状況認識(SITUATIONAL AWARENESS)
まえがき
未来を最初に覗き見られる街――それがサンフランシスコだ。
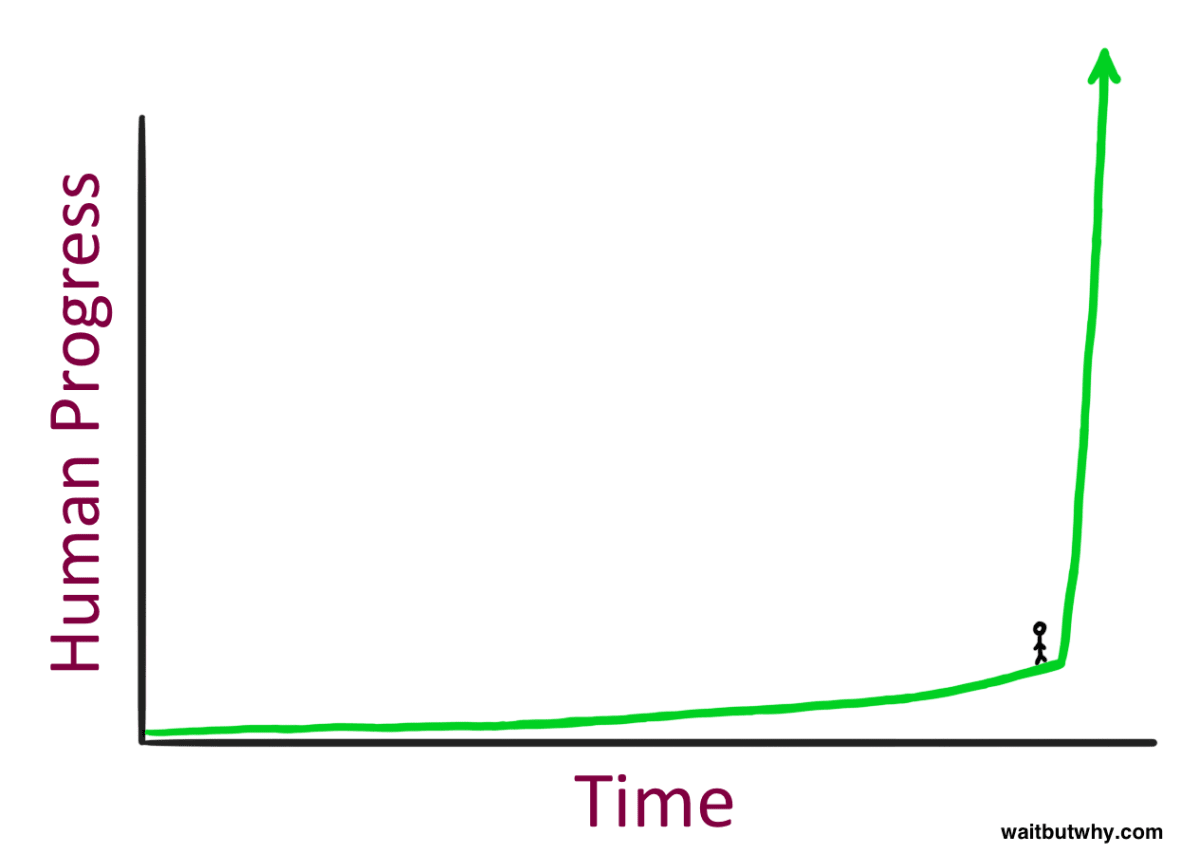
この 1 年で、界隈の会話は「100 億ドル規模の計算クラスター」から「1,000 億ドル規模」へ、そして今では「1 兆ドル規模」へと跳ね上がった。半年ごとに取締役会のプランに 0 が 1 つ加わる勢いだ。裏では、2030 年までに確保できる電力契約と変圧器を一つ残らず押さえようと、熾烈な争奪戦が進んでいる。米国大企業は 数兆ドル規模 の投資を見据え、久しく見られなかった産業総動員に向けて動き出した。10 年後には米国の発電量が数十%増え、ペンシルベニアのシェール油田からネバダのソーラーファームまで、数億枚の GPU が一斉に唸りを上げるだろう。
AGI レースはすでに始まっている。 私たちは「考え、推論する機械」を作っているのだ。2025〜26 年には、これらの機械が多くの大卒者を凌ぎ、10 年が終わる頃にはあなたや私より賢くなる――真の意味での超知性が誕生しているはずだ。その過程で、半世紀ぶりの国家安全保障上の力が解き放たれ、「ザ・プロジェクト」が動き出す。運がよければ中国共産党(CCP)との総力レース、悪ければ全面戦争になる。
いま AI を語る人は多いが、これから何が起こるのかを真に理解している人はほとんどいない。NVIDIA のアナリストでさえ「24 年がピークかもしれない」と言う始末。一般メディアは「所詮は次単語予測」と目を背け、せいぜい「インターネット級の変化」くらいにしか考えていない。
しかし、世界が目を覚ます日は近い。現時点で状況を正しく把握しているのは数百人ほど――その多くがサンフランシスコと大手 AI 研究所にいる。数年前、彼らは「狂信者」と嘲笑されたが、トレンドラインを信じて過去数年の AI 進歩を的中させた。この先も当たり続けるかは分からない。だが私は、これほど賢い人々を他に知らない。そして、彼らこそが技術を実際に作っているのだ。もし彼らの見立てが少しでも当たっているなら、われわれを待つのはジェットコースターのような数年間である。
その“見立て”を、ここで共有したい。
目次
-
序文(本ページ) – 歴史が動いているのはサンフランシスコだ
-
GPT‑4 から AGI へ:オーダー・オブ・マグニチュード(OOM)を数える
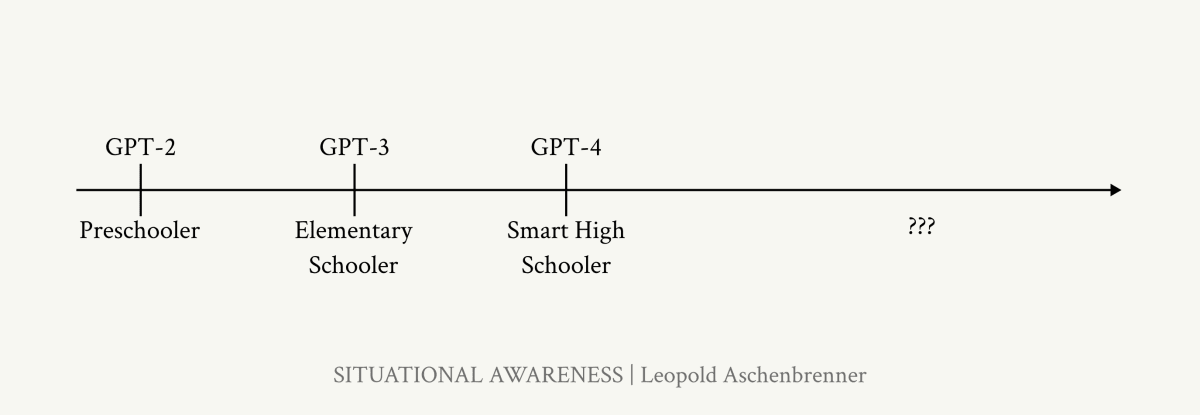
2027 年までに AGI――それは驚くほど現実味のある予測だ。GPT‑2 から GPT‑4 への 4 年間で、AI の能力は「幼稚園児」から「賢い高校生」へ跳躍した。- 計算資源:年 0.5 オーダー増
- アルゴリズム効率:年 0.5 オーダー増
-
“足枷外し”効果(チャットボット→エージェント化)
を掛け合わせると、2027 年にはもう一段階の跳躍が妥当に見える。
-
AGI から超知性へ:インテリジェンス・エクスプロージョン
AI は人間レベルで止まらない。数億体の AGI が AI 研究を自動化すれば、10 年分(5 OOM 以上)のアルゴリズム進歩が 1 年以内に圧縮されうる。パワーも危険も桁違いだ。 -
迫る課題
-
1 兆ドル・クラスターへの競争
AI 収益が爆発的に伸びるにつれ、GPU・データセンター・電力への投資が 数兆ドル規模に。米国の発電量を数十%押し上げる産業動員が始まる。
-
ラボをロックダウンせよ:AGI の安全保障
現状、主要 AI ラボはセキュリティ後回しで、AGI の鍵を CCP に手渡しているも同然。国家レベルの脅威に耐える防御は急務だが、まったく追いついていない。 -
スーパーアラインメント
自分たちより賢い AI を確実に制御する技術は未解決。知能爆発が急進すれば脱線は容易で、失敗は取り返しがつかない。 -
自由世界は勝たねばならない
超知性は決定的な経済・軍事優位をもたらす。中国はまだレースから脱落していない。自由世界が覇権を守れるか、あるいは自滅せずに済むかが懸かる。
-
-
ザ・プロジェクト
AGI レースが本格化すれば国家安全保障機構が介入する。米政府は 27〜28 年に何らかの「政府版 AGI プロジェクト」を立ち上げるだろう。スタートアップに超知性は扱えない。極秘施設(SCIF)の奥で、終盤戦が始まる。 -
おわりに:もし私たちが正しかったら?
もし、ここに描いた未来が現実のものとなったら――。
執筆後記と謝辞
私はかつて OpenAI に在籍していたが、ここに書いた内容は公開情報・個人の洞察・業界常識・サンフランシスコの噂話に基づくものだ。
Collin Burns、Avital Balwit、Carl Shulman、Jan Leike、Ilya Sutskever、Holden Karnofsky、Sholto Douglas、James Bradbury、Dwarkesh Patel ほか多くの友人・同僚に議論と助言をいただいた。Joe Ronan には図表制作で、Nick Whitaker には公開準備で助けてもらった。
このシリーズを、イリヤ・サツケバーに捧げる。
I. GPT‑4 から AGI へ ―― OOM を数える
「2027 年までに AGI」は驚くほど現実的だ。
GPT‑2 から GPT‑4 までの 4 年間で、AI の能力は「幼稚園児」から「優秀な高校生」へ大跳躍した。
- 計算資源:年あたり約 0.5 OOM(10 倍の半分)
- アルゴリズム効率:同じく年 0.5 OOM
- “足枷外し(アンホブリング)”:チャットボット→エージェント化で latent 能力を解放
これらを足し合わせれば、2027 年には再び幼稚園児→高校生級の質的ジャンプが妥当になる、というのが1章の主張だ。
1章で扱うトピック
-
過去 4 年を振り返る
- GPT‑2 → GPT‑4 の 4 年間
- ディープラーニングの潮流
- OOM(オーダー・オブ・マグニチュード)を数える
-
OOM の内訳
- 物理計算量(Compute)
- アルゴリズム効率
- “データの壁”という不確実性
- “足かせ外し”(Unhobbling)
- チャットボットから“同僚エージェント”へ
-
今後4年間
-
追補:OOM を駆け抜けろ――勝負は今世紀のこの10年で決まる
「モデルはただ“学びたい”だけなんだ。そこを分かってくれ」
――イリヤ・サツケバー(2015 年ごろ、ダリオ・アモデイ経由の回想)
GPT‑4 が見せた衝撃――コードもエッセイも書き、難解な数学問題を解き、大学入試を軽々突破する AI――は、実は 10 年間にわたる凄まじいスケーリングの延長線にすぎない。猫と犬の画像すらロクに識別できなかった時代から、ベンチマークを出すたびに数か月で塗り替えられる現在まで、一貫したトレンドが続いている。
かつて「狂気」と笑われた一部の研究者は、グラフ上の直線を信じ続けただけで、ここ数年の進歩を的中させた――そして今、その直線は 2027 年を指している。
私の主張はシンプルだ。
2027 年までに、モデルが AI 研究者/エンジニアの仕事を肩代わりしても驚きではない。
必要なのは SF を信じることではなく、グラフ上の直線を読み取ることだけだ。

本稿で紹介した公開データをもとに、有効計算量(物理的な計算資源とアルゴリズム効率の双方)について過去と将来のスケールアップをおおまかに推計したものです。モデルを大きくするほど知能は一貫して向上しており、「OOM(10 倍単位)」を数えることで、近い将来どの程度の知能が期待できるかを大づかみに把握できます。
※ グラフが示しているのはベースモデルのスケールアップのみで、アンホブリング(足枷外し)による上乗せ分は含まれていません。
GPT‑2 → GPT‑4 の 4 年間
| モデル | “知能”たとえ話 | 主な驚き |
|---|---|---|
| GPT‑2 (2019) | 幼稚園児 | たまに筋の通った段落を書ける 当時、人々が GPT‑2 に驚いた例のいくつか。左:ごく初歩的な読解問題になんとか正答している。右:10 回試行して最も出来の良かった “当たり” の出力ではあるが、南北戦争について一応筋の通った段落を書けている。 当時、人々が GPT‑2 に驚いた例のいくつか。左:ごく初歩的な読解問題になんとか正答している。右:10 回試行して最も出来の良かった “当たり” の出力ではあるが、南北戦争について一応筋の通った段落を書けている。
|
| GPT‑3 (2020) | 小学生 | 少数ショットで簡単タスク、基礎コード生成  当時、人々が GPT‑3 に感心した例。上: ごく簡単な指示を与えるだけで、造語を使った新しい文を作れる。左下: GPT‑3 と豊かな物語の掛け合いができる。右下: ごくシンプルなコードを生成できる。 当時、人々が GPT‑3 に感心した例。上: ごく簡単な指示を与えるだけで、造語を使った新しい文を作れる。左下: GPT‑3 と豊かな物語の掛け合いができる。右下: ごくシンプルなコードを生成できる。
|
| GPT‑4 (2023) | 賢い高校生 | 本格的コーディング、高校数学コンテスト級の推論  GPT‑4 の公開時に「Sparks of AGI」論文で取り上げられた、驚きの例。上: 非常に複雑なコードを書き(中央のグラフもその出力)、手強い数学問題を筋道立てて解く。左下: AP 数学の問題を解答。右下: かなり複雑なコーディング課題をこなす。GPT‑4 の能力を探った興味深い抜粋は、論文の他の箇所にも載っている GPT‑4 の公開時に「Sparks of AGI」論文で取り上げられた、驚きの例。上: 非常に複雑なコードを書き(中央のグラフもその出力)、手強い数学問題を筋道立てて解く。左下: AP 数学の問題を解答。右下: かなり複雑なコーディング課題をこなす。GPT‑4 の能力を探った興味深い抜粋は、論文の他の箇所にも載っている
|
- GPT‑4 は SAT・AP などの試験で 上位数% に入る。
- いまだ凹凸はあるが、多くの制約は 「足枷外し」で解決可能な人工的制限 だ。
わずか 4 年間でここまで進歩しました。――さて、あなたはこの “進歩の線” のどこに立っているでしょうか?
ディープラーニングの潮流
この 10 年でディープラーニングは驚異的な速度で進歩してきました。たった 10 年前、猫と犬の画像を識別できるだけで「革命的」と言われた技術が、いまや新しい難関ベンチマークを作っては次々に打ち破る段階に到達しています。かつて広く使われるベンチマークを攻略するには数十年かかりましたが、いまでは数か月で “陳腐化” してしまう感覚です。

Our World in Dataの図表が示す通り、深層学習システムは多くの領域で急速に人間レベルに追いつき、時に追い越しています。
ベンチマークそのものが品切れ状態になりつつあります。たとえば友人の Dan と Collin が 2020 年に作った MMLU は「長く通用する難問集」を目指したベンチマークでしたが、わずか 3 年後には GPT‑4 や Gemini が 約 90 % を叩き出し、ほぼ「解かれた」状態になりました。
もっと大きく見ると、GPT‑4 は高校・大学レベルの標準的な適性試験をほぼ網羅的に突破しています。しかも GPT‑3.5 から GPT‑4 への 1 年足らずの進化で、人間偏差値の下位から一気に上位へとジャンプしたケースが多いのです。

GPT‑3.5 から GPT‑4 で人間偏差値が大幅に上昇。しかも GPT‑3.5 は GPT‑4 の 1 年前に登場したばかりで、昔の “小学生レベル” GPT‑3 とは別物です。

灰色:2021 年 8 月に専門家が予測した 2022 年 6 月時点の MATH(高校数学コンテスト問題)スコア 赤星:実際の 2022 年 6 月時点の SOTA。楽観的予測をさらに上回った。ML 研究者の中央値予測はもっと悲観的だった。
MATH ベンチマークが公表された 2021 年、当時の最高モデルは 正答率 5 % 程度でした。論文には「強力な数学的推論にはモデルの規模や学習コストをただ増やすだけでは不十分。コミュニティ全体で新たなアルゴリズム的ブレークスルーが必要だろう」と記され、多くの研究者も「数年での進展はわずか」と予測。しかし 1 年後(2022 年中頃)には 50 % に到達し、いまでは 90 % 超。たび重なる “不可能宣言” はことごとく打ち破られてきました。
この 10 年で得た最大の教訓:ディープラーニングを過小評価してはいけない。
現在、未攻略で最難関とされるのは GPQA のような博士課程レベルの生物・化学・物理問題です。私には意味不明な設問も多く、異分野の PhD 研究者が 30 分かけてもほぼ当てずっぽう。しかし Claude 3 Opus は約 60 %、専門分野の PhD は約 80 %。次世代モデルが現れれば、この壁もすぐ崩れるでしょう。

私よりモデルのほうがもう得意です。博士レベルもそう遠くありません。
OOM(オーダー・オブ・マグニチュード)を数える
いったいどうして、ここまで急速に進歩したのでしょうか。ディープラーニングの “魔法” は「スケールさせれば そのまま効く」点にあります。そして懐疑的な声がいくらあっても、トレンドラインは驚くほど一貫して伸び続けてきました。
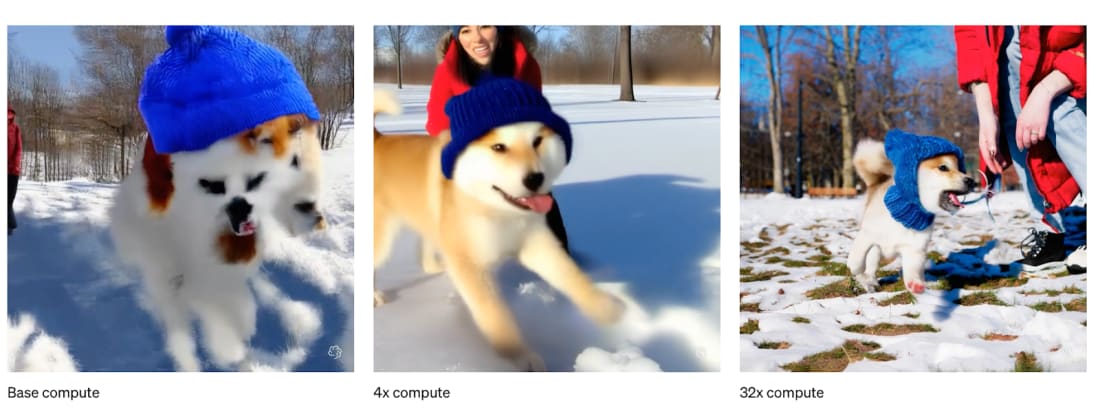
OpenAI Soraなどを見れば分かるとおり、計算資源(コンピュート)を 1 桁増やすたびにモデルは確実に賢くなる。OOM を数えれば、(ざっくりではあっても)今後どの程度の能力向上が望めるか見積もれる──先見の明ある少数の研究者が GPT‑4 を予見できたのはこのためです。
GPT‑2 から GPT‑4 までの 4 年間の進歩は、次の 3 つの “スケールアップ” に分解できます。
| スケールアップの種類 | 概要 |
|---|---|
| Compute | より巨大な計算機を使って学習する。 |
| アルゴリズム効率 | 継続的なアルゴリズム改良により「実効コンピュート」を増幅させる。 |
| “アンホブリング” | モデルが本来持つ潜在能力を、RLHF や Chain‑of‑Thought、ツール使用、スキャフォルディングなどで解放する。 |
改善量を OOM(10 倍=1 OOM) で数えると、
- 3 倍 ≒ 0.5 OOM
- 10 倍 = 1 OOM
- 30 倍 ≒ 1.5 OOM
- 100 倍 = 2 OOM …となります。
以下では 2023〜2027 年に GPT‑4 の上にどれだけ積み増せるかも合わせて見ていきます。結論を先取りすれば、私たちは猛烈な勢いで OOM を駆け上がっている──データ枯渇という逆風はあるものの、2027 年までに「GPT‑2→GPT‑4」と同じ規模のジャンプがもう一度起きる 可能性が高いと考えられます。
Compute(計算規模)
最近の進歩で最も語られる要因は「ひたすら計算資源を増やした」ことです。
多くの人は「ムーアの法則でコンピュータが速くなったから」と思いがちですが、ムーアの法則全盛期でも 10 年で 1〜1.5 OOM 程度の伸びに過ぎません。実際には 5 倍 ものペースでコンピュートが増えており、背景にあるのは 桁違いの投資 です。かつては「モデル 1 つに 100 万ドル」は論外でしたが、今やはした金同然になりました。
| モデル | 推定学習コンピュート | GPT‑2 比伸び |
|---|---|---|
| GPT‑2 (2019) | ~4e21 FLOP | – |
| GPT‑3 (2020) | ~3e23 FLOP | + 約 2 OOM |
| GPT‑4 (2023) | 8e24〜4e25 FLOP | + 約 1.5–2 OOM |
Epoch AI の推計によれば、GPT‑4 の学習には GPT‑2 の 3,000〜10,000 倍 の生コンピュートが使われました。これは投資と専用ハード(GPU・TPU)の大規模導入が 15 年以上続いてきた結果で、年あたり 約 0.5 OOM のペースで増えています。

注目すべきディープラーニング・モデルのトレーニング量の推移。/Epoch AI
そして 2027 年末までに さらに 2 OOM(数十億ドル級クラスター)、ひょっとすると +3 OOM(1000 億ドル級)も現実味がある――というのがシリコンバレーの“噂”です。
アルゴリズム効率
計算資源に巨額マネーが注ぎ込まれる一方で、アルゴリズム改良も同じくらい決定的――にもかかわらず過小評価されがちです。
たとえば高校数学コンテスト MATH で 正答率50% を達成する“推論コスト”を比べると、わずか 2 年で約 1,000 分の 1(≒3 OOM) に低下しました。

MATHのパフォーマンスを~50%にするための相対的な推論コストの概算。
“パラダイム内”アルゴリズム改良
まずは ベースモデルそのものを賢く・安く する改良です。
-
たとえば 10 倍 少ない学習計算で同じ性能が出せれば、実効コンピュート +1 OOM と同義になる。
-
後述の “アンホブリング”(ツール使用や RLHF などで潜在能力を解放)とは区別します。
長期トレンド
公開データが豊富なImageNetでは 2012–2021 年に 年 0.5 OOM(約 3 倍/年)ペースで効率化。
これは 4 年で 100 倍 の計算節約に相当します。

同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているでしょうか?2021年には、同じ性能のモデルを学習させるために必要な計算量は、2012年と比較してどの程度減少しているのでしょうか?/ Erdil and Besiroglu 2022.
LLM でも Epoch AI の推定で 年 0.5 OOM が続いており、8 年で 4 OOM(1 万倍)の効率化を達成した計算になります。

Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。彼らの試算によると、私たちは8年間で~4 OOMsの効率化を達成したことになる。
直近 4 年の主な“見える”改良
| 改良の手がかり | 規模感・ポイント |
|---|---|
| API 価格 | GPT‑4 = GPT‑3 並みの料金で数段上の性能。さらに 1 年で 6×/4× 値下げ(GPT‑4o)。 |
| Gemini 1.5 Flash | GPT‑4 相当の性能を 85×/57× 安価に実行。 |
| Chinchilla法則 | パラメータ数とデータ量を最適化 → 3× 以上 の学習効率。 |
| Mixture of Experts(MoE) | 必要サブネットのみ計算 → 複数倍の効率向上。 |
| その他 | 正規化・位置埋め込み・最適化アルゴリズムなど細かい改良が継続。 |
総じて GPT‑2→GPT‑4 で 1–2 OOM のアルゴリズム効率化があったと推定されます。

2027 年までの見通し
-
年 0.5 OOM のペースが続けば +2 OOM。
-
画期的ブレイクスルー(Transformer 級)が出れば +3 OOM 以上 も。
“データの壁”という不確実性
何が問題か
-
既にフロンティア LLM は Web 全体の良質テキストをほぼ使い切り つつある。
-
Llama 3 = 15 兆トークン、Common Crawl 精製後で 30 兆 程度。
-
ソースコード領域はさらに乏しく「数兆トークン」規模。
-
同じデータの再エポック学習は 16 周 あたりで効果が急減。
打開策の大本命
- 合成データ(Synthetic Data)
- 自己対戦/自己回帰学習(Self‑Play / RL)
Anthropic の Dario Amodei いわく「データ枯渇はブロッカーにならない」との強気コメント。
研究成果は非公開が増え、各社の秘伝アルゴリズムが差を生む時代 に入ります。
“足かせ外し”(Unhobbling)
定量化は難しいものの、実用化の鍵を握る改良カテゴリー が「アンホブリング(足かせ外し)」です。
なぜ“足かせ外し”が効くのか
たとえば難しい数学問題を出され、最初に思いついた答えを即座に口にしなければならないとしたら――大抵は解けません。従来の LLM はまさにこの状態で数学をやらされていました。
しかし人間は紙に書きながら段階的に考えます。同じことを Chain‑of‑Thought(CoT)プロンプト でモデルにもやらせたところ、一気に成績が向上しました。潜在能力はあったのに、“一発回答”という足かせで封じ込められていたのです。
近年の主なアンホブリング技術
| 技術 | 概要と効果 |
|---|---|
| RLHF(人間フィードバックによる強化学習) | 「汚い言葉の検閲」程度に思われがちだが、実際は使えるモデルに変える決定打。InstructGPT 論文では、小型モデル + RLHF ≒ 100 倍大きい非 RLHF モデル と同等のユーザ評価を達成。 |
| Chain of Thought | 内部メモ書きを許可。数学・推論系で 10× 以上の実効コンピュート増 に相当。 |
| スキャフォールディング(段取り分業) | ①計画を立てる → ②複数案を出す → ③批評する …と複数モデルで役割分担。HumanEval では GPT‑3.5+スキャフォールディング > 素の GPT‑4。 |
| ツール利用 | ブラウザ閲覧・コード実行等を許可。計算機なしの人間に電卓を渡すようなもの。 |
| 長大コンテキスト | 2k → 32k → 100 万トークン 超へ。小型モデルでも 10 万語の文脈があれば大型モデル 4k 読み込みより強い場合も。Gemini 1.5 Pro はこれで未収集言語を「辞書+文法書」から学習。 |
| ポストトレーニング改良 | GPT‑4 は公開後も継続改善。MATH 正答率 50%→72%、LMSys ELO +100 など。 |
Epoch AI の調査では、これらアンホブリング施策だけで 5〜30× の実効コンピュート相当向上が各種ベンチで確認されています。METR も Agentic Tasks で同一 GPT‑4 を 5%(素のベース)→20%(公開時)→40%(最新チューニング+ツール+スキャフォ) と報告。
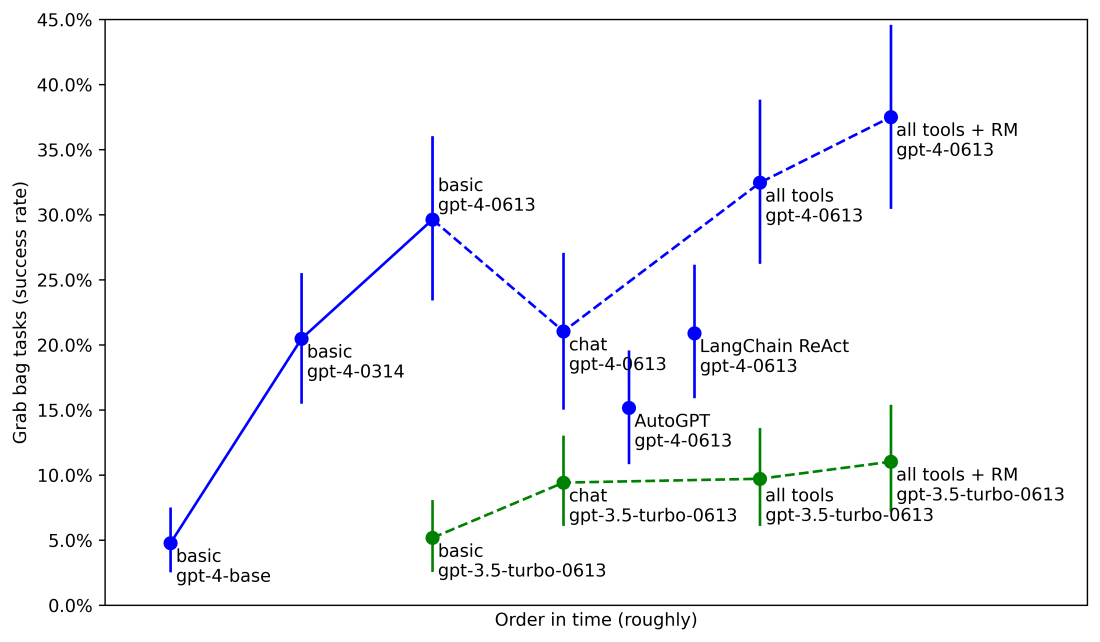
METRのエージェントタスクのパフォーマンス。

ここでの縦軸は「同等性能を出すのに必要な訓練計算量」を何倍節約できるかをラフに換算した値。
それでも残る“足かせ”
- 長期記憶 がない
- PC を自由操作 できない(ツールは限定的)
- 下書きなしの即答 が基本
- 長時間タスク を自律遂行できず、小刻み対話に終始
- 個人・組織に最適化されていない(社内ドキュメント等を前提に動けない)
2027 年に見える景色
したがって「GPT‑6=更に賢いチャットボット」を想像するのは誤りです。
アンホブリングが進めば、チャットボットではなく“同僚エージェント” に化ける――
- 自分で調べ、計画し、数日〜数週間かけて成果物を仕上げる
- 社内コードベースを読み込み、PR を投げ、レビュー対応まで行う
- 必要に応じて人間と協働・調整する
そういう存在が、計算効率・アルゴリズム効率の OOM 改良と並ぶ第三の成長エンジンになる、というのが筆者の主張です。
チャットボットから“同僚エージェント”へ
今後 2〜3 年で大胆なアンホブリングが進むとしたら——鍵になるのは次の 3 要素だと筆者は考えます。
1.「オンボーディング問題」を解く
GPT‑4 はかなり賢いものの、入社5分の新人と同じで 社内の文脈をまったく知らない。
社員ハンドブックも Slack の履歴も読んでおらず、コードベースも把握していない新人は即戦力になりません。しかし1か月経てば違います。同様に、極端に長いコンテキスト長 などを活かしてモデルを“新人研修”できれば、それだけで大きなブレイクスルーになるでしょう。
2. テスト時コンピュートの“オーバーハング”
現在のモデルは 短時間タスク しかこなせません。質問→即回答、で終わり。
けれど価値のある知的作業は、たいてい 数時間〜数か月 かかります。
科学者が難題を5分考えただけで発見などできない。
エンジニアが関数1つを書いただけでは製品は完成しない。
要するに、モデルには テスト時(推論時)の計算予算が圧倒的に不足 しています。
GPT‑4 のトークンを「頭の中の独り言の単語」と見なすと、今はせいぜい 数百トークン=数分 ぶんしか整然と推論できません。
| 使用トークン数 | 人間の作業時間に相当 | |
|---|---|---|
| 100 〜 数百 | 数分 | ChatGPT:現在地 |
| 数千 | 30 分ほど | +1 OOM(10×)の計算 |
| 1 万 | 半日 | +2 OOMs |
| 10 万 | 1 週間 | +3 OOMs |
| 数百万 | 数か月 | +4 OOMs |
※人間が 1 分に約100トークン思考し、週40時間働くと仮定。
“同じ知能密度”でも 数分 vs. 数か月 では成果が段違いです。
この テスト時コンピュートの余地(オーバーハング) は何 OOM(桁)分も残っています。
長コンテキストは「大量トークンを読める」ようにはなりましたが、生成 側はまだ不安定で、モデル単独で何日も思考し続けることはできません。ここを解くのは、比較的小さなアルゴリズム改良──たとえば RL によるエラー訂正や計画立案の学習──で足りるかもしれません。
必要なのは “システムII” 外側ループ を教え込むこと。うまくいけばチャットの短文ではなく、読み切れないほどの思考ストリーム が流れ込み、モデル自身が調査・試行錯誤・他者との調整を経て巨大プロジェクトを完遂する姿が見られるでしょう。
囲碁AI など他分野では「推論時に計算を多く使えば、学習計算を節約できる」ことが示されています(例:Hex ゲームで 1.2 OOM 多い推論 ≒ 1 OOM 多い学習に相当)。同じ関係が LLM で成立すれば、推論 +4 OOM は学習 +3 OOM に匹敵し、GPT‑3→GPT‑4 に相当する飛躍をもたらす可能性があります。
テスト時コンピュートと学習時コンピュートのトレードオフ — 他分野での例
将棋や囲碁など ボードゲーム用 AI の分野では、
推論時(テスト時)に多めの計算資源を割り当てれば、学習時の計算を一部代替できる ことがすでに実証されています。
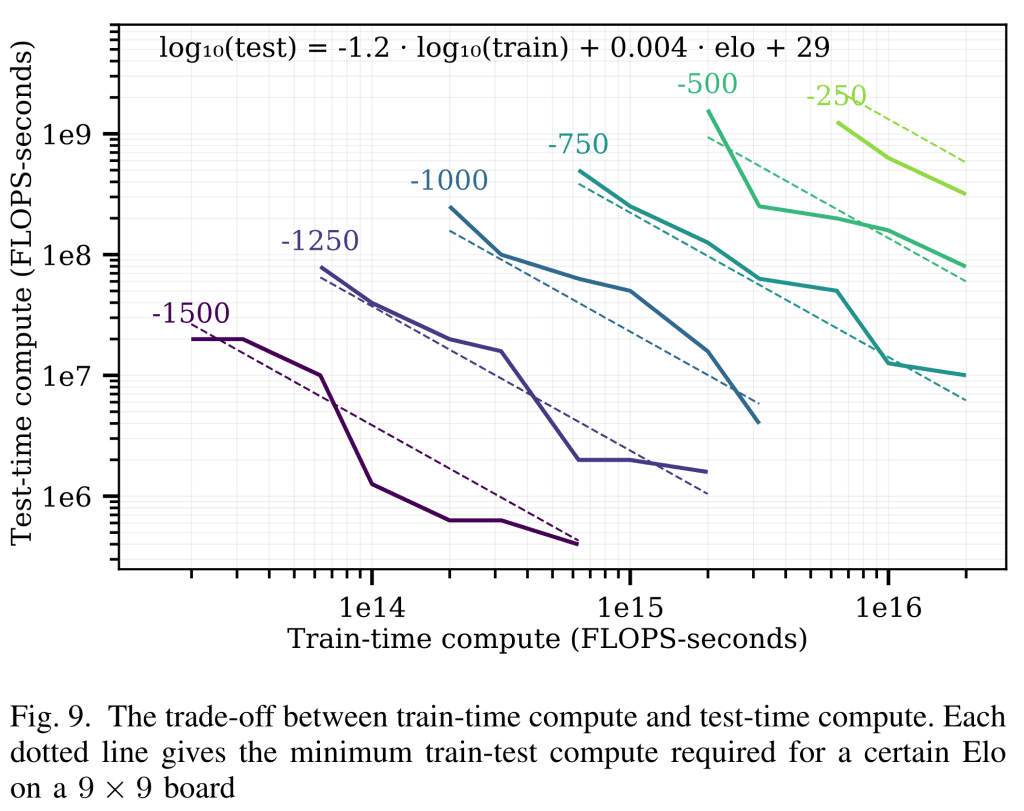
Jones (2021) — ゲーム Hex で検証, 小型モデルでも 「考える時間」を長く与える(=テスト時コンピュートを約 1.2 OOM 増やす)と、学習時コンピュートを約 1 OOM 追加した大型モデルと同等の成績を達成。
もし同じ比率が LLM でも成立するなら、
テスト時コンピュートを +4 OOM 解放できれば
事前学習コンピュート +3 OOM(概ね GPT‑3 → GPT‑4 の跳躍に相当)にも匹敵する効果が得られる計算になります。
要するに、このアンホブリングが実現すれば “巨大な OOM スケールアップ” と同じインパクトになるわけです。
3.「PCを使える」ようにする
最後はもっと直截的。現状の ChatGPT は テキスト窓の中に閉じ込められた人間 のようなもの。
ツール呼び出しは増えたものの、本格的なマルチモーダルモデルになれば まるごとPCを操作 させられるはずです。
- Zoom 会議に参加
- ウェブ検索・資料収集
- Slack やメールで連絡
- 社内アプリや IDE を利用
長期タスク用のテスト時コンピュート解放と組み合わせれば、“リモート社員をドロップイン” するように AI を導入できるでしょう。PR 作成やレビューもこなし、大規模プロジェクトを数週間で自主完結──そんな姿が、GPT‑4 より少し賢い程度の基盤モデルでも、足かせを外せば実現し得ます。

早期の実験例としては Devin があります。完全自動ソフトウェアエンジニアにはまだ遠い試作段階ですが、「エージェント化によるオーバーハング解放」の片鱗と言えるでしょう。
ちなみに、アンホブリングが中心的な役割を果たすことで、商用アプリケーションには一種の「ソニックブーム(超音速衝撃波)」のような現象が起こると私は見ています。
ドロップイン型リモートワーカー(AI エージェント)が完成するまでに登場する中間世代のモデルは、ワークフローを作り替えたり、インフラを整えたりといった “導入の雑務” が山ほど必要で、経済価値を引き出すには手間がかかります。
ところがドロップイン型リモートワーカーは統合が桁違いに簡単です。――文字どおり「放り込むだけ」で、リモートでこなせる仕事を丸ごと自動化できてしまう。
つまり、雑務に要する時間のほうがアンホブリング自体より長くかかる 可能性が高い。ドロップイン型が大量の職務を自動化できる段階になっても、中間世代モデルはまだ十分に活用・統合されていないかもしれません。その結果、経済価値の伸びは滑らかではなく、ある時点で一気に跳ね上がる ような不連続が起きる恐れがあります。
今後4年間


GPT‑4 以前の4年間に進歩を牽引した要因と、GPT‑4 以後に想定される伸び幅のまとめ
数字を総合すると――2023 年の GPT‑4 から 2027 年末までの 4 年で、GPT‑2→GPT‑4 に匹敵する大ジャンプがもう一度起きると見込まれます。
-
GPT‑2→GPT‑4
- 物理的コンピュート+アルゴリズム改良で 4.5〜6 OOM(10^4.5〜10^6 倍)のスケールアップ
- さらに アンホブリング によって「生モデル → チャットボット」へ実用化
-
GPT‑4 → 2027 年末
- 物理コンピュート/アルゴ改良で 3〜6 OOM(目安 5 OOM)
- アンホブリングの第2波で「チャットボット → エージェント/リモート社員」へ
たとえば GPT‑4 の学習に 3 か月かかったとしても、2027 年には同等性能を 1 分で学習できる計算です。コンピュート効率は桁外れに伸びます。
その先にあるもの

GPT‑2→GPT‑4 は、“幼稚園児” レベルから“賢い高校生” まで一気に成長したような変化でした。もう一度同じギャップを埋めるなら、博士号レベルの専門家を凌駕するモデルに至っても不思議ではありません。
今の AI 進歩は「子どもの成長 ×3 倍速」
3 倍速の子どもは高校を卒業したばかり――次はあなたの仕事を奪いに来る番です。
そして重要なのは、「超高性能な ChatGPT」を想像するだけでは不十分ということ。アンホブリングが進めば、モデルは会社の業務を数週間単位で独立遂行できるリモート同僚へと変貌します。
2027 年までに AGI 到達コース
2027 年に AGI(汎用人工知能)へ到達するシナリオは、もはや突飛な SF ではありません。現在の直線的トレンドを外挿するだけで十分に現実的です。
もちろん誤差範囲は大きい――
- データ不足で伸びが止まる
- アルゴリズムの壁を越えられない
- アンホブリングが想定ほど進まず「高度チャットボット止まり」
――という可能性もあります。逆に、テスト時コンピュートの解放など小さなブレークスルーで AGI が前倒しになることもあり得ます。
いずれにせよ、OOM(桁数)単位のスケールアップが続く限り、2027 年 AGI の可能性を真剣に考えざるを得ません。
“真の AGI” とは何か
最近は AGI の定義を「すごいチャットボット」と矮小化する向きもありますが、ここで言う AGI とは AI 研究者・エンジニアの仕事を丸ごと自動化できるシステムです。ロボティクスなど物理領域は遅れるとしても、AI 自身が AI 研究を自動化できれば、そこからは爆発的なフィードバックループが回り始めます。数百万人分の“自動研究者”が、10 年分のアルゴリズム革新を 1 年以内に圧縮する未来も十分あり得ます。
AGI は、やがて到来する スーパーインテリジェンス の前菜にすぎません(この続きは次章で)。
見落とすな、指数の勾配
モデルは「学習したがっている」――ただスケールさせるだけで能力は伸びる。驚異的な GAN の進歩が示すように、深層学習の加速度は鈍りません。数年後には、
- PhD が数日かける難題を瞬時に解く
- あなたの PC 上で仕事を肩代わりする
- 数百万行のコードベースをゼロから生成する
- 経済価値が 1〜2 年で 10 倍になる
――といった光景が「当たり前」になるでしょう。SF を語るまでもなく、OOM を数えれば それが妥当な帰結だと分かります。2027 年末までに 10 万倍超 のスケールアップ――私たちより賢い存在が誕生する日は、もう遠くありません。

GPT-4は始まりに過ぎない-4年後はどうなっているのか?GANの進歩に見られるようにディープラーニングの進歩の急速なペースを過小評価する過ちは犯してはならない。
追補:OOM を駆け抜けろ――勝負は今世紀のこの10年で決まる
かつて私は「短期で AGI が来る」という見方に懐疑的だった。
「たまたま自分たちの時代だけ特別に確率が高い」と考えるのは思い上がりでは――という古典的な誤謬を疑ったからだ。
AGI に到達するまでに必要なものが不確かなら、達成時期の確率分布も幅広く“ぼやける”はずだと思っていた。
しかし今は考えが変わった。
決定的不確実性があるのは「あと何年か」ではなく、あと何桁(OOM)ぶんの“有効コンピュート”が要るかのほうだ――と気づいたからだ。
今、この10年で OOM を猛スピード消化している
往年のムーアの法則ですら 10 年で 1〜1.5 OOM(10^1〜10^1.5 倍)の伸びだった。
ところが今世紀 2020 年代の AI は 4 年で約 5 OOM、10 年通算では 10 OOM 超 を駆け抜けようとしている。

2020 年代に一気に伸び、その後はペースが鈍化する予想
要するに、今は巨大スケールアップ期の“特需” にあり、2030 年代に入れば OOM の進捗は何倍も遅くなる。
もしこの特需で AGI に届かなければ、次に大きな飛躍が来るまで長い停滞を覚悟しなければならない。
伸びしろが鈍る三つの理由
| 要素 | 2020 年代の見通し | 2030 年代以降 |
|---|---|---|
| 資金投入 | 1 モデルに数千万ドルは当たり前、 $100B〜$1T クラスの計算クラスターも視野 |
これ以上は企業体力・GDP 比で限界。伸びは実質 GDP 成長(実質 2%/年)に縛られる |
| ハードウェア | CPU→GPU→AI 専用 ASIC、fp64→fp8 と非ムーア的に高速化 | ほぼ AI 最適化し尽くし、再びムーア並み(1〜1.5 OOM/10 年)ペースへ |
| アルゴリズム | 研究開発投資に数百億ドル、世界中のトップ頭脳が参入 低ハンギングフルーツを一気に刈り取る |
人材と投資の急拡大が頭打ち。アンホブリングも有限。進歩率は漸減 |
だから「この10年で決まる」
これらを合わせると、次の10年で消化できる OOM は、以後数十年分を先取りする勢いになる。
言い換えれば this decade or bust――
- うまく行けば:2020 年代のスケールアップで AGI に到達
- 失敗すれば:長く緩慢な時代が続き、AGI は遠のく
あなたや私が「AGI 達成は難しい」とどこまで見るかで中央値は動くだろう。だが、現に OOM を猛烈に縮めている今、最頻値(モード)はどう見ても「この 10 年の後半」に置くのが妥当だろう。
研究者 Matthew Barnett は、計算リソースと生物学的制約だけを軸にした可視化を公表している。彼の図も「2020 年代に OOM を一気に食い潰し、その後は緩やか」という本稿と同じ結論を示している。

II. AGIから超知性へ――インテリジェンス・エクスプロージョン
人間レベルで進歩は止まらない。何億体もの AGI が AI 研究を自動化し、通常は 10 年かかるアルゴリズム改良(5 OOM 以上)を 1 年以内 に圧縮しかねない。
人類が追いつく間もなく、AI は「人間並み」から「はるかに人間を超える」段階へ一気に跳ぶ。
超知性の力――そして危険――は、まさに桁外れだ。
2章の構成
- AGI の次に訪れるもの
- AI 研究の自動化――「研究者」をAIが代替すると何が起こるか
- 想定されるボトルネック
- 超知性の威力
「超知能機械とは、いかに優れた人間であろうと、 その知的活動のすべてをはるかに凌駕できる機械である。
機械設計自体も知的活動の一つなのだから、超知能機械はさらに優れた機械を設計し得る。
そうなれば “知能の爆発” が起こり、人間の知能は遠く置き去りにされる。
したがって、最初の超知能機械こそ、人類が発明すべき最後の機械なのだ。」
— I. J. グッド(1965)
ボムと“スーパー”――比類なき跳躍
冷戦の恐怖はロスアラモスで生まれた原爆(The Bomb)から始まったと語られることが多い。
だが実際には、水素爆弾(The Super)への飛躍も同じくらい重要だった。
- 1945年の東京大空襲──数百機の爆撃機が数千トンの焼夷弾を投下
- 同年、広島に落とされた「リトルボーイ」は 1 発で同等の破壊力
- その 7 年後、テラー式水爆は 威力をさらに千倍 に拡大──
第二次大戦全体で投下された爆弾量を 1 発で超えた
原爆が「より効率の良い爆撃」なら、水爆は「国家を消し飛ばす兵器」だった。
AGI と超知性の関係も、ちょうどこの Bomb ↔ Super の差に重なる。
AGI の次に訪れるもの
AlphaGo は人間の棋譜を学んだあと自己対戦を始め、創造性あふれる超人的手を打つようになった。
同じ原理で、AGI を手にした人類は “もう一回、いや二回三回とクランクを回す” ことになる。
すると AI は――
- 質的に私たちを超え
- 私たちと小学生ほどの開き以上で賢くなり
- 理解しきれない複雑な行動を取りうる
現在の “連続的だが急速” なペースでも AGI → 超知性 は十分衝撃的だが、
AI 自身が AI 研究を自動化すれば話はさらに早い。

既存トレンド(アルゴリズム効率 ~0.5 OOM/年)をそのまま高速再生するだけで5 OOM 以上、つまり GPT‑2 → GPT‑4 級の跳躍を 1 年足らずで達成
- 2027 年頃には推論用 GPU 群だけで 数千万〜1億体の AGI を同時稼働できる可能性
- その一部を 10 倍速で動かせば、人間 1 億人・24 時間研究体制に匹敵
ボトルネック――実験用コンピュート不足、人間との補完関係、
「改良が難しくなる限界」など――はあるが、決定的な減速要因には見えない。
超知性の力、そして危機
- ML 以外の研究開発にも超知性が投入されれば、ロボティクスや基礎科学が急加速
- 経済・産業面で 爆発的なスケールアップ
- 軍事面では 決定的優位 と 破壊力 を併せ持つ
こうして人類は、歴史上もっとも激烈で不安定な瞬間に直面する。
AGI はゴールではなく、超知性への序章にすぎないのである。
AI 研究の自動化――「研究者」をAIが代替すると何が起こるか
「すべてを自動化する」必要はありません。自動化すべきは AI 研究そのものだけです。
AGI の変革的インパクトを疑う人はよくこう言います──「ロボット工学を見れば分かる。たとえ AI が PhD 並みに賢くなっても、現実世界での作業は難題だ」あるいは「バイオ研究を自動化するには実験室の手作業や治験が要るだろう」と。
しかし AI 研究 にはロボットも試験管も不要です。最先端ラボの研究者やエンジニアの仕事は 完全にオンライン で完結し、現実世界の制約をほとんど受けません(計算資源という制限は残りますが、後ほど扱います)。仕事の内容はいたってシンプルです。
- 論文を読み、アイデアや疑問を立てる
- 実験を実装して検証する
- 結果を解釈して次の実験へ──
このループは、現在の AI の単純な外挿でも 2027 年末には人間トップ研究者を超える地点まで到達し得ます。
何体の「AI 研究者」を走らせられるか
- 2027 年には学習クラスタだけで 10 M+ A100 相当
- 推論用 GPU 群はさらに桁違い
- 単純計算で 数千万〜1億体 の AI 研究者(人間相当)を 24 時間稼働 させられる
内部独白を 100token/分 と見積もり、Chinchilla 則に従うと「1 日でインターネット全量に匹敵するトークンを生成できる」規模です。厳密な数字は重要ではなく、桁が合うことが肝心。
さらに――
-
並列数を減らし、シリアル速度を上げる方式で 5×→100× 人間速度も可能
-
最初に彼らが取り組むイノベーションは「推論を 10×〜100× 高速化」
- 例:Gemini 1.5 Flash は GPT‑4(初期版)と同等性能を 約10倍速 で達成
つまり 1 億体 × 100×速度=人間研究者 1 兆人年/年 に相当する努力が、
数か月以内に投入されうるのです。
10 年分の進歩が 1 年で起こる?
過去記事で示したとおり、アルゴリズム効率は 0.5 OOM/年 で向上し続けています。
もしこのトレンドを 10 倍 に圧縮できれば 5 OOM(=10⁵倍)の跳躍が 1 年で実現。
そして AI 研究の自動化が生むのは数だけではありません。
- 全論文を読破し、過去すべての実験を“経験”として共有
- 何百万行ものコードを一挙に把握し、バグも最適化も漏らさない
- 1体を育てれば コピーで無限増殖──政治も疲労も不要
- latent space 共有で 人間離れした協調 が可能
- さらに賢い次世代モデルを自己改良で連続生成
「アレック・ラドフォードが 10 人いたら」──そんな比喩を耳にします。
実際には 1 億体の“アレック”が 100×速で働く世界が出現するかもしれません。
つまり、AGI から 超知性 への移行は、驚くほど短期間(最悪でも数年、うまく行けば 1 年以内)で起こり得るということです。
想定されるボトルネック
ここまで述べた “AI 研究の自動化 → インテリジェンス爆発” というシナリオは、かなり強力なロジックで支えられており、詳細な経済モデルにも裏づけられています。それでも現実には、進行を “ある程度” 遅らせ得る妥当なボトルネックがいくつか存在します。
まず概要を示し、その後に関心のある方向けに各項目を詳述します。
| 主なボトルネック | 要点(概要) |
|---|---|
| 計算資源の制約 | 研究は「ひらめき」だけでなく 実験用コンピュート が必須。研究労働力を 100 万倍に増やしても実験 GPU が同数に増えるわけではない。ただし、AI 研究者(AI)がコンピュートを 10 倍以上効率的 に使える余地は大きい。 • 膨大な論文と過去実験を内面化 → 実験設計を最適化 • バグ取りに “世紀単位” の思考時間を投入して一発成功 • 小規模(とはいえ GPT‑4 級 10 万モデル/年)の試行でアーキテクチャ探索――等々。 |
| 補完性/ロングテール問題 | 経済学でいう ボーモル病:70 % を自動化しても残り 30 % がボトルネック化。 AI 研究の最後の 10 %(微妙な判断・統合など)は自動化が難しく、完全自動化には数年遅れが出るかもしれない。たとえば 2026‑27 年モデルは「半自動研究者」止まりで、最終的な“完全版”は 2028 年頃になる可能性。 |
| アルゴリズム効率の上限 | 「あと 5 OOM(10万倍)の効率向上は不可能では?」という懸念。だが過去 10 年で 5 OOM 得られた事実、現在の手法がまだ粗削りなこと、生物的参考例などを踏まえると、まだ相当な余地 があると考えられる。 |
| アイデア探索が難化し、加速ではなく現状維持に留まる説 | 研究努力が増えても「アイデアは見つけにくくなる」ため、100 M 研究者は 進歩を維持するだけ かもしれないという反論。しかし研究努力の増加は 100 万倍 規模で、歴史的に観測される“必要努力の増大”をはるかに上回る。維持だけで打ち消されるのは “ナイフエッジ” な仮定に近い。 |
| 収穫逓減で爆発がすぐ萎む説 | 一時的には跳ねても、逓減カーブが急なら急失速する可能性。ただし実証研究から見積もる限り、指数は 爆発/加速 を支持する範囲にある。まして「研究者 100 人→1 億人」の一度きりのブースト は、少なくとも数 OOM 分の前進を押し切ると見るのが自然。 |
実験用コンピュートの制約
アルゴリズム進歩の「生産関数」には、研究労力と実験用コンピュートという 2 つの補完的要素があります。
どれほど多くの AI 研究者を自動生成しても、実験を回す GPU が増えなければ彼らはジョブ終了を待つだけ──という事態も起こり得ます。
これはインテリジェンス爆発にとって 最重要のボトルネック でしょう。とはいえ定量的に考えると、たとえ計算資源が増えなくても 100 万人分の Alec Radford が 最低でも 10 倍 は実験コンピュートの「限界生産力」を高めるだろうと私は見ています。その理由は次のとおりです。
なぜ 10 倍は十分あり得るのか?
-
小規模実験でも得るものは多い
AI 研究ではまず小さなモデルでアイデアを試し、スケーリング則で外挿します。
例:Transformer 論文(2017)は GPU8枚・数日学習。
4 年後にベースライン計算量が +5 OOM 拡大すれば、「小規模」と言っても GPT‑4 相当。年あたり GPT‑4 級 10 万回、GPT‑3 級 数千万回 の実験が可能になります。 -
検証を省いて“本命”だけに絞る
年 1 回の巨大プリトレで「誤差数%の効率向上」を吟味するより、OOM 単位で効く大勝ちに集中すれば良い──レース中ならなおさらです。 -
“アンホブリング”は低コストで巨大な果実
まず RL や長コンテキストなど プリトレ不要 の改良で数 OOM 得たうえで、本格的な再学習へ進めます。 -
効率化でさらに実験回数を稼ぐ
推論コスト 1000 倍削減(先の例)や 10 倍高速化(GPT‑4→GPT‑4o)といった 人間研究者の成果 でさえ短期間に実現しました。
自動化研究者は同種の効率化を最優先で達成し、その浮いた計算で RL 手法などを雪だるま式に試せます。- 例:Gemini Flash は GPT‑4 相当を 100 分の 1 コスト で実現。
- 分散学習の改良で “推論用 GPU プール” までも動員すれば +1 OOM は堅い。
-
バグゼロ&高 V_o_I 実験で 3–10× 節約
1000 体の AI 研究者が 1 か月 かけてコードを精査し、最適な実験設定を一発で決める──それだけで多くのプロジェクトは 3〜10 倍 の計算節約が見込める、と現場研究者も認めています。 -
人間超えの“直感”
– 全論文・全過去実験を暗記
– 実験結果を予測する自己教師付き学習
– 1 % 学習時点で成功可否を当てるメタモデル
…といった“ML 第六感”を持てば、不要なジョブを大量にカットできます。Jason Wei が言う “YOLO run = 一発成功” 研究者が 10–100× 有能であるのと同じ理屈です。
補完性/ロングテール問題
経済学者が AI 自動化による成長加速に懐疑的な典型的理由は タスクの相補性 です。
──1800 年に人間労働の 80 % を機械が肩代わりしても成長爆発も大量失業も起きず、残った 20 % が人間の仕事としてボトルネックになった、という話はよく引用されます(モデル例はこちら)。
このモデル自体は正しいと思います。ただし私が論じているのは 経済全体ではなく、ごく狭い領域(AI 研究開発) に限った話です。
ロボット理髪師が普及せず、人々が普通に散髪している間でも――
- AI は 完全にバーチャル な仕事である ML 研究を自動化できる
- 前回の記事で述べたとおり、現在のトレンドは 「社内に即投入できるリモートワーカー級 AI」 に向かっている
- その範囲内なら「AI 研究者」の仕事は 丸ごと自動化可能 に見える
とはいえ「最後の 1 割」は残る
実際には、100 % 自動化 に到達するまで多少のロングテールがあるでしょう。
たとえば初期のシステムはほぼエンジニア代替になっても 最終確認だけ人間 が要るかもしれません。
-
能力はドメインごとにムラが出る
- コーディングでは人間超えでも、別の技能に死角
- 最弱領域が人間レベル になる頃には、易しい領域ではすでに大幅に超人化
-
そのため
- 限られた GPU を 人間より効果的 に使える
- (後の「スーパーアラインメント」問題にも影響:最初の自動研究者でさえ多くの分野で実質スーパー)
時間軸イメージ
この「最後の詰め」は 数年以内 に解消されると私は予想します。
急速な能力向上と、残る制約を外す アンホブリング が進むためです。
| 年 | フェーズ | 概要 |
|---|---|---|
| 2026/27 | プロト自動エンジニア | コーディング等で盲点は残るが 1.5–2× の加速。ゆるやかに進歩が加速し始める。 |
| 2027/28 | プロト自動研究者 | 仕事の >90 % を自動化。 巨大 AI 組織の調整や残り 10 % がボトルネックだが 3× 以上 加速。 ここで得た追加アンホブリングが 完全自動化 を達成。 |
| 2028/29 | 10× 以上の進歩速度 → スーパーインテリジェンス | 研究ペースが桁違いに跳ね上がり、超知性段階へ突入。 |
──十分に速いシナリオであることに変わりありません。
アルゴリズム効率の上限
アルゴリズムの改良には 物理的な上限 が存在するはずです。
(たとえば 25 OOM=10²⁵倍 もの効率向上は現実的ではありません。これは “GPT‑4 クラスのモデルを総計 10 FLOP 未満で学習できる” という計算になってしまいます。ただし“現在のアーキテクチャのままなら、それを実現するにはハードウェアをさらに 25 OOM 追加する必要がある” という意味ではあり得ます。)
しかし 5 OOM(10⁵倍)程度の効率向上 なら十分射程内でしょう。
実際、ここ 10 年ほど続いている 年 0.5 OOM 前後 のアルゴリズム効率トレンドが向こう 10 年続くだけで達成できる規模です(アンホブリングによる別枠の改良分は考慮せずとも)。
直感的にも、私たちはまだ 低い枝の果実 を取り尽くしていません。最大級のブレークスルーが驚くほど単純だったこと、そして現在のモデルや訓練手法が依然として “わざと足かせをはめられた” かのように粗削りであることが、その証左です。
- たとえば チェイン・オブ・ソウト のように「思考を逐語的に書き出させる」方法で AGI に迫るとしても、これは決して最効率ではないはずです。内部状態やリカレント処理を巧みに使う方が遥かに計算効率は高いでしょう。
- アダプティブ・コンピュート の観点では、Llama 3 も依然として “and” という単語の予測に、難問への回答と同じだけの計算を費やしています。ここだけでも明らかに最適化余地があります。
実際、小さな修正だけで 桁違いの効率向上 が得られた例は山ほどあります。未踏の改良余地――新しいアーキテクチャや訓練手順の工夫――はまだ数多く残っているはずです。
生物学的な比較から見ても、大きな余白 が示唆されます。
ヒトと他の哺乳類は脳のニューロン数が大差ないのに、わずかな配線・学習の違いで知能には大きな開きが出ることが知られています。さらに、人間の脳は現在の AI より 桁違いにデータ効率が高い――極端に少ないサンプルで学習できる――ことも、まだまだアルゴリズム上の伸びしろが大きいことを示しています。
アイデアは見つけにくくなり、収穫逓減が効くという反論について
低い枝の果実を取り尽くすほど、次のアイデアを見つけるのは難しくなります。これは技術進歩のあらゆる分野で見られる現象です。要は「研究努力の対数 と 進歩量の対数 がほぼ直線で結ばれている」──つまり、さらなる 10 倍の進歩を得るには、前回よりも さらに多く の研究努力を投入しなければならない、という経験則です。
ここから次の 2 つの異論が導かれます。
- 自動化された AI 研究は、進歩ペースを“維持”するだけで加速は起きない
- アルゴリズムだけのインテリジェンス・エクスプロージョンはすぐ頭打ちになる
モデルは正しいが、実証が合わない
経済学でいう 半内生的成長理論 は、この「研究努力の増大」と「アイデア発見の難化」の両方を組み込んだ標準モデルです。私も過去にこの種のモデルを扱ってきましたが、ポイントは 実証データがどうか に尽きます。そして実際の数字を見る限り、上の異論は当てはまりません。
例:直近 4 年間のアルゴリズム進歩
-
0.5 OOM/年(10⁰.⁵ ≒ 3.2 倍)のペースで進歩 → 4 年で 約 100 倍
-
ではこの間、トップラボの研究者数(質調整後)は 100 倍に増えたか?
- いいえ、多く見積もって 10 倍 程度でしょう。
-
それでも進歩ペースは維持されている。
つまり 研究努力の伸び < 進歩の伸び が続いており、「100 万人分の AI 研究者」を投入すれば「進歩ペースを保つだけ」では到底済まない――大幅な加速が不可避 ということになります。これを「加速しない」とみなすのは、“ちょうど釣り合う” と仮定するナイフエッジ的前提に過ぎません。
「自己持続しない」場合でも十分に危険
- 仮に“アイデア発見の難化”で連鎖的な自己強化が途中で鈍化しても、
100 万倍の研究投入 という“一回こっきりの衝撃”だけで 数 OOM 規模の一気の跳ね上がりは現実的です。 - 経済成長モデルでも、科学投資を GDP の 1%→20% に増やせば、長期成長率は戻っても 水準効果 が何十年も続く、という結果になります。
Tom Davidson や Carl Shulman の成長モデル分析、Epoch AI の実証研究も同様の結論に達しており、実証的には“爆発”を支持しています。
全体として──「一晩で世界が変わる」ほどではないにせよ、前節で挙げたボトルネックは、爆発的な知能向上を多少は減速させるでしょう。
たとえば “一夜にして世界が変わる” といった極端なシナリオは、現実的とは言えません。また、人間の補助が必要な “プロト自動研究者” の段階から、本格的な 自律型 Alec Radford*1 に至るまでに、1〜2 年ほど余計にかかる可能性もあります。
それでも――
-
完全自動のAI研究者が誕生してから、圧倒的な超知性システムに到達するまで
数 か月〜せいぜい数 年 で済む――これが本線シナリオと見るべきです。
超知性の威力
インテリジェンス・エクスプロージョンが 1 年以内か、数 年か――細部はともかく、「超知性」を覚悟すべき なのは明らかです。今世紀末どころか 2030 年代に入る頃には、想像を絶する能力を持つ AI が出現している公算が高いのです。
量的な超人性
- 2030 年頃には 数億枚規模の GPU が稼働し、十億体規模のエージェント を同時起動できる
- 人間の何桁も上の速度で「思考」し、あらゆる分野の論文を読み尽くし、
トリリオン(兆)行のコードを瞬時に書き上げる - それぞれのコピーが得た経験を共有し、数十億人‑年分 の知見を数週間で吸収
質的な超人性
AlphaGo の「第37手」が示したように、強化学習は人類が思いつかない創造的手を生み出します。
超知性はこれを無数の領域で再現します。
- 人間の思考パターンの「穴」を突く攻撃や説得
- 解説に何十年かけても理解できないほど複雑な設計
- 人類が数十年足止めされる難題を「当たり前」に解く
Minecraft を 20 秒でクリアする。スピードランを科学・技術・経済の全領域でやってのける──それが超知性です。
超知性がもたらす連鎖的爆発
-
AI 能力の全面的開花
AI 研究 以外の領域でも自動化が進み、すべての知的労働を置換。 -
ロボティクスの解決
ハードよりアルゴリズムがボトルネック。超知性が瞬時に突破し、
工場はロボット群だけで稼働。 -
科学技術の超加速
億単位の超知性科学者・技術者・ロボット技師が、
世紀分の R&D を 数年 で消化。
20世紀の技術革新を 10 年未満で再演するイメージ。 -
産業・経済の爆発
自己増殖ロボ工場 が砂漠を覆い、
経済成長率は 年 30 % 超、場合によっては年数回の GDP 倍増。成長モード 支配的になった年代 世界経済の倍増に要する年数 狩猟採集 紀元前200万年頃 23万年 農耕 紀元前4700年頃 860年 商業・科学 1730年 58年 産業革命 1903年 15年 超知性? 2030年? ??? 文明が狩猟から農耕、科学と商業の開花、そして工業へと移行するにつれ、世界経済の成長ペースは加速した。超知能は、成長モードの新たなシフトを引き起こす可能性がある。ロビン・ハンソン「指数関数的モードの連続としての長期成長」に基づく。
-
圧倒的な軍事優位
ドローン群やロボ軍は序の口。新型WMDやレーザー防衛など、
19世紀軍を21世紀兵器で潰すほどの開きが生じる。 -
既存国家の転覆リスク
超知性を掌握した主体は、サイバー操作・経済制圧・新型バイオ兵器の設計などで
既存政府を凌駕し得る。16 世紀に数百人のスペイン兵がアステカ帝国を滅ぼした――
同じことが 知能と戦略眼で桁違いに 起こりうる。
ロボット
こうした主張に対してよく挙げられる反論は、「AI が認知的タスクをこなせても、ロボティクスははるかに遅れているので、現実世界へのインパクトには大きなブレーキがかかる」というものだ。
私も以前はその見方に共感していたが、今では ロボットは障害にならない と確信している。長年「ロボットはハードウェアの問題だ」と言われてきたが、ハードウェアはすでに解決へ向かっている。
むしろ現在の課題は ロボット用の ML アルゴリズム だ。LLM が急速に発展できたのは、インターネットという膨大な事前学習データがあったからだが、ロボットの行動にはそれに相当する巨大データセットがない。そのため、マルチモーダルモデルをベースにしたり、シミュレーションや合成データ、巧みな強化学習などを組み合わせたりする工夫が必要になる。
今や、この問題解決に膨大なエネルギーが注がれている。たとえ AGI 登場前にロボティクスが完全に解決できなくても、数億体規模の AGI/超知性 が誕生すれば、彼ら自身が卓越した AI 研究者となり、ロボットを機能させる ML 手法を編み出すのはほぼ確実だ。
したがって、ロボットが原因で数年ほど遅れが生じる可能性はある(物理世界でのテストはシミュレーションより根本的に時間がかかるし、ロボット自身が工場を建てられるようになるまで初期生産を拡大する必要もある)。しかし、その遅れが「数年以上」になるとは考えにくい。
2030年代に何が起こるのか──予測は難しい

爆発的な成長はAIの研究開発という狭い領域から始まり、超知能を他の分野の研究開発に応用することで、爆発的な成長は拡大する。
この先十数年間にわたる展開は誰にも読み切れない(詳しい物語はまた別の機会に譲ろう)。だが少なくとも一つだけ確かなことがある。人類は、史上かつてない極限状況へと急速に突入する、ということだ。
人間レベルの AI――いわゆる AGI――が出現するだけでも社会は激変する。しかし、それはあくまで「既存の人類社会を、はるかに効率化した延長線上」にすぎないとも言える。ところが実際には、AGI からわずか一年ほどで、私たちにはまったく異質な――そして人類総体をも上回る――能力と理解を備えたシステムへと移行する可能性が高い。こうした急激な変化の渦中で、人類はコントロールを失い、意思決定を AI に委ねざるを得なくなる恐れがある。
もっと広い視点で言えば、あらゆる物事が信じられない速度で進行し、世界は狂気の様相を呈し始める。もし20世紀の地政学的緊張と人為的脅威が、ほんの数年で凝縮して起こったらどうなるか──ポスト・スーパーインテリジェンス期には、まさにそれと同等の状況が待ち受けているだろう。その最中には、私たちに残された時間は極端に少なく、正しい判断を下さねばならない。課題は途方もなく大きい。人類が無事に切り抜けるには、ありとあらゆる知恵と力を総動員する必要がある。
インテリジェンス・エクスプロージョンと、それに続く超知性の時代――これは人類史上もっとも不安定で緊迫し、危険かつ狂騒的な時期となるだろう。そして2030年代が終わる頃、私たちはおそらくそのただ中にいる。
連鎖反応の再来
超知性の出現という「連鎖反応」の可能性を直視する議論は、かつて核分裂連鎖反応と原爆をめぐって交わされた論争を思い起こさせる。
- 1914年、H.G.ウェルズは小説で原子爆弾を予言した。
- 1933年、シラードは連鎖反応の概念を提唱したが、誰も相手にしなかった。
- 1938年に核分裂が実証されるや、シラードは再び慌てて機密保持を訴え、少数の科学者だけが目を覚まし始めた。
- アインシュタインは最初こそ懐疑的だったが、シラードに説得されるや警鐘を鳴らすことを厭わなかった。
- しかしフェルミやボーアを含む多くの科学者は「保守的」態度を取り、ドイツへの情報漏洩を恐れての秘密主義や総力戦体制は「大げさだ」と受け流した。
――連鎖反応など荒唐無稽、と。だが実際には、そのわずか5年後に原爆は現実となったのである。
いま私たちは再び、知能の連鎖反応という可能性に向き合わねばならない。荒唐無稽に聞こえるかもしれない。しかし、主要 AI 研究所の上級研究者の多くは「急激なインテリジェンス・エクスプロージョンは十分あり得る」と見ている。スーパーインテリジェンスは実現可能だ。
Discussion