人もAIエージェントもオンボーディングは大事だと思った話
はじめに
最近、私はAgent Development Kit(ADK)を用いたAIエージェントの開発にハマっています。
この記事では、ADKを用いてBigQueryデータ分析AIエージェントを開発し、その中で感じた「人もAIエージェントもオンボーディングは大事だと思った話」を紹介します。
ADK
こちらの資料がわかりやすかったです。
ADKを用いたBigQueryデータ分析AIエージェント
ADKのBuilt-in tools
ADKはGoogleが開発したこともあり、Google Cloud上のサービスと簡単に連携が可能なBuilt-in toolsが用意されています。
Built-in toolsとして連携可能なGoogle Cloud上のサービスの例として、Vertex AI SearchやBigQueryなどがあります。
今回は、BigQueryのBuilt-in toolsを使用します。
Built-in tools以外だと、データベース向けMCPツールボックスがあり、BigQueryと接続が可能なようです。
データベース向けMCPツールボックスの場合、MySQLなどの他のデータベースが可能なので、BigQuery以外だと選択肢に入ってくると考えます。
ローカルでBigQueryデータ分析AIエージェントを動かしてみる
全体
構築方法は公式のQuickstartが参考になります。
uvなど、ご自身のパッケージ管理方法で構築を実施してください。
エージェントの部分
BigQueryデータ分析AIエージェントの場合、agent.pyの内容を以下のように変更します。
先述したように、Toolsは、ADKのBuilt-in toolsを使用します。
import google.auth
from google.adk.agents import Agent
from google.adk.tools.bigquery import BigQueryCredentialsConfig, BigQueryToolset
from google.adk.tools.bigquery.config import BigQueryToolConfig, WriteMode
# Define constants for this example agent
AGENT_NAME = "bigquery_agent"
GEMINI_MODEL = "gemini-2.0-flash"
# Define a tool configuration to block any write operations
tool_config = BigQueryToolConfig(write_mode=WriteMode.BLOCKED)
# Define a credentials config - in this example we are using application default
# credentials
# https://cloud.google.com/docs/authentication/provide-credentials-adc
application_default_credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(
credentials=application_default_credentials
)
# Instantiate a BigQuery toolset
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config, bigquery_tool_config=tool_config
)
# Agent Definition
root_agent = Agent(
model=GEMINI_MODEL,
name=AGENT_NAME,
description=(
"Agent to answer questions about BigQuery data and models and execute"
" SQL queries."
),
instruction="""\
You are a data science agent with access to several BigQuery tools.
Make use of those tools to answer the user's questions.
""",
tools=[bigquery_toolset],
)
動作確認
-
gcloud auth application-default loginコマンドでプログラムがGoogle Cloudに認証が通るように設定
※ 別のコマンドとしてgcloud auth loginもあります。2つのコマンド違いは以下の記事が参考になります。
※ gcloud auth application-default loginで取得する認証情報は、ローカル環境で管理されているユーザーアカウントに紐づく権限になるので、権限不足にはご注意ください。(今回は検証のため、Google Cloudプロジェクトに対しオーナー権限がついている前提で進めます)
-
adk webコマンドでADK製のチャットUIを起動
以下のようなチャットUIが起動します。

- データ分析AIエージェントと対話
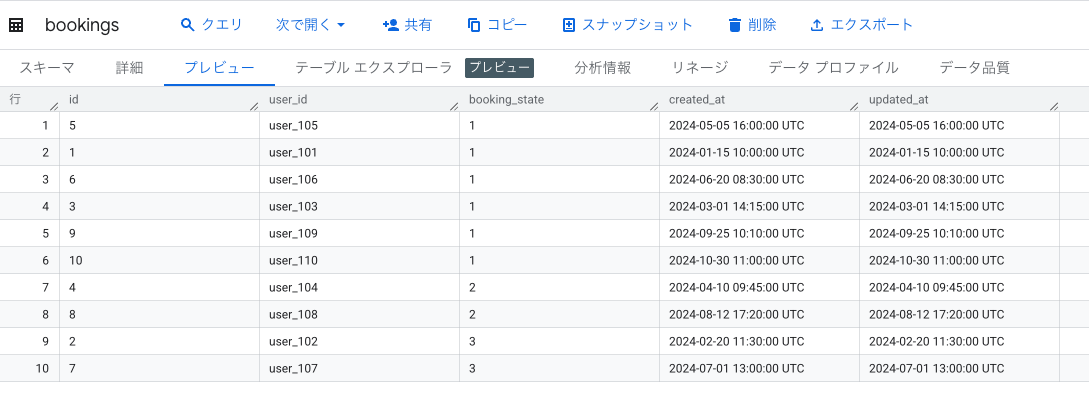
検証用で以下のデータセットとテーブルを作成しています。
- データセット: poc_dataset
- テーブル: bookings(予約管理テーブル)
- id
- user_id
- booking_state(1=予約完了, 2=事前キャンセル, 3=無断キャンセル)
- created_at
- updated_at
- テストデータ数: 10件

以下のように、ある程度テーブルの情報をプロンプトとして与えてあげると、正しく回答が1回で返ってきます。
以下のテーブルのレコード数を教えてください
プロジェクト: YOUR_PJ_ID
データセット: poc_dataset
テーブル: bookings

人もAIエージェントもオンボーディングは大事
データ分析AIエージェントのユースケース
データ分析AIエージェントは、自然言語でデータ分析が可能なため、非エンジニアに多く利用されることが想定されます。
先述した動作確認では、ある程度データセットやテーブルの構造を知っていることが前提となります。
つまり、非エンジニアにとっては使い物にならない可能性があります。
例えば、以下の使い方だと、データ分析はできませんでした。
データ分析AIエージェントが思考し、bookingsというテーブル名から予約情報が管理されているか特定はしてくれますが、booking_stateカラムの予約状態の1=予約完了, 2=事前キャンセル, 3=無断キャンセルという事実を知らないので、困ってしまっています。
「プロジェクト: YOUR_PJ_ID」というGoogle CloudのPJから、予約を事前キャンセルしたデータのレコード数を教えてください。
進める過程で該当データが格納されているデータセット、テーブルを調査しながら進めてください。
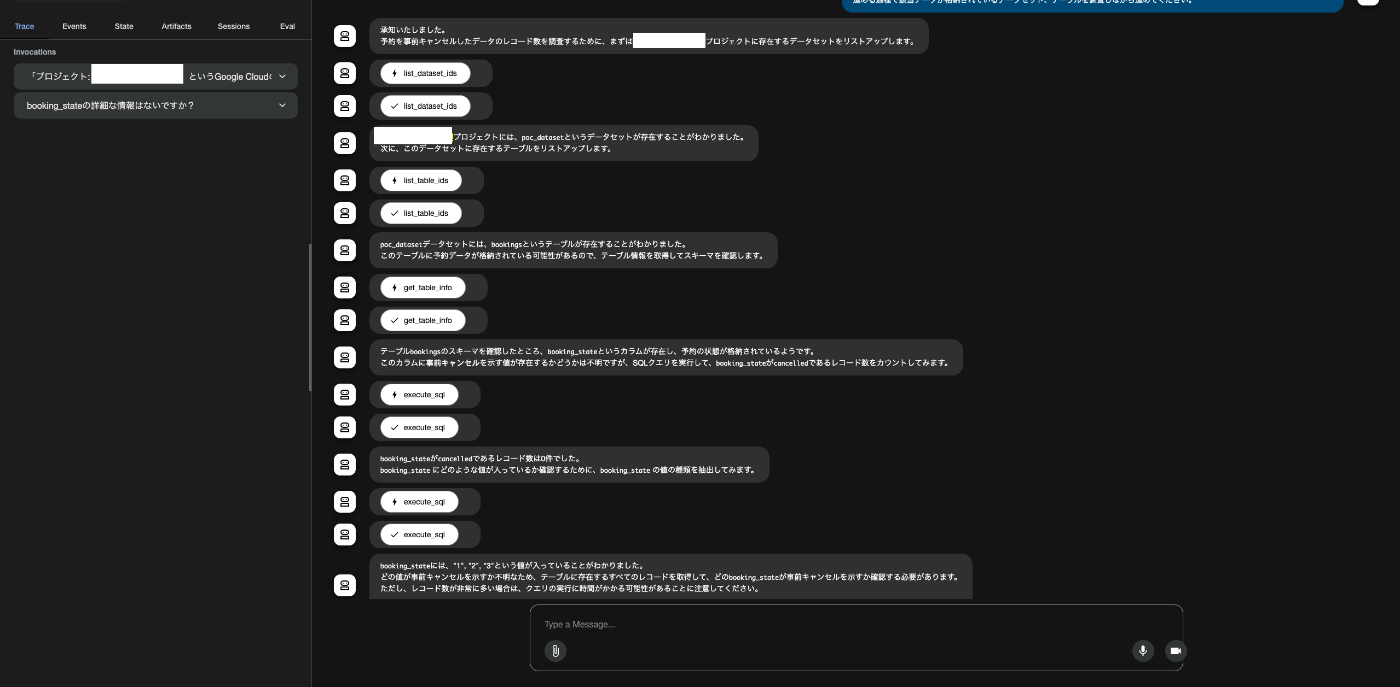
実際のプロジェクトでは、予約状態のようなドメイン知識はドキュメントで管理されていたりするケースも多いと考えます。
データ分析AIエージェントが知り得ない情報がある状態では、導入に期待していたとしても、その能力を高いレベルで活用することはできないのではないでしょうか。
オンボーディング
データ分析AIエージェントが知り得ない情報がある状態では、導入に期待していたとしても、その能力を高いレベルで活用することはできない
このような状態は、人も同じだと考えます。
新規プロジェクトに配属されたはいいものの、オンボーディング体制整っておらず、各種理解に時間がかかり、プロジェクトから期待されていたスキルを発揮できないという状態です。

人のオンボーディングの場合、ドキュメント一覧やチェックリストがあると、何をすべきかが明確なので、進めやすいと考えます。
では、データ分析AIエージェントにおけるオンボーディングとは何が該当するでしょうか。
データ分析AIエージェントにおけるオンボーディング
データ分析AIエージェントが知り得ない情報がある場合に、期待していた能力を発揮できなくなるとするのであれば、知り得ない情報がないようにしてあげることが大事です。
具体的な話をすると、booking_stateカラムの予約状態は1=予約完了, 2=事前キャンセル, 3=無断キャンセルで管理しているという補足情報を付与してあげれば良いと考えます。
BigQueryの場合、補足情報はメタデータとして、以下のように追加できます。

メタデータを付与した後に、先ほどと同じクエリをもう一度実行してみます。
先ほどとは結果が変わり、メタデータを付与すると、正しい結果が得られるようになりました。

ADKのメニューから実行ログを確認しても、正しいSQLが実行されていることがわかります。

メタデータを付与することで、非エンジニアが具体的なデータセットやテーブル構成を知らずとも、データ分析がある程度可能になると考えられます。(=データ分析AIエージェントへのオンボーディング)
また、BigQueryのメタデータを自動生成する仕組みも出てきているようなので、データ分析AIエージェントへのオンボーディングも容易になっていくことが想定されます。
おわりに
データ分析AIエージェントに限らず、AIエージェントがその能力を最大限に発揮し、人間からの期待に応えるためには、AIエージェントに対する「オンボーディング体制」を整えることが重要だと改めて感じました。
今回のBigQueryの事例では、メタデータの付与が効果的なオンボーディングとなりました。これにより、エージェントはドメイン固有の知識を習得し、より正確な分析が可能になりました。
AIエージェントの導入を検討する際は、彼らが「新人」として現場で活躍できるよう、適切な情報や学習機会を提供することを意識することで真価を発揮してもらえるのではないでしょうか。
Discussion