Azure Load BalancerでHealth Status(正常性状態)がGAしたので試してみた


はじめに
2024/11/07のAzureアップデートで、Azure Load BalancerのHealth Status(正常性状態)機能がGAしていました。
便利そうな機能だったので、試してみました!
Health Statusとは
Health Status機能でバックエンドプールの正常・異常状態をサーバー単位で確認することができます。
また、なぜ異常となっているのかの判断材料となる異常理由も確認できるようになりました!
試してみる
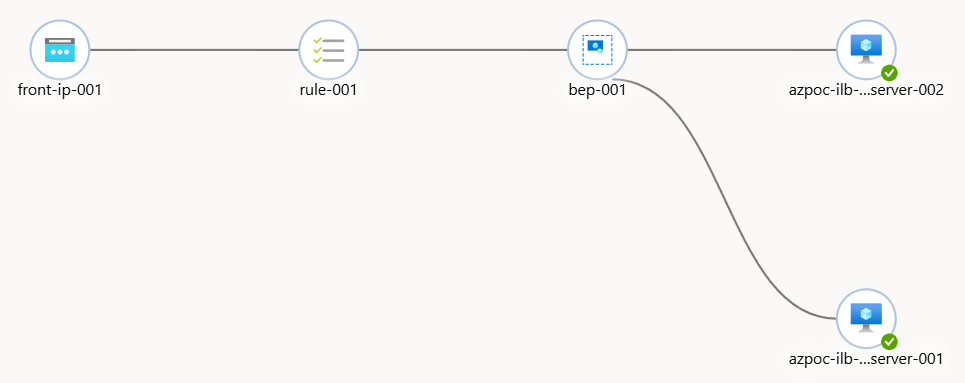
構成図
まずは、このような環境を用意しました。
Azure Load Balancerのバックエンドで2台のVirtual Machinesを起動し、NGINXでWEBサーバーを起動します。
環境を作成するためのTerraformコードはこちらのリポジトリに置いてあります。
 |
|---|
正常時
サーバー2台ともNGINXを起動し、正常性プローブが成功している状態にします。
 |
|---|
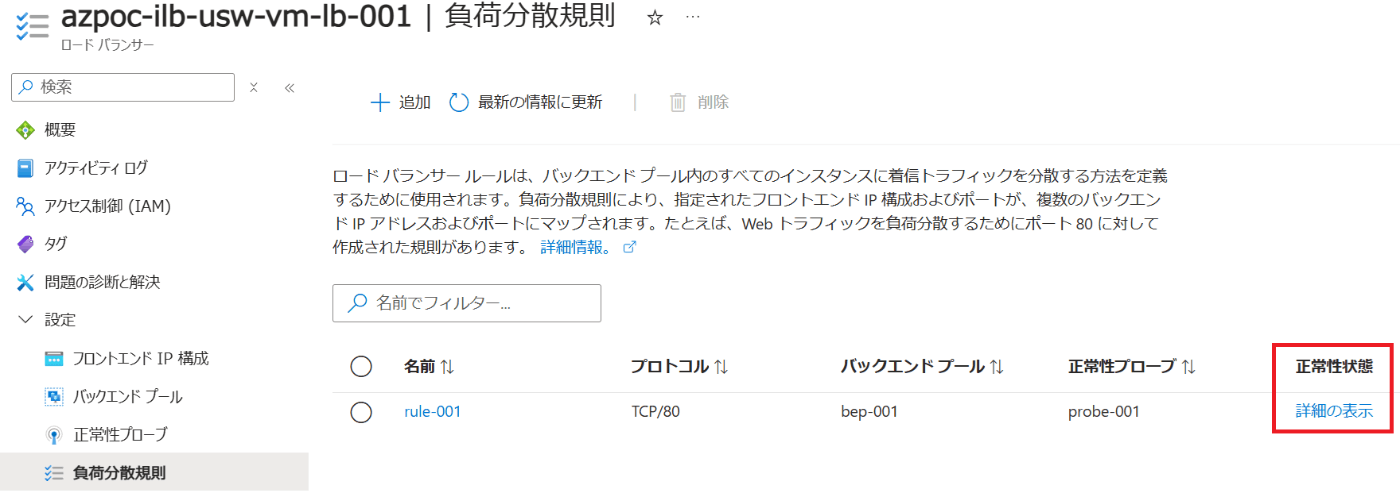
Health Status(正常性状態)機能を開いてみます。
Azure PortalのLoad Balancerで「負荷分散規則」を開き、「正常性状態」列の「詳細の表示」リンクが表示されているので、クリックしてみると…
 |
|---|
バックエンドプールの各サーバーの正常性状態を確認することができます。
 |
|---|
現時点では「理由」列は英語で表示されます。「The backend instance is responding to health probe successfully.」となっており、バックエンドプールのVMが正常性プローブに正常に応答していることが確認できました。
「理由」列に表示されるメッセージの説明と、表示されるメッセージのバリエーションは以下ドキュメントに記載されています。
異常時
WEBサーバー(NGINX)停止
1台のサーバーでNGINXを停止してみます。正常性プローブはHTTP(Port80)に設定しているため、失敗判定となるはずです。
NGINXを停止後に「正常性状態」を表示してみると…
正常性プローブでHTTPエンドポイントに到達できなかったことが確認できました!
NSGルールでブロックされている、またはサーバーアプリケーションで異常が起きている可能性が示唆されています。
 |
|---|
WEBサーバーHTTPレスポンス異常
次に、NGINXのHTMLコンテンツを退避して、HTTPレスポンスコード403が発生するようにしてみます。
「正常性状態」を表示してみると、正常性プローブでHTTPレスポンスコード200以外が受信されていることを確認できました。
 |
|---|
Admin StateによるDown
同じく2024/11/07のAzureアップデートで、Admin State機能もGAしています。こちらは、正常性プローブの状態を上書きするもので、Admin Stateで強制的にバックエンドプールのVMをUp状態/Down状態に指定することができます。
以前はAzure Load Balancer側の操作だけでバックエンドプールの特定のVMだけDown状態にすることはできず、NSG Rule側で特定VMだけ正常性プローブが失敗するよう通信をブロックしたり、VM側のサーバー設定を弄って正常性プローブに応答しないようにする必要がありました。
Admin Stateを使うことにより、バックエンドプールの特定VMだけ正常性プローブをDown状態することで、Azure Load Balancerから新規で接続されない状態にしてVMのメンテナンスを行ったり、新しい機能をデプロイしてテストを行うなどが容易になります。
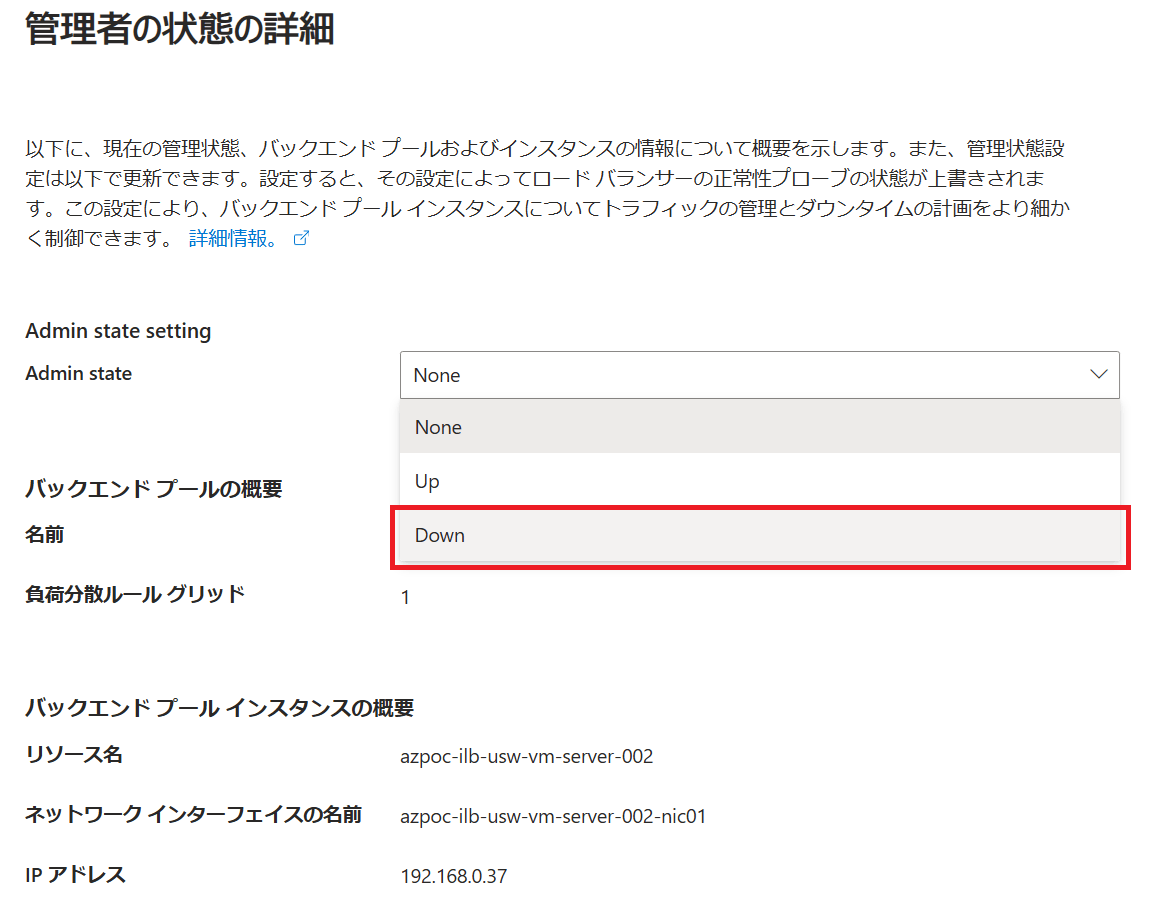
Admin State機能を使って、もう1台のサーバーも明示的にDown状態にしてみます。
Azure PortalのLoad Balancerで「バックエンドプール」を開くと、「管理者の状態」列が表示されているので、「なし」リンクをクリックします。
 |
|---|
2台目のサーバーもAdmin Stateで明示的にDown状態に設定します。
 |
|---|
その後、「正常性状態」を表示してみると、Admin StateでDwon設定がされていることが原因であると確認できました。
 |
|---|
最後に
Azure Load BalancerでもAzure Application GatewayのようにAzure Portal上で正常性プローブの失敗理由が確認できるようになったのはトラブルシュートが迅速にできるので便利になりましたね!
以上です。
Discussion