LlamaIndexとVertex AI Vector Searchで手を動かしながらRAGの全体像を理解する
はじめに
Google Cloud には Vertex AI Search というマネージドサービスがあり、
BigQuery や CloudSQL、Cloud Storage にデータがあれば、そのまま使って RAG ができます。すごくラクで、便利です。
今回はその「ラクで便利」な RAG の裏側に対する理解を深めていくことを目的に、
フレームワークである LlamaIndex と Google Cloud のベクトルデータベースである
Vertex AI Vector Search(旧 Vertex AI Matching Engine)を使って RAG をやってみます。
今回の記事では触れないこと
- ビジネスの観点
- 「RAG 以前にやることがあるのでは?」といったことには触れません。技術的なことのみ触れます。
- RAG の意義
- 「ハルシネーションを減らす」、「自社データを活用できる」といった "Why RAG?" には触れません。
- RAG に対する賛否
- 「コンテキストウインドウの大きいモデルが出てきて RAG はもう不要になるのでは?」といったことにも触れません。
- RAG をやりたいときにどうするかということにのみ触れます。
記事の流れ
以下の流れで解説していきます。
- RAG のコンセプトと各ステージにおける検討ポイント
- Google Cloud を使った RAG の選択肢
- Google Cloud と LlamaIndex で RAG やってみた
RAG のコンセプトと各ステージにおける検討ポイント
図を交えながら RAG のコンセプトと、回答精度向上におけるポイントを整理していきます。
コンセプト
まず最初に、RAG のコンセプトを整理します。
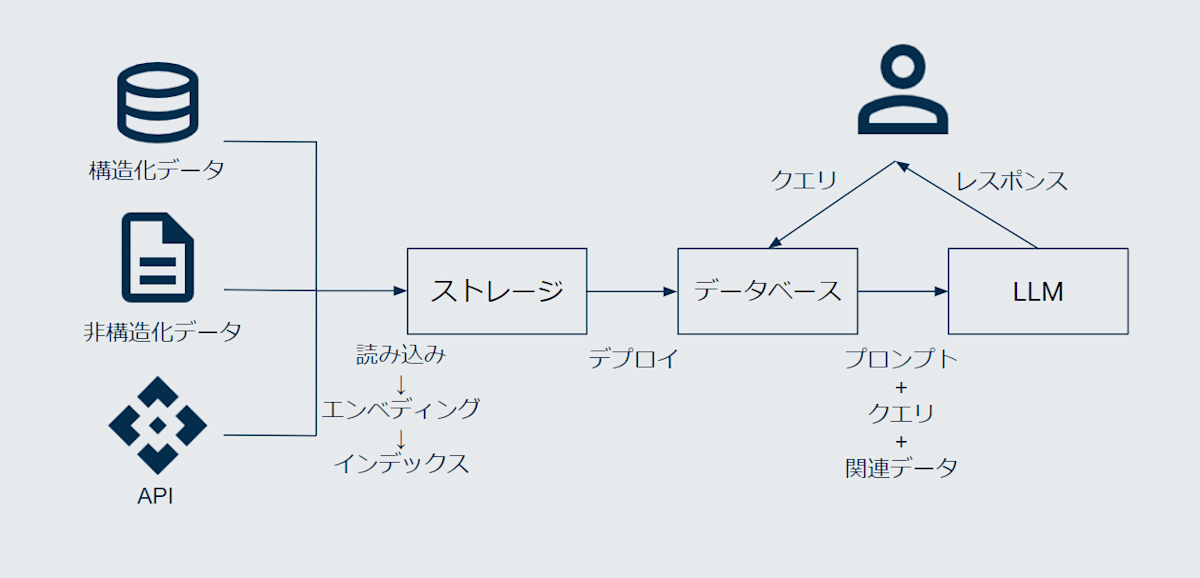
図で表すとこのようなものです。

ざっくりと流れを示すと以下の通りです。
- ユーザからのクエリに関連する情報を検索
- 上記で得た検索結果とユーザからのクエリを組み合わせたプロンプトを LLM に入力
- 出力されたレスポンスをユーザーへ返す
Retrieval(データを検索して)→Augment(その結果を付け加えて)→Generate(LLM で回答を生成する)ということですね。
開発者の視点では、RAG は以下のステージから構成されていると考えられます。
- ドキュメントの読み込み
- エンベディング生成、インデックス
- インデックスの保存
- ユーザーからのクエリ受付、検索
- 評価
これからは上記に沿って各ステージの解説と、
回答精度向上の視点を含め、どういった検討事項があるのか整理をしていきます。
いずれのステージにおいても銀の弾丸的な絶対解はなく、
LLM の処理時間やコスト、性能とのバランス、クエリの性質など、
ユースケースに応じて組み合わせていく必要がありそうです。
各ステージにおける検討事項
各ステージごとに解説していきます。
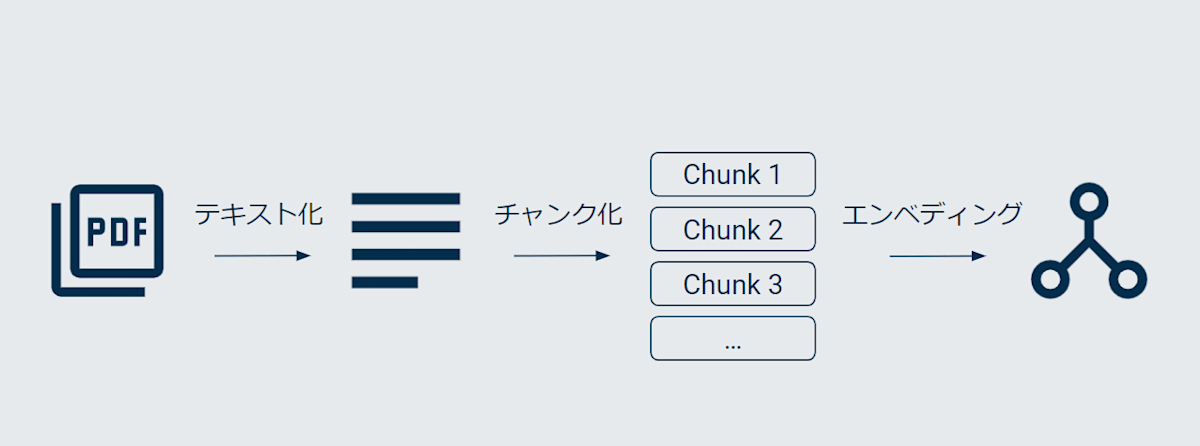
ドキュメントの読み込み
検索に使いたいドキュメントを読み込みます。
ざっくり表現すると RAG は
「ドキュメントの中から、関連している箇所のみ LLM に渡す」
という仕組みのため、読み込んだドキュメントすべてをそのまま LLM に渡すのではなく、
チャンク化します(そのあとでベクトル変換もしますが、それはまたあと解説します)。
チャンク化とは、クエリに対して適切な情報(コンテキスト)を取得できるよう、
長いテキストを細切れにすることです。
そのため、読み込みそれ自体と、それに次ぐ工程のチャンク化でそれぞれ検討事項があります。
読み込みに関する検討事項
RAG の次のステージ(インデックス)で使用するために、
ドキュメントの情報は基本的にプレーンなテキストに変換する必要があります。
そのため、非構造化データ(画像や音声、PDF など)を扱う方法について特に検討が必要です。
-
ファイルの形式
- 対応しているファイル形式は使用するプラットフォームやフレームワークによって異なるため、これによってデータの前処理の難易度も変わってくる可能性がある
-
前処理
- 非構造化データの処理
- 同じ内容のテキスト形式の代替ファイルがあれば、それを使う
- ライブラリを使用して読み取る
- OCR で読み取る
- マルチモーダル LLM で読み取る
- マルチモーダル LLM で要約する
- テキストの処理
- 特殊記号などの除去
- マークアップなどの不要な文字の削除
- 非構造化データの処理
特に PDF の情報を正確に読み取ることには難儀するのではないでしょうか。
人間には見えない謎の文字が入っていたり、テキストと思いきや埋め込み画像だったり、
特殊なレイアウトだったりします。
チャンク化に関する検討事項
-
チャンクのサイズ
- 大きすぎるとクエリに関係ないコンテキストを多く含んでしまう
- 小さすぎるとコンテキストを適切に反映させられない
-
チャンク化のルール
- 機械的な方法
- 文字数やトークン数
- 改行の数など
- ファイル形式の構造
- Markdown や HTML
- AI を活用する方法
- 意味の近さで分類を試みる
- 機械的な方法
-
前後のチャンク間における重複
-
メタデータの付与
- ドキュメントのタイトルや作成者、作成日、キーワード、カテゴリなど
エンベディング生成、インデックス
チャンク化されたテキストをすべてベクトル化(エンベディングを生成)し、
検索できるように構造化します。
まだメジャーな手法ではない様子ですが、ナレッジグラフを構築するパターンもあります。
インデックスのステージにおける検討事項は以下です。
- エンベディング生成の際に使用するモデル
- 使用するインデックスのタイプ
エンベディング生成の際に使用するモデル
どのような観点で使用するモデルを検討すべきか、一例を記載します。
- 対応言語
- 最大入力長
- OSS モデルか否か
- 学習データのドメイン
- モデルのカットオフ時期
- マルチモーダル対応か否か
使用するインデックスのタイプ
- 例えばLlamaIndex には対応しているインデックスのタイプが複数あります。
- インデックスを木構造にして、情報に階層を持たせたりする方法など。
インデックスの保存
作成したインデックスを保存します。
コストやレスポンス速度の観点から
ユーザーからクエリを受けるたびに毎回インデックスを作成するわけにはいかないため、
保存してすぐに呼び出せるようにしておきます。
検討事項は、ユースケースに応じた適切なデータベースを選択することです。
この記事では具体的な製品名は列挙しませんが、
Google Cloud では Vertex AI Vector Search というサービスがあります。
後ほど、LlamaIndex とともに使用してご紹介します。
ユーザーからのクエリ受付、検索
ユーザーからのクエリに対してエンベディングを生成し、
すでに保存されているものとの類似度を比較のうえ、適切なものを取り出します。
このステージでは主に以下 3 つの検討事項があります。
- クエリの処理
- 使用する検索技術
- 検索結果のリランキング
それぞれキーワードを挙げていきます。
クエリの処理
リテラシーの問題などから、ユーザーのクエリが検索に適切でない場合があります。
検討できる手法をいくつかピックアップします。
-
クエリ拡張
- 元のクエリに何かしらの情報を追加して検索する。例えば以下のような情報
- 同義語や関連語
- 例えばRAG-Fusionという手法
- 特定のドメインやトピックに関連する情報
- クエリの意図や背景に基づいた情報
- 同義語や関連語
- 元のクエリに何かしらの情報を追加して検索する。例えば以下のような情報
-
HyDE
- 質問に対する仮説的な回答を LLM で生成し、その仮説的な回答を元の質問に追加して、埋め込みベクトルに変換する
-
サブクエリ
- 複雑な質問を、LLM で複数の単純な質問に分割
-
書き換え
- LLM でユーザーのクエリを書き換える
- 例えばRewrite-Retrieve-Readという手法
- LLM でユーザーのクエリを書き換える
分類モデルを使って、上記のうちのいずれか適切な手法にルーティングさせるという方法もあります。
また、この検討事項の前段として、
ユーザーからの入力フォーマットに制限を設けることも有効です。
例: フリーフォーマットではなく、プルダウンでの選択式にするなど。
入力フォーマットに制限を設ける具体例としてはアフラックさんの社内向け生成 AIがあります。
ユーザーフレンドリーな UI という文脈で、X で話題になっていた記憶があります。
使用する検索技術
全文検索とベクトル検索の 2 つがメジャーで、その両方を組み合わせて使う方法もあります。
-
全文検索
- スコアの計算に BM25 が使われることが一般的
-
ベクトル検索
- ベクトル同士の類似性を計算
- 広く使われる計算指標としてユークリッド距離、コサイン類似度、内積などがある
- ベクトル同士の類似性を計算
-
上記 2 つを組み合わせたハイブリッド検索
デフォルト設定の全文検索とベクトル検索をシンプルに組み合わせただけのハイブリッド検索だと、
ベクトル検索単体の場合よりも精度がむしろ下がるという話もあるようです。
参照: ハイブリッド検索で必ずしも検索性能が上がるわけではない
検索結果のリランキング
特定のモデル(Reranker)を使用して検索結果を並び替える処理をリランキング(再ランク付け)と呼び、
ベクトル検索に使われる埋め込みモデルよりも、Reranker の方が正確であるという話があります。
最初から Reranker を使えば良いじゃないかという話になりますがそうではなく、
Reranker は計算コストが高い(つまり、遅い)ので実用的ではありません。
そのため、まずベクトル検索で絞り込まれた対象に対して
リランキングを行うという二段階を踏む手法がとられることがあります。
評価(主に RAGAS の指標)
RAG における定量評価の方法は大きく 3 つに分けられます。
- 人による評価
- LLM による直接的な評価
- RAG に特化した評価
今回の記事では RAG に特化した評価について、
具体的には RAG の評価フレームワークである「RAGAS」における指標を主に紹介していきます。
RAGAS では、まず評価の観点を「Retrieval(データベースからの検索、取得)」と「Generation(回答の生成)」の 2 つに大きくわけ、
そしてそこからさらにわけて考えます。
- Retrieval(データベースからの検索、取得)
- Context Precision
- 質問の回答に必要な情報(コンテキスト)を LLM がどの程度正確に取得しているか
- Context Recall
- 取得したコンテキストがどの程度 Ground Truth と一致しているか
- Generation(回答の生成)
- Faithfulness
- 取得したコンテキストに関連した情報を LLM がどの程度返しているか
- Answer Relevancy
- 成された回答が元の質問にどれだけ関連しているか
ここではいったん概要の紹介のみにとどめておき、
実際にコードで触っていく際に詳細に踏み込んでいきます。
Google Cloud を使った RAG の選択肢
大きくは 2 つです。
- マネージドなサービスを使う
- 自前で実装する
マネージドなサービスを使う
Google Cloud にはVertex AI Searchというマネージドサービスがあります。
Vertex AI Search は Google Cloud に保存されている様々なデータ※に対して、簡単に検索を行えるようにできます。
※現在、Web サイト、BigQuery、Storage、Google ドライブ、(ここから右は 2024/7/4 時点でプレビュー)CloudSQL、Spanner、Bigtable、Firestore に対応しています。最新の情報はこちらでご確認ください。
手元にあるデータでちょっと RAG を試してみたいといった場合でも、
Cloud Storage にファイルをアップロードして、
コンソール画面をポチポチするだけで準備が完了しますので非常にお手軽です。
社内情報に対する生成 AI を用いた検索をお試しでやってみたい場合などに最適ではないでしょうか。
自前で実装する
どこまでスクラッチで開発するか次第ですが、
LangChain や LlamaIndex などのフレームワークを使いながら実装することが多いのではないでしょうか。
マネージドサービスの回答精度では不十分な場合や、
運用中のシステムとの兼ね合いなど様々な理由で自前での実装が必要になります。
その際、Google Cloud では以下のような選択肢があります。
- 各種フレームワークと Google Cloud の統合
- Google Cloud が公開している RAG 用 API
各種フレームワークと Google Cloud の統合
Google Cloud では各種フレームワークとの統合も進んでいます。
Google Cloud が公開している RAG 用 API
Google Cloud でも RAG における各ステージごとに API を公開しています。
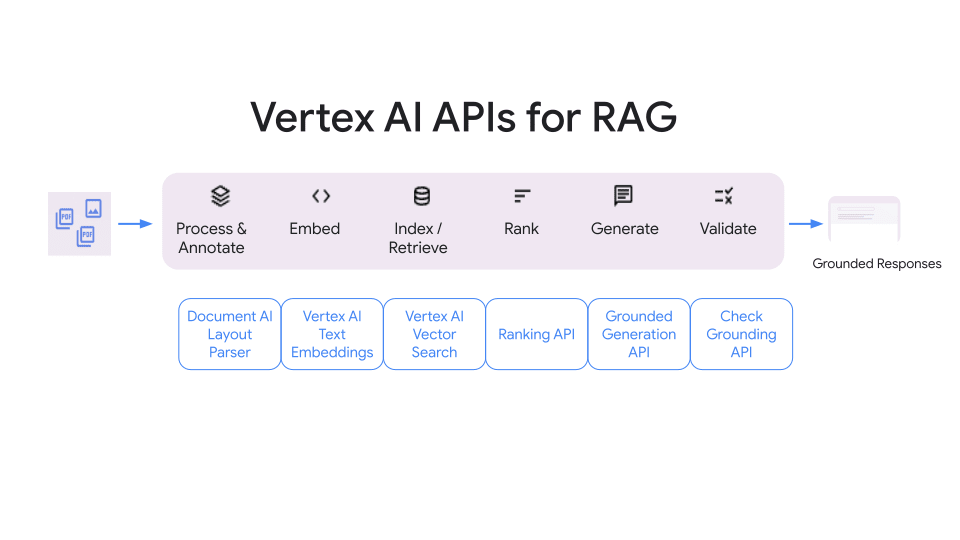
詳細はこちらのドキュメントをご覧ください。
次回以降の記事で触ってみて紹介する予定です。
LlamaIndex で RAG やってみた
ここからは実際に、Google Cloud と LlamaIndex を使って RAG を実装していきます。
LlamaIndex とは
LlamaIndex は、LLM と外部データ間の接続インターフェースを提供するフレームワークです。
雑に表現すると、RAG を簡単に実装するためのものです。
さっそく、LlamaIndex を動かしてみます。
準備
- 前提条件
Pythonのバージョン: 3.11.9
LlamaIndexのバージョン: 0.10.48.post1
特にLlamaIndexは変更が非常に激しいためご注意ください。
-
まずは Python の仮想環境を作成します。
python -m venv venv
-
必要なライブラリをインストールします。(今回は環境変数を python-dotenv を使って読み込みます)
-
pip install llama-index openai python-dotenv
※LlamaIndex はデフォルトで OpenAI の API を使うため、API キーのご準備をお願いします。
-
-
.envを作成し、API キーを書き込みます。
OPENAI_API_KEY=YOUR_OPENAI_API_KEY
- データを準備します。
- ルートディレクトリに適当な名前でフォルダを作成します。今回は、
dataとします。 - 例として経済産業省が公開している AI 事業者ガイドライン(第 1.0 版)を使用します。この PDF を data フォルダに格納します。
- ルートディレクトリに適当な名前でフォルダを作成します。今回は、
ここまでの手順で、以下のような状態になっている想定です。
├── venv
├── Include
├── Lib
└──...
├── .env
└── data
└── AI事業者ガイドライン.pdf
- Python ファイルを作成し、以下のコードを貼り付けます。
import os
import dotenv
import openai
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
dotenv.load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
def main():
# ドキュメントの読み込み
documents = SimpleDirectoryReader("data").load_data()
# インデックスの作成、ローカルへの保存
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir="index_storage")
query_engine = index.as_query_engine()
response = query_engine.query(
"AI利用者がAIシステム・サービスを利用する際に重要なことは何ですか?日本語で回答お願いします。"
)
print(response)
こちらは最も基本的なサンプルとして、クイックスタートから持ってきたコードです。
実行すると、以下のようなレスポンスが返ってきます。
AI利用者がAIシステム・サービスを利用する際に重要なことは、安全を考慮した適正利用、入力データ又はプロンプトに含まれるバイアスへの配慮、個人情報の不適切入力及びプライバシー侵害への対策です。
不十分ではありますが、PDF から正しい情報を取ってきてくれています。

改めてですが、(LlamaIndex における)RAG は以下のステージで構成されています。
- ドキュメントの読み込み
- エンベディング生成、インデックス
- インデックスの保存
- ユーザーからのクエリ受付、検索
- 評価
ここからは各ステージについてそれぞれ少しだけ深堀っていきます。
ドキュメントの読み込み
図で言うと、以下の部分のお話です。
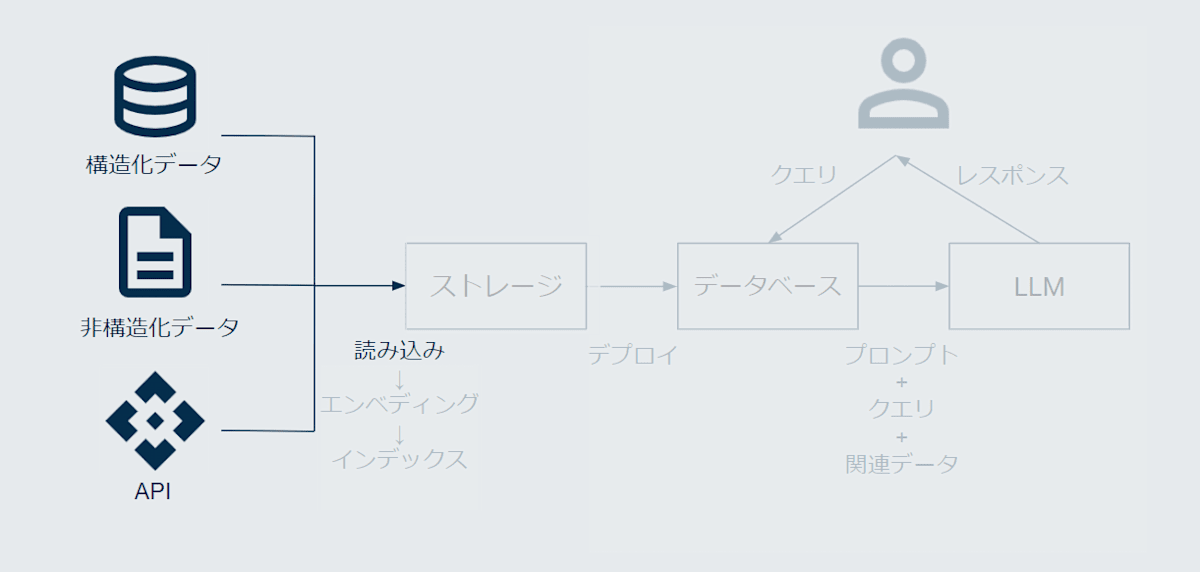
そしてコードは以下の部分です。
# ドキュメントの読み込み
documents = SimpleDirectoryReader("data").load_data()
以下はdocumentsを print で出力した結果の一部を少し見やすくしたものですが、
PDF の中身のテキストが抽出されたり、ファイル名などのメタデータが付与されていることがわかります。
[Document(id_='4eda7d9d-cf4c-4d03-8bd6-989553995a9b',
embedding=None,
metadata={'file_path': 'C:\\path\\to\\your\\data\\AI事業者ガイドライン_1.pdf',
'file_name': 'AI事業者ガイドライン_1.pdf', 'file_type': 'application/pdf',
'file_size': 115595},
excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date',
'last_modified_date', 'last_accessed_date'],
excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date',
'last_modified_date', 'last_accessed_date'],
relationships={}, text='5 \n \uf09f AI開発者(AI Developer ) \nAIシステムを開発する事業者(AI を研究開発する 事業者を含む) \nAIモデル・アルゴリズムの開発、 データ収集(購入を含む)、前処理、 AIモデル学習 及び検証を通して\nAIモデル、AIモデルのシステム基盤 、入出力機能等を含む AIシステムを構築する役割を担う。 \n \n\uf09f AI提供者(AI Provider)',
start_char_idx=None, end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}', metadata_seperator='\n')]
LlamaIndex 内部的にはDocumentというオブジェクトに変換された状態で、
これは次のステージであるインデックスのためのデータ形式です。
今回はローカルのフォルダにある PDF を読ませるため、SimpleDirectoryReaderというReaderを使用しましたが、
LlamaIndex には様々な Reader が用意されています。
エンベディング生成、インデックス
Documentオブジェクトに変換されたデータを、検索できる状態にします。
具体的には、テキストをチャンク化(分割)し、ベクトル化します(エンベディングの生成)。
図で言うと、以下の部分のお話です。
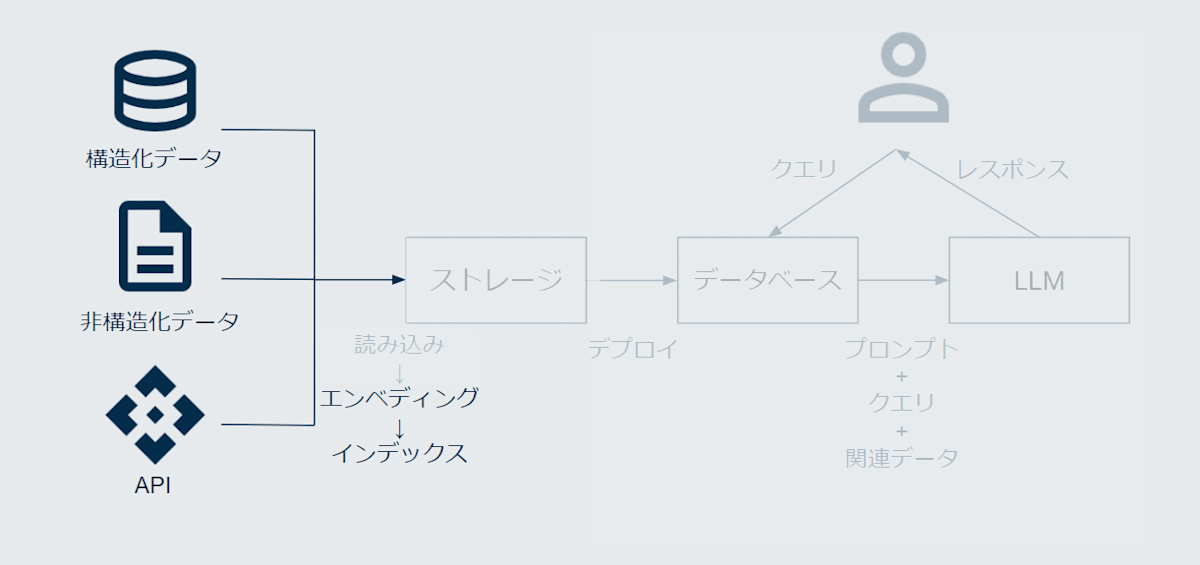
コードは以下の部分です。
index = VectorStoreIndex.from_documents(documents)
LlamaIndex の内部的な言葉で表現すると、
読み込まれたドキュメントであるDocumentオブジェクトがチャンク化されされたものをNodeオブジェクトと言います。
(詳細は公式ドキュメントを参照ください)
ユーザーからのクエリを受け取る際は、このNodeオブジェクト 1 つ 1 つが検索対象になります。
このインデックスのステージではベクトル化を行うために、
embedding モデルの LLM を使用しています。
つまり、大量の PDF などのデータを毎回インデックスしているとコストが非常に高くなってしまいます。
そこで、次回以降は作成したインデックスを呼び出せるように、どこかに保存する必要があります。
インデックスの保存
図で言うと、以下の部分のお話です。

コードは以下の部分です。
index.storage_context.persist(persist_dir="index_storage")
今回はいったん、ローカルにフォルダを作り、保存しています。
index_storageというフォルダと、その中にいくつかの json ファイルが作成されます。
├── data
└── index_storage
├── default_vector_store.json
├── docstore.json
├── graph_store.json
├── image_vector_store.json
└── index_store.json
├── venv
├── .env
└── main.py
ファイルの内容について深くは立ち入りませんが、
default_vector_store.jsonにはベクトル変換されたそれぞれのテキストや、それともとの文章を紐づける ID(document_id)などが格納されています。
のちほど、この保存先をローカルのフォルダではなく、
Google Cloud の Cloud Storage と Vertex AI Vector Store に設定してみます。
ユーザーからのクエリ受付、検索
ユーザーからのクエリを受け付け、関連するドキュメントを検索します。
図で言うと、以下の部分のお話です。
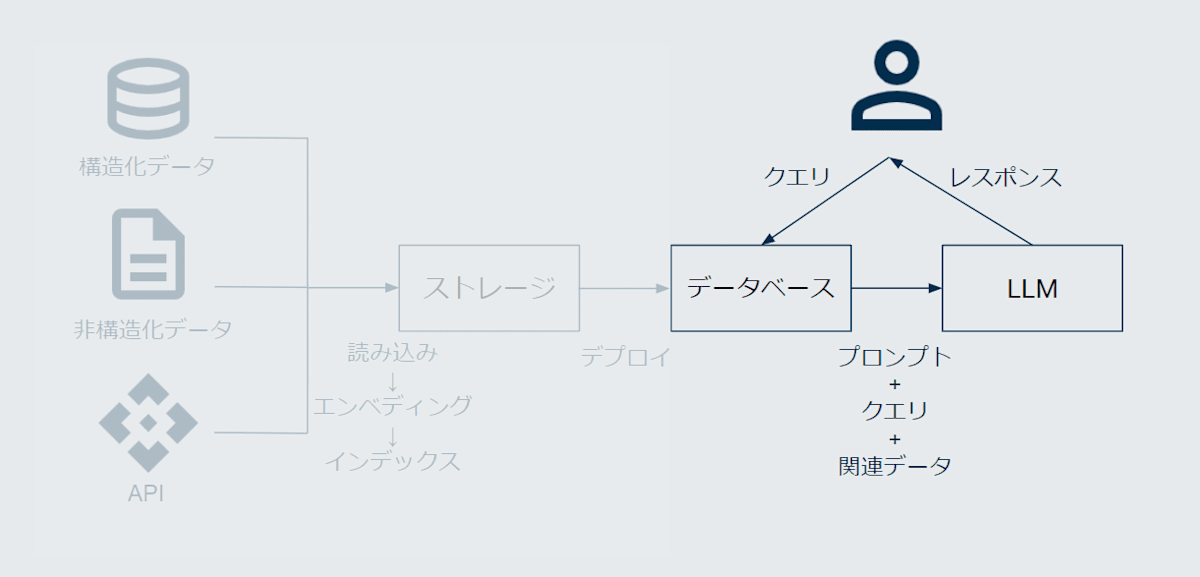
コードは以下の部分です。
query_engine = index.as_query_engine()
response = query_engine.query(
"AI利用者がAIシステム・サービスを利用する際に重要なことは何ですか?日本語で回答お願いします。"
)
ざっくりと表現すると、以下のような流れで処理が行われています。
- クエリをベクトル変換
- インデックスファイル内を検索し、関連性の高いデータ(
Node)を取ってくる - クエリと取ってきたデータを組み合わせて、LLM に渡す
オプションとして、2 と 3 の間で、取ってきたデータの並び替え(Reranking)や、フィルタリングができます。
評価(主に RAGAS)
最後に、LlamaIndex での評価について紹介していきます。
おさらいすると、RAG における評価には、大きく分けて 2 つの観点があります。
- 「Retrieval(データベースからの検索、取得)」
- インデックスファイルから取ってきたデータが適切か否か(とその度合い)
- 「Generation(回答の生成)」
- LLM が生成した回答が適切か否か(とその度合い)
再掲ですが、今回は RAG に特化した評価フレームワークである「RAGAS」における指標を主に紹介していきます。
retriever と generator でそれぞれ 2 つずつピックアップします。(評価指標は他にも多数あります)
-
Retrieval
-
Context Precision
- 質問の回答に必要な情報(コンテキスト)を LLM がどの程度正確に取得しているか
-
Context Recall
- 取得したコンテキストがどの程度 Ground Truth(正しい回答)と一致しているか
-
-
Generation
- Faithfulness
- 取得したコンテキストに関連した情報を LLM がどの程度返しているか
- Answer Relevancy
- 成された回答が元の質問にどれだけ関連しているか
- Faithfulness
LlamaIndex からも RAGAS は使えるため、引き続き先ほどまでのデータを使って進めていきます。
準備
以下の流れで進めていきます。
- RAGAS のインストール
- 評価用データセットの準備
RAGAS のインストール
pip install ragas
評価用データセットの用意
測定したい評価指標によりますが、RAG の評価には以下 4 つのデータセットが必要になることが多いです。
- 質問
- 回答
- コンテキスト
- LLM が回答を生成する際に参考にするドキュメントの情報
- 真の回答(Ground Truth)
特に、「質問」、「コンテキスト」、「真の回答」の 3 つは事前に用意をする必要がありますが、
これは手で作成する方法と LLM で作成する方法の 2 つがあります。
今回は LLM での作成で進めます。(自分でデータセットを作成する場合はこちらを参考にしてみてください。)
以下は、これまで使ってきた PDF ファイルを改めてDocumentオブジェクトとして読み込み、
評価用のデータセットを作成し、CSV に出力するコードです。
import os
import dotenv
import openai
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from ragas.integrations.llama_index import evaluate
documents = SimpleDirectoryReader("data").load_data()
generator_llm = OpenAI(model="gpt-3.5-turbo-16k")
critic_llm_llm = OpenAI(model="gpt-4")
embeddings = OpenAIEmbedding()
# テストセットを作成する際に使用するモデルの設定
generator = TestsetGenerator.from_llama_index(
generator_llm=generator_llm,
critic_llm=critic_llm,
embeddings=embeddings,
)
testset = generator.generate_with_llamaindex_docs(
documents,
test_size=5,
# 生成する質問のタイプの比率
distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25},
)
# convert to HF dataset
testset_df = testset.to_pandas()
testset_df.to_csv("testset.csv")
以下の部分について、distributionsのパラメータは 4 つのタイプに対応しています。
testset = generator.generate_with_llamaindex_docs(
documents,
test_size=5,
# 生成する質問のタイプの比率
distributions={simple: 0.5, reasoning: 0.25, multi_context: 0.25},
)
| 項目名 | 説明 |
|---|---|
| simple | 単純な質問 |
| reasoning | 推論を必要とする質問 |
| multi_context | 複数のセクションやチャンクから情報を取得する必要がある質問 |
| Conditioning | 条件付き要素を加えられた複雑な質問 |
出力された CSV ファイルは以下のようになります。5 つのデータを作成しました。
※非常に小さいので、お手数ですが拡大してください。
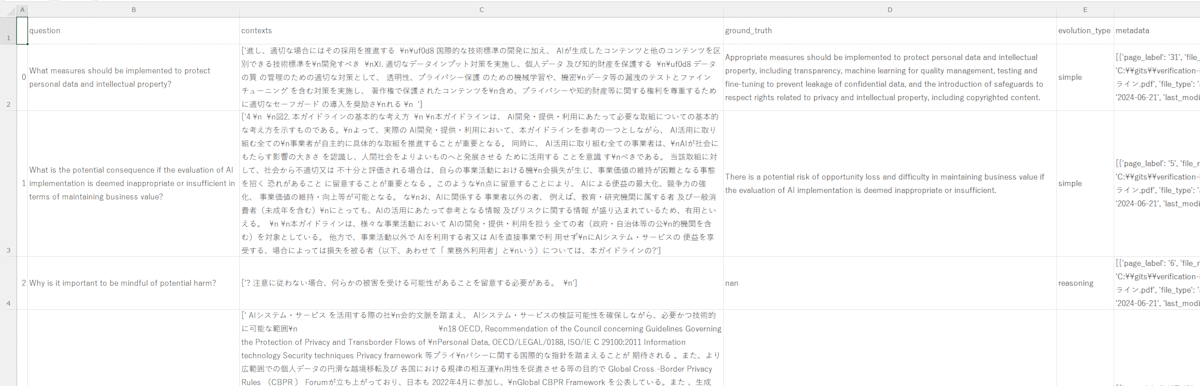
評価の実行
用意した評価用データセットで実際に評価します。
import os
import dotenv
import openai
import pandas as pd
from llama_index.core import (
StorageContext,
load_index_from_storage,
)
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from ragas.integrations.llama_index import evaluate
from ragas.metrics import (
answer_relevancy,
context_precision,
context_recall,
faithfulness,
)
def main():
storage_context = StorageContext.from_defaults(persist_dir="index_storage")
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
metrics = [
faithfulness,
answer_relevancy,
context_precision,
context_recall,
]
df = pd.read_csv("testset_df.csv")
data_dict = {
"question": df["question"].astype(str).tolist(),
"ground_truth": df["ground_truth"].astype(str).tolist(),
"contexts": df["contexts"].astype(str).tolist(),
}
evaluator_llm = OpenAI(model="gpt-4")
result = evaluate(
query_engine=query_engine,
metrics=metrics,
dataset=data_dict,
llm=evaluator_llm,
embeddings=OpenAIEmbedding(),
)
# final scores
print(result)
result_df = result.to_pandas()
result_df.to_csv("result.csv")
結果として出力される CSV は以下です。
※非常に小さいので、お手数ですが拡大してください。
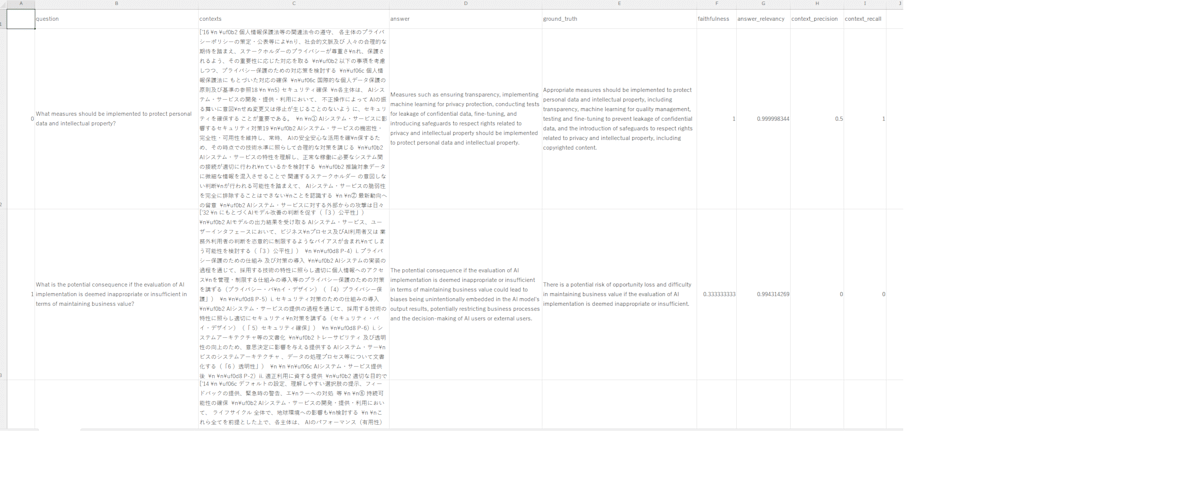
そして、print(result)で標準出力に表示される結果は以下です。
{'faithfulness': 0.6667, 'answer_relevancy': 0.9618, 'context_precision': 0.1000, 'context_recall': 0.5000}
これは、評価用データ 5 つに対する結果の算術平均です。
これらの指標がどのように計算されているか簡単に解説していきます。
各指標の解説
繰り返しになってしまいますが、
RAG における評価は、検索の部分と回答生成の部分の大きく 2 つに分けられるのでした。
そしてそれぞれ 2 つずつ指標をピックアップしました。
-
Retrieval
- Context Precision
- 質問の回答に必要な情報(コンテキスト)を LLM がどの程度正確に取得しているか
- Context Recall
- 取得したコンテキストがどの程度 Ground Truth(正しい回答)と一致しているか
- Context Precision
-
Generation
- Faithfulness
- 取得したコンテキストに関連した情報を LLM がどの程度返しているか
- Answer Relevancy
- 生成された回答が元の質問にどれだけ関連しているか
- Faithfulness
上記 4 つを順番に紹介していきます。
なお、いずれの指標も 0~1 の値を取り、高いほど結果が良いことを表しています。
Context Precision
Context Precision は、質問への回答に必要な情報(コンテキスト)を LLM がどの程度正確に取得しているかを測る指標です。
計算式は以下の通りです。

-
Kは、コンテキスト(チャンク)の総数を表します。 -
vは、順位kにおける関連性の指標で、0 または 1 の値をとります。0 は関連性がなく、1 は関連性があることを示します。
RAGAS の公式ドキュメントにある具体例を日本語訳しながら解説します。
質問: フランスはどこにあり、首都はどこですか?
真の回答(Ground truth): フランスは西ヨーロッパにあり、首都はパリです。
この質問に対して、以下 2 つのコンテキストが返ってきたとします。
- コンテキスト 1:「この国は、ワインと洗練された料理でも有名です。ラスコーの古代の洞窟壁画、リヨンのローマ劇場」
- 関連性がない
- コンテキスト 2:「フランスは西ヨーロッパにあり、中世の街並み、アルプスの村々、地中海のビーチなどがあります。首都のパリは、ファッションハウス、ルーブル美術館などの古典美術館、エッフェル塔などのモニュメントで有名です。」
- 関連性がある
そのうえで、以下の流れで算出されます。
- 関連性の判定
- 検索結果の各文章について、質問「フランスはどこにあり、首都はどこですか?」に関連する情報を含んでいるかどうかを判定します。
- Precision@k の算出
- 各順位における Precision@k を計算します。
- Precision@1 は 1 番目のコンテキストのみ考慮します。関連するコンテキストは 0 個、関連しないコンテキストは 1 個であるため、Precision@1 は
0/1 = 0 - Precision@2 は 2 番目のコンテキストまでを考慮します。関連するコンテキストは 1 個、関連しないコンテキストは 1 個なので、Precision@2 は
1/2 = 0.5
- Context Precision の算出
- 全てのコンテキストの Precision@k の平均値を計算し、最終的な Context Precision を算出します。
- 今回の例では、Context Precision は以下の計算で 0.5 になります。

Context Recall
Context Recall は、 取得したコンテキストがどの程度 Ground Truth(真の回答)と一致しているかを測る指標です。
具体的には、以下の流れで算出されます。
- Ground Truth を文章単位で分解
- 分解された文章(ステートメント)とコンテキストとの関連を LLM で判定(Yes / No)
- コンテキストに関連するステートメントの数を、ステートメントの合計数で除算
公式ドキュメントにある具体例を日本語訳しながら解説します。
質問: フランスはどこにあり、首都はどこですか?
Ground truth: フランスは西ヨーロッパにあり、首都はパリです。
「フランスはどこにあり、首都はどこですか?」に対して、以下のコンテキストを取得しました。
西ヨーロッパに位置するフランスは、中世の街並み、アルプスの村々、地中海のビーチを擁している。ワインや洗練された料理でも有名だ。ラスコーの古代洞窟壁画、リヨンのローマ劇場、広大なヴェルサイユ宮殿は、その豊かな歴史を証明している。
Ground truth は 2 つの文章(ステートメント)に分解されます。
- ステートメント 1: フランスは西ヨーロッパにある
- ステートメント 2: 首都はパリです
この 2 つのステートメントと、取得されたコンテキストの関連をチェックすると、
1 つ目は関連アリと判断され、2 つ目は関連ナシと判断されます。
よって、context recall は以下の計算で 0.5 になります。

Faithfulness
Faithfulness は、質問の回答に必要な情報(コンテキスト)を、LLM がどの程度正確に取得しているかを測る指標です。
具体的には、以下の流れで算出されます。
- 質問と回答のセットから、回答をいくつかの単純な文章(ステートメント)に分解
- コンテキストとステートメントの関連性を LLM で判定(Yes / No)
- 関連性があると判断されたステートメントの数を全ステートメントの数で除算
計算式は以下の通りです。

公式ドキュメントの例で具体的に紹介すると、以下の通りです。
質問: アインシュタインが生まれた場所と、生まれた年を教えてください
コンテキスト: アルバート・アインシュタイン(1879年3月14日生まれ)は、ドイツ生まれの理論物理学者で、史上最も偉大で影響力のある科学者の一人と広く認識されています。
回答: アインシュタインは1879年3月20日にドイツで生まれました。(この回答は、日付が誤っている)
この回答を以下の 2 つに分解します。
- ステートメント 1: アインシュタインはドイツで生まれました
- ステートメント 2: アインシュタインは 1879 年 3 月 20 日に生まれました
この 2 つのステートメントをコンテキストと突き合わせて、
関連性を Yes/No で判断します。ステートメント 1 は Yes、ステートメント 2 は間違っているので No です。
よって faithfulness は、以下の計算で 0.5 となります。

Answer Relevancy
Answer Relevancy は、生成された回答が元の質問にどれだけ関連しているかを測る指標です。
具体的には、以下の流れで算出されます。
- コンテキストと生成された回答から、疑似的な質問を LLM で生成
- 「元の質問」と「疑似的な質問」のコサイン類似度を計算
- 類似度の平均を計算
生成された回答が元の質問に正確に対応しているならば、
その回答から生成された疑似質問と元の質問は内容が近くなるよね。といった考えです。
コサイン類似度などが絡んでくるので解説は割愛しますが、以下のような数式で表されます。
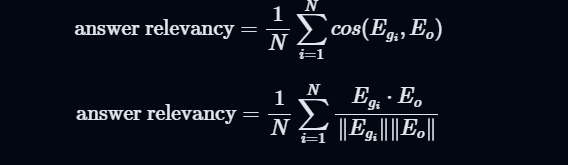
公式ドキュメント
公式ドキュメントを参照しました。こちらでは、ほかの指標含めて紹介されています。
まとめ
RAGAS の解説のパートが長くなってしまいましたが、
RAG の一連の流れを LlamaIndex の基礎的な内容で手を動かしながら試してみました。
ここからは、Google Cloud のサービスを用いてアレンジしていきます。
LlamaIndex から Vertex AI Vector Search を使う
Vertex AI Vector Search にインデックスを作成し、LlamaIndex からクエリを投げてみましょう。
ただその前に、Vertex AI Vector Search について簡単に解説します。
Vertex AI Vector Search とは
Vertex AI Vector Search(旧 Vertex AI Matching Engine)とは、
Google Cloud が提供する近似最近傍探索(ANN: Approximate Nearest Neighbor) を実行するためのサービスです。
つまり、ベクトル検索のためのものです。
ScaNNというアルゴリズムによって、高い再現率と低レイテンシを実現していることなどが特徴です(他にも色々特徴があります)。
Vertex AI Vector Search は以下のステップで使用します。
- テキストのチャンク化
- エンベディングを生成、形式を整え、Cloud Storage にアップロード
- Vector Search のインデックス、インデックスエンドポイント作成からデプロイ
順番にやっていきます。
テキストのチャンク化
エンベディングを生成するためにはまず、基本的にはデータをテキスト化する必要があります。
色々な方法がありますが、今回はマルチモーダル LLM(Gemini Pro 1.5 Flash)で PDF を文字起こしします。
文字起こししたテキストをチャンク化し、エンベディングを生成します。
Google Cloud には Document AI という PDF をパースできるサービスもありますが、
今回は検証ということで、LLM にぶん投げるという脳死でやれる方法を選びました。
先ほどまで使っていた AI 事業者ガイドラインの PDF(35 ページ分)のテキストすべての出力はできなかったので、
PDF を 4 分割して順番にインプットします。
PDF の 4 分割は手動でやります。
PDF ファイルを開いて「Ctrl + p」コマンドで「PDF として保存」を選び、
「1-10」、「11-20」、「21-30」、「31-」のページでそれぞれ保存します。
├── data
├── AI事業者ガイドライン_1.pdf
├── AI事業者ガイドライン_2.pdf
├── AI事業者ガイドライン_3.pdf
└── AI事業者ガイドライン_4.pdf
├── index_storage
├── venv
├──...
次に、Gemini Pro 1.5 Flash で 4 つの PDF をパース(読み取り)し、
500 文字でチャンク化して json ファイルに一旦保存します。
まずライブラリのインストールをし、Google Cloud のコンソールから Vertex AI の API を有効化します。
pip install --upgrade google-cloud-aiplatform
以下のコードを実行します。
project_id = "YOUR_PROJECT_ID"の箇所だけ修正してください。
import json
import os
import vertexai
from vertexai.generative_models import GenerativeModel, Part
def load_json_with_fallback_encoding(file_path, primary="utf-8", fallback="cp932"):
try:
with open(file_path, "r", encoding=primary) as f:
return json.load(f)
except UnicodeDecodeError:
with open(file_path, "r", encoding=fallback) as f:
return json.load(f)
def main():
project_id = "YOUR_PROJECT_ID"
vertexai.init(project=project_id, location="us-central1")
generation_config = {"temperature": 0, "top_p": 0}
model = GenerativeModel(
model_name="gemini-1.5-flash-001", generation_config=generation_config
)
folder_path = "./data"
input_mime_type = "application/pdf" # Refer to https://cloud.google.com/document-ai/docs/file-types for supported file types
for i, filename in enumerate(os.listdir(folder_path)):
file_path = os.path.join(folder_path, filename)
if os.path.isfile(file_path):
with open(file_path, "rb") as f:
image_file = Part.from_data(f.read(), input_mime_type)
prompt = "PDFファイルに書かれているテキストすべてを一言一句違わず読み取ってください。文意の補足などは不要です。図が挿入されている場合は、図の内容を説明してください。"
response = model.generate_content([image_file, prompt])
output_file_path = f"./output/chunked_text_{i}.json"
chunk_size = 500
chunked_text_list = [
response.text[i : i + chunk_size]
for i in range(0, len(response.text), chunk_size)
]
existing_data = {}
existing_data["chunked_text"] = chunked_text_list
with open(output_file_path, "w", encoding="utf-8") as f:
json.dump(existing_data, f, indent=4, ensure_ascii=False)
エンベディングを生成、形式を整え、Cloud Storage にアップロード
チャンク化したテキストをベクトル化(エンベディングの生成)し、
エンベディングを Vertex AI Vector Search のインデックスに対応する JSON に変換します。
そして、Cloud Storage にアップロードします。
アップロード先の Cloud Storage バケットの作成は各自お願いします。
手順がわからない方は公式ドキュメントをご覧ください。なお、location はus-central1で作成ください。
import json
import os
import uuid
import vertexai
from google.cloud import storage
from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel
project_id = "YOUR_PROJECT_ID"
region = "us-central1"
model_name = "textembedding-gecko-multilingual@001"
bucket_name = "YOUR_BUCKET_NAME"
def load_json_with_fallback_encoding(file_path, primary="utf-8", fallback="cp932"):
try:
with open(file_path, "r", encoding=primary) as f:
return json.load(f)
except UnicodeDecodeError:
with open(file_path, "r", encoding=fallback) as f:
return json.load(f)
def main():
folder_path = "./output"
for i, filename in enumerate(os.listdir(folder_path)):
file_path = os.path.join(folder_path, filename)
existing_data = load_json_with_fallback_encoding(file_path)
vertexai.init(project=project_id, location=region)
task = "RETRIEVAL_DOCUMENT"
model = TextEmbeddingModel.from_pretrained(model_name)
texts = existing_data["chunked_text"]
inputs = [TextEmbeddingInput(text, task) for text in texts]
embeddings = model.get_embeddings(inputs)
embed_text_list = []
for embedding in embeddings:
embed_text_list.append(embedding.values)
converted_data = [
{
"id": str(uuid.uuid4()),
"text": text,
"embedding": embedding,
}
for i, (text, embedding) in enumerate(zip(texts, embed_text_list))
]
output_folder_path = "./embs/"
output_filename = f"embs{i}.json"
output_file_path = os.path.join(output_folder_path, output_filename)
# ファイルに書き込む
with open(output_file_path, "w", encoding="utf-8") as f:
for item in converted_data:
json_line = json.dumps(item, ensure_ascii=False)
f.write(json_line + "\n")
# ファイルをCloud Storageにアップロード
source_file_name = output_file_path
destination_blob_name = output_filename
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(source_file_name)
なお、Cloud Storage にアップロードする JSON のデータはこのようになっています。

拡張子は json ですが、jsonl(JSON LINES)の形式です。
そのほかインデックスの入力データに関する形式などについては、公式ドキュメントをご覧ください。
インデックス、インデックスエンドポイント作成からデプロイ
ここで先に注意ですが、デプロイまで完了された場合は、
お試し後にかならず環境のクリーンアップをお願いします。
デプロイされている間は継続して課金され、
今回のデータ量だと、1 日あたり数千~数万円になると予測されます。
クリーンアップの方法は先の項目で記載してあります。
以下のコードでクエリが投げられる状態まで完了します。
from google.cloud import aiplatform
def main():
aiplatform.init(project=project_id, location=region)
index_display_name = "vs-llamaindex-index"
bucket_uri = "gs://YOUR_BUCKET_NAME"
dimensions = 768
approximate_neighbors_count = 10
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name=index_display_name,
contents_delta_uri=bucket_uri,
dimensions=dimensions,
approximate_neighbors_count=approximate_neighbors_count,
)
# create `IndexEndpoint`
index_endpoint_display_name = "vs-llamaindex-index-endpoint"
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name=index_endpoint_display_name, public_endpoint_enabled=True
)
# deploy the Index to the Index Endpoint
deployed_index_id = "vs_deployed_1"
my_index_endpoint.deploy_index(index=my_index, deployed_index_id=deployed_index_id)
デプロイまで問題なく完了すると、以下のようなメッセージが出力されます。
※見やすいようにコメントと改行を挿入しています。
# ここからindexについての出力
Creating MatchingEngineIndex
Create MatchingEngineIndex backing LRO: projects/123456789111/locations/us-central1/indexes/1234567891112131415/operations/1518914600114847744
MatchingEngineIndex created. Resource name: projects/123456789111/locations/us-central1/indexes/1234567891112131415
To use this MatchingEngineIndex in another session:
index = aiplatform.MatchingEngineIndex('projects/123456789111/locations/us-central1/indexes/1234567891112131415')
# ここからindex endpointについての出力
Creating MatchingEngineIndexEndpoint
Create MatchingEngineIndexEndpoint backing LRO: projects/123456789111/locations/us-central1/indexEndpoints/1234567891112131415/operations/6461052241200545792
MatchingEngineIndexEndpoint created. Resource name: projects/123456789111/locations/us-central1/indexEndpoints/1234567891112131415
To use this MatchingEngineIndexEndpoint in another session:
index_endpoint = aiplatform.MatchingEngineIndexEndpoint('projects/123456789111/locations/us-central1/indexEndpoints/1234567891112131415')
# ここからindex endpointへのindexのデプロイについての出力
Deploying index MatchingEngineIndexEndpoint index_endpoint: projects/123456789111/locations/us-central1/indexEndpoints/1234567891112131415
Deploy index MatchingEngineIndexEndpoint index_endpoint backing LRO: projects/123456789111/locations/us-central1/indexEndpoints/1234567891112131415/operations/4176038380263440384
MatchingEngineIndexEndpoint index_endpoint Deployed index. Resource name: projects/123456789111/locations/us-central1/indexEndpoints/1234567891112131415
なお、AI 事業者ガイドラインの PDF で試されている場合は、
インデックス作成からインデックスエンドポイント作成、
そしてインデックスのデプロイまでの一連の工程に約 1 時間半かかります。
その間に、Vertex AI Vector Search の公式ドキュメントなどを読んで理解を深めてみてください。
- 補足
空のインデックスを作成した後に、チャンクされたテキストだけを用意すれば LlamaIndex からインデックスに登録できます。
こちらの方が楽ですが、おそらく日本語のテキストであることが原因でうまくいかなかったので紹介しませんでした。
# setup storage
vector_store = VertexAIVectorStore(
project_id=PROJECT_ID,
region=REGION,
index_id=vs_index.resource_name,
endpoint_id=vs_endpoint.resource_name,
gcs_bucket_name=GCS_BUCKET_NAME,
)
# configure embedding model
embed_model = VertexTextEmbedding(
model_name="textembedding-gecko@003",
project=PROJECT_ID,
location=REGION,
)
# setup the index/query process, ie the embedding model (and completion if used)
Settings.embed_model = embed_model
# Input texts
texts = [
"The cat sat on",
"the mat.",
"I like to",
"eat pizza for",
"dinner.",
"The sun sets",
"in the west.",
]
nodes = [
TextNode(text=text, embedding=embed_model.get_text_embedding(text))
for text in texts
]
vector_store.add(nodes)
クエリ
インデックスエンドポイントにインデックスがデプロイできたら、
LlamaIndex からクエリを投げます。
まず、必要なライブラリをインストールしておきます。
pip install llama-index llama-index-vector-stores-vertexaivectorsearch llama-index-llms-vertex
そして以下のコードを実行します。
import json
import os
from google.cloud import aiplatform
from llama_index.core import Settings, VectorStoreIndex
from llama_index.embeddings.vertex import VertexTextEmbedding
from llama_index.vector_stores.vertexaivectorsearch import VertexAIVectorStore
project_id = "YOUR_PROJECT_ID"
region = "us-central1"
model_name = "textembedding-gecko-multilingual@001"
gcs_bucket_name = "YOUR_BUCKET_NAME"
def load_texts_from_json_files(directory):
texts = []
for filename in os.listdir(directory):
if filename.endswith(".json"):
filepath = os.path.join(directory, filename)
with open(
filepath,
"r",
encoding="utf-8",
) as file:
data = json.load(file)
texts.append(data["chunked_text"])
return texts
def main():
text = {}
embs = {}
for filename in os.listdir("embs"):
if filename.endswith(".json"):
filepath = os.path.join("embs", filename)
with open(filepath, "r", encoding="utf-8") as f:
for line in f.readlines():
# JSONデータの解析
p = json.loads(line)
id = p["id"]
# 辞書へのデータの格納
text[id] = p["text"]
embs[id] = p["embedding"]
# indexの名前ではなく、idを指定する
vs_index = aiplatform.MatchingEngineIndex(index_name="123456789101112")
# 同じくendpointの名前ではなく、idを指定する
vs_endpoint = aiplatform.MatchingEngineIndexEndpoint(
index_endpoint_name="123456789101112"
)
vector_store = VertexAIVectorStore(
project_id=project_id,
region=region,
index_id=vs_index.resource_name,
endpoint_id=vs_endpoint.resource_name,
gcs_bucket_name=gcs_bucket_name,
)
embed_model = VertexTextEmbedding(
model_name=model_name,
project=project_id,
location=region,
)
Settings.embed_model = embed_model
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store, embed_model=embed_model
)
retriever = index.as_retriever()
response = retriever.retrieve(
"AI利用者がAIシステム・サービスを利用する際に重要なことは何ですか?日本語で回答お願いします。"
)
for row in response:
print(f"Score: {row.get_score():.3f} text: {text[row.node.id_]}")
以下のように出力されます。
Score: 0.853 text: ) ~XI)
適切な範囲で遵守すべきである
• XII)
遵守すべきである
33
第5部 AI利用者に関する事項
AI 利用者は、AI提供者から安全安心で信頼できる AI システム・サービスの提供を受け、AI 提供者が意図し
た範囲内で継続的に適正利用及び必要に応じて AI システムの運用を行うことが重要である。これにより業務効
率化、生産性・創造性の向上等 AI によるイノベーションの最大の恩恵を受けることが可能となる。また、人間の
判断を介在させることにより、人間の尊厳及び自律を守りながら予期せぬ事故を防ぐことも可能となる。
AI 利用者は、社会又はステークホルダーからAIの能力又は出力結果に関して説明を求められた場合、AI
提供者等のサポートを得てその要望に応え理解を得ることが期待され、より効果的な AI利用のために必要な知
見習得も期待される。
以下にAI 利用者にとって、重要な事項を挙げる。
• ● AI システム・サービス利用時
U-2)i. 安全を考慮した適正利用
◇ AI 提供者が定めた利用上の留意点を遵守して、AI提供者が設計において想定した範囲内で
AI システム・
問いに対して必要なコンテキストを取得してくれていそうです。
今回はあくまで retriever を使ってコンテキストを取得しましたが、
以下のようにすれば問いに対する LLM からの回答も取得できます。
query_engine = index.as_query_engine()
response = query_engine.query(
"AI利用者がAIシステム・サービスを利用する際に重要なことは何ですか?日本語で回答お願いします。"
)
print(response)
ここまで使用した LlamaIndex と Vertex AI Vector Search のコードについては、
LlamaIndex の公式ドキュメントを参照しました。
また、エンベディング生成の際のモデルを OpenAI のものから Google Cloud のものにしれっと変えています。
詳しい使い方などは以下のあたりをご覧ください。
※重要※ 環境のクリーンアップ
最後に、使用したサービスを忘れずに停止、削除してください。
Vertex AI Vector Search はインデックスがデプロイされている限り継続して課金されます。
(今回のデータ量だと 1 日で数千~数万円かかると推測されます。)
# delete Index Endpoint
my_index_endpoint.undeploy_all()
my_index_endpoint.delete(force = True)
# delete Index
my_index.delete()
gsutil rm -r {YOUR_BUCKET_URI}
参照: Vertex AI Vector Search の料金体系について
この記事のまとめ
LlamaIndex というフレームワークを通じて RAG の仕組みの理解を深めると同時に、
マネージドサービスである Vertex AI Search が裏側で行っていることの多さにも気づけました。
LlamaIndex は Vertex AI からも使用できるようになっているため、Google Cloud では LlamaIndex が Vertex AI に統合されたものが提供されているため、それも次回以降の記事でご紹介します。
Discussion