はじめに
こんにちは、株式会社モリサワの田中です。フォントに関するR&Dを主に担当しています。
本記事では、フォントを含むベクターグラフィクスとAIにまたがる分野の研究で重宝するDiffVGについて、導入手順や基本的な使い方の解説と、フォントの文字形状を編集する簡単な実験について紹介します。
ベクターグラフィクスとは
ベクターグラフィクスは、数式で表される直線・円・ベジエ曲線などを使用して画像を表現する方法です。ピクセルで構成されるラスター画像と比較して、拡大しても画質が低下しない・編集が行いやすいなどの利点があります。
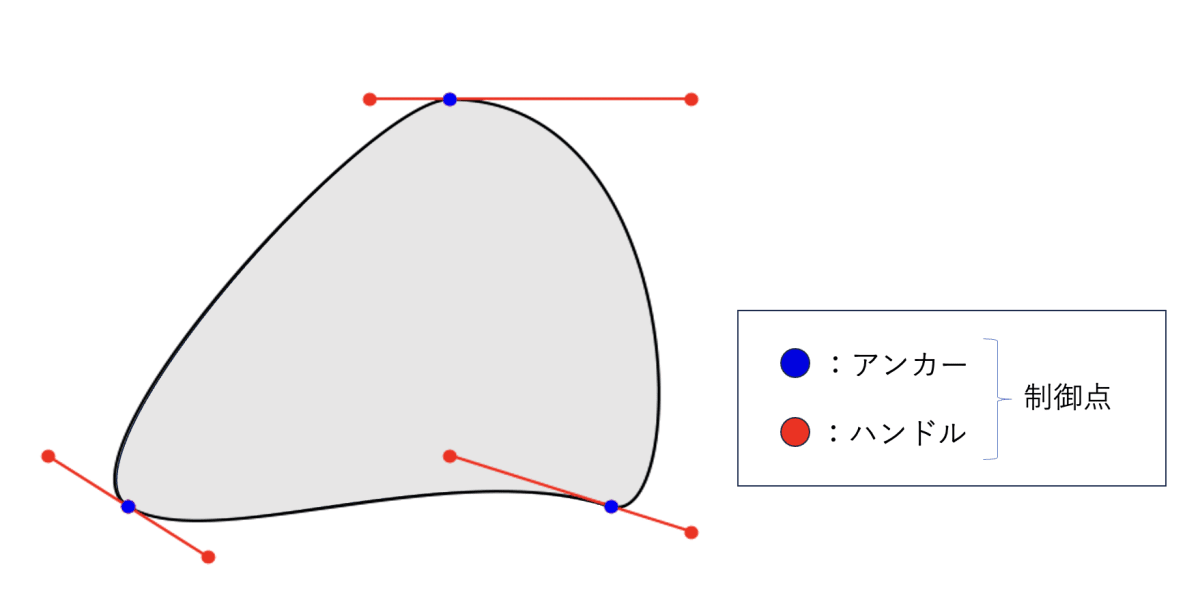
なかでもベジェ曲線は、円弧などよりも表現の幅が広く、アンカーやハンドルをつまんで動かすと直感的に曲線を操作できることから、図形を扱うツールでよく使われています。一例を次の図に示します。どこかで見たことがある方も多いのではないでしょうか。
DiffVGとは
DiffVG(Differentiable Vector Graphics) はアドビとMITによる研究で、ベクターグラフィクスのラスタライザを自動微分に対応させる研究です。pytorch/tensorflowと連携して使えるpythonライブラリが実装されています。通常の描画過程には微分できない処理が入っているため、DiffVGでは近似計算など行うことでこれを可能にしています。
このように描画過程を微分可能にする手法はどちらかというと3次元グラフィクスで盛んに研究されており、その方面では微分可能レンダラーと呼ばれています。
ディープラーニングでベクターグラフィクスを扱う研究のほとんどが、このDiffVGを使っています。
微分可能だとなにがいいのか
「微分」と聞くと帰りたくなる人もいるかも知れませんが、大雑把に「入力を少し変えたとき関数の出力がどう変わるか」ぐらいのイメージで捉えてください。
ベクターグラフィクスのラスタライザでいえば、入力はベジェ曲線の制御点や色などのパラメータ、出力はラスター画像です。つまり、ラスタライザを微分できると、パラメータを少し動かしたときに画像がどう変わるかがわかるようになります。さらに、この情報をうまく使うことで、逆に画像を目標としてパラメータを最適化できるようになります。
現状の画像系AIではラスター画像を扱うものがほとんどですので、微分可能ラスタライザは最新の研究成果をベクターグラフィクスの世界に持ち込むという重要な役目をもっているといえます。
DiffVGはフォントに関連する研究でも使われており、例えば自動生成した文字のベクター化に挑戦したDeepVecFontや、指定したモチーフに見えるように文字形状を変形させるWord-as-Imageなどがあります。
使い方等
インストール
pipインストーラーが無いので気楽さはないですが、READMEを参考にすれば大丈夫です。
READMEに記載の手順はsetup.pyを使うものとpoetryを使うものがあります。ここではsetup.pyを使う方法を紹介します。
setup.pyを使う方法ではconda/pipでライブラリ等をインストールする手順となっています。diffvgそのものに必要なライブラリ以外に、サンプルの実行に必要なライブラリも併記されていますので、ここで用途別に整理しておきます:
- 本体ビルドに必要なツール:
cmake - 本体動作に必要なpythonパッケージ:
torch torchvision numpy scikit-image cssutils svgpathtools - サンプル動作に必要なツール:
ffmpeg - サンプル動作に必要なpythonパッケージ:
torch-tools visdom svgwrite numba
diffvgそのものに必要なのは上記1と2だけですので、cmakeさえ用意しておけば残りはpipでインストールできます。condaは無くても大丈夫です。
ここではcmakeのインストールについては割愛し、venvの仮想環境内でdiffvgを使えるようにするまでの手順を記載しておきます。
まずvenvで仮想環境を作ります:
python -m venv venv
source venv/bin/activate
必要なパッケージをインストールします:
pip install torch torchvision numpy scikit-image cssutils svgpathtools
diffvgをビルドしてインストールします:
git clone https://github.com/BachiLi/diffvg
cd diffvg
git submodule update --init --recursive
python setup.py install
これでdiffvgを使えるようになります。
API
DiffVGにはAPIドキュメントが用意されていませんが、サンプルアプリがリポジトリのappsフォルダ以下に多数ありますので、これを参考にするのがよいと思います。
サンプルコード
リポジトリのサンプルコードsingle_curve.pyを参考に基本的な動作を解説します。
このサンプルでは、制御点9個(アンカー3個・ハンドル6個)からなる3次ベジェ曲線について、ラスタライズ後の画像が、あらかじめ用意した目標画像に近づくように制御点および色の最適化を行っています。
サンプルコードの目標画像生成と最適化の部分が混ざっていわかりにくいので、目標画像をファイル読み込みに変更して整理すると、次のように見通しがよくなります:
import pydiffvg
import torch
import numpy as np
import skimage
# GPUが使える場合は使う
pydiffvg.set_use_gpu(torch.cuda.is_available())
# 目標画像を読み込む
target = torch.from_numpy(skimage.io.imread("results/target.png")).to(torch.float32) / 255.0
# 条件設定
canvas_width, canvas_height = 256, 256 # 画像サイズは256x256
num_control_points = torch.tensor([2, 2, 2]) # 3ノードの閉じたベジェ曲線で、各点ごとに2個の制御点を持つ想定
scale = torch.tensor([[canvas_width, canvas_height]], dtype=torch.float32) # 正規化を元に戻すときに使うスケール
# 制御点パラメータ:最適化対象
# 初期値は正解値を少しずらしたものになっている
# 変数が典型的な値におさまるよう正規化している
points_n = torch.nn.Parameter(torch.tensor([
[100.0/canvas_width, 40.0/canvas_height], # base
[155.0/canvas_width, 65.0/canvas_height], # control point
[100.0/canvas_width, 180.0/canvas_height], # control point
[ 65.0/canvas_width, 238.0/canvas_height], # base
[100.0/canvas_width, 200.0/canvas_height], # control point
[170.0/canvas_width, 55.0/canvas_height], # control point
[220.0/canvas_width, 100.0/canvas_height], # base
[210.0/canvas_width, 80.0/canvas_height], # control point
[140.0/canvas_width, 60.0/canvas_height]])) # control point
# 色パラメータ:最適化対象
color = torch.nn.Parameter(torch.tensor([0.3, 0.2, 0.5, 1.0]))
# 引数を用意
path = pydiffvg.Path(num_control_points = num_control_points,
points = points_n*scale,
is_closed = True)
shapes = [path] # 形状のリスト:ラスタライズ時の引数になる。
path_group = pydiffvg.ShapeGroup(shape_ids = torch.tensor([0]), # shapes内のインデックスを指定する
fill_color = color) # グループでまとめて色を指定できる
shape_groups = [path_group] # 形状グループのリスト:ラスタライズ時の引数になる
# Optimizer指定
optimizer = torch.optim.Adam([points_n, color], lr=0.02)
# 最適化ループ
for t in range(100):
optimizer.zero_grad()
# パラメータ再設定
# 各iterationで再設定が必要。
path.points = points_n * scale
path_group.fill_color = color
# 引数の前処理
scene_args = pydiffvg.RenderFunction.serialize_scene(\
canvas_width, canvas_height, shapes, shape_groups)
# ラスタライズ実行
# 内部の近似で乱数を使っているためnum_samples_x/y, seedを指定する。num_samples_x/yは後続研究でも2を使っているものが殆ど。
img = pydiffvg.RenderFunction.apply(canvas_width, # width
canvas_height, # height
2, # num_samples_x
2, # num_samples_y
t+1, # seed
None, # background_image
*scene_args)
# 損失関数を計算(平均二乗誤差)
loss = (img - target).pow(2).mean()
# 動作確認用
print('loss:', loss.item())
pydiffvg.imwrite(img.cpu(), f'results/iter_{t:02d}.png', gamma=2.2)
# バックプロパゲーション
loss.backward()
# パラメータ更新
optimizer.step()
これで、目標画像に向かって制御点の座標と色の最適化が実行できるようになります。
実行結果をみてみましょう。
目標画像はこちら:

そして最適化の進行はこのような具合です:

ちゃんと動いていそうですね。
フォントを扱ってみる
これだけではサンプルコードをなぞっただけで面白くないので、フォントを扱えるようにしてみます。
制御点を一つ一つ取ってきて展開してもよいのですが、SVGを読み込む機能が用意されていますので、「文字のアウトライン → SVG → DiffVG ShapeGroup」という形で実装してみました:
from fontTools.ttLib import TTFont
from fontTools.pens.svgPathPen import SVGPathPen
from fontTools.pens.transformPen import TransformPen
from fontTools.misc.transform import Transform
from tempfile import NamedTemporaryFile
def prepare_glyph_scene(character:str, font_path:Path, width:int, height:int):
# 文字のアウトラインをdiffvgで使える形で取り出す
assert(len(character)==1)
font = TTFont(font_path)
glyph_name = font.getBestCmap()[ord(character)]
glyph_set = font.getGlyphSet()
pen = SVGPathPen(glyph_set)
ascender, descender = font['OS/2'].sTypoAscender, font['OS/2'].sTypoDescender
w = h = ascender - descender
t = Transform(width/w, 0, 0, -height/h, 0, height).translate(x=0, y=-descender)
tpen = TransformPen(pen, transformation=t)
glyph_set[glyph_name].draw(tpen)
with NamedTemporaryFile("w") as tmpf:
tmpf.write(f'<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 {width} {height}"><path d="{pen.getCommands()}"/></svg>')
tmpf.flush()
_w, _h, shapes, shape_groups = pydiffvg.svg_to_scene(tmpf.name)
for sg in shape_groups:
sg.fill_color = torch.tensor([0.0, 0.0, 0.0, 1.0])
sg.stroke_color = None
return shapes, shape_groups
最適化をやってみましょう。
例題の設定としては、各制御点をバラバラに撹乱した状態(before)から、元の状態(after)のラスター画像を目標として、制御点を修正するというタスクにしてみます。
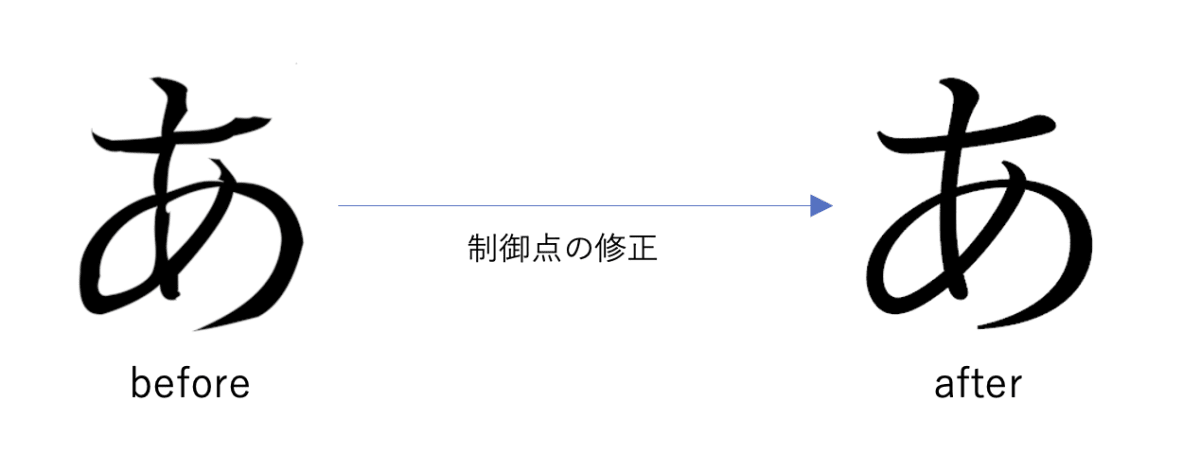
最適化のコードは先程とほとんど同じで動きます。動かしてみましょう。

うまくいっているように見えますね。
といっても、実は細かいところをベクター画像として拡大して見ると、最適化時のサイズでは見えなかったようなひび割れ形状や曲線の交差がみられたりします。ですので、制御点を修正したというよりも、ある解像度で同じ画像に見えるような制御点が得られた、というほうが正確な認識です。
実用シーンでは、制御点を追加調整したり、何らかの正則化や拘束条件を追加するなど、このような異常な制御点の配置にならない工夫が必要になります。
おわりに
微分可能ラスタライザであるDiffVGについて、その導入から基本的な使い方、そしてフォントの文字形状を編集する実験まで紹介しました。
本記事がベクターグラフィクスxAIに取り組む方の助けになれば幸いです。

Discussion