スポットインスタンスの落とし穴。データ消失の教訓と対策
はじめに
誤ったインフラ構成と運用が原因で発生した、個人開発サービスにおける大きな失敗についてお話しします。他の開発者が未然に防ぐ助けとなること、または万が一発生した際に参考にしていただけることを願っています。
何があったか
個人開発の「ちゃくどん」というラーメンの待ち時間計測・共有サービスにおいて、ある日の早朝、サービスがHTTPステータスコード500でダウンした通知を受け取りました。当初は一時的な障害かと思いましたが、調査の結果、データベース(以下DB)をホストするサーバーが削除されており、その結果としてアプリケーションがデータベースに接続できない状態に陥っていることが判明しました。最後にDBのバックアップを取得したのは事象からちょうど1週間前の一般リリース時点で、その間に登録されたユーザーアカウントやコンテンツが全て消失するというインシデントとなりました。。
事象発生時のアプリケーション構成
ECS Fargate上でRuby on Railsのコンテナを運用しており、DBとしてはEC2インスタンス上でPostgreSQLを稼働させていました。PostgreSQLのデータはEC2インスタンスに添付されたEBSボリュームに保存されています。重要な点は、これらのインスタンスはコスト削減のためにスポットインスタンスを使用していたことです。スポットインスタンスはEC2の余剰リソースを活用することで、最大90%の値引きを提供していますが、後述するリスクも存在します。
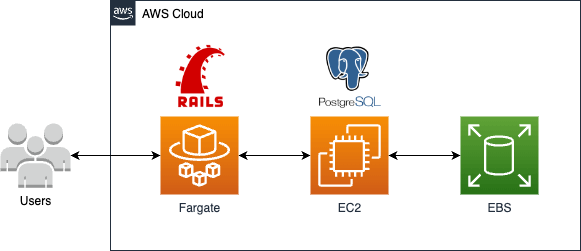
データ消失の直接的な原因
このデータ消失の直接的な原因は、スポットインスタンスの性質にありました。スポットインスタンスは、EC2の余剰リソースを活用するもので、これが少なくなるとEC2から中断リクエストが送信されます。この中断リクエストを受けると、インスタンスはデフォルトで「停止」ではなく「終了」状態になります。終了時には、インスタンスに接続されているEBSボリュームもデフォルトで削除されるため、結果としてデータが完全に消失しました。このデフォルトの挙動はEC2起動時のスポットインスタンスリクエストに関するカスタマイズによって変更可能となりますが、私はデフォルトの挙動と設定内容を十分に理解しておりませんでした。
参考:スポットインスタンスの挙動
事象発生から対策までのアクションについて
- 現状確認
最初に行ったのは影響範囲と復旧可能性の確認でした。幸い、EC2イメージをAMIとしてバックアップしていたため、リリース日までのデータは復旧可能であることがわかりました。しかし、リリース以降の自動バックアップシステムを導入していなかったため、EBSのスナップショットを確認しましたが、残念ながら存在しませんでした。 - 現状復旧
AMIイメージを使用してEC2インスタンスを再起動し、サービスを再稼働させることはできましたが、リリース日以降のデータは全て失われていました。 - 影響を受けたユーザーへの通知
RailsコンテナからCloudWatchログを取得しており、ロググループ内でPOST /usersなどのフィルター検索を活用して、新規登録されたユーザーのメールアドレスを特定し、直接謝罪のメールを送信することができました。ただし、Googleログインを使用したユーザーのメールアドレスは、設定されていたログレベルでは特定できず、状況と対策についてはX(旧Twitter)で報告することにしました。 - 対策実施
いくつかの対策案を検討した後、次の対策を実施しました。
実施した対策
対策として以下を実施し、サービスを再稼働しております。
- スポットインスタンスからオンデマンドインスタンスへの移行
スポットインスタンスの不安定さを踏まえ、サービスの安定性を高めるためにオンデマンドインスタンスへ移行しました。これにより、EC2の事情による意図しない終了から保護されます。 - インスタンスの停止・終了保護の設定
オンデマンドインスタンスへの移行に伴い、EC2起因による終了は防ぐことができますが、加えて人為的なミスによるインスタンスの不意な終了を防ぐために、停止・終了保護を設定しました。 - EBSボリュームの定期的なスナップショット作成
データの安全性をさらに強化するため、データライフサイクルマネージャ(DLM)を使用してEBSボリュームに対して定期的なスナップショットを作成しました。これにより、万が一EBSが消失しても影響を最小限に抑えることができます。
参考:
その他の対策案
以下のような追加の対策案も検討しましたが、実施には至りませんでした。
- RDSの使用
最も確実な解決策は、AWSのマネージドデータベースサービスであるRDSを使用することです。以前はRDSを利用していましたが、最小インスタンスタイプでもコスト(約$30/月)と、サービス維持の重荷となり、RDSからの移行を余儀なくされていました。今回の対策により引き続きEC2上での運用が可能であると判断し、RDSへの移行は見送りました。 - スポットインスタンスの中断通知をトリガーとした対策
スポットインスタンスが中断される2分前に通知が送信されることを活用し、これをトリガーとしてスケールアップするなどの対策が考えられます。ただし、2分という短い時間制限や複雑なオペレーションによるデータベースの整合性問題などのリスクを考慮し、この方法は採用しませんでした。 - PostgreSQLコンテナをFargateで運用し、EFSでデータを永続化
以前試みましたが、コンテナのローリングアップデート時にデータの整合性を維持することが困難であるため、この方法は断念しました。将来的にはまたチャレンジしてみようと思います。
参考:ElasticFileSystemを使ってデータを共通化|MariaDBコンテナの立ち上げ|AWSでDockerを本番運用!AmazonECSを使って低コストでコンテナを運用する実践コース
反省
この一連の事象を振り返って、スポットインスタンスという仕組みの特性を十分に理解せず、安易に採用してしまったことが大きな失敗の原因です。また、インフラの信頼性の重要性を再認識しました。特に、データベースのような重要なデータを扱う際には、中断要求があるスポットインスタンスのような不安定なリソースを使用するリスクをより慎重に考慮すべきでした。今後は、サービスに導入するあらゆる仕組みの特性やメリット・デメリットを十分に理解し、検証した上で採用することを心がけます。
さいごに
リリース直後からこの大きな失敗に始まり、利用ユーザーへご迷惑をおかけしていることを深く反省しております。失ったユーザーの信頼を取り戻すことは簡単ではありませんが、この経験を活かし、より良いサービスを提供するため、技術への理解を深めていきます。今後とも「ちゃくどん」へのご支援をお願いできればと思います。
Discussion