[Rust] 静的ディスパッチ(Enum)と動的ディスパッチ(dyn Trait)はどちらが速いのか?
ある時、 Rust で動的ポリモーフィズムを実現するには、 Enum は dyn Trait より遅いという主張を見ました。 dyn Trait は仮想関数テーブルのルックアップがある分、遅いはずだと思っていたので、これは確かめてみようと思いました。
[2024/5/24追記]:
少し後で考えると、ここで静的ディスパッチという言葉を使うのは語弊があるような気がしたので補足します。静的ディスパッチとは、 dyn Trait に対する impl Trait のことを呼ぶことが多く、ここで Enum で実現しているのは「一つのコンテナに異なる型や挙動を示すオブジェクトを含める」という意味では動的ディスパッチです。正確に言うならば、この記事で示しているのは、同じ動的ディスパッチでも、 Enum を使った場合分けか、 dyn Trait を使った仮想関数テーブルを使ったポリモーフィズムかという違いです。
ただし、このようなマイクロベンチマークは話半分ぐらいに思っておいた方が良いです。実際のコードではオプティマイザがかなり仕事をするので、本当にスピードが問題になる局面では実際のコードでプロファイルを取った方が良いです。
この記事では rustc -O を使って最適化を適用しています。
Enum の実装
実用的には(平均的には) 5 種類ぐらいの型にポリモーフィズムを適用することが多いと思いますので、 5 つのバリアントを持つ Enum を使います。オプティマイザが計算を取り除いてしまうことを避けるため、 counts というアキュムレータに結果を加算していくようにしました。 10 億回のループの合計を取っています。
#[derive(Clone, Copy, Debug)]
enum E {A, B, C, D, E}
pub fn calc() -> [i32; 5] {
let aa = [E::A, E::B, E::C, E::D, E::E];
let mut counts = [0; 5];
for i in 0..1000000000 {
let a = aa[i % aa.len()];
let n = match a {
E::A => 0,
E::B => 1,
E::C => 2,
E::D => 3,
E::E => 4,
};
counts[i % aa.len()] += n;
}
counts
}
pub fn main() {
let counts = calc();
println!("aa: {counts:?}");
}
アセンブラの結果は次のようになります。長いので折りたたんでいます。
最適化がかなりコードを変形させているのでかなり見づらいですが、メインループ (.LBB3_1 から jne .LBB3_1 の間) では関数呼び出しが存在せず、スタックフレーム内で計算が完結していることが分かります。
アセンブラコード
example::calc::hc2870328f6203ca1:
push r15
push r14
push r13
push r12
push rbx
mov dword ptr [rsp - 37], 50462976
lea r8, [rsp - 36]
mov byte ptr [rsp - 33], 4
xorps xmm0, xmm0
movaps xmmword ptr [rsp - 32], xmm0
mov dword ptr [rsp - 16], 0
lea r9, [rsp - 28]
mov ecx, 1
mov r10d, 1000000000
lea r11, [rsp - 37]
lea rbx, [rsp - 32]
xor esi, esi
movabs r14, -3689348814741910323
.LBB3_1:
mov rax, rcx
mul r14
mov rax, rdx
shr rax, 2
and rdx, -4
lea rdx, [rdx + 4*rdx]
mov r15, r9
sub r15, rdx
lea r12, [rax + 4*rax]
neg r12
mov rax, rsi
mul r14
mov rax, rdx
shr rax, 2
lea rax, [rax + 4*rax]
neg rax
and rdx, -4
lea rdx, [rdx + 4*rdx]
mov r13, rbx
sub r13, rdx
movzx eax, byte ptr [r11 + rax]
add dword ptr [r13], eax
movzx eax, byte ptr [r8 + r12]
add dword ptr [r15], eax
add rsi, 2
add r9, 8
add rcx, 2
add r8, 2
add r11, 2
add rbx, 8
add r10, -2
jne .LBB3_1
mov eax, dword ptr [rsp - 16]
mov dword ptr [rdi + 16], eax
movaps xmm0, xmmword ptr [rsp - 32]
movups xmmword ptr [rdi], xmm0
mov rax, rdi
pop rbx
pop r12
pop r13
pop r14
pop r15
ret
実行結果は私の環境では次のようになりました。
aa: [0, 200000000, 400000000, 600000000, 800000000]
real 0m1.069s
user 0m1.069s
sys 0m0.000s
dyn Trait の実装
dyn Trait の場合は、それぞれの型について実装しなければならないのでコードの量がかなり増えます。ここでは繰り返しを減らすため宣言的マクロを使っています。
trait T {
fn get(&self) -> i32;
}
macro_rules! def_t {
{$name:ident, $value:literal} => {
struct $name;
impl T for $name {
fn get(&self) -> i32 {
$value
}
}
}
}
def_t!(A, 0);
def_t!(B, 1);
def_t!(C, 2);
def_t!(D, 3);
def_t!(E, 4);
pub fn calc() -> [i32; 5] {
let a = A;
let b = B;
let c = C;
let d = D;
let e = E;
let aa: [&dyn T; 5] = [&a, &b, &c, &d, &e];
let mut counts = [0; 5];
for i in 0..1000000000 {
let a = aa[i % aa.len()];
let n = a.get();
counts[i % aa.len()] += n;
}
counts
}
fn main() {
let counts = calc();
println!("aa: {counts:?}");
}
アセンブラを見ると、 .LBB1_1: と jne .LBB1_1 の間に call qword ptr [rax + 24] があります。これはメモリ上のアドレスを使って関数呼び出しを行う動的ディスパッチだと考えられます。
アセンブラコード
example::calc::hc2870328f6203ca1:
push rbp
push r15
push r14
push r13
push r12
push rbx
sub rsp, 136
mov qword ptr [rsp + 48], rdi
lea rax, [rsp + 15]
mov qword ptr [rsp + 56], rax
lea r15, [rsp + 64]
lea rcx, [rip + .L__unnamed_1]
mov qword ptr [rsp + 64], rcx
mov qword ptr [rsp + 72], rax
lea rcx, [rip + .L__unnamed_2]
mov qword ptr [rsp + 80], rcx
mov qword ptr [rsp + 88], rax
lea rcx, [rip + .L__unnamed_3]
mov qword ptr [rsp + 96], rcx
mov qword ptr [rsp + 104], rax
mov qword ptr [rsp + 112], rcx
mov qword ptr [rsp + 120], rax
mov qword ptr [rsp + 128], rcx
xorps xmm0, xmm0
movaps xmmword ptr [rsp + 16], xmm0
mov dword ptr [rsp + 32], 0
mov r12d, 1000000000
lea r13, [rsp + 56]
lea rbx, [rsp + 16]
xor r14d, r14d
.LBB1_1:
mov rax, r14
movabs rcx, -3689348814741910323
mul rcx
lea rax, [4*rdx]
and rax, -16
lea rax, [rax + 4*rax]
mov rcx, r15
sub rcx, rax
inc r14
mov rsi, r13
sub rsi, rax
and rdx, -4
lea rax, [rdx + 4*rdx]
mov rbp, rbx
sub rbp, rax
mov rdi, qword ptr [rsi]
mov rax, qword ptr [rcx]
call qword ptr [rax + 24]
add dword ptr [rbp], eax
add r15, 16
add r13, 16
add rbx, 4
dec r12
jne .LBB1_1
mov ecx, dword ptr [rsp + 32]
mov rax, qword ptr [rsp + 48]
mov dword ptr [rax + 16], ecx
movaps xmm0, xmmword ptr [rsp + 16]
movups xmmword ptr [rax], xmm0
add rsp, 136
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
ret
出力は次のようになりました。
aa: [0, 200000000, 400000000, 600000000, 800000000]
real 0m1.983s
user 0m1.982s
sys 0m0.000s
結果
統計的誤差を回避するため、5回ごと実行して平均値と標準偏差を取りました。誤差は1%程度で Enum の方が約2倍速いという結果が出ました。
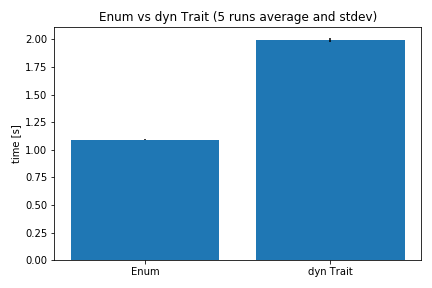
この傾向は予想通りではありますが、どちらも非常に速いということは言えると思います。 10 億回の動的ポリモーフィズムが1,2秒でできるということは、それがパフォーマンスのボトルネックになる可能性は低いと言えます。
今回のデモではポリモーフィズムでロジックを振り分ける以外にはほとんど意味のある計算をしていないのですが、 dyn Trait が2倍程度の計算時間になるということは、その意味のない計算程度のオーダーのオーバーヘッドだということです。
dyn Trait の特性としてより重要なのは、 Enum と違って、後からどんな型でもポリモーフィズムが振り分ける対象に追加できるということです。これはクレートなどで公開するインターフェースとしては大きな意味があります。 Enum には #[non_exhaustive] 属性をつけることでクレート作者が将来新たなバリアントを互換性を壊さずに追加する機能がありますが、そのクレートのユーザが新たな型を追加するのを許すことはできません。
その一方で、トレイトの実装はコード量がほぼ確実に増えるのと、 Object safety を考慮する必要があるなど、複雑度が増すことは避けられません。
また、トレイトはジェネリック関数を使えば静的ディスパッチ相当になるので(今回のデモではそうならないように配列に異なる型を混ぜています)、パフォーマンス上の懸念があればジェネリック関数を使うこともできます。ただし、 monomorphization によってコードは肥大化し、キャッシュミスを増やすかもしれません。
実際に Enum と dyn Trait のどちらを選ぶかは、様々な要因を考慮し、速度はそのごく一部に過ぎない場合が多いでしょう。
Discussion
Enum の場合の測定結果が、dyn Trait の場合の測定結果と同じになっているような?
ご指摘の通り、コピペ間違いでした。
修正しました。