プライバシーサンドボックスについて調べる
プライバシーサンドボックスは、サードパーティの Cookie やその他の追跡メカニズムを使用せずにクロスサイトのユースケースを満たすことを目指す一連の提案です。
https://developer.chrome.com/ja/docs/privacy-sandbox/
主に Chrome (Google) がサードパーティ Cookie を廃止するために別の仕組みを入れたいので、それ関連の提案とかをまとめているよう。
このスックラップの目的
シェア No.1 の Google Chrome の動向は無視できないので、とりあえずどういうことをやろうとしているのかの概要を把握するのが目的。
モチベーション
個人的には、トラッキングとかされるのは嫌いだし、FLoC (Federated Learning of Cohorts) とかも好きじゃない。
でも実際広告でいろいろ成り立っている面もあるし、実際どこかでバランスを取っていく必要はあると思うので、Webエンジニアとしてどういうものが導入されて、どういう懸念があるのかとかは知っておきたい。
参考リンクとかを貼っておくスレッド
自分で書いた First-Party Sets のメモ
Web とは直接関係ないけど、トラッキング拒否すると色々影響はありますよね、という感じ。
サードパーティ Cookie 廃止のスケジュールが送れることになった。
Mozilla の提案に対する立場を示したもの。
Mozilla Specification Positions
FLoC (Federated Learning of Cohorts)
こういうイメージのブラウザAPIらしい。
API 自体が問題ではなくて、どういう風にコホート(興味のグループ的なもの)を出すかと、どの程度の粒度があるか(細かいと、ユーザーを特定しやすくなる)とかが問題なきがする。
cohort = await document.interestCohort();
url = new URL("https://ads.example/getCreative");
url.searchParams.append("cohort", cohort);
creative = await fetch(url);
そもそもターゲティング広告自体に問題もある、という話もあるよう。
加えてEFFは、そもそも「ターゲティング広告」そのものに問題があると指摘。これまで、民族・宗教・性別・年齢または能力に基づいて人々をターゲティングすることにより、仕事や住居といった分野で差別的な広告の数々が行われてきました。例えば信用情報に基づくターゲティングを行うと、金銭的な問題を抱える人に高金利のローンを表示させるという「略奪的な」広告が可能になります。また、政治の世界では、ターゲティング広告が世界的な混乱を起こしてきたと知られています。
https://gigazine.net/news/20210305-googles-floc-terrible-idea/
一応長期的なプライバシーへの懸念と対策案も書かれているよう。
ただ、ちょっと微妙な雰囲気があるな・・・。
Longitudinal Privacy
The expectation is that the user’s FLoC will be updated over time, so that it continues to have advertising utility. The privacy impacts of this need to be taken into consideration. For instance, multiple FLoC samples means that more information about a user’s browsing history is revealed over time. Possible mitigations include not updating FLoC on a site once it has been called (making it sticky), or reducing the rate of refresh.
Second, if cohorts can be used for tracking, then having more interest cohort samples for a user will make it easier to reidentify them on other sites that have observed the same sequence of cohorts for a user. Possible mitigations for this include designs in which cohorts are updated at different times for different sites, ensuring each site sees a different cohort while the semantic meaning of the cohort remains the same.
Webの閲覧履歴などはどこにもアップロードしない、とのこと。
The central idea is that these input features to the algorithm, including the web history, are kept local on the browser and are not uploaded elsewhere — the browser only exposes the generated cohort.
なんか漠然と考えていたのは、Google に送って Google 内で処理するとかなのかな〜、とか思っていた。
なので、思っていたよりはマシな印象だった。
とはいえ、色々問題はありそうな雰囲気を感じた。
- どういうロジックでコホート(興味のグループ的なもの)は決定されるのか?
- ブラウザに依存することになりそうだし、機械学習で行われるもののようだから、ブラウザベンダーと教師データ(がいるのかもよくわからない?)によって依存しそう。
- コホートが逆にプライバシーを侵害する危険性がないのか?
-
サンプルに
"43A7"みたいな値があったから、16進数4桁で65,536パターンあると思うので、それなりに識別する情報になりそう。 - IPアドレスや User-Agent とかと組み合わせればほぼ特定できるレベルになるのでは?
- そういうのがあるから、プライバシーサンドボックスとして一連の提案しているとは思うけど。
-
サンプルに
FLEDGE
言葉自体の意味。
羽毛が生えそろう、巣立ちができる
https://ejje.weblio.jp/content/fledge
FLEDGE はリマーケティングに活用可能でありながら、第三者がサイト間のユーザーの閲覧行動を追跡できないように設計されています。この API を使用すると、ユーザーが以前にアクセスした Web サイトが提供する関連広告を選択するためのブラウザーによるデバイス上の「オークション」を実現できます。
ユーザーが自社の製品またはサービスを宣伝したいサイトのページ (広告主) にアクセスすると、サイトはユーザーのブラウザーに特定の期間 (たとえば、30 日間) ユーザーを特定の広告グループに関連付けるように要求できます。
https://developer.chrome.com/ja/docs/privacy-sandbox/fledge/#fledge-の仕組み
TURTLEDOVE というリポジトリの中にあるな・・・。
なにかの提案の中にあるものなのか?
The browser, not the advertiser, holds the information about what the advertiser thinks a person is interested in.
ブラウザが閲覧者の関心がある情報を知っている(広告主は知らない)って感じか。
この場合 Chrome を持っているのが Google だから微妙な気もするな・・・。
- Advertisers can serve ads based on an interest, but cannot combine that interest with other information about the person — in particular, with who they are or what page they are visiting.
- Web sites the person visits, and the ad networks those sites use, cannot learn about their visitors' ad interests.
閲覧者の関心に基づいて広告を配信できるが、誰かを特定することはできない、ってところか。
Chrome expects to build and ship a first experiment in this direction during 2021. For details of the current design, see FLEDGE.
なるほど。
TURTLEDOVE が提案の内容で、FLEDGE が具体的な実装みたいなイメージなのかな。
First Experiment (FLEDGE)
よく見たら、最初の実験の名称が FLEDGE なのか。
FLEDGE は TURTLEDOVE から生まれた API です。
ん?よくわからなくなってきた・・・。
FLEDGEはプライバシーサンドボックスで議論されてきたTURTLEDOVEという概念の初期のプロトタイプです。TURTLEDOVEはインターネットユーザーの興味・関心といった情報をブラウザに保存し、広告主がそれを利用可能にする仕組みですが、「Google Chromeへの依存が増す」と懸念されています。
https://gigazine.biz/2021/02/21/fledge/
なるほど。
実装的には、こんな感じで navigator.joinAdInterestGroup で特定のグループに参加させる、って感じなのか。

こんな感じでオークション(?)されるのか。

なんだろ、ブラウザが閲覧者の関心を持つ、っていうところがそもそも引っかかるな・・・。
シェアNo.1 の Chrome は Google が持っているわけで、そこを色々やったり、最悪 Chrome はユーザーと紐付けることもできなくはなさそう。
アトリビューションレポート
Cross-Site Identifier (クロスサイト識別子) を使用せずに、ユーザーの操作 ( 広告のクリックや表示など) がコンバージョンにつながるタイミングを測定します。
https://developer.chrome.com/ja/docs/privacy-sandbox/attribution-reporting/
え、Anchor 要素にこういう属性を追加するの!?



結局のところ、これもブラウザに保存するのか・・・
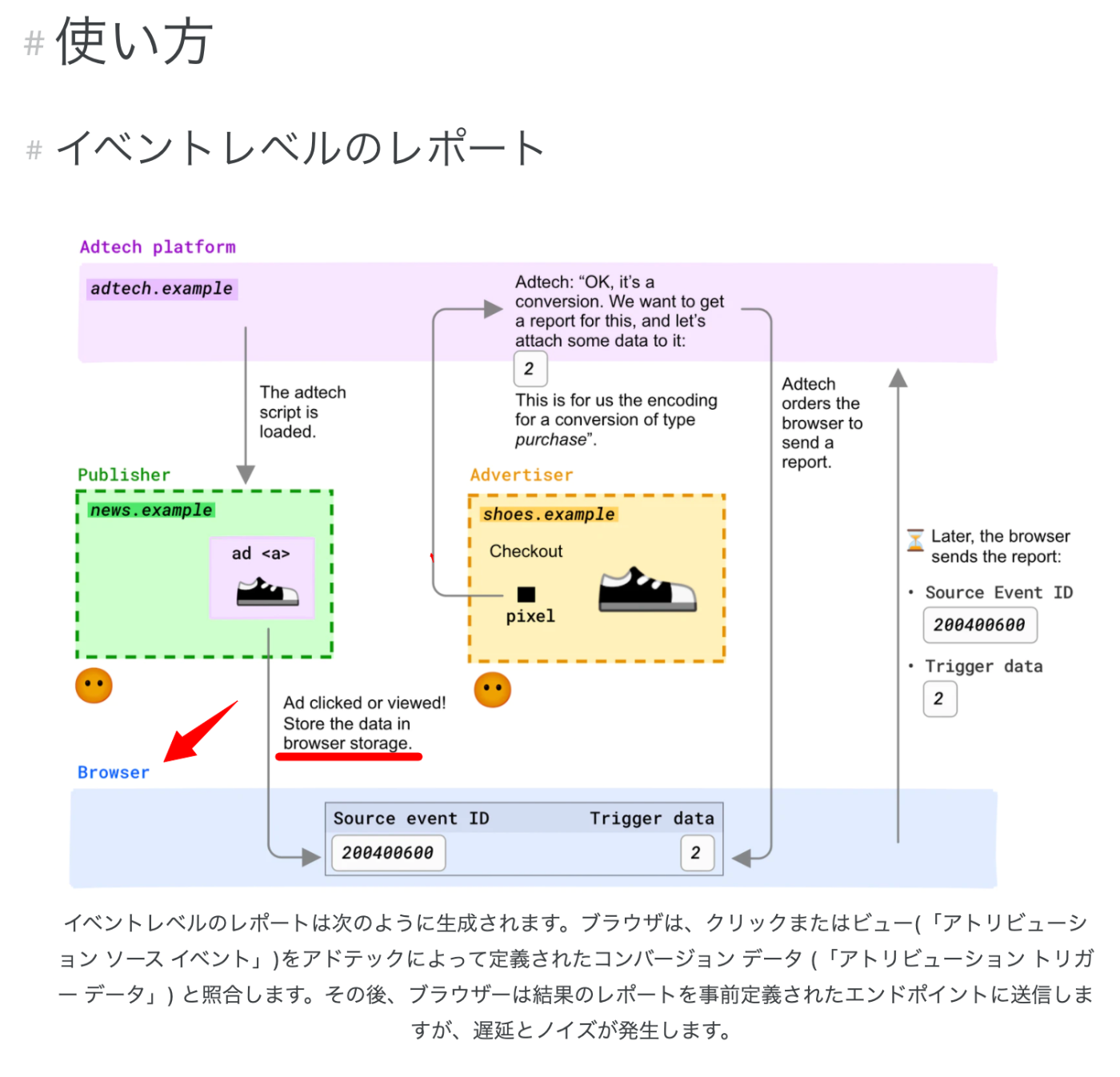
この送信する部分とかどうなってんだ・・・?

この Trusted Servers ってのはどこのサーバーなんだ?Google?
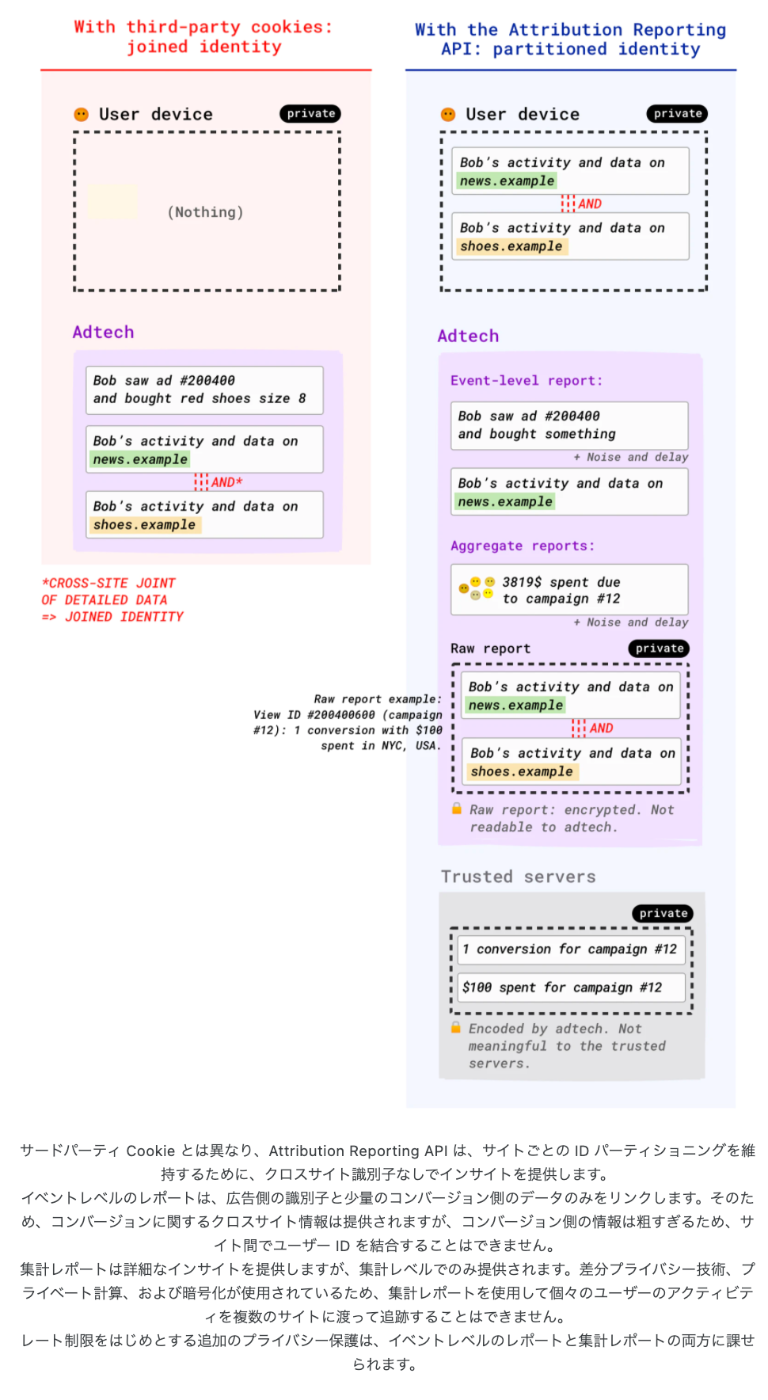
うーん、こういう微妙な制限を入れないといけないあたり、本質的に微妙な気がする。

詳細なクリックまたは表示イベントを詳細なコンバージョンデータに関連付ける生のレポートは暗号化されており、アドテック企業は読み取ることができません。集計データは、信頼できるサーバーを介してプライベートな方法でこれらのレポートから計算されます。いくつかの計算オプションが検討されています。
信頼できるサーバー=Google という前提(これは想像)だとすると、
Google を信頼しないといけない、ってことになるんだろうか。
結局のところ、Truested Servers には追跡可能なレベルの生レポートがある気がするから、
おそらく Google は見ようと思えば見れる状態になるんじゃないだろうか(想像)
これは、好ましくない状態な気がする。
SameSite Cookieの変更
リンク先を見る限り SameSite=None SameSite=Lax SameSite=Strict の話のよう。
First-Party Sets
Trust Tokens
トラストトークンを使用すると、ユーザーを認証できるかどうかの信頼性をあるコンテキストから別のコンテキストに伝達できるほか、サイトが詐欺行為を防いだり、ボットを実際の人間と区別したりするのに役立ちます。受動的な追跡は必要ありません。
https://developer.chrome.com/ja/docs/privacy-sandbox/trust-tokens/
Caution
トラストトークンは、reCAPTCHA やユーザーが主張する人物であることを判断するためのメカニズムに取って代わるものではありません。
トラストトークンは、ユーザーに対する信頼を確立するための手段ではなく、伝達するための手段です。
結局広告の計測のためなのか・・・。

Web 開発者向けにまとめた概要
Mozilla の立場

現状検討する予定はない
発行者サイトが、結局 Google になるのかなぁ・・・。
別で作れそうな雰囲気はあるけど、なかなか独自で維持していくのは大変そうなので、Google やそういう広告系のサービスで提供されていくことになる気がするな。
まぁでも、Google 以外でもできるのであれば、まだマシなのかもしれない。
Privacy Budget
リンクされていたこの動画が詳しかった。(英語だけど、日本語字幕もある)

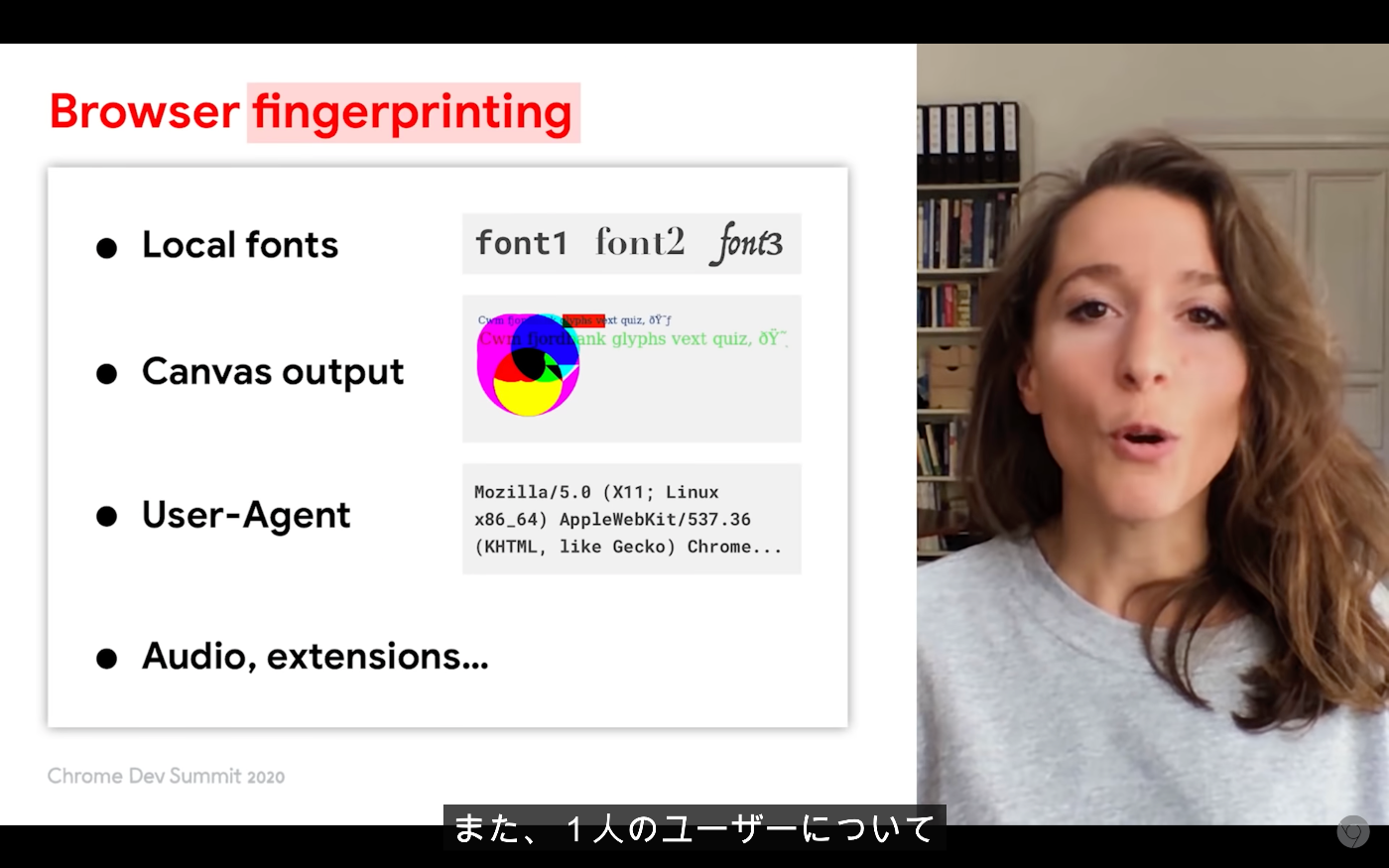
Font, Canvas, User-Agent などブラウザを識別するため使える API に対して、
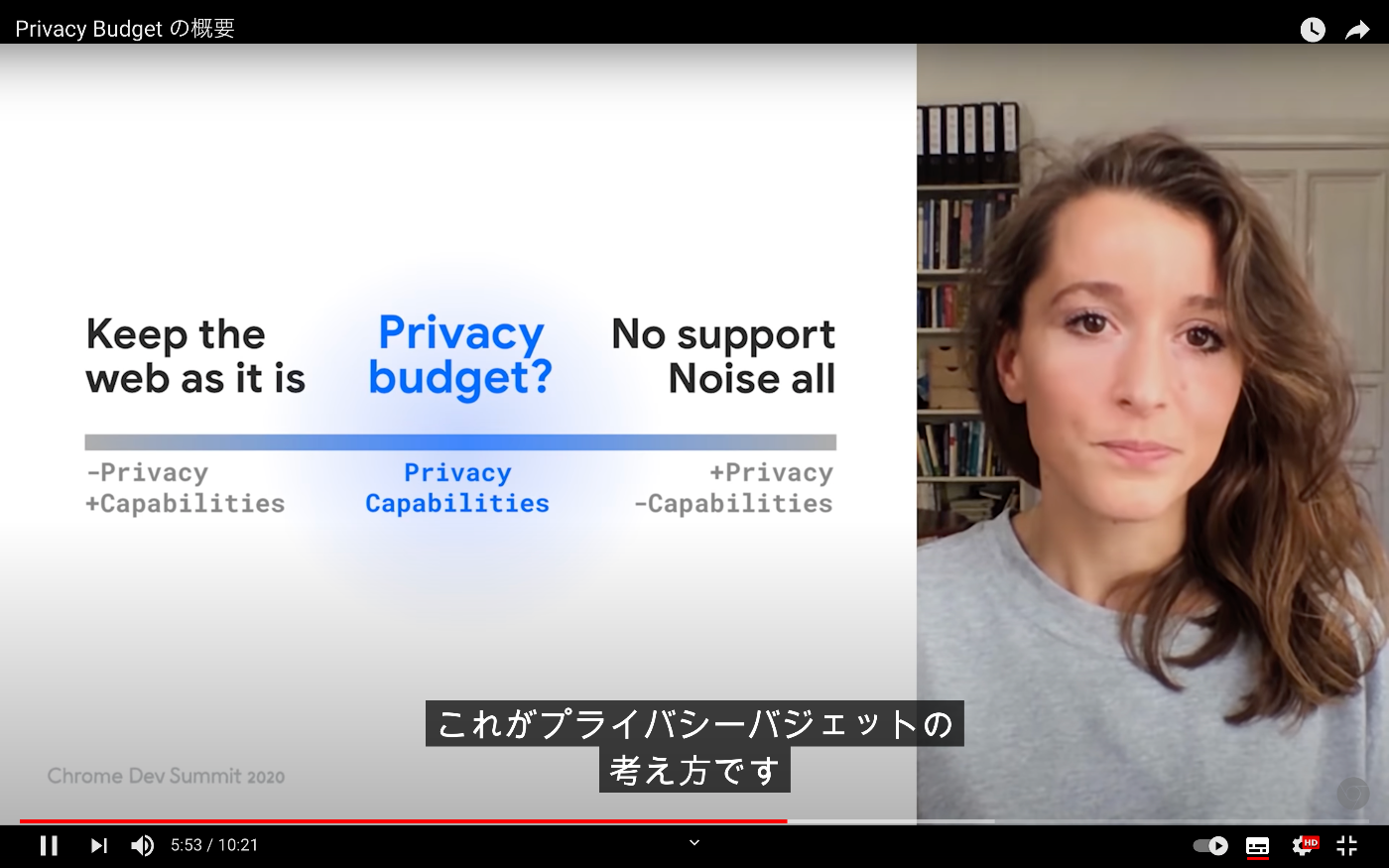

一定の制限を設ける、という趣旨らしい。
ただ、現時点では実験段階で絶対的な基準は存在しないっぽい。
User-Agent Client Hints
(力尽きてきたのでざっくりまとめると)
User-Agent で色々な情報を送信し、ユーザーを識別する一部の情報として使えてしまうので、情報をシンプルに、最低限にする、っていう取り組みのよう。

こういう画面サイズを送ってもらうようなことも可能になるっぽい。

Chrome 94 で見てみたけど、確かに送っていそう。

Gnatcatcher
IPアドレスを利用して個々のユーザーを識別する機能を制限します。提案には2つの部分があります。Willful IP Blindnessでは、WebサイトがIPアドレスをユーザーに関連付けしていないことをブラウザに通知できるようになります。Near-path NATでは、ユーザーのグループが同じプライベートサーバーを介してトラフィックを送信し、実質、サイトホストからIPアドレスを隠せます。Gnatcatcherはまた、不正使用防止などの正当な目的でIPアドレスの情報を必要とするサイトが、認証と監査を条件としてIPアドレス情報を取得できるようにします。
Apple の Private Relay について(参考)
クライアントがサーバに通信すれば、 IP アドレスが伝わることは防ぎようがない(伝えなければレスポンスを受け取れない)。そこで、間に Apple が用意した Proxy を挟むことによって、サービスには Proxy の IP アドレスしか伝わらないというのが基本の発想だ。
Private Relay と IP Blindness による Fingerprint 対策 | blog.jxck.io
(力尽きてきたのでざっくりまとめると)
サーバーからIPアドレスを隠すための技術っぽい。
ユーザーを特定しにくくなるという面では賛成。
ただ、サービス提供側の立場で考えると攻撃者も同じようなことをすると識別しにくくなるので、そのへんは悩ましくなる可能性がありそう。
Safari / Webkit: Private Click Measurement (プライベート クリック測定)
4bit のデータを送信できる。

24~48時間後(ランダム)に送られる。
(バックグラウンドで送られるのかな?)

IPアドレス保護についてはこっちを見てね。

Anchor 要素の attributionsourceid (多分コンバージョンを識別するためのID) と attributiondestination (コンバージョン先のドメイン)を指定する

<img> タグに元サイトへの特定のURLにアクセスするようにしておくと、

/.well-known/private-click-measurement/trigger-attribution/(ID)/(priority) にリダイレクトさせるのかな。
(priority) の部分は後から上書きしたいときとかに使うっぽい。たぶんキャッシュとかするから?
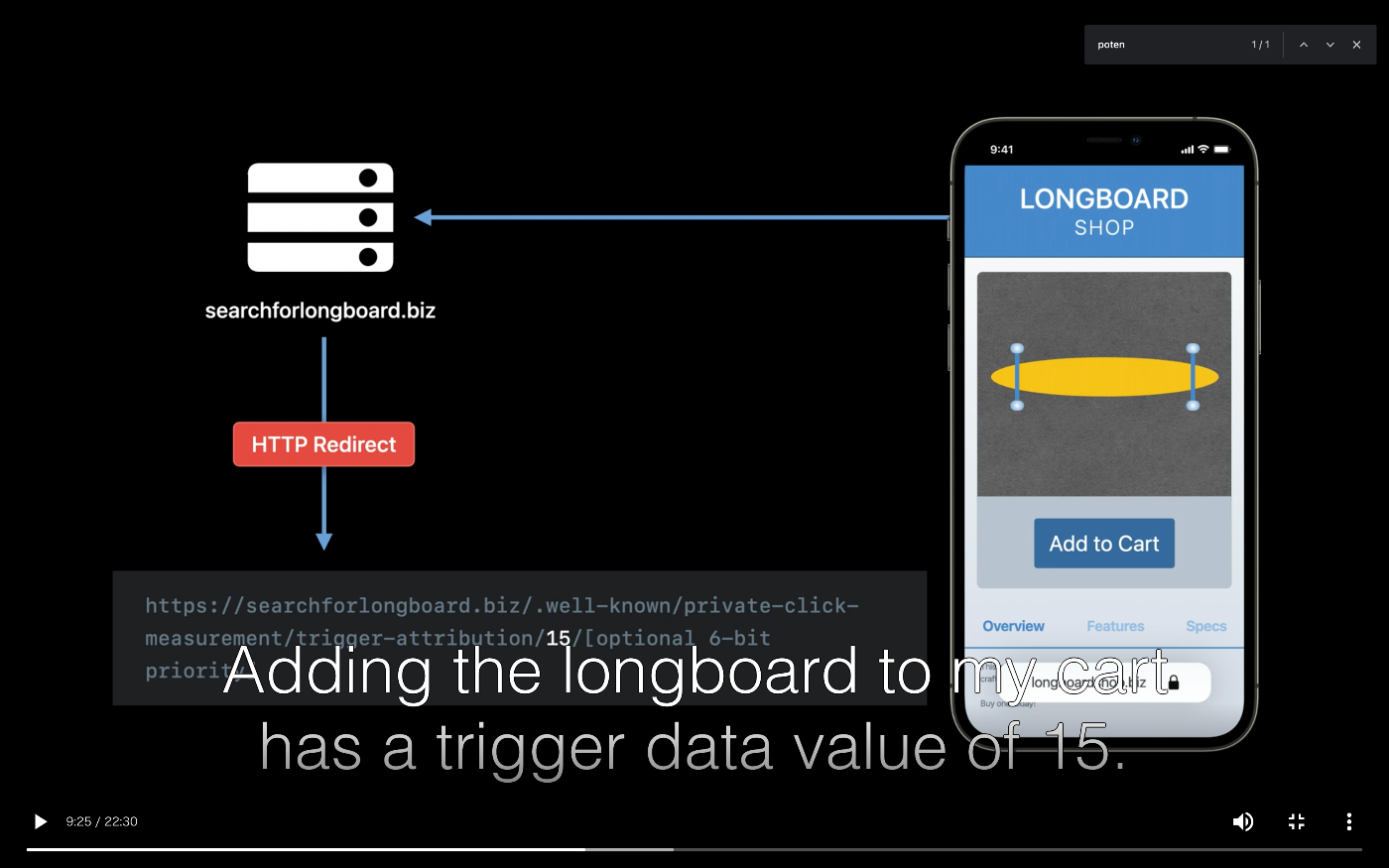
この辺は、Safari が自動判別するためにやるから <img> タグとかに入れておかないといけないって感じなのかなぁ。
で、それぞれのレポートを作成するための紐付け情報を /.well-known/private-click-measurement/report-attribution/ にJSON形式で提供する。
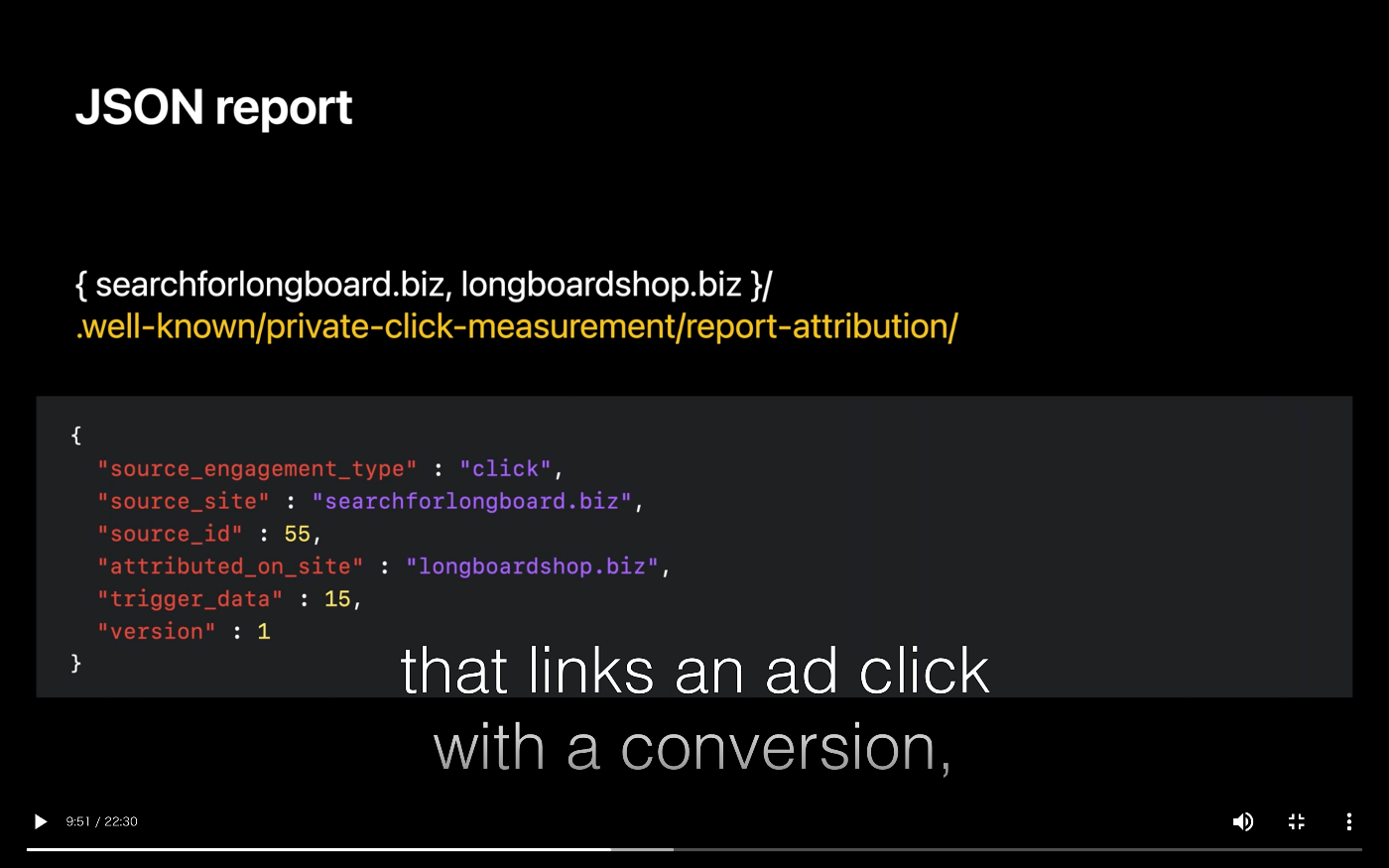
アプリにも、同様の仕組みがあるっぽい。
(そこまでは追わない)
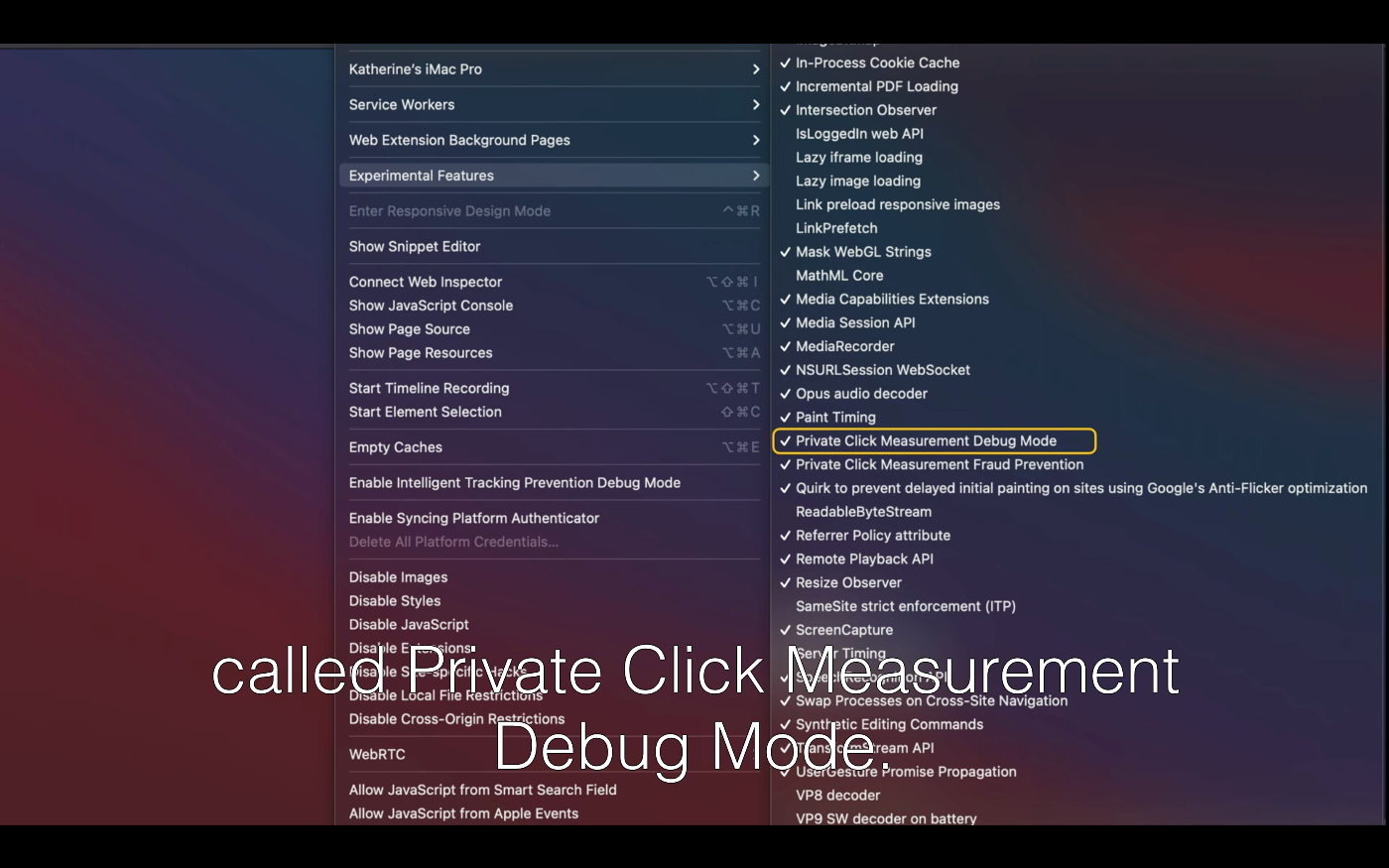
Debug モードも用意されていて、10秒程度で送ってくれるようになるらしい(通常は24〜48時間後)
RSAでの署名を使って、不正防止をするっぽい。

記事の方にまとめたのでクローズ。