OLAPDBのパターンと工夫
はじめに
この記事はいくつかのOLAPDBの特徴をまとめたものです。
作ったり比較したりするときに、どんな特徴があるか把握しやすくすることを目的としています。
参考DB一覧
この記事は以下のDBを参考に作成しています。
※ 筆者の好みでDBを選んでいるため、中立・網羅性はありません。
Apache Druid
A high performance, real-time analytics database that delivers sub-second queries on streaming and batch data at scale and under load.
リアルタイム分析用DB。
OSS化: 2012年
Apache Pinot
Insights, Unlocked in Real Time.
Apache Pinot: The real-time analytics open source platform for lightning-fast insights, effortless scaling, and cost-effective data-driven decisions.
LinkedInから生まれた、リアルタイム分析用DB。
OSS化: 2015年
Trino
Trino, a query engine that runs at ludicrous speed
Fast distributed SQL query engine for big data analytics that helps you explore your data universe.
複数ソースへのアクセスに特化した分散クエリエンジン。かつてはPrestoと呼ばれていた。
OSS化(Presto): 2013年
フォーク(Prestoから): 2019年
Apache Doris
Open Source, Real-Time Data Warehouse
Apache Doris is a modern data warehouse for real-time analytics. It delivers lightning-fast analytics on real-time data at scale.
百度(Baidu)から生まれたデータウェアハウス。
OSS化: 2017年
StarRocks
Fast, Fresh, and Flexible: Analytics With No Compromise
An Open-Source, High-Performance Analytical Database
Apache Dorisのフォーク。コードはほとんど書き換えられているらしい。
フォーク: 2020年
Databend
Unlock Lightning-Fast Data Ingestion and Query Speed
Databend is a High-Performance/Cost-Effective/Flexibly-Designed Cloud Data Warehouse saving 50% on costs over Snowflake.
Snowflake対抗を押し出したデータウェアハウス。
OSS化: 2021年
共通した特徴
OLAPという目的のため、各DBにはある程度共通して見られる特徴があります。
1. 複数サーバーで並列に計算する
OLAPDBはテラバイト・ペタバイト級のデータを処理することを想定しているため、処理を分散して複数サーバーで並列に計算します。
2. 列志向フォーマットを採用している
必要な列だけを効率的に取得することができる、SIMDで高速化できる、などの理由から、多くの場合列志向でデータを保持しています。
ただし、高頻度にデータが追加される場合には列志向のファイルを生成するコストが高くなるので、「まず行志向でデータを保存(追記)して、後で列志向に変換する」という処理もよくあります。特にストリーミングでは顕著です。
また、テーブルごとに1つのファイルを作るのではなく、複数ファイルに分けて保存することも一般的です。
3. オブジェクトストレージを利用している
S3やMinIOなど、各種オブジェクトストレージに対応していることが多いです。
一方で、オブジェクトストレージの遅さから、キャッシュなど、アクセス回数を減らす工夫があることも一般的です。
4. ストリーミングに対応している
内容に差はあっても、「ストリーミングに対応している」ことを大きくアピールしているDBが多いです。
特にKafka。
ストリーミングなデータを直接投入することはできなくても、Kafkaには対応しています。
Kafkaと連携できることにはかなりのニーズを感じます。
各DBのアーキテクチャの特徴
OLAPDBはクラスタとして動くので、複数のサービスがあります。
サービスの分け方やアーキテクチャの設計はDBの重要な工夫ポイントで、各DBそれぞれに工夫があるため、DBごとに特徴をまとめます。
※ サービスという言葉以外にもコンポーネントやレイヤーなどの呼び方がありますが、この記事ではサービスに統一しています。
Apache Druid
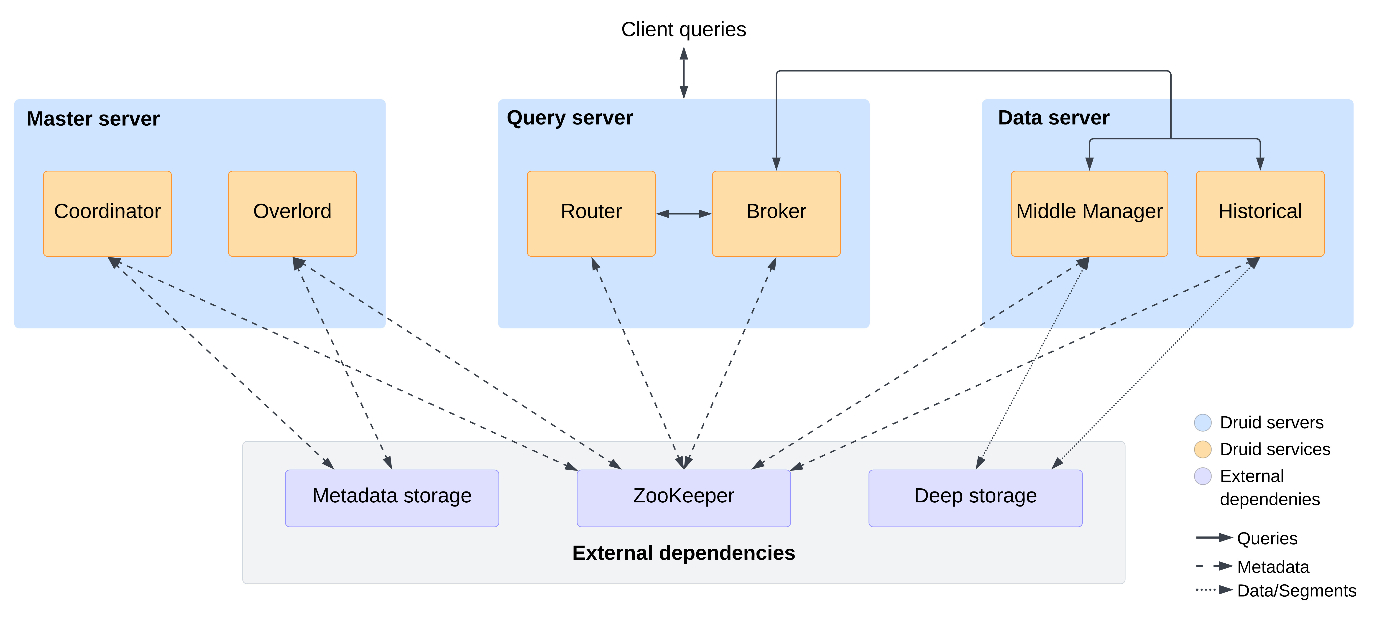
https://druid.apache.org/docs/latest/design/architecture
Druidは多くのサービスを持ち、階層もあるのが特徴です。
- Query server
- Broker: SQLの実行計画を作成し、各Historicalに命令を出すサービス。
- Router: BrokerやCoordinator、Overlordに処理を回すサービス。クエリの内容によってBrokerを変えることで優先度を付ける役割もある。
- Data server
- Historical: ローカルにデータを持つサービス。自身が持つデータを使って計算をする役割もある。
- Middle Manager: データの取り込み処理を担当するサービス。(indexerというサービスに代替されることもある)
- Master server
- Coordinator: データを適切に管理するためのサービス。Historicalサービスの持つデータをバランシングしたり、古いデータを削除したりする。
- Overlord: データ取り込み用タスクなど、タスクを管理するサービス。
- その他
- Metadata storage: 設定やデータ情報など、いわゆる"メタデータ"を持つ。PostgreSQLやMySQLなどが使われる。
- Zookeeper: そのままZooKeeper
- Deep Storage: オブジェクトストレージの層。すべてのデータが入っている。HistoricalはDeepStorageからデータを取得してローカルに保存する。
DBの特徴として重要なのはHistoricalです。
Historical用サーバーがローカルにデータを持っているため計算が速くなります。
また、サービスごとに別サーバーを割り当てることができるので、負荷に応じた柔軟性が高くなっています。
Apache Pinot

https://docs.pinot.apache.org/basics/concepts/components
PinotはBrokerとServerが中心です。
- Broker: SQLを受け取って、実行計画を作り、各Serverに命令を出すサービス。
- Server: データをローカルに持つサービス。保持しているデータに対するクエリを処理します。 offline serverとreal-time serverという区別がありますが、処理内容は変わりません。
- Segment Store: データ(segment)の置き場所。オブジェクトストレージやHDFSです。
- Controller: クラスター管理のサービス。Apache Helixとして動きます。
- Minion: バックグラウンドで動くタスクです。定期的な取り込みやコンパクションをします。
Pinotで重要なのはServerです。
DruidのHistoricalと同じように、ローカルにデータを持つことで計算速度を上げています。つまり、Serverが多いほど速くなります。
また、Pinotには2種類のクエリエンジンがあり、single-stage query engine(v1) だと処理するServerを決めるだけですが、multi-stage query engine(v2)は複雑な実行計画を作れます。
Trino

https://docs.starburst.io/introduction/architecture.html
Trinoの最大の特徴は、独自のストレージを持たないことです。
- Coordinator: クライアントからSQLを受け取って処理するサービス。またクラスター管理もします
- Worker: データを取得して計算するサービス。
独自のストレージはありません。
外部のDBやオブジェクトストレージからデータを取得して計算します。
Apache Doris

https://doris.apache.org/docs/gettingStarted/what-is-apache-doris
Dorisは主に2つのサービスで動いています。
- Frontend: クライアントからSQLを受け取って処理するサービス。クラスター管理やリーダー選出も行います。
- Backend: データの置き場となるサービス。クエリの処理も行います。
クラスターやメタデータの管理の仕事をFrontendが行うことでシンプルな役割分担になっています。
データはBackendに保存されています。
また、TieredStorageを使うとデータをオブジェクトストレージに置くようにすることができるようです。
さらに、レイクハウスとしてIcebergなどに接続することもできるので、参照だけであればかなり広い範囲のデータにアクセスできます。
StarRocks
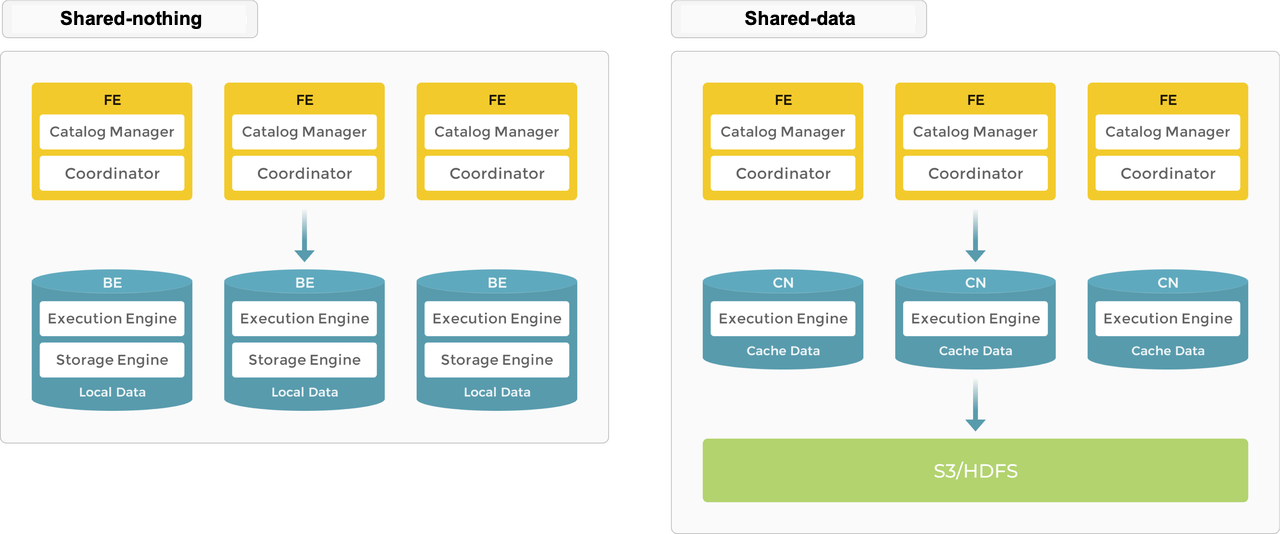
https://docs.starrocks.io/docs/introduction/Architecture/
フォーク元のDorisと似ているものの、StarRocksには2つのモードが用意されています。
- Shared-nothing
- FE(frontend): メタデータ管理と実行計画作成を担当するサービス。
- BE(backend): データの置き場となるサービス。クエリの処理も行います。
- Shared-data
- FE: メタデータ管理と実行計画作成を担当するサービス。
- CN(compute node): クエリの処理をするサービス。キャッシュも持ちます。
- 外部ストレージ: データの置き場です。
Shared-nothingの方が高速ですが、Shared-dataはデータ移動が不要なため、計算用ノードの追加が簡単になります。
また、レイクハウスとしてIcebergなどに接続することもできます。
Databend

https://docs.databend.com/guides/products/dc/architecture
Databendはオブジェクトストレージを基盤にしたアーキテクチャです。
- Meta-Service: クラスタやユーザー情報などのメタデータ管理を担当するサービス。
- Compute: SQLの実行計画作成から実行まで行うサービス。
- Storage: データをオブジェクトストレージに保存するサービス。保存時にインデックス作成なども行います。
図にはありませんが、データ本体はオブジェクトストレージに置かれています。
また、レイクハウスとしても動きます。
ちなみに、ストレージエンジンの名前はFuseです。
以上、アーキテクチャの特徴でした。
他の特徴は分類しやすいので、以降はパターンごとに紹介します。
データに関するパターン
OLAPDBはデータの持ち方でいくつかのパターンに分けられます。
保存場所のパターン
計算に利用するデータをどこに置くかでパターン分けすることができます。
| 種類 | 概要 | DB例 |
|---|---|---|
| オブジェクトストレージメイン | オブジェクトストレージを使うことで耐障害性が上がりますが、アクセスは遅くなります | Trino, Databend |
| ローカルメイン | ローカルにデータを置くことで転送が不要になり計算が高速化します。 オブジェクトストレージにもデータを置けるDBでも、データはローカルにあることを前提としています |
Druid, Pinot |
| ストレージクラスタ | オブジェクトストレージを使わず、自前でストレージクラスタを持つパターン。 データが存在するノードで計算できるのでデータ移動がなく速いです。 オブジェクトストレージを使う方法が用意されていることも。 |
Doris, StarRocks |
耐障害性・速度・コストを考慮してオブジェクトストレージの利用度合いが変わっている印象です。
アクセス頻度の高いデータを"hot"としてローカルに置き、頻度が低いものは"cold"としてオブジェクトストレージなど遅いストレージに移動するようになっていることもあります。(tiered storage)
データフォーマット
ストレージに保存するファイルのフォーマットにも違いがあります。
| 種類 | 概要 | DB例 |
|---|---|---|
| 独自フォーマット | 独自のフォーマットでデータを保存するパターン | Druid, Pinot, Doris, StarRocks |
| OSSフォーマット (Parquet, Arrow など) |
普及しているフォーマットに変換して保存するパターン | Databend |
| ユーザーのファイルをそのまま利用 | ユーザーが作ったファイルをそのまま利用するパターン。 ユーザーによる最適化余地が多いものの、ユーザーに要求する知識も増えます |
Trino |
高速化のための工夫
OLAPDBにおいて、速度は常に重要な項目であるため、様々な工夫が存在します。
この章では代表的な工夫を一覧します。
クエリ実行時の工夫
クエリ実行時に行われる工夫です。
| 工夫 | 概要 |
|---|---|
| リソース制御 | 優先度の高いクエリにより多くのサーバー・リソースを割り当てる工夫。 (例: 直近1週間は素早く見たい。広告関係は速く処理したい) |
| 近似集計 | 近似値を計算するアルゴリズムを使用することで、処理時間・メモリ使用量を削減する工夫。 (例:hyperloglog, t-digest) |
| マテリアライズドビュー | マテリアライズドビューは定期的に更新されたり、データ更新時に一緒に更新されたりします。 マテリアライズドビューをSQLで直接指定しなくても、自動でマテリアライズドビューが利用されるようになる便利機能があることも。 |
| プリペアドステートメント | SQLのパース時間が削減されます。 |
| キャッシュ | クエリ結果をキャッシュすると計算自体を省略できます。 |
バックグラウンド処理
バックグラウンドで追加処理を行うことで、クエリが速くなります。
| 工夫 | 概要 |
|---|---|
| コンパクション | 複数の小さなファイルを1つにまとめる処理です。 小さいファイルが大量にあるせいで処理が遅くなるのを防ぎます。 時間やファイルサイズ・数などを基に処理が走ります。 |
| 事前集計 | 定期的に指定した計算の結果を収集することで、クエリ実行時の計算を省略します。 データ取り込み時に更新するものも。 |
| 統計情報収集 | 統計情報を利用してクエリの最適化を図ることができます。 |
取り込み時の工夫
データを取り込む時に、追加で処理を行うことで、計算時の負荷を減らす工夫は多くあります。
パーティション
大量のデータを処理するとき、不要なファイルにはアクセスしないことが重要です。
パーティションを使うと、ファイルの要否が簡単に判断できます。
パーティションの基準はユーザーが設定することが基本ですが、自動で対応するDBもあります。
自動の場合は時間が使われることが多いです。
データ変換
データ取り込み時に集計をしたり、値を変換して格納したりすると、必要な処理が減り速くなります。
既存の集計があれば、集計は合算されます。
また、JSONの値を別の列として抜き出しておくと、クエリ実行時にJSONのパースが必要なくなり、速くなります。
インデックス
インデックスはかなり色々あります。以下は気になったものです。
- ビットマップインデックス
- ブルームフィルター
- FST
- 空間インデックス
- 転置インデックス
- ベクトルインデックス
- N-gram
- star-tree index (Apache Pinot独自のインデックス。詳細)
おわりに
以上、OLAPDBの特徴と工夫のまとめでした。
OLAPDBや類似のシステムは他にも多く存在しますが、体力が切れたのでここまでにします。
この記事で紹介されていない工夫やパターンはたくさんあるはずなので、気になる点や追加したい内容があればコメントなどで教えてください。
Discussion