[Rust] クレート分けのベストプラクティス
以前はモジュールのベストプラクティスという記事を書きました。
Rustには、モジュールのほかにクレート(crate)[1]という単位があります。このクレートの分け方について、イメージがつかない人も多いのではないかと思い、記事にします。
クレートとは?
クレートというのは Rust 特有の用語なので初見ではよくわからないと思います。ライブラリやパッケージのことだと思っている人も多いのでないかと思います。ここで定義をはっきりさせておきます。
クレートとは Rust の翻訳単位(Translation unit)のことです。
翻訳単位とは、コンパイラが一度に読み込むソースコードのことです。 C や C++ ではソースファイル (.c, .cpp) に当たります。
クレートという用語はオーバーロードされており、パッケージマネージャの Cargo はライブラリの単位もクレートと呼び、 crates.io に登録されているパッケージはクレート単位です。したがって、クレート=パッケージという理解も間違いではありません。しかし、それだけではどのような時にクレートを分けるべきかの判断には理解が足りません。
なぜクレートを翻訳単位にするのか?
そもそもなぜクレートが翻訳単位として設計されたのでしょうか。 C や C++ のようにソースファイル単位でコンパイルし、オブジェクトファイルをリンクする分割コンパイル形式ではいけなかったのでしょうか。
少し補足すると、 C や C++ のビルド手順は次のようになっています。 a.c や b.c や c.c がそれぞれ別々にコンパイルされ、その結果がリンカによって統合されて一つの実行ファイルになるイメージです。ヘッダーファイルがインクルードされていればソースファイル間でコードを共有することもできますが、これは単純にソース文字列を挿入するだけであり、あくまでもコンパイラが一度に見ているのは一つの .c ファイルです。
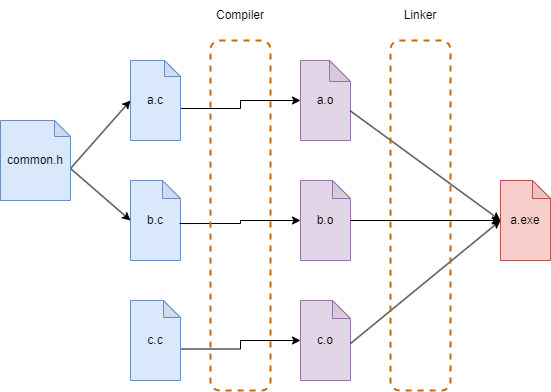
これに対し、 Rust のコンパイル手順は次のようになります。クレート内の全ての .rs ファイルがまとめてコンパイルされて .rlib ファイルができます(.rlib は Rust のスタティックライブラリの拡張子です)。リンク時にはメインの .rlib ファイルのほかに、依存先クレートの .rlib もリンカに入力されます。

実は、これには最適化の都合があります。オブジェクトファイルに一度コンパイルしてしまうと、インライン化などのソース内の知識を必要とする最適化が翻訳単位を跨いで適用できません[2]。このため、最近の C++ ではヘッダーファイルにロジックを書くことが多く、ヘッダーオンリーライブラリも増加傾向にあります[3]。
ワークスペースとの関係は?
Cargo にはワークスペースという概念があります。これは複数のクレートを一つのコードベースでまとめて管理するのに役立つ機能です。
具体的な使い方は公式ドキュメントがよくまとまっているので繰り返しません。しかしいくつか注意点があります。
ワークスペース内では Cargo.lock は一つだけです。そしてクレートの解決はワークスペース内で共有されます。つまり、依存先ライブラリのバージョンに 0.1.1 と 0.1.2 のような Semvar 上は互換性のあるものがあった場合、どちらか一方に統一されます。これはコンパイル時間や中間コードサイズの肥大化を防ぐのに役立ちますが、認識していないと驚くような結果をもたらすかもしれません。
また、公式ドキュメントだけを読んでいるとわかりませんが、相対パスで依存先クレートを指定すれば、ワークスペースの外のクレートを参照することも可能です。
[dependencies]
my-lib = { path = "../my-lib" }
これはマルチレポ構成で役に立つかと思いますが、私個人は使っていません。 git のパスでサーバを指定した方がパスの移動に対して頑健なのが理由です。
[dependencies]
behavior-tree-lite = { git = "https://github.com/msakuta/rusty-behavior-tree-lite" }
Rust Analyzer の注意点
Rust Analyzer は(みんなすでに使っていると思いますが)エディタのコーディングサポートツールです。コードヒントやリファクタリングに大きな効果を発揮します。 Rust Analyzer のサポート機能は Rust の強力な型システムと合わさって非常に強力であり、 tabnine などの AI サポートツールが煩わしく思えるほどです。
しかし、 Rust Analyzer はエディタで開いたルートディレクトリの Cargo.toml しか見に行きません。サブディレクトリに入れ子にしたクレートは認識してくれません。このようなときはルートディレクトリに次のような Cargo.toml を置くと認識してくれます。
[workspace]
members = ["crate1", "crate2"]
resolver = "2"
しかし、この方法だと前述のワークスペースになるので、前述の注意が必要になるのと、 target フォルダが一つにまとめられてしまうので、そこは認識しておく必要があります。
モジュールとの関係は?
ソースファイルが翻訳単位ではないのなら、モジュール(ほとんどソースファイルと対応)とは何なのでしょうか。これは簡単に言うと名前空間とプライバシー境界を提供する入れ物です。詳しくは前の記事を参照していただければと思いますが、プログラムの論理的な構造化をサポートするものであって、コンパイラが見るものは一つの巨大なソースのセットです。
このことから、一つの観測が導けます。巨大なプロジェクトの場合、モジュールをいくら小分けにしても分割コンパイルによるコンパイル時間の短縮の恩恵にはあずかれないということです。そこでクレートを分ける第1のケース、コンパイル時間の短縮につながります。
クレートを分ける3つの場合
ここからは実際にクレートを分ける場合を3つのシナリオで紹介します。
- コンパイル時間の短縮
- 共通ロジックの共有
- 手続きマクロ
コンパイル時間の短縮
プロジェクトが大きくなってきたとき、コンパイル時間が遅くなってきたなと感じたら、それはクレートに分けるタイミングかもしれません。特に、滅多に変更しないけどボリュームの大きいコードをクレートに分けると効果が高いでしょう。
とは言いましたが、正直、コンパイル時間の短縮だけを目的としてクレート分けしたことは私はありません。最近は Rust のインクリメンタルコンパイラが進化して、それなりの規模のコードベースでも待てないほど遅いと感じることは少なくなってきました。しかし、私のプロジェクトにはそれほど大きな単一のコードベースはないので、何万行もあるようなプロジェクトでは考慮に値するかもしれません。
共通ロジックの共有
これが最も正統なクレート分けの理由と言えるでしょう。例えば、サーバサイドとクライアント(WebAssembly)でロジックを共有したいような場合です。サーバサイドはネイティブ(x64等)、クライアントは WebAssembly なので、異なるターゲットプラットフォームですが、 Rust のクレートはターゲットごとにコンパイルする共通ロジックを実装することができます。
他にも考えられるケースとしては、ライブラリと実行形式などがあります。例えば git のようなコマンドラインツールは、他のアプリケーションに組み込むためのライブラリも実装していることがあります(git の場合は libgit2 というものです)。クレートに分ければこのような共有は実に簡単にできます[4]。
手続きマクロの実装
Rust には手続きマクロ(procedural macro)という概念があります。これは宣言的マクロ(declarative macro)と対比される概念です。宣言的マクロは機械的なソースコードの置き換え(厳密に言うとASTの置き換え)ですが、手続きマクロは任意のプログラムで入力ソースコードを変換することができます。これは非常に強力な機能で、 derive マクロなどはこの機構で実装されていますが、実は手続きマクロはそれを実装したクレート自身には使えません。宣言的マクロはこれと異なり、実装したクレート自身でも使うことができます。
なぜでしょうか?答えは翻訳単位という言葉の意味にあります。実は、 Rust の手続き的マクロはコンパイラのダイナミックリンクライブラリプラグインとして実装されています。つまり、手続きマクロを使ってソースコードを変換するには、そのマクロ自体のコードをコンパイラが走っているプラットフォームのネイティブバイナリとしてコンパイルする必要があります。 Windows でいえば .dll 、 Linux でいえば .so です。自分自身をコンパイルする前に実行することはできないので、翻訳単位を分ける必要があるのです。
これは宣言的マクロとは対照的です。宣言的マクロはコンパイラへのASTの置き換えルールを記述するものにすぎませんので、別途ネイティブコードへコンパイルする必要がなく、同じクレート内に適用できるのです。
手続きマクロは個別の実行可能形式をビルドするので、宣言的マクロよりも一般的に低速です。しかし、クレートに分かれているので、手続きマクロ自体のロジックを変更しない限り2回目のビルドではコンパイルがスキップされるはずです。
-
いつも悩むのがこのような固有名詞的なワードを英語のままにするかカタカナ化するかです。特に R か L を含む単語は、カタカナ化してしまうとスペルのヒントが無くなってしまうので、誤解の元になりそうな気がします。 Rust 自体も、ラストとしてしまうと Last なのか Lust なのかわからなくなります。しかし、ここでは公式ドキュメントの日本語版がカタカナ化しているのでそれに倣います。 ↩︎
-
実際にはリンク時のグローバルな最適化などの技術もないわけではないですが、ソースの全てを見通せるコンパイル時には最適化に使える情報が最大限活用できます。 ↩︎
-
ヘッダーオンリーライブラリが好まれる理由は他にもあります。オブジェクトファイルをコンパイルするライブラリの場合、配布に際して考えなくてはいけないことが増えるのです。例えば、スタティックライブラリをコンパイルする際、バイナリ配布をするには各プラットフォームごとにコンパイルしたバイナリを用意する必要があります。 x86, x64, Arm32, Arm64, Windows, Linux, Mac などなど。同じ Linux でも libc のバージョンによっては非互換であったりします。さらに動的リンクライブラリ (.so, .dll) を配布するか否かも選択肢に入ります。ヘッダーオンリーライブラリであれば、ユーザーのプログラムにソースを注入するだけなので、バイナリ配布とそれにまつわる面倒ごとはありません。 ↩︎
-
実は Rust では一つのクレートがバイナリとライブラリの両方になれます。 lib.rs と main.rs の両方をソースに置くことで可能です。さらに複数のバイナリを Cargo.toml の [[bin]] セクションに置くこともできます。しかし、バイナリのみに含めたいコード、ライブラリのみに含めたいコードなども出てくるので、混乱を避けるためにも共通部分はクレートに括りだすのがクリーンでしょう。 ↩︎
Discussion