前回までのあらすじ
フォントでつながった文字を表現する(その 1)—文脈に依存した字形変化とは? では、アラビア語の語頭形、語中形、語尾形の考え方から、和文フォントでの連綿体の実現と位置に応じた表現がインスパイアされた話を書きました。
フォントでつながった文字を表現する(その 2)—欧文フォントの場合 では、文脈に依存する形で一部の文字の字形を変更することができるということについて書きました。
今回は、これらをベースに連綿体フォントの作成について触れたいと思います。
語頭形、語中形、語尾形
アラビア語の文字はそれが単語の中に出現する位置によって、語頭形、語中形、語尾形、そして独立形の 4 種類の字形を取りうるそうです。
ということについて第 1 回目の記事で書きました。これを支える OpenType feature は init、medi、fina になります。ところがこれらは、通常の日本語組版設定のままでは適用されないアプリケーションがあります。このような事情もあり、これら 3 つの OpenType feature は利用できません。代わりに、自作することを考えます。
今回は、medi と fina の模造品の実装について触れます。具体的には「〜あり〜」という文脈で あり 合字を語中形として、「〜ます。」という文脈で ます 合字を語尾形として呼び出します。
実装概要
今回の内容は縦組み文章で連綿体を呼び出す実装をしたいものです。よって、横組みには影響のないようにしないとなりません。このためまずは
- 縦組み専用の仮名グリフを用意する。
となります。その上で
- 特定のシーケンスで合字に置換する。
となります。但し、
- 常に連綿体に置換すると繋がり文字が多発する時に視覚的にごちゃごちゃするので、ある条件の時には置換処理をスキップさせて間引く。
という形にします。流れを図示すると以下のようになります:
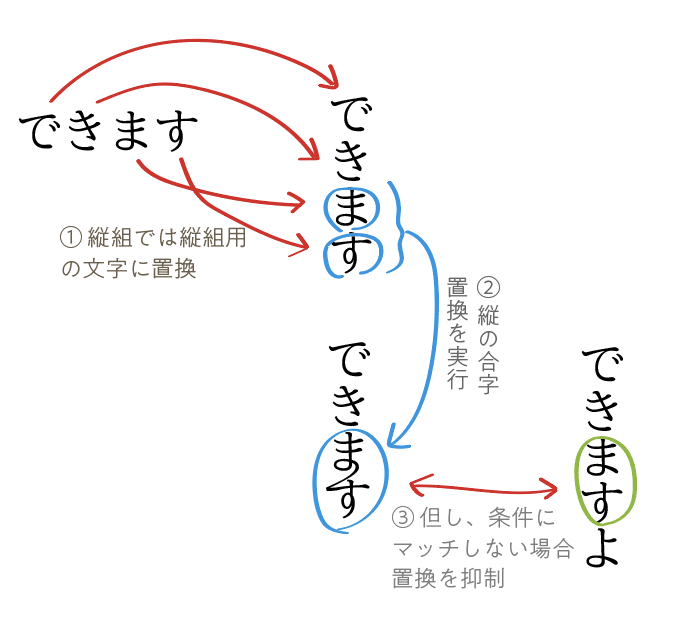
表示イメージ
できあがったフォントで横組みと縦組みをすると、以下のような表示になります。

実装
筆のまにまに。言葉によって形が変わるフォント「みちくさ」 を参考にします。
文章の中でも文頭や文末で文字が入力された時のみで連綿化するものや、
と
ある特定の単語でのみ連綿化するもの、
を採用します。また note では割愛されていますが、「連綿合字同士は連続しない」という制約条件もあります。これは例えば「あり」合字と「ます」合字を同時に連綿合字にするとくどいためです。
上記を文章で書くと、実装したい内容は、以下のようになります:
-
文末のみで連綿化
・「ま」+「す」+ 句読点以外の文字の時は無視 = 文末以外で登場する場合は抑制。 -
連綿合字同士は連続しない
・連綿 +「ま」+「す」は無視。真上に連綿合字が既に登場していれば抑制。 -
ある特定の単語でのみ連綿化
・それ以外での「ま」+「す」を「ます」連綿合字に置換。
これを次に疑似コードで記載したいと思います。分かりやすさのために「ます」合字の語尾形のケースだけここで扱います:
@連綿合字全体 = [あり ます];
@句読点以外 = [あ い う ... ぬ ね の ...];
lookup Fina {
### ある条件下では連綿体への置換を抑制 ###
# 【「ます」ね】など「ます」の後ろが句読点以外は無視
ignore sub ま' す @句読点以外;
# 【連綿 +「ます」】は無視
ignore sub @連綿合字全体 ま' す;
### 連綿体が繋がらない条件下で、直後が句読点になる部分を連綿体にする ###
# 「ます」連綿合字。【ます。】【ます、】などで発動
sub ま' す' by ます;
} Fina;
上記を実際に OpenType™ Feature File Specification で実装していきます。
その前に 1 つ注意事項があります。日本語のフォントの場合、搭載文字数が約 10,000 文字になることから、文字を管理するのが大変です。このため、フォントの中の文字に「文字 ID」(Character ID; CID) という数字を割り当てて ID で管理することがよくあります。ID が 156 の場合はよく「CID+156」などと書きます。以下の実装でもグリフの参照はグリフ名ではなく、この「文字 ID」を利用します。
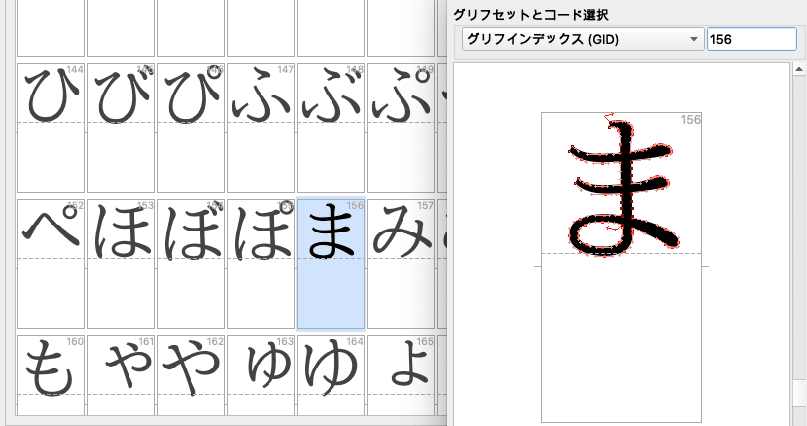
参考までに、今回の実験フォントでは縦組の「ま」を CID+156 に、縦組の「す」を CID+119 に、連綿合字「ます」を CID+183 に実装しています。
この CID を用いて「ます」の連綿合字呼び出しを実装すると以下のようになります。残りの実装についてはご興味がありましたらソースコードを見ていただけたらと思います。
@all_remmens = [cid00182 - cid00183];
@all_chars_except_punctuations = [cid00005 - cid00091 cid00094 - cid00180];
lookup Fina {
# 【「ます」ね】など「ます」の後ろが句読点以外は無視
ignore sub cid00156' cid00119 @all_chars_except_punctuations;
# 【連綿 +「ます」】は無視
ignore sub @all_remmens cid00156' cid00119;
# 「ます」連綿合字。【ます。】【ます、】などで発動
sub cid00156' cid00119' by cid00183;
} Fina;
フォントを使ってみる
RemmenGSUBDemo-Regular.otf にビルド済みのフォントを置いていますので、インストールしていただいて、高度な組版機能に対応したアプリケーションで利用することで自動的に連綿体が表示されます。例えば、Adobe InDesign や Adobe Illustrator が対応しています。下記は Adobe InDesign での表示例です。

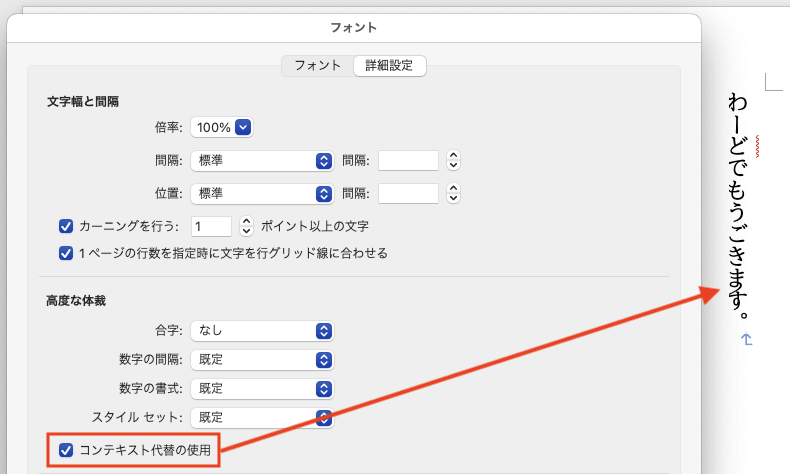
自動的ではないものの、実は Microsoft Word でも連綿合字を使うことができます。下記は Microsoft® Word for Mac バージョン 16.79.1 (23111614) での表示例です[1]。縦組みにしたテキストを選択して「フォーマット」→「フォント」→「詳細設定」から「コンテキスト代替の使用」にチェックを入れます。
フォントをビルドする
Remmen GSUB Demo で 2 種類のビルド方法を参考までに用意しています。あくまで興味がある場合のための参考情報です。
- ローカルの Python 環境にフォント開発キット AFDKO をインストールして使う。
- Docker 環境で Python + AFDKO の環境を作って使う。
ローカルの Python 環境にフォント開発キット AFDKO をインストールして使う
ターミナルを起動して以下を実行することで AFDKO をインストールできます[2]。
pip install "afdko==4.0.0"
その後、
cd RemmenGSUBDemo/sources
sh ./build.sh
でフォントをビルドすることができます。
Docker 環境で Python + AFDKO の環境を作って使う
Docker を利用できる場合、Docker イメージの形でビルド環境を作ってしまい、ホスト側のファイルをコンパイルしてフォントをビルドする方法もあります。
必要な手順を「build_font.sh」に記載していますので、以下のコマンド Docker イメージのビルドとフォントのビルドを一括して実行できます。
sh ./build_font.sh
まとめ
3 回の連載にて、フォントでつながった文字を表現する方法について見ました。
製品化する上では他にも考えなくてはならないことが沢山ありますが、一部分だけを抽出すると今回のような実装になります。フォントについてご興味を持っていただく一助になれば幸いです。

Discussion