機械学習と数理最適化を用いたプライシングアーキテクチャ : 100万 SKUをボタン1つで値付けする方法
1. はじめに
大量SKUの値付けを「人力」で回している現場には、想像以上の負荷がかかっています。競合の動きを見ながら、在庫状況を確認し、季節要因を加味して...。これを人的オペレーションで、複数人・大量SKU・常に一定水準で対応し続けるのはなかなか構築できる体制ではありません。
緻密かつスピーディな価格対応には専用AI・MAツールの開発が有効です。しかし、実際に需要予測AIからどのように価格の意思決定を自動化できるのか、技術と運用の橋渡しがイメージの湧きにくい・Webには資料の少ない分野でもあります。
そこで本記事では、これを実現するアーキテクチャ全体像、および実装の勘所・実際にPDCAを回すためのKPIをまとめていきます。実装できれば10万SKUでも、100万SKUでも値付けが可能です。ボタン1つで~というタイトルにしていますが、設計しだいでボタンすら押さずに運用する設計も可能です。
この価格設定分野のテクノロジー化はプライステックと呼ばれ、ECサイトや小売チェーンなどで活用が進んでおり、単なる自動化ではなく収益向上策として運用されています。コンビニやスーパーの割引も裏側ではプライステックが動いているほか、スポーツの観戦チケットやホテル宿泊料金では実際に収益増事例が続々と生まれていますし、価格 = 利益率を直接コントロールできる変数であることからダイナミックプライシングは経営計画にも組み込まれる重要分野となっています。
オリックスバファローズ実証実験:チケット平均販売価格は2%低下したものの、チケット販売数が17%上昇し、結果的にチケット収入額が14%上昇
コカ・コーラ自販機でダイナミックプライシング、事業利益率5%以上の450~500億円を目指していくなどの計画を盛り込んだ新中期経営計画「Vision2028」の一翼を担う
この記事で得られること
本記事では、プライステック(価格×テクノロジー)の実装方法を、以下の観点から具体的に解説します。
- 全体アーキテクチャ - 需要予測から価格決定までの5ステップ
- 実装の勘所 - 各ステップでの技術選定と注意点
- 効果測定の枠組み - PDCAを回すためのKPI設計
代表的なユースケースとして、以下のような価格戦略の自動運用が可能になります。
| ユースケース | 実施内容 | 成果例 |
|---|---|---|
| 1. 全体最適な価格戦略 | - 需要予測から価格弾力性を自動算出 - 高弾力SKUは最大30%値下げ、低感度SKUは最大15%値上げ |
全体粗利率 +1.0%、売上維持 |
| 2. 戦略的な競合対抗 | - 競合価格を5分間隔で自動取得 - 交差弾力性ベースで即時価格調整 |
粗利率を維持しながら、重要商品のシェアを確保 |
| 3. 在庫回転率の最適化 | - 商品ライフサイクル別に価格パスを設計 - 目標販売期間内の利益最大化を価格でシミュレーション |
在庫切れ/余剰リスクの最小化 |
注:本記事はベストプラクティスを約束するものではありません。各社の状況に応じて、適宜カスタマイズしていただければと思います。
2. プライステックのアーキテクチャ全体像
プライシングの意思決定は、データ収集から価格決定まで必ず5つのステップを経ます。人手による価格決定でも、担当者は無意識のうちに同様のステップを踏んでおり、この流れは普遍的なものです。
本記事では「プライステック」として、需要予測には機械学習、最適化には数理最適化ソルバーを用いる実装方法を解説していきます。

各ステップの概要は以下の通りです:
-
ステップ 1: データ収集・管理
- 需要予測や価格シミュレーションに必要なデータを収集
- バッチ処理とストリーミング処理を要件に応じて使い分け
-
ステップ 2: 需要予測モデル構築
- 価格変更による需要変動を予測するモデルを構築
- 学習済みモデルは定期的に更新
-
ステップ 3: シミュレーションデータ生成
- 様々な価格パターンでの需要予測を実施
- 価格弾力性の検証も含む
-
ステップ 4: 最適化アルゴリズムによる価格選定
- 予測結果をもとに、制約条件下で最適な価格を決定
- 個別SKUの利益最大化と全体最適のバランスを考慮
-
ステップ 5: 価格本番反映・市場動向モニタリング
- 決定された価格を実際に適用
- KPIの追跡と分析によるPDCA
以降の章では、各ステップの実装方法と注意点を詳しく解説していきます。
3. 各ステップのアーキテクチャ詳細と課題
3.1 データ収集ステップ
主に需要予測のためのデータを収集します。
需要予測モデルの構築、価格シミュレーション、効果測定などに合わせてデータを供給できるパイプラインを構築しておくのが本ステップです。
プロジェクト立ち上げ時は、以下の優先度に従って段階的にデータを整備していきます。
最終的にはPhase3まで網羅している必要があるでしょう。需要予測モデル構築時の流れに沿って箇条書きにしていますが、実際にはデータの取得難易度に応じて優先度を変更していくことが多いです。
必要なデータと優先度
Phase 1(必須): コアデータ
- 販売データ(価格・受注点数・納期)
- 価格変更履歴
- 閲覧・カート追加等の行動データ
→ まずはこれらで需要予測モデルのベースラインを構築
Phase 2(精度向上): 外部要因データ
- 競合価格データ(自動収集の仕組みが必要)
- 在庫推移データ(倉庫・店舗の統合が必要な場合も)
→ 価格弾力性の予測精度を大きく向上させる要素
Phase 3(高度化): 補完データ
- 商品マスタ(商品説明文/カテゴリ等)
- マーケティング施策情報(広告・キャンペーン)
- 季節・天候データ
- トレンド・イベント情報
→ より細かな需要変動要因を捉えるために活用
これらデータがすぐ機械学習に使える状態になっている企業はほぼ存在しないため、各所にデータ有無や使用可否を尋ねて周り、ひたすら前処理を組むという…現場では多くの時間を要する部分ですが、ここで整備しておくと後工程が非常にスムーズになります。
データ取得方法は要件に応じてバッチ処理・ストリーミング処理を使い分けます。バッチ処理ではAirflowによるDAGを用いた自動化など、ストリーミング処理の場合はKafka/Flinkを中心にしたリアルタイム処理などの導入が候補に挙がります。高度な異常値排除などの特殊な前処理が必要なケースでは、単純なデータ転送ではなく専用バッチジョブを組みます。
バッチ処理での実装例
- Apache Airflowによる日次ETL
- 販売・在庫データの集計
- 商品マスタの更新
- 異常値の検知と補正
ストリーミング処理での実装例
- Kafka/Flinkによるリアルタイム処理
- 競合価格の即時検知(数分間隔)
- 行動データのリアルタイム集計
- 価格更新の即時反映
また、データレイクと検索用データベース(主にkey-value)を分離構築していくことで、効率的なデータアクセスと検索性能を担保することができます。
3.2 需要予測モデル構築ステップ
価格を5%下げたら、販売数はどれだけ伸びるのか?
これは価格決定に携わる全ての人が直面する問いですが、特に数万SKUなど大量商品を扱う場合、各商品ごとの「値下げ効果」を人力で予測するのは現実的ではありません。そこで機械学習アプローチが重要になります。
このステップでは、過去の実績データから価格変更による需要変動を学習し、未来の売上を予測するモデルを構築します。目指すのは、「商品Aは10%値下げで1.5倍売れる」「商品Bは値下げしても売上が伸びない」といった商品固有の特性を、機械的に把握することです。
これを実現するには、以下のような価格以外の要因も含めたモデリングが必要になります:
- 商品ごとに異なる価格感応度
- 競合の価格変動による影響
- 在庫状況や季節要因の変化
価格弾力性を考慮したモデリング
モデルには価格弾力性と交差価格弾力性を明確に組み込む必要があります。
価格変更と需要の関係は、通常「価格弾力性」として表現されます。

画像引用・参考 正しく値上げするための価格弾力性分析
価格にはしきい値効果や価格競争があることから、弾力性は直線ではなく曲線を描くことが一般的です。
上記画像はイメージですが、この例では220円を境に値下げ効果が薄れており、これ以上の値下げは利益を圧迫するだけという判断ができます。このような価格と需要の非線形な関係を、機械学習モデルで自動的に学習させることが目標となります。
実務に適した機械学習手法の選定
需要予測のアプローチとしては、主に以下の手法が実績を上げています:
- 勾配ブースティング(XGBoost, LightGBM): 特徴量の重要度を明示できるため、価格感度の解釈がしやすい。特にLightGBMの"単調制約条件"パラメータが価格弾力性の矛盾解消に寄与する
- LSTM等のニューラルネットワーク: 複雑な時系列パターンの学習に強いが、計算コストが高い
- 強化学習(発展的手法): 中長期的な価格戦略の最適化に使える可能性がある
ビジネス要件として「〇時間以内に△商品数の予測ができている」というった時間的制約がある場合が多いため、学習リソースと時間リソースを考慮した手法選定が必要です。
参考1 勾配ブースティング(GBDT)について: そもそもGBDTとは / GBDTの仕組みと手順を図と具体例で直感的に理解する
参考2 LSTMについて: LSTMを使った時系列予測の実装
参考3 Alibaba・深層強化学習テスト事例: ダイナミックプライシングで強化学習を使った論文読んでみた
実際のモデル構築においては以下のような特徴や課題に留意しつつ、特徴量エンジニアリング・サンプルデータ確保を行ったうえで、Optunaなどのパラメータ探索を実施していきます。モデル評価指標についてはRMSEやMAPEで問題ありません。
特徴量エンジニアリング
価格弾力性予測では価格推移や競合価格差分指数といった特徴量の生成が精度に寄与します。
また未来の需要を予測するため、天気予報や予想来店者数をまず予測し、その予測データを特徴量として価格弾力性予測していくという二段階予測も必要です。
例)8月・気温30度 ⇒ 予想来店者100人 ⇒ アイス価格100円 ⇒ 30人売れる
8月・気温30度 ⇒ 予想来店者100人 ⇒ アイス価格130円 ⇒ 27人売れる
この例では未来の気温と来店者数を予測した段階で、おそらくN人前後に販売できるという目安が生まれますが、そこから価格を変更した場合の予測を行う必要があるということです。
どのような特徴量が精度に寄与しているかは商品によって異なりますが、ここで価格変更特徴量の影響度が強いかどうかも、弾力性の尺度になり得ます。
また、異常値の除去・補正については注意が必要になります。
キャンペーン等の外部要因影響が大きい商品、最近急成長してきた商品などはルールベースのIQR外れ値検出が自然需要をも削ってしまう場合があるためです。そのような場合は例えば異常値排除のための時系列予測モデルを構築し、予測結果からの残差を一定以内に補正するといった工夫をしていく事となります。
データ蓄積が不十分な場合の課題
新商品やロングテール商品などでは、商品ごとのサンプル数が不足してしまいがちです。そこでオーバーサンプリング手法として、以下のような対策を講じるケースが存在します。今回は特に、「特定の価格帯での販売実績だけ極端に少ない」といったケースでの使用が念頭に置かれます。
ただしデータの「捏造」に踏み込んでしまうと自然需要からは遠のいてしまうため、最低限傾向を捉えられるデータ量の見切りをつけておくことや、新製品に対する対応スタンス(このルール化での類似商品傾向を適用させられればそれで良い 等)の明確化を抑えておくことが必要です。
-
データ拡張生成ライブラリの活用: 受注実績が非常に少ない商品に対して、データ拡張手法(SMOTEのような手法を参考に商品属性ベースの合成サンプルを作成する等)で一定のボリュームを補う。

-
類似商品情報の活用: カテゴリやブランド・スペックをベクトル化することで類似商品を探索可能にし、近しい商品同士でデータを「横展開」しすることでコールドスタートを緩和する。
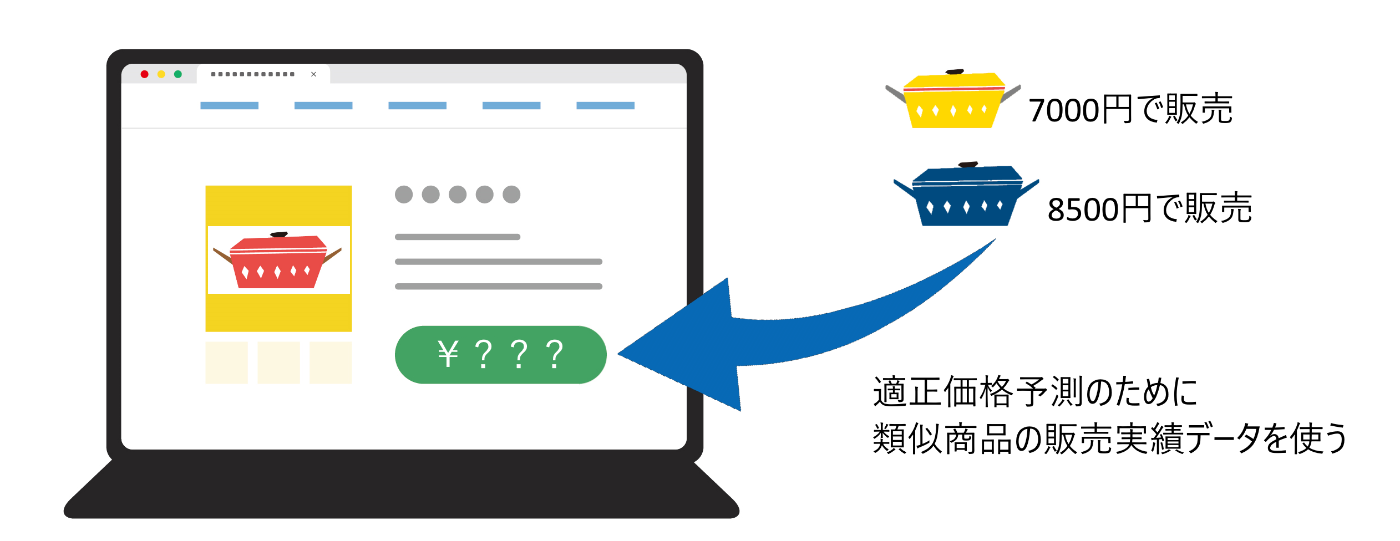
参考 メルカリが主催したKaggleコンペにおける、商品相場の推定方法
Kaggleは凄かった! 更に簡単な出品を目指して商品の値段推定精度を改善中
優勝コードから学ぶ―メルカリコンペ編①―
【Kaggle】メルカリ価格提案コンペの最多得票数コードを解説
3.3 シミュレーションデータ生成
構築した需要予測モデルを使い、実際に価格変更のシミュレーションを実施していきます。
例えば10000~11000円を10円単位で価格検討したい場合は10000円、10010円、10020円・・とデータを変更しつつ予測モデルに投入していくことで、全価格パターンの予測結果を得ることができます。連続価格 を扱う場合は 離散化(例:5 円刻み)しておくと後段の最適化工程が容易であり、競合連動型の場合は「自社 ± {0, 1, 2 %}」のように相対値で生成する関数を用意しておくのが望ましいでしょう。
また交差価格弾力性まで高精度で予測できていれば、競合価格に変更があった際は自動で再予測を回すことで競合値下げによる影響を常に推し量ることも可能です。
このステップの運用まで設計することで、例えば「競合の価格変更がありしだいシミュレーション開始」といったデータ連携要件が確定してきます。
弾力性学習失敗の兆候を捉える
また、シミュレーション結果を確認していく本ステップでは弾力性学習失敗の兆候を捉えることが求られます。
受注数を予測する精度は高いものの、価格変更に対する予測としては異常なSKUが必ず出てきます。例えば値下げした結果、需要が落ちる予測が生まれた場合、それがブランドと消費者心理から考えて有り得るところなのか解釈が必要です。価格弾力性の「傾き」は通常ゆるやかな右肩下がりになりますが、例えば右肩上がりになっている等の予測結果をここで検出・分析していきます。
価格上昇に対して需要が単調減少でないSKUをリスト化していき、需要予測信頼区間 > 閾値で “要人手レビュー” フラグを立てるといった運用が必要です。異常な価格弾力性予測は特定の価格帯での販売実績が不足している場合によく見受けられます(対策としてはサンプリング上の工夫になります)。
※なおLightGBMでは"単調制約条件"というパラメータが存在しており、特定の特徴量が予測値と必ず正の関係(もしくは負の関係)になるよう条件をつけて学習させることができます。
ここまで構築できれば、価格変更することでどれくらい需要が変動するのかシミュレーションデータが貯まっている/自動生成が可能な状態となります。
次はその結果を元に、実際の価格意思決定を行うステップです。
3.4 数理最適化アルゴリズムの適用
需要予測モデルによって作成した価格変更シミュレーションデータを、ビジネス目標と掛け合わせ、各商品の価格意思決定を行うのがこのステップです。ビジネス意思決定と直結するという意味で、予測モデル以上に重要なのがこの設計です。
全体最適(全SKU・全カテゴリ横断での最適化)と部分最適(特定カテゴリやチャネル内での最適化)をどれだけ考慮するのか、制約として含めておくべき事は何なのか。
需要予測の結果をビジネス要件に落とし込み、「どの価格を選べば粗利を最大化しつつ粗利率を守れるか」「在庫を期限内に消化しながら利益も伸ばせるか」を数学的に解くのが数理最適化です。本章ではプライシング文脈での数理最適化の基本と、代表的なモデリング例を解説します。
数理最適化(Mathematical Optimization)とは
数理最適化は、次の 3 要素で構成される「最適解探し」の枠組みです。
| 要素 | 意味 | 価格最適化での例 |
|---|---|---|
| 目的関数 | 最大化/最小化したい指標 | 粗利額の合計 |
| 制約条件 | 必ず満たすべきルール | 粗利率≥25%、値上げ幅±10%以内 |
| 意思決定変数 | 最適値を探したい対象 | 各 SKU の価格 |
ビジネス要件を以下に紹介していくような「目的関数」「制約条件」として 定式化 し、ソルバー※に渡すことで、最適(または最適に近い)価格セットを高速に得ることができます。
※ソルバー:数理最適化に用いられるアルゴリズム計算モジュール
定式化の具体例
運用例1.「粗利最大化 × 粗利率制約」モデル
- 目的関数: 粗利額を最大化
-
制約条件:
- 全体の粗利率 ≥ 目標値(例 25%)
- 価格は候補リストから選択し、各 SKU から 1 つ採用
- 価格改定幅は現行比 ±Δ% 以内
粗利最大化モデル ~数式~
-
Demand_i(Price_i) -
CandidatePrice_{i,k} -
Cost_{i,k} -
y_{i,k} - Δ : 価格変更可能な幅(例えば 10 % 以内)。そもそも価格候補作成の段階から想定外の価格は間引いてしまうのがスマート
- 候補価格を離散化しておくと、混合整数線形計画(MILP) として解ける。
- SKU が数万を超える場合は、列生成法・メタヒューリスティクスで解空間を絞り込むなどの高速化が必須。
運用例2.「在庫消化 × 粗利最大化」モデル
- 目的関数: 粗利額を最大化
-
制約条件:
- 各 SKU の累計販売数量が在庫を売り切る(T 日以内)
- 各日・各 SKU で候補価格を ただ 1 つ 採用
- 価格改定幅は前日比 ±Δ % 以内
- (任意)日別粗利率 ≥ 目標値
在庫消化モデル ~数式~
-
Demand_i(Price_i) -
Inventory_{i,k} -
CandidatePrice_{i,d,k} -
Cost_{i,k} -
y_{i,k} - Δ : 価格変更可能な幅(例えば 10 % 以内)。そもそも価格候補作成の段階から想定外の価格は間引いてしまうのがスマート
- 価格候補を離散化し、二値変数 (y_{i,d,k}) を用いることで混合整数線形計画(MILP) として解ける
- Rolling Horizon(動的最適化)で毎日または毎時間再計算すると、
在庫進捗に応じて価格を自動調整できる
参考 [ウォルマート:在庫一掃を目的とした最適化]
(https://snknitin.github.io/publications/pub-3)
数理最適化をPythonで処理するためのライブラリとしてはOSS・商用ともに数種類存在しますが、おすすめはGoogle OR-Tools(無償・商用可)です。OSSソルバーの中で比較して計算速度・メモリ負荷ともに良いパフォーマンスです。
全SKU×全価格パターンのシミュレーションは膨大な計算量となり、組み合わせの数が増えれば指数関数的にメモリ使用量・計算時間が増加します。リソース負荷と計算時間を見つつ、価格パターンのうち明らかに採用しないデータを予めルールベースで間引いておく・全SKUではなく一定数で分割処理させていくといった対応を検討していく事になります。
以下は補足知識です。
プライシング特有の「相乗積」という考え方、数理最適化とは違った方法として強化学習による価格意思決定という方法論を紹介しておきます。
補足知識1. 相乗積と最適化
予備知識として、プライシングには「相乗積」という手法があります。ひとつのセグメントで粗利率を上下させた場合に、全体の粗利率がどれだけ影響を受けるかを簡単な計算で求められるというものです。
全体の粗利率変動 = 該当セグメントの粗利率変動 × 売上構成比
例えば売上構成比10%のセグメントを10%値下げする場合、全体粗利率は1%低下します。
先ほどの例で「全体の粗利率が一定以上」という最適化を行いましたが、価格弾力性が高い商品は値下げ・価格弾力性が低い商品は値上げしながら相乗積でバランスを取っているんだな、と捉えると理解しやすいです。
補足知識2. 強化学習による動的価格決定
これまで数理最適化による意思決定を紹介してきましたが、意思決定の機械学習である「強化学習」を用いた研究も存在します。
SKU単体での価格方策など、高度な局所最適に用いられます。状態(在庫や需要状況)に応じてエージェントが価格を選択し、その報酬(売上・利益)を最大化するポリシーを学習する方法です。ダイナミックプライシングの意味を体現するかのようなロジックであり、これによりタイムセール系の値引き幅を自動で最適化できる可能性があります。
参考 Alibaba:深層強化学習
参考 Alibaba 解説記事:ダイナミックプライシングで強化学習を使った論文読んでみた
最適化ロジックの運用組み込み、スケジューリング
ビジネス要件の定式化により、最適化問題として解くことが可能になりました。
次に、需要予測~最適化サイクルの実行頻度に基づいてシステム要件を設計します。週1回の価格更新か、日次更新か、それとも更に高頻度かといった要件に合わせて、データパイプラインやインフラ構成を定義することで、これまでの需要予測と最適化プロセスが実用的な「プライシングシステム」として機能します。
定期実行型の運用に加え、競合価格変動などの市場シグナルを検知して即時反応する仕組みも構築可能です。市場変化への反応速度をほぼリアルタイムにまで高めたシステムは「ダイナミックプライシング」と呼ばれ、ECや航空券など変動の激しい市場で活用されています。
また、運用組み込みに当たっては既存オペレーションとどのように親和性を得るかが重要になります。
アルゴリズムベースを補うルールやヒト運用
ある程度アルゴリズムベースに委ねている大企業も、その中にヒトがいない訳ではなく、大まかな舵取りは人間がしているものです(筆者の意見です)。
数理最適化の目的関数に入れる目標数値はある程度人間が調整可能にしておく、商品セグメンテーションごとの予算管理でPDCAを動かせるようにしておく、といった業務設計もここでは大きく問われるでしょう。
ドンキホーテの店舗スタッフが店頭価格を決める際に使う”価格ミル”というツールでは、価格弾力性等の分析データと推奨価格をスタッフに提案するという運用になっています。最終的な決定は人間が行う運用であり、意思決定への導入ハードルは比較的低いと言えます。
Amazonの提供するマーケットプレイス出品者向けプライシングツールでは、24時間体制で価格を微調整しますが、上限・下限価格や対象競合といったルールを細かく設定できるようになっています。仮に同じようなルールを自社プライシングロジックに組み込んでいく場合、ルールの粒度や変更方法の設計が求められます。また価格決定システムにおいては最適化の後工程でルール適用させるのではなく、上限下限の範囲外となる価格選択肢は排除したうえで数理最適化させるといった組み込みも必要です。
3-5. 効果測定と継続学習フレームワーク
ここまで準備してきた価格を市場に反映し、その後の売上・利益など成果指標をモニタリングしていきます。
前提として、プライシングが左右する変数は CVR (Conversion Rate) です
消費者購買活動において、プライシングは基本的に比較検討フェーズに位置することから、「興味を持った人のうち、どれだけ購買に至ったのか」が直接的な指標となります。ECの場合は閲覧者に対する購入率、店舗なら来店客に対する購買率など。価格変更が顧客の購買行動に与えた影響を示します。
値上げ・値下げに対してCVRがどれだけ影響を受けているかは常に観測し続ける必要があります。

画像引用・参考 AISCEASの法則とは
そのうえで、プライシングの良し悪しを判断する事業KPIは以下となります。
| レイヤ | KPI | なぜ必要か |
|---|---|---|
| 事業価値 | 粗利インクリメント | 価格施策が利益を生んだか |
| 運用健全性 | 在庫回転日数 | 値付けがキャッシュを寝かせていないか |
| モデル健全性 | 需要予測誤差 | 予測ズレが最適化を壊していないか |
以下、詳しく見ていきます
KPI-1. 粗利インクリメントについて
価格とCVRが変化した結果、事業としての収益を上げることができているかどうか。という指標です。
(※計測可能な場合、粗利ではなく利益を扱います)
以下ツリー構造で把握しておくことによって、 「どのノードが寄与して粗利が伸び/縮んだのか」 を経営陣もオペレーション担当も同じビューで追跡できます。「CVR は伸びたが平均単価が落ちすぎた」 といったトレードオフを 1 画面で特定できるようにしておきます。
Δ 粗利 (Contribution Margin)
│
├─ Δ 販売数量 (Units)
│ ├─ トラフィック (Sessions / Footfall)
│ └─ CVR (Units ÷ Traffic)
│
└─ Δ 単価粗利 (Unit CM)
├─ Δ 平均販売価格 (ASP)
│ ├─ 価格水準 (List Price)
│ └─ 販売 Mix (SKU, チャネル, キャンペーン構成比)
└─ Δ 変動原価 (Variable Cost)
| 変化 | ツリーで起こる事 | 典型シナリオ |
|---|---|---|
| CVR↑, ASP↓ | - 販売数量ノードが増 - ASP ノードが減 |
値下げで購入率が跳ねたが 価格下落幅が大きい |
| CVR↓, ASP↑ | - 数量ノードが減 - ASP ノードが増 |
値上げで単価は上がったが 離脱者が増えた |
| CVR↑, ASP↑, 変動原価↑ | - 数量・ASP とも増 - 原価ノードも増 |
高付加価値 SKU にシフトし マージン率は横ばい |
KPI‑2. 運用健全性について
業態によって変わるものの、小売や EC、D2C の多くはモノを倉庫に貯めてから売るモデルです。
売ったら終わり ではなく 売れ残りや回収遅れで死なないか が実運用の肝になります。
「仕入れた原価が何日寝ているか」= DIO(Days Inventory Outstanding)、 在庫回転率などがここでの指標になります。
| 指標 | 定義 |
|---|---|
| DIO | 在庫簿価 ÷ 日次売上原価 |
| 在庫回転率 | 年間売上原価 ÷ 平均在庫原価 |
売れ残らず、しっかり売れて回転率を維持できていればよいわけです。業種や商材により “良い回転率” は変わりますが、同業平均より 2 回転ほど低い SKU は Markdown(値下げ)の候補としてリストアップしておくといった対応が考えられます。
これらの指標を見つつ、在庫が余ってしまうセグメントに関しては売り切りの最適化条件を組んだり、マークダウン対象として値引きしていく候補となります。
KPI‑3. モデル健全性について
「需要予測モデルが正しく市場動向を計算できているか」もモニタリングが必要です。
モデル構築時に見ていたRMSE等の指標についてはリリース後も継続観測し、必要に応じてモデルのチューニングを行う必要があります。(極端な例としてコロナ禍に突入してお客様の購買傾向が変わると、それ以前の傾向に基づいた予測モデルでは対応できなくなる)
必要に応じて、モデルの学習フロー見直しや特徴量エンジニアリングの調整などを行います。
| 項目 | 説明 |
|---|---|
| wMAPE | 実績 vs 予測の絶対誤差重み付き(予測値と実際の値の誤差を割合で評価する指標。小さいほど予測精度が高い) |
| Prediction‑Interval Coverage | 予測区間に実績が入る率(予測した範囲内に実際の結果が収まる確率。高いほど予測の信頼性が高い) |
| Data Drift PSI | 特徴量分布シフト(学習に使ったデータと新しいデータの分布の違いを測定する指標。大きいほどモデルの再学習が必要) |
続いて、モデル性能低下を自動検知して対応する仕組みの例:
- 時系列データの変化を自動検知:時系列 ADWIN / HDDM(データの傾向変化を自動検知する方法)を Flink CEP(リアルタイムデータ処理技術)で常時監視
- 新旧モデルの比較テスト:変化を検知したら→「影モデル」(Shadow Model:既存モデルとは別に裏で動かす新モデル)を1週間テスト運用
- 自動切替:新モデルの方が成績良ければ自動で「チャンピオン⇄チャレンジャー」切替(現行モデルと新モデルを入れ替え)
以上がプライシングテックのKPI代表例です。
価格を動かした翌日には 「利益はいくら増え、在庫は何日縮み、モデルは健全か」 を一目で言える、その状態がプライステック導入時に合わせて行うべき分析体制構築となります。これらの指標を観測し続けることで、以下のような症状を早期発見・即対処できるような体制に繋げていくことができます。
サイクルが安定したら 異常アラート→自動値付け再計算 まで自動化していくと、より多くの知見を貯めつつ、リアルタイムなプライシング運用を実現していくことができます。
ビジネス観点から見た好調不調・システム上の誤差などを把握していき、ステップ1~4へフィードバックすることでシステム全体の精度向上を図りましょう。
| 症状 | 原因 | アクション |
|---|---|---|
| CVR 急落 | 在庫欠品 | 調達部門連係 |
| DIO 上昇 | 値上げで回転低下 | 価格下限解放+プロモ率自動計算 |
| wMAPE スパイク | 外乱・新 SKU | 部分データ再学習ジョブ発火 |
分析は「何と比較するのか」しかありません
どことどこを比べて良し悪しを解釈していくかのアタリをつけるところで分析結果は決まります。
期間であれば前年比、前月、前回キャンペーン、価格変更の前後など。カテゴリであれば別ジャンルや類似商品。特定のキャンペーン対象だった商品群とそれ以外。
業績指標としては期間比較が多いですが、プライシングシステム自体の成績を判断する場合、運用システム別の成績比較や、何もしなかった場合の需要予測結果と比べていく事も多いです。
(以下はAlibabaグループが実施したAIモデル別の成績比較)

画像引用・参考 価格オペレーションの種類を複数テストした場合の推移比較例
ダイナミックプライシングで強化学習を使った論文読んでみた
「普段使いできるBI」をひとつ作るだけで仕事が非常にしやすくなります
KPIの可視化では、全体推移に加えて主要セグメントごとの推移、そしてドリルダウンと探索をある程度自由にできるBIを備えている必要があります。価格帯や商品カテゴリだけでなく、キャンペーン対象有無や在庫有無といったフィルター軸を用意しておくと良いでしょう。
ビジネス判断において「この資料には載ってない、あの数値はどうなんだ?」というものは常に出てきます。ここで調べて後でご連絡します・・というのではなく、一瞬で探索結果をシェアできるBIがあれば会議の熱量を殺さず企画を進める事ができます。
何より、自分が思いついた仮説の検証をすぐにできるツール これを多人数で探索できることの威力。
例えばKPIと以下のような 4W グリッドを組み合わせたUIは汎用性が高く、画面ひとつ作っておくとその後何度も使うことになります。「在庫過多 × 特定エリア × 新規客」 といった多条件絞りが即時返ると、会議中に打ち手を合意しやすいでしょう。4クリック以内で大抵の効果測定が完了するように設計しておくと分析での操作時間を減らせます。
| 4W 軸 | 例 | 推奨ドリル深さ |
|---|---|---|
| Who (顧客) | 新規 / 既存 / 年齢性別 / その他属性 | 2–3 |
| What (商品) | SKU → ブランド → 大カテゴリ | 3–4 |
| Where (チャネル/地域) | EC / 直営 / FC | 2–3 |
| When (時間) | 日 → 週 → 月 | 3 |
おわりに
本記事で解説した5ステップのフレームワークにより、10万、50万、さらには100万SKUといった規模でも、ボタン1つで最適価格を算出・適用するシステムを実装できます。
重要なのは、このシステムが単に「自動化」を目指すのではなく、「全体最適」を追求する点です。人間の感覚や経験だけでは捉えきれない価格弾力性の複雑なパターンを、機械学習モデルが捉え、数理最適化が制約条件下で最適解を導き出す。この組み合わせこそがプライステックを導入するメリットになります。
最後に、各ステップの担当編成例を記載すると以下となります。プライシングは特に最適化に関する要件定義ハードルが高いため、技術者とビジネスサイドの相互理解が重要です。
- データ収集管理 → データエンジニア
- 需要予測モデル構築 → データサイエンティスト
- シミュレーションパターン生成 → データマーケターとビジネス運用者
- 最適化アルゴリズム設計 → データサイエンティスト(ビジネス決裁者と共同)
- 効果測定PDCA → システム精度はデータサイエンティスト、ビジネス判断はマーケターと決済者
以上、いかがでしたでしょうか。
プライステックの実装は意思決定プロセスの構築です。
この技術導入は段階的に進めるべきであり、まずは小規模な実証から始め、成功体験を積み重ねていくことをお勧めします。情報の少ないこの分野において、本記事がプライステック全体像把握の一歩となれば幸いです。
Discussion