【情報収集の自動化】生成AIにRSSフィードを巡回させてみた
背景|読む記事を探している時間の肥大化
仕事やプライベートでニュースやブログ記事を大量に追いかけていると、「読む記事を探す時間ばかりかかってしまう」という悩みに直面する方も多いのではないでしょうか。僕もRSSフィードを大量に登録しているうちに、記事を探す時間が肥大化してきたことを痛感しました。
そこで今回は生成AI(LLM)を活用して、RSSフィードを自動巡回し、重要度の高そうな記事をAIが選んで通知してくれる仕組みを構築しました。現在、1日あたり約200~500記事をLLMが巡回した結果がメールで届くようになっています。
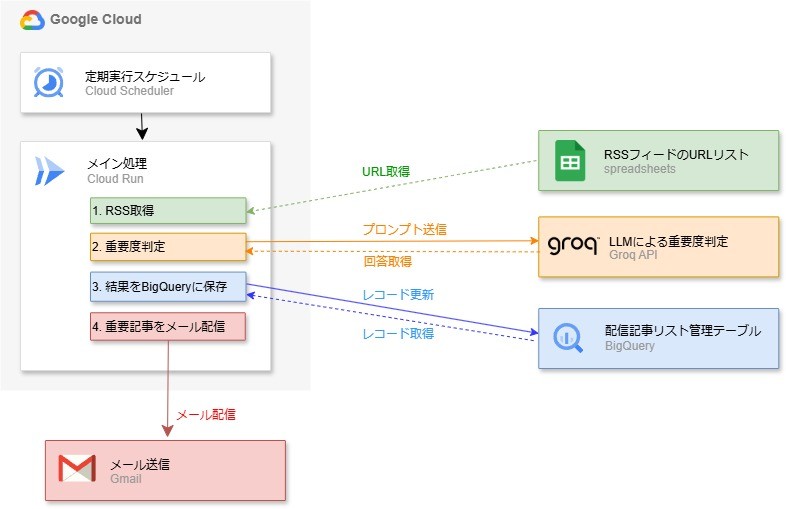
アーキテクチャ|LLM-API(Groq)とGoogleCloudによる自動処理
- RSSフィードの自動取得
- LLM-API(Groq)で記事の重要度を判定
- BigQueryへ格納・記事管理
- 重要度が高い記事だけメール配信
「巡回」という言葉を使っていますが、実際はRSSフィードに流れてきた記事を次々とAIに投げているイメージです。すべてPythonで記述しています。
Groq-APIとGoogle Cloud(BigQuery、Cloud Run)は無料枠が利用可能ですが、Cloud Runの立ち上げ回数が多い場合、わずかに課金(1日1~5円程度)が発生することがあります。僕は開発・デプロイ時に何度も試行させてしまったこともあってか、それくらいの課金を発生させてしまいました。
以下、技術&サンプルコードを紹介していきます。
1.RSSフィード一覧をスプレッドシートから取得
まず、様々なRSSフィードをまとめて取得するコードを書きます。
RSSリストはGoogleスプレッドシートに記録し、バッチ側で都度読み込む仕組みとしています。気になるサイトやキーワードを追加したいとき、スプレッドシートにURLを1行追加するだけなので運用が非常に楽です。また各種RSSフィードに加え、Googleアラートにも対応できるようにしています。
以下はサンプルコードです。
登録サイトのRSS情報を取得したら、テキストクリーニングしつつタイトル・要約・リンクを抽出し、後の工程に備えます。
ソースコード:RSSフィードの自動取得
import re
import feedparser
import hashlib
from datetime import datetime
import pandas as pd
from google.auth import default
from googleapiclient.discovery import build
# ここでスプレッドシートIDを指定
spreadsheet_id = "xxxxxxxxxxxxxxxxxxxxxxxxx"
spreadsheet_range = "rss_list!A2:A"
# スプレッドシートからRSSリスト取得する関数
def get_urls_from_spreadsheet():
# GoogleAPI認証
credentials, project = default()
service = build('sheets', 'v4', credentials=credentials)
# スプレッドシートのデータ取得
sheet = service.spreadsheets()
result = (
sheet.values()
.get(spreadsheetId=spreadsheet_id, range=spreadsheet_range)
.execute()
)
urls = result.get("values")
flat_urls = [item[0] for item in urls if item]
return flat_urls
# HTMLタグを削除する関数(補助関数)
def clean_html(text):
text_without_tags = re.sub(r'<[^>]*>', ' ', text)
cleaned_text = re.sub(r'\s+', ' ', text_without_tags)
return cleaned_text.strip()
# メイン関数
def process_rss_feed():
# スプレッドシートからRSSリストを取得
urls = get_urls_from_spreadsheet()
# RSSフィードからURLリストを取得
dfs = []
for url in urls:
try:
f = feedparser.parse(url)
entries = f.get("entries", [])
df = pd.json_normalize(entries)
except:
continue
# googleアラート用のURLを削除
df['link'] = df['link'].str.replace('https://www.google.com/url?rct=j&sa=t&url=', '')
# タイトルと要約をクリーニング
df['title'] = df['title'].astype(str).apply(clean_html)
df['summary'] = df['summary'].astype(str).apply(clean_html)
dfs.append(df)
df = pd.concat(dfs)
# 取得日時
df['get_date'] = datetime.now().strftime('%Y-%m-%d')
df['get_date'] = pd.to_datetime(df['get_date']).dt.date
# 記事識別用ID生成(ハッシュ値)
df['id'] = df.apply(
lambda row: hashlib.md5(
(str(row['title']) + str(row['link'])).encode('utf-8')
).hexdigest(),
axis=1
)
# 必要なカラムだけ抽出
df = df[['id', 'title', 'summary','link', 'get_date']]
# 採点結果・配信済フラグ管理のカラムを追加
df[['importance', 'importance_reason', 'delivered_flag']] = None
return df
# 実行
df_rss_list = process_rss_feed()
2.LLMで重要度判定させる方法(Groq-API)
取得した記事の情報をLLMに渡して「重要度スコア」を付けてもらいます。
今回はGroq APIで deepseek-r1-distill-llama-70b モデルを使用しました。
Groqとは?APIキー取得方法
- 高速AIチップによる高速応答がウリ
- deepseek-r1-distill-llama-70bは1日1000回まで無料利用可能
- 他にも複数モデルから選択可能
Groqは大規模言語モデルのトレーニング等に特化した言語処理ユニットLPU(Language Processing Unit)を発明した企業ですが、高速AIチップの開発元だけありAPIレスポンスも非常に高速という評判です。2025年2月15日現在、無料APIを提供しています。
deepseek-r1-distill-llama-70bは、DeepSeek-R1の知識を蒸留した軽量モデルであり、1日あたり1000回が無料枠となっています。
Groq APIでは他モデルも色々試せるようになっており、無料APIで提供されているモデル・無料利用可能枠は以下ページに記載されています。
Groq | レートリミット(上限)について
メモ:レート上限の用語について
TPM(Tokens Per Minute): 1分あたりに処理できるトークン数
RPM(Requests Per Minute): 1分あたりに行えるリクエスト回数
RPD(Requests Per Day): 1日あたりに行えるリクエスト回数
TPD(Tokens Per Day): 1日あたりに処理できるトークン数
APIキーは以下ページから取得します。
初回はLoginボタンから進んでアカウントを作成。
ログイン後、以下スクショのように発行ボタンを押して名前を入力とAPIキーを取得できます。
Groq | APIキー管理画面

Groq-API実装コード
以下は重要度判定させる実装コードです。
Groq公式ライブラリを使用します。
重要度は {"importance": <int>, "reason": "<string>"} の JSON 形式で出力させ、JSON をパースして取得します。
抽出の成功率を計測したところ99.6%とほぼ成功していますが、稀に失敗がありますので、再試行させるロジックを追加予定です。
ざっくりした聞き方だと大半の記事が「重要度8~10」という高得点で返ってきてしまう傾向があるため、要素ごとに部分点を付けさせる指示を入れることで、0点から10点まで細かく刻んだ分布とすることができました。
実際に運用してみると、記事によっては重要度スコアの納得感がイマイチだったり、同じような記事タイトルでもスコアにばらつきが生じたりします。しかし、多数の記事を俯瞰して優先度を付ける程度なら十分使える印象でした。プロンプトや採点ルールを微調整することで、より自分好みの結果に近づけることが可能です。
プロンプトの差し替えだけで微調整や、多ジャンル対応が可能という意味では良い点だと思います。
ソースコード:Groq-APIで重要度判定
import re
import json
from groq import Groq
# Groq API準備(実際には、APIキーは環境変数で設定してください)
groq_api_key = "your_api_key_here"
groq_model_id = "deepseek-r1-distill-llama-70b"
# 採点ルールの設定
system_instruction = """
[事業内容]を推進する[あなたのポジション]として記事概要を確認し、その記事が重要かどうか「採点ルール」に沿って判定してください。
説明は省いて結果だけ、以下で回答してください。
採点ルール:[事業内容]との関連性を0から3、[あなたのポジション]目線での重要度を0から4、現場での実践性/ハンズオン性で0から3ポイントを判定し、その合算値を以下フォーマットで記載する。
出力は必ず JSON 形式で返してください。フォーマットは以下に厳密に従うこと。
{
"importance": 1〜10 の整数,
"reason": "10文字程度の日本語理由"
}
JSON 以外は出力しないこと。
"""
# 評価対象記事の情報(サンプルです。実際には、取得してきたRSS記事リストのコンテンツを使います)
text = (
"title: 記事タイトルを記載, "
"url_domain: リンクURLの先頭15文字ほど記載, "
"summary: 記事概要を記載"
)
def evaluate_article(text):
# Groq-APIにプロンプトを投げる
client = Groq(api_key=groq_api_key)
system_prompt = {"role": "system","content": system_instruction}
user_prompt = {"role": "user", "content": text}
chat_history = [system_prompt, user_prompt]
response = client.chat.completions.create(
model=groq_model_id,
messages=chat_history,
max_tokens=10000,
temperature=0.5
)
answer = response.choices[0].message.content
answer = answer.split("</think>")[-1] if "</think>" in answer else answer
# 重要度を取得
result = json.loads(answer)
raw_importance = str(result.get("importance", "0"))
match = re.search(r"\d+", raw_importance)
score = int(match.group()) if match else 0
# 重要度の判定理由を取得
reason = str(result.get("reason", "")).strip()
return score, reason
# 実行
score, reason = evaluate_article(text)
print("重要度:", score)
print("理由:", reason)
3.BigQueryで記事リストをテーブル管理
次に、記事を格納し、同じ記事を何度も判定・配信しないようテーブル管理します。
採用したのはBigQueryです。毎月10GBストレージ・毎月1TBクエリデータ処理までは無料枠であり、今回の用途で課金対象となる事はまずありません。
あとからジャンル別対応のロジックを追加する可能性もあるため
記事をプールする動作と、重要度を入れる動作はあえて別処理にしています。
ソースコード:BigQueryへの格納
from google.cloud import bigquery
# 1. 新規記事の追加
# RSSから取得してきた記事リストをBigQueryにアップロードします
def upload_articles_to_bigquery(df, table_name):
client = bigquery.Client()
# 既にレコードを保持している記事IDは除外
query_job = client.query(f"SELECT id FROM {table_name}")
result = query_job.result()
existing_ids = result.to_dataframe()
existing_ids = set(existing_ids['id'].tolist())
df = df[~df['id'].isin(existing_ids)]
# 新規記事のみBigQueryにアップロード
job_config = bigquery.LoadJobConfig(write_disposition="WRITE_APPEND") # WRITE_TRUNCATE
job = client.load_table_from_dataframe(df, f"{table_name}", job_config=job_config)
job.result()
df_rss_list = process_rss_feed() # 前述したRSSリスト取得関数を実行
upload_articles_to_bigquery(df_rss_list, "テーブル名")
# 2. 重要度判定が済んでいないレコードの抽出
# Groq-APIで重要度判定をする対象抽出を行います
def get_without_importance(table_name):
client = bigquery.Client()
query = f"SELECT * FROM {table_name} WHERE importance IS NULL"
query_job = client.query(query)
result = query_job.result()
df = result.to_dataframe()
return df
df_without_importance = get_without_importance("テーブル名")
# 対象抽出したリストを重要度判定していく
result_list = []
for index, row in df_without_importance.iterrows():
text = 'title: ' + row['title'] + ' ,summary: ' + row['summary']
score, reason = evaluate_article(text)
print(f"ID: {row['id']}, 重要度: {score}, 理由: {reason}")
result_list.append((row['id'], score, reason))
result_df = pd.DataFrame(result_list, columns=['id', 'importance', 'importance_reason'])
df_without_importance = df_without_importance.merge(result_df, on='id', how='inner', suffixes=('_old', ''))
df_without_importance.drop(columns=['importance','importance_reason'], inplace=True)
# 3. 重要度判定済みレコードの挿入
def upload_to_bigquery(df, table_name):
client = bigquery.Client()
client.query(f"Delete From {table_name} where id in ({str(df['id'].tolist()).replace('[', '').replace(']', '')})")
job_config = bigquery.LoadJobConfig(write_disposition="WRITE_APPEND")
job = client.load_table_from_dataframe(df, table_name, job_config=job_config)
job.result()
upload_to_bigquery(df_without_importance, "テーブル名")
4.重要記事のメール配信および配信フラグ管理
こちらからアクションしなくても自然と記事に気づけるよう、メールで届く仕組みとしています。
好みの条件(例:重要度7以上、上位30件など)で記事を抽出し、メール配信させます。
送信後には送信済みフラグ(delivered_flag)を立てることで二重配信を防ぎます。
メール送信にはPythonのSMTPライブラリを使っています(こちらの記事を参考にしました)。
ソースコード:メール配信管理
# 記事対象抽出
def get_articles_to_email(table_name, limit_num):
client = bigquery.Client()
query = """
SELECT id, title, summary, link, importance, importance_reason
FROM {table_name}
WHERE delivered_flag IS NULL AND importance IS NOT NULL
ORDER BY importance DESC
LIMIT {limit_num}
"""
query_job = client.query(query)
df = query_job.result().to_dataframe()
return df
df_articles = get_articles_to_email(table_name, limit_num=30) # 上位30件を取得する場合
# PandasデータフレームをHTMLテーブルに変換
def generate_html_table(df):
rows = ""
for _, row in df.iterrows():
title_with_link = f"<a href='{row['link']}' target='_blank'>{row['title']}</a>"
summary = row['summary'][:200] if len(row['summary']) > 200 else row['summary']
rows += (
f"<tr>"
f"<td>{row['importance']}</td>"
f"<td>{row['importance_reason']}</td>"
f"<td>{title_with_link}</td>"
f"<td>{summary}</td>"
f"</tr>"
)
table_html = f"""
<table border="1" cellpadding="5" cellspacing="0">
<thead>
<tr>
<th style="width: 10%;">重要度(AI判定)</th>
<th style="width: 15%;">判定理由</th>
<th style="width: 30%;">タイトル</th>
<th style="width: 45%;">要約</th>
</tr>
</thead>
<tbody>
{rows}
</tbody>
</table>
"""
return table_html
html_table = generate_html_table(df_articles) # 取得した記事をHTMLテーブルに変換
# メール送信
def send_email(html_content):
smtp_server = "smtp.gmail.com"
port = 587
username = "your-email-address"
password = "your-password" # 実際には環境変数で
server = smtplib.SMTP(smtp_server, port)
server.starttls()
server.login(username, password)
from_email = "your-email-address"
to_email_list = ["your-email-address"]
subject = f"重要記事リスト {datetime.now().strftime('%Y/%m/%d')}"
message = MIMEMultipart("alternative")
message["From"] = from_email
message["To"] = ", ".join(to_email_list)
message["Subject"] = subject
css_style = """
<style>
table th{ background-color: #000035; color: white; text-align: center; padding: 2px 8px; }
table{ margin: 5px; border-collapse: collapse; }
table td{ border-bottom: solid black 1px; text-align: left; padding: 2px 10px; }
</style>
"""
html = f"""
<html>
<head>{css_style}</head>
<body>
<h2>RSS記事リスト - {datetime.now().strftime('%Y/%m/%d')}</h2>
RSSから取得した記事をLLMにより重要度を判定し、上位記事リストを配信しています。<br />
{html_content}
</body>
</html>
"""
part = MIMEText(html, "html")
message.attach(part)
server.sendmail(from_email, to_email_list, message.as_string())
server.quit()
send_email(html_table) # メール送信
# 送信済みフラグ更新
def update_delivered_flag(df_ids, table_name):
client = bigquery.Client()
update_query = f"""
UPDATE {table_name} SET delivered_flag = 1
WHERE id IN ({str(df_ids['id'].tolist()).replace('[', '').replace(']', '')})
"""
query_job = client.query(update_query)
query_job.result()
update_delivered_flag(df_articles, table_name) # 送信済みフラグ更新
メールを受け取るだけで、その日の重要な記事をチェックできるようになります。
あとはCloud Schedulerで定期実行すれば、完全自動でのニュース収集・配信が完成します。
結果|本文まで読みたくなる記事に出会う確率が向上
- 結果: 1日数百本の記事をとりあえずLLMに読み込ませ、重要度で並べ替えたメールを受け取れるようになりました。AIの判定精度は完璧ではないものの、本文まで読みたくなる記事に出会う確率は明確に向上しており、「なんとなく優先度が高そうな記事を逃さない」という目的では十分役立っています 。新規で気になるサイトやキーワードがあれば、RSSフィードをスプレッドシートに追加するだけで運用でき、管理コストもかなり低いです。
-
改良の余地: 本文要約の自動生成、RSS以外の情報源(SNSや特定サイトのスクレイピング)対応、UIの改善など、まだまだ出来ることは多いため、運用しながら改良していこうと考えています。また、プロンプトを変更すれば全く別ジャンルの記事でも柔軟にスコアを付けられるため、多ジャンル化も考えています。
「AIに記事の厳選を任せられるのか?」と疑う気持ちもありましたが、アウトプットされたスコアを参照するだけで目を通す記事を効率よく選べるのは、想像以上に時短に役立ちました。
様々なプロンプトで重要度がどう変わるかだけでも見ていて楽しいので、ぜひお試しください。
PS1. RSSタイトルのスクロールチェックが完全に不要になるわけではないので、私は最終的に両方を併用しています。記事タイトルをざっと見渡したい心理は完全には捨てられないですね。
PS2. 他モデル(Groq以外にGeminiも)も試したところ、個人的にはdeepseekのモデルが一番しっくりきました。ただし判定結果がモデルによって大きく変わるわけではなかったため、好みの問題かもしれません。どのLLMモデルを使っても良いと思います。
Discussion