に、数値を設定します。私たちは以下の条件を元に算出してみました。
- 正常に稼働するべき時間帯を通常の営業時間帯(9時~18時までの9時間)とする
- 連休日数はトータル6日
- 障害発生時に見込まれる復旧までの時間は30分
- 直前に起きたRDS通信のインシデント対応時間を参考に算出
- 発生確率は1回あるか無いか
以上から、99%と設定しました。
まとめると「ログイン後の特定ページにアクセスした際のリクエスト成功率99%」が、私たちの定めたSLOになりました。
ヘルスチェックおよび障害発生検知はNew Relicにお任せ
次に、設定したSLOに基づき、New Relicを利用してリクエストのレスポンスを計測し、特定のレスポンス時にアラートがSlackに飛ぶように設定してみました。
Synthetic monitoringでレスポンスを監視
ターゲットのURLに対し、一定の間隔でリクエストを送り、そのレスポンスを監視するモニターを設定します。

Alert conditions(Policies)でアラートを設定
Alert conditionsでSynthetic monitoringのレスポンスに応じたアラート条件を設定します。
NRQL Queryには、以下の構文を設定しました。
SELECT count(*) AS 'Error responses(not in 2xx)' FROM SyntheticRequest WHERE monitorId = 'xxx' AND responseCode > 299 FACET responseCode
これは、レスポンスのステータスが200番台でなければアラートするためのクエリです。
(※このページは、200番台までが正常な処理ができている際のステータスになるという事情があります)
次にcondition thresholdsの設定です。ここでアラートの各閾値を決めます。

上記の場合、5分に1回以上指定のクエリを検出した場合にアラートする設定になります。
Signal is lost afterでは、指定のクエリが検知されなくなった場合、どのくらいの時間でインシデントが終了したと判断(recovery period)し、Issueを自動でクローズするかを設定できます。
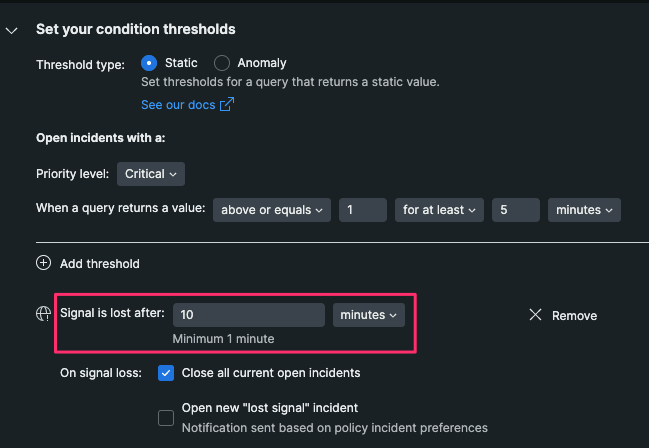
私たちはデフォルトに従い、10分の回復期間を持ってクローズするようにしました。
workflowからSlackにアラートを飛ばす設定を追加
普段利用しているSlackでアラートを検知できるよう、workflowにて設定を追加します。
Policyの項目には、先ほど作成したAlert conditionを選択します。
Test workflowでSlackにテスト通知ができます。こんな感じ↓で通知が届きます。

またIssueが自動でcloseした際にも、通知がきます。

これで障害を自動検出するための設定は完了となります。
私たちは通知が意図通りのタイミングで必ずくることを確認するため、demo環境を利用してエラーを引き起こし、動作確認を行いました。
SLOを共有し合意をとる
休業期間中、障害対応に当たる可能性のある他のエンジニアメンバーに今回のSLOの説明をしました。対応に当たる全メンバーが責任を追うことになるので、合意をとります。
(本来であれば、全社的な共有と合意を得るべきでしたが、時間の都合上エンジニア内だけでの共有となってしまいました)
伝えたことを簡単にまとめると以下です。
- 休業期間中にシステムとして担保するのは、通常の営業時間中にサイトへアクセスできることと、DBへ通信できること
- この指標を前提に、可用性を99%として定めた
- 障害が起きてシステムが停止した際、30分で対応すれば可用性は99%になる
- 障害はアラートによってSlackに通知される。対応完了条件は、Issueが自動closeしたのを確認すること
この内容で合意を得ることができたので、連休に入りました。
連休を終えて
連休中にアラート通知が来ることはありませんでした。その代わり社内からの連絡があり、アラートとは別の対応にあたったメンバーもいました。
この結果を踏まえて、振り返りの内容は以下でした。
- システム的な観点は持てていたが、今回の設定では1種類のuser roleからのアクセスでしか検証できていなかった。ヘルスチェックではなく、ログを活用してSLIを計測する方法もあった
- ビジネス的な観点が足りなかった(その結果別対応があった)ので、次の課題にする
- 社内にもユーザーがいたため、社外向けシステムと社内向けシステムの観点を分ける必要があった。社内に関してはルールなど設けて共通認識を持つことが大事そう
まとめ
SLOにより明文化された一定の行動基準ができたのは良かったと思います。障害とは何かを定義することで、その自動検出も容易になることがわかりました。
しかし何もないところに新しい基準を定義をするのはなかなか難しかったです。各社どのようにSLOやSLAを取り決めているのか気になりました。
今回は年末年始のみの対応でしたが、この経験をもとに、より良いSLOを定義していけたらと思います。
Discussion