Scalaで自動微分してみた感想
自動微分シリーズ、何番目かもう自分でもわかりません。
今回は Zig に続き Scala で自動微分を実装してみます。 Scala は関数型とオブジェクト指向の特徴を織り交ぜた言語だそうで、 Rust とたまに比較されます。 ADT があれば自動微分のノードの表現も捗りそうです。
自動微分は Rust で書いた rustograd をベースとしていますが、汎用的なライブラリというほど完成度を高めることは目指しません。 Scala 自体の学習が主な目的です。似たような形で以前には Zig でもやってみました。
例によって成果は GitHub にあります:
出力例
まあチューリング完全な言語ですから当然同じことができますよね。
-
\sin(x^2)
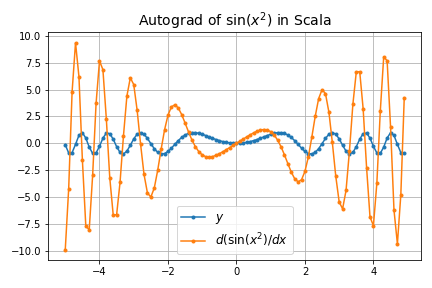
- 高階微分

- グラフの可視化

感想
一通り動作するプログラムができたので、ここまでの Scala の経験から感想を述べたいと思います。いつも通り Rustacean のバイアスがかかっているのでご注意ください。
ADT (代数的データ型)について
ADT はトレイトとそれを実装したクラスで実現され、 Tagged Union ではありません。これは JVM が Tagged Union に相当するものを持っていないためにやむを得ないことではありますが、動的型検査を実行時に毎回行うということなので、パフォーマンス上はあまり望ましくありません。
例えば、次のような単純なコードを考えてみます。 直和型 E が整数か浮動小数点数をバリアントとして持ち、 square メソッドが実体に応じてポリモーフィックに動作するという例です。
sealed trait E
case class A(a: Int) extends E
case class B(a: Float) extends E
object Square {
def square(num: E): Float =
num match {
case A(a) => a * a
case B(a) => a * a
}
}
Godbolt にかけてみると square メソッドのバイトコードは次のようにコンパイルされます(抜粋)。
public float square(E);
0: aload_1
1: astore_3
2: aload_3
3: instanceof #19 // class A
6: ifeq 32
9: aload_3
10: checkcast #19 // class A
13: astore 4
15: aload 4
17: invokevirtual #23 // Method A.a:()I
20: istore 5
22: iload 5
24: iload 5
26: imul
27: i2f
28: fstore_2
instanceof インストラクションを使ってバリアントを特定し、 checkcast によって型を特定し、さらに invokevirtual を使ってメソッドを呼び出しています。これら動的ディスパッチは、 JVM 上は一つのインストラクションに見えますが、実際のハードウェア上ではメモリアドレスを飛び回ったり継承ツリーを辿ったりするのでキャッシュフレンドリーではありません。バリアント A か B かを判定するだけにしては大掛かりなチェックです。
これに対し、 Rust でのほぼ等価な次のコードはどうなるでしょうか。
pub enum E {
A(i32),
B(f32),
}
pub fn square(num: E) -> f32 {
match num {
E::A(num) => num as f32 * num as f32,
E::B(num) => num * num,
}
}
Godbolt は次のようにコンパイル結果を出します。
example::square:
mov qword ptr [rsp - 16], rdi
(*) mov rax, qword ptr [rsp - 16]
(*) mov qword ptr [rsp - 24], rax
(*) mov eax, dword ptr [rsp - 24]
(*) cmp rax, 0
jne .LBB0_2
mov eax, dword ptr [rsp - 20]
cvtsi2ss xmm0, eax
cvtsi2ss xmm1, eax
mulss xmm0, xmm1
movss dword ptr [rsp - 4], xmm0
jmp .LBB0_3
(*) でマークを付けた行がメモリから判別用のタグをロードして判定している部分です。最適化オプションを有効にしていないのでレジスタとの間で無駄なやり取りがありますが、スタックとレジスタ上で操作が完結していることがわかります。
ついでに、 Zig も見てみます。
pub const E = union(enum) {
a: i32,
b: f32,
};
fn square(num: E) f32 {
switch (num) {
.a => |v| return @intToFloat(f32, v * v),
.b => |v| return v * v,
}
}
Godbolt はやはり Rust と似たようなことをしていることを示しています。
square:
push rbp
mov rbp, rsp
sub rsp, 32
mov qword ptr [rbp - 24], rdi
mov al, byte ptr [rdi + 4]
mov byte ptr [rbp - 13], al
test al, al
jne .LBB76_2
jmp .LBB76_6
ADT がトレイトの継承で実現されていることのもう一つの副作用は、 match 式のケースの取り尽くしがコンパイラによって保証されないということです。 sealed trait にすれば警告は出してくれますが、純粋関数型言語や Rust に慣れているとしっくり来ません。
トレイトについて
トレイトって、ぶっちゃけインターフェイスのことですよね。 JVM を使っているのにわざわざ名前を変える理由がよくわかりません。 Rust のトレイトもインターフェイスとしての側面は持っていますが、 monomorphization や演算子オーバーロードなどのコンパイル時の挙動に影響するので、差別化の理由はあります。しかし、 Scala のトレイトは Java のインターフェイスに近すぎて混乱を招きそうです。
[2023/12/24 追記] トレイトにはメソッドの実装ができるという点でインターフェースと差別化がされているそうです。詳しくはコメント欄をご覧ください。
パターンマッチについて
Scala のマッチ式はとても関数型的で良いです。特に複数の変数の型をマッチさせつつ取り出す下記のようなコードは美しく書けます。
(gen_graph(lhs, wrt), gen_graph(rhs, wrt)) match {
case (Some(lhs), None) => Some(lhs)
case (None, Some(rhs)) => Some(rhs)
case (Some(lhs), Some(rhs)) => Some(add_add(lhs, rhs))
case _ => None
}
これは「左側 (lhs) のみに値があればそれをそのまま返し、右側 (rhs) のみに値があればそれをそのまま返し、両方に値があればそれを足した結果を返し、どちらも値がなければ None を返す」という動作ですが、直感的に書くことができるうえに場合の取り尽くしも確認できます。
Rust と比較してみると非常に似ています(Rust では借用チェッカーの関係で引数が多いですが、それを除けば構造は全く一緒です)。
let lhs = gen_graph(nodes, lhs, wrt, cb, optim);
let rhs = gen_graph(nodes, rhs, wrt, cb, optim);
match (lhs, rhs) {
(Some(lhs), None) => Some(lhs),
(None, Some(rhs)) => Some(rhs),
(Some(lhs), Some(rhs)) => Some(add_add(nodes, lhs, rhs, optim)),
_ => None,
}
これが Zig ではどうだったかというと、こんなです。
const lhs = try self.gen_graph(args[0], wrt, allocator);
const rhs = try self.gen_graph(args[1], wrt, allocator);
if (lhs) |lhs2| {
if (rhs) |rhs2| {
debug_print(" .add both derived = ({?} {?})\n", .{ lhs2.idx, rhs2.idx });
return try lhs2.add(rhs2, allocator);
} else {
return lhs2;
}
} else {
return null;
}
Zig の switch 文は Tagged Union の振り分けには使えるのですが、一般のパターンマッチには使えないので、このような醜い if のネストで対応するしかありません。ケースが取り尽くされているかも一目ではわかりません。
とは言え、このようなパターンマッチが必要になる場合は比較的少ないので、大きな問題になるわけではなく、主に美的感覚の問題です。
Option 型について
個人的にはちょっと残念だったのが Option 型の仕様です。 Option は実体としてはトレイトで、 Some と None というクラスが継承しています。これによって Option 型の変数に Some(a) と None のどちらもセットできるというわけですが、実はこれ以外にも null がセットできてしまいます。
var data: Option[Double] = Some(1) // OK
var data: Option[Double] = None // OK
var data: Option[Double] = null // これもOK!?
つまり次のような安全に見えるマッチ式も、実は完全に安全ではありません。
data match {
case Some(a) => println(s"data set to $a")
case None => println("data is not set")
}
null のケースもカバーするとなると次のようになります。
data match {
case Some(a) => println(s"data set to $a")
case None => println("data is not set")
case null => println("oops")
}
Option 型の変数に null を代入するなんて悪の所業をそもそも許すべきではないのですが、コンパイラはこれを防いでくれませんし、警告すら出しません。私は null が None に型強制されるのかと思って null を代入してみたらおなじみの NullPointerException が出迎えてくれました。
Option 型は非常によく使うジェネリック型なので、この仕様はいただけません。もちろん、 Java との相互運用性を考えて null も許さざるを得なくなっているのでしょうが、 Java では値の非存在を null で表すという慣例が長いこと通用しているので、 Option と役割がバッティングしています。
[2023/12/24 追記] null を Option に代入できなくするコマンドラインオプションがあるそうです。詳しくはコメント欄をご覧ください。
演算子オーバーロードについて
Java には演算子オーバーロードはありませんが、 Scala では演算子のオーバーロードどころか、自分の好きな演算子を作ることもできます。これはメソッド呼び出しと中置演算子を上手く同一視することで実現されています。元々の構文の省略できる部分が多いことも相まって、複数の演算子のオーバーロードは非常に簡潔に書けます(unary_- だけなんだか変な構文ですが…)。
def +(other: TapeTerm) = TapeTerm(tape.add_add(idx, other.idx), tape)
def -(other: TapeTerm) = TapeTerm(tape.add_sub(idx, other.idx), tape)
def *(other: TapeTerm) = TapeTerm(tape.add_mul(idx, other.idx), tape)
def /(other: TapeTerm) = TapeTerm(tape.add_div(idx, other.idx), tape)
def unary_- = TapeTerm(tape.add_neg(idx), tape)
Rust では演算子のオーバーロードはトレイトの実装によって行われるので、ここまで簡潔には書けません。
これは自動微分のような「数値のように振舞うけど、実体としては数値ではない」ようなオブジェクトを簡潔に扱うのに非常に役に立ちます。ちょっと考えるだけでも、ベクトル、行列、複素数、四元数、高階関数など様々な数学的オブジェクトに明らかに役に立ちます。
余談ですが、 Java が演算子のオーバーロードをサポートしていない理由は、James Gosling の個人的な嗜好だったようです。なんでも C++ で濫用するユーザーが多かったせいだとか。実装自体はやろうと思えば簡単にできたはずです。
コンパイル速度
JVM 言語全てに言えることですが、処理系の動作がなんだかもっさりしています。特に小さなプログラムをコンパイルするのにも10秒ぐらい待たされる感じです(Godboltに至っては20秒ぐらい待たされます)。これは JVM が非常に大きいランタイムであるからで、プロセスの起動のたびに重いランタイムをウォーミングアップしているということでしょう。
Scala コミュニティもこの問題は認識しているようで、ビルドシステムの sbt はコマンドラインツールではなく、サーバとして常駐します。一度重い腰を上げたランタイムをメモリ上にロードしたままにすることで再コンパイルを速くしているのだと思います。 Rust も決してコンパイルが速い言語ではありませんが、ランタイムのオーバーヘッドは小さく、小さなプログラムのコンパイルはスケールに応じて速いです。
総括
総合的に、 JVM の上に関数型言語の機能を盛り込むという野心的な目標のために少々無理をしている印象を受けます。元々 Java という言語が強烈にオブジェクト指向な言語なので、その処理系である JVM もその影響を強く受けており、関数型言語のような全く違うパラダイムを構築しようとすると無理が出てくるような気がします。具体的には、型安全性は Haskell や OCaml や Rust ほど強い静的保証ではなく、抜け道があります。
JVM とそれに影響を受けた言語の歴史を見ると興味深いところがあります。昔々、 Java Applet という技術があり、ブラウザ上で Java アプリケーションのサブセットを動かすことができました。これが広まればサーバとwebページの両方[1]で同じ言語が使えると期待されていましたが、いろいろあって[2]廃れてしまいました。むしろ今ではwebページを動かすための技術であった JavaScript がサーバアプリケーションを侵食しています。
今では Java Applet が目指した地位に近づいているのは WebAssembly です。その理由を考えるに、一つは低レベルの VM でありオブジェクト指向のような思想の押し付けがないため、あらゆる言語がコンパイルターゲットにできるということがあると思います(他にもライセンスやマーケティング、安全性などの理由もあるでしょうが)。
ソフトウェア開発の世界の流れとしては WebAssembly のように実行環境は低レベルにし、コンパイラで機能の追加を行うという風向きを感じます。もし Scala が WebAssembly を最初からターゲットにしていたら、 Option 型と null などの問題もなかったのではないでしょうか。その代わり、存在意義が Rust に取って食われますが…。
Scala をどんな時に使うかというと、 Java の膨大な資産があり、それを維持しながら新しい開発をしなければならないけど、 Java は使いたくないような場合でしょうか。それだと Kotlin とも競合しますが…。
Discussion
こんにちは。ある程度Scalaに詳しいので補足させてください。
enumキーワードで定義するのが普通になっています(内部的にはsealed相当になります)。自動でsealedになるため、コンパイラによるexhaustive checkが自動で動作します。Optionにnullが代入できてしまう点については、-Yexplicit-nullsコンパイラオプションで抑制できます。ともあれ、普段Scalaを使っていない方による記事は新鮮でした。ありがとうございます。
ありがとうございます。経験のある方に補足していただければ記事の価値も上がります。
Optionにnullが代入できてしまうのは、個人的にはデフォルトでエラーにして欲しかったところではあります。いわゆる Billion dollar mistake は低水準言語では必ずしも「間違い」ではないと思いますが、 Scala の設計思想には許さないほうが合っている気がします^^; とはいえ、防ぐ手段ががあるという貴重な情報をいただきありがとうございます。ちなみに、本文では Scala に対して割と辛口ですが、構文は結構気に入っています。最近私が作った Wascal という言語は直接 Wasm にコンパイルする言語ですが、 Scala の構文の影響をかなり受けています。