34週目: 2種のattentionを用いたニュース推薦タスク用の(王道?)コンテンツベース手法 NRMS の論文を読んだ!
NRMS: Neural News Recommendation with Multi-Head Self-Attention
published date: November 2019,
authors: Chuhan Wu, Fangzhao Wu, Suyu Ge, Tao Qi, Yongfeng Huang, Xing Xie
url(paper): https://aclanthology.org/D19-1671/
(勉強会発表者: morinota)
n週連続推薦システム系論文読んだシリーズ 34 週目の記事になります。
ちなみに33週目は 異種行動データによるimplicit feedbackの分布の違いを考慮して推薦モデルを学習させるMBAの論文を読んだ! でした!
どんなもの?
- (本論文を読んだ理由):
- ニュース推薦タスクに特化したある程度ナウい、王道なdeepのコンテンツベース手法を把握しておきたかった。
- 本論文の手法が https://arxiv.org/abs/2106.08934 や https://arxiv.org/pdf/2104.07413 などで紹介されていたので、王道っぽい手法だと思い読んでみた。
- (論文概要):
- ニュース推薦タスク用のコンテンツベース推薦手法 NRMS を提案した2019年の論文。
- (ちなみに2021年の同著者の論文で、事前学習済み言語モデルを使う方法に拡張されてた: n週連続推薦システム系 論文読んだシリーズ27週目: 事前学習済み言語モデルをNews Encoder部分に用いて、ニュース推薦の品質を向上させる論文を読んだ!(2021年))
-
ニュースとユーザ嗜好の特徴をより良く反映した (i.e. ニュース推薦タスクに関する4つの洞察を考慮するように調整された) 埋め込み表現を得るために、news encoder部分とuser encoder部分に2種のattention機構を採用してる。
- ニューステキストに含まれる単語間、ユーザ閲読履歴に含まれるニュース間の相互作用を考慮したい...! -> multi-head self-attention層を採用。
- ニューステキスト内の各単語、ユーザ閲読履歴内の各ニュースの重要度の違いを考慮したい...! -> additive attention層を採用。
- 学習時には、同一impression内でクリック/クリックされなかったニュース履歴を学習データとする。(ここは結構シンプル)
- ニュース推薦タスク用のコンテンツベース推薦手法 NRMS を提案した2019年の論文。
- (感想):
- attention機構の使い方は、任意の言語モデルを使うコンテンツベース推薦手法に応用できそう。
- NRMS自体の推論処理はベクトル間の内積による軽量な処理なので、2-stages推薦システムにおける1-stage目 candidate retrieve に使えそう。
- NRMSの成果物としてニュースとユーザ嗜好の埋め込み表現が得られるので、2-stages推薦システムにおける2-stage目 candidate ranking の特徴量としても使えそう。
- (ちなみに...)FTI pipelinesアーキテクチャを意識した上で実プロダクト上でNRMSを開発・運用するための設計を想像すると、例えば以下の4つだろうか? :thinking:
-
- news encoderとuser encoderのパラメータを学習し学習済みモデルを保存する学習パイプライン。
- (低頻度のバッチ処理。月1回くらいの学習で十分?)
-
- ニューステキストからニュースベクトルを作って保存する news encoder の推論パイプライン(特徴量生成パイプライン)。
- (新規ニュースがDBに追加されるたびに走るオンライン処理 or 高頻度のバッチ処理。)
- (encoderは推論してるけど、ニュースベクトルを特徴量と見做すなら「特徴量パイプライン」...!)
-
- ユーザの閲読履歴からユーザベクトルを作る 。user encoderの推論パイプライン(特徴量生成パイプライン)
- (ユーザの閲読履歴が更新されるたびに走るオンライン処理 or 高頻度のバッチ処理。)
- (i.e. news encoderの推論同様に「特徴量パイプライン」とも言ってもいいはず)
-
- 作成済みのニュースベクトルとユーザベクトルを使って候補記事をスコアリングして推薦結果を作る、推論パイプライン。
- (新規ニュースを推薦できるようにしたいケースを想定すると、高頻度のバッチ処理 or オンライン処理。)
- (NRMSのみで推薦結果を作るなら、スコアリングは内積なので、時間速度的にはオンライン推論でも可能。ただ、特にリクエスト側の入力情報をスコアリングに使用しなければ、バッチ推論で良いと思う。)
-
先行研究と比べて何がすごい?
- ニュースとユーザに関する正確な埋め込み表現を学習することは、ニュース推薦における中核タスク。
- (ここで「正確な」という意味は、「推薦タスクに有用な」とか「特徴をより良く表現した」みたいなイメージ:thinking:)
- 深層学習ベースの既存手法:
- Okura et al.(2017): Triplet loss損失関数 & auto-encodersでニュース本文からニュース表現を学習し、GRU(RNN系の手法)によって閲読履歴からユーザ表現を学習させてた。
- 単語間の相互作用や重要度の違いを考慮できない。GRUは計算量が多くて時間がかかる。
- Wang et al.(2018): knowledge-awareなCNNでニュースタイトルからニュース表現を学習し、閲読履歴のニュースの類似性に基づいてユーザ表現を学習させてた
- CNNは単語間の長距離の相互作用を考慮できない。閲覧ニュース間の相互作用も考慮できない。
- Okura et al.(2017): Triplet loss損失関数 & auto-encodersでニュース本文からニュース表現を学習し、GRU(RNN系の手法)によって閲読履歴からユーザ表現を学習させてた。
技術や手法の肝は?
提案手法 NRMS のモチベーション

(論文より引用)
本論文の提案手法 NRMS は、ニュース推薦に関する4つの洞察に動機づけられている:
- 洞察1: ニュースタイトルに含まれる単語間の相互作用は、ニュースを理解するのに重要。
- ex. 図1において、RocketsとBullsは強い関連性を持っており、これらの単語の組み合わせが対象ニュースの特徴となりうる。
- (i.e. 単語Aと単語Bが一緒の文章に含まれていることが対象ニュースの特徴を表現する上で重要。特徴量間の相互作用を考慮したいって話だよね:thinking:)
- 洞察2: ユーザの閲覧履歴に関するニュース間の相互作用は、ユーザを理解するのに重要。
- ex. 図1において、2番目のニュースは1番目と3番目のニュースと関連性を持っており、これらのニュースの組み合わせが対象ユーザの興味の特徴となりうる。
- 洞察3: 品質の高いニュース表現を得る上で、ニュースタイトル内の単語によって重要性の高さが異なる。
- ex. 図1において、"2018"よりも"NBA"の方が、ニュースの特徴を表現する上で有用そうである(i.e. 情報量が多い)。
- 洞察4: 品質の高いユーザ表現を得る上で、閲覧履歴内のニュースによって重要性の高さが異なる。
- ex. 図1において、4番目のニュースよりも1 ~ 3番目のニュースの方が、ユーザの特徴を表現する上で有用そうである(i.e. 情報量が多い)。
上記の4つの洞察を考慮できる手法として、本論文ではNRMS (Neural news Recommendation approach with Multi-head Self-attention) を提案している。
NRMSのアーキテクチャ概要
NRMSのアーキテクチャは、大きく news encoder と user encoder と click predictor の3つのcomponentから構成される:
図2はNRMSのアーキテクチャ。(左側がnews encoder、中央がuser encoder)

(論文より引用)
- news encoder:
- ニュースタイトルからニュース表現を学習する。
- 洞察1を考慮するためにmulti-head self-attentionを、洞察3を考慮するためにadditive attentionを採用してる。
- user encoder:
- ユーザのニュース閲覧履歴からユーザ表現を学習する。
- 洞察2を考慮するためにmulti-head self-attentionを、洞察4を考慮するためにadditive attentionを採用してる。
- click predictor:
- ユーザ表現とニュース表現を用いて、ユーザが対象ニュースをクリックする確率を予測する。
- ここは既存研究に習い、シンプルにdot productを用いてる。他の種類のスコアリング方法も試したが、ドット積が最も優れた性能と効率を示したらしい。(効率はそりゃそうだと思うけど、性能も優れてたんだ...!:thinking:)
News Encoderのアーキテクチャ
News encoderは以下の3層で構成されている:
-
- word embedding層
-
- word-level multi-head self-attention層
-
- word-level additive attention層
1層目はword embedding層:
- 観察可能な振る舞い:
- 入力: 記事タイトルのテキスト(単語のsequence)
[w_1, w_2, ..., w_M] - 出力: 単語埋め込みベクトルのsequence
[e_1, e_2, ..., e_M]
- 入力: 記事タイトルのテキスト(単語のsequence)
- 実装の詳細:
- 何らかのNLP手法や言語モデルによって各単語を埋め込む。
2層目はword-level multi-head self-attention層:
観察可能な振る舞い:
- 入力: 単語埋め込みベクトルのsequence
[e_1, e_2, ..., e_M] - 出力: 単語間の相互作用を考慮した単語表現ベクトルのsequence
[h^{w}_1, h^{w}_2, ..., h^{w}_M]
実装の詳細:
- k番目のattention headによって得られる、i番目の単語の隠れ表現
h_{i,k}^{w}
- ここで...
-
Q_{k}^{w} V_{k}^{w} -
alpha_{i,j}^{k} w_{i} w_{j}
-
- 最終的なi番目の単語の、単語間の相互作用を考慮した表現
h_{i}^{w} \mathbf{h}_{i,k}^{w} - すなわち、
h_{w}^{i} = [h_{w}^{i,1} ; h_{w}^{i,2} ; ...; h_{w}^{i,h}]
- すなわち、
3層目はword-level additive attention層:
観察可能な振る舞い:
- 入力: 単語間の相互作用を考慮した単語埋め込みベクトルのsequence
[h^{w}_1, h^{w}_2, ..., h^{w}_M] - 出力: 単語間の相互作用 & 各単語の重要度を考慮した最終的なニュース埋め込みベクトル
\mathbf{r}
実装の詳細:
- まずi番目の単語の attention weight
\alpha^{w}_{i} - (式3はadditive attentionの式。
q_{w} V_{w} v_{w} - (式4のように、最終的なattention weightはsoftmaxで正規化される)
- (式3はadditive attentionの式。
- ここで...
-
V_{w} v_{w} q_{w}
-
-
最終的なニュース表現は以下。
- contextual word representations(2層目の出力)の重み付き合計として定式化される:
User Encoderのアーキテクチャ
User encoderは以下の2層で構成されている:
- news-level multi-head self-attention層
- news-level additive attention層
1層目はnews-level multi-head self-attention層:
観察可能な振る舞い:
- 入力: ユーザの閲覧履歴のニュース埋め込み表現のsequence
[r_1, r_2, ..., r_N] r - 出力: ニュース間の相互作用を考慮したニュース埋め込み表現のsequence
[h^{n}_1, h^{n}_2, ..., h^{n}_N]
実装の詳細:
- (基本的にnews encoderの2層目と同じ。ニュースをユーザに、単語をニュースに置き換えたver.)
2層目はnews-level additive attention層:
観察可能な振る舞い:
- 入力: ニュース間の相互作用を考慮したニュース埋め込み表現のsequence
[h^{n}_1, h^{n}_2, ..., h^{n}_N] - 出力: ニュース間の相互作用 & 各ニュースの重要度を考慮した最終的なユーザ埋め込みベクトル
\mathbf{u}
実装の詳細:
- (基本的にnews encoderの3層目と同じ。ニュースをユーザに、単語をニュースに置き換えたver.)
NRMSの学習方法
- negative sampling技術を使用してpositive exampleとnegative exampleを用意して教師あり学習をする。
- 具体的には、ユーザによって閲覧された各ニュース(positive sample)について、**同じインプレッションに表示されたがユーザによってクリックされなかったニュース(negative sample)**をK個無作為にサンプリングする。
- (一般的なimplicit feedbackのpositive sampleしか観測されない状況での未観測アイテムを頑張って工夫してnegative samplingする、という感じではなかった。シンプルでありがたい...!:thinking:)
- positive sampleの事後クリック確率を定義:
- 1個のpositive newsとK個のnegative newsのクリック確率スコアをそれぞれ
\hat{y}^{+} [\hat{y}^{-}_{1}, \hat{y}^{-}_{2}, ..., \hat{y}^{-}_{K}] - スコアをsoftmax関数に通す事で、陽性サンプルの事後クリック確率を計算する:
- 1個のpositive newsとK個のnegative newsのクリック確率スコアをそれぞれ
- 損失関数:
- ニュースのクリック確率予測問題を、擬似的な(K + 1)個分類タスクとして定式化し、損失関数を「全てのpositive sample
S - (要はmaximum likelihood estimation...!:thinking:)
- ニュースのクリック確率予測問題を、擬似的な(K + 1)個分類タスクとして定式化し、損失関数を「全てのpositive sample
どうやって有効だと検証した?
MINDデータセットを使ったオフライン実験
- 使用データセット:
- MINDデータセット(Microsoft News Dataset)を使用。
- MSN Newsの1ヶ月間(2018年12月13日から2019年1月12日まで)のログから収集した実世界のニュースデータ。
- 最終週のログはテスト用データ。残りが学習用データ。
- 学習データのうち、ランダムに10%を検証用データとする。
- 実装の詳細:
- 単語埋め込みは300次元。(Glove埋め込み)
- self-attentionのhead数は16。各headの出力は16次元。
- additive attentionのクエリベクトルの次元数は200。
- negative sampling比
K - optimizerはAdam。
- over fittingを防ぐために、単語埋め込みい20%の確率で0ベクトルに置き換えるdropoutを使用。
- batch sizeは64
- 評価指標:
- テストデータに対するAUC、MRR、nDCG@5、nDCG@10。
- 各実験を独立に10回繰り返し、その平均値を報告。
- 比較するベースライン手法:
- 非deepな推薦手法
- ニュース間の相互作用を考慮しないdeepな推薦手法
- ニュース間の相互作用を考慮するdeepな推薦手法
議論はある?
オフライン精度の話(図2)
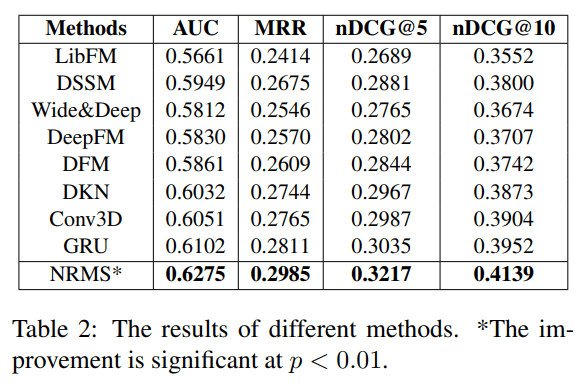
(論文より引用)
結果からわかった事:
-
- deepな推薦手法は非deepな推薦手法よりもオフライン性能が高かった。
-
- deepな推薦手法の中でも、ニュース間の相互作用を考慮する手法の方が、考慮しない手法よりもオフライン性能が高かった。
-
- NRMSは、ニュース間の相互作用を考慮する手法の中でも最もオフライン性能が高かった。
時間計算量の話
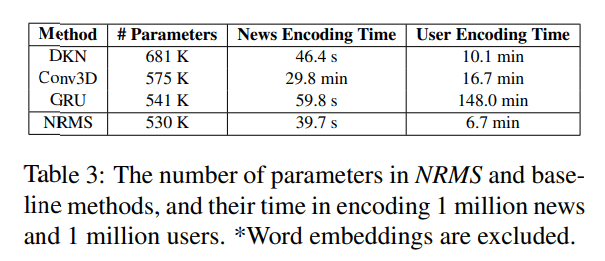
(論文より引用)
結果からわかった事:
- NRMSは、既存のニュース推薦手法と比較して、時間計算量が小さい。
- ニュース表現やユーザ表現を学習する際のパラメータサイズが小さいから。
- また、推論時はニュース表現とユーザ表現のドット積を計算するだけだから。
- 更にNRMSは、異なるattention headsの隠れ表現
h_{i}^{hoge}
NRMSの各componentsの重要性の話
ablation studyを行った結果からわかった事:
図3はablation studyの結果。
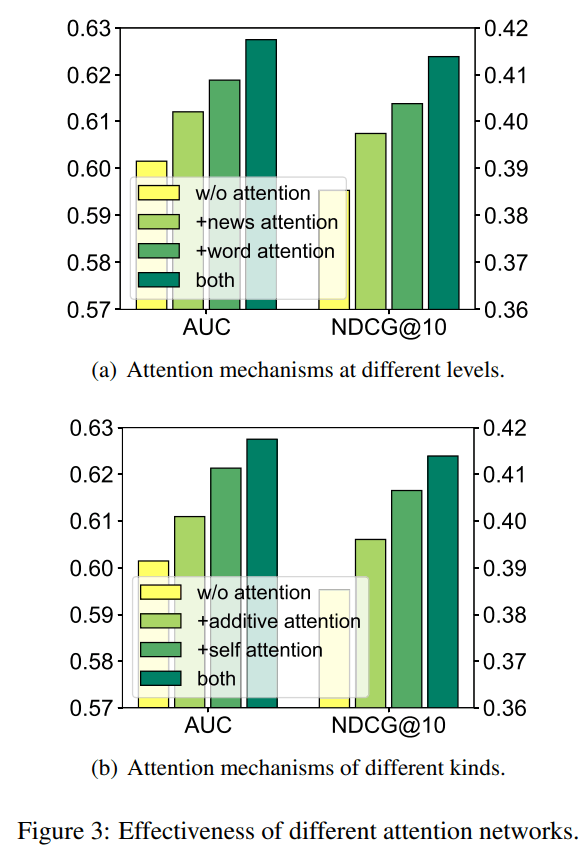
(論文より引用)
-
word-levelとnews-levelのattentionネットワークに関するablation study(figure 3 a):
- word-levelのattentionが特に性能向上に寄与する事がわかった。
- また、news-levelのattentionも、word-levelのattentionほどではないが、性能向上に寄与する事がわかった。
- そして、word-levelとnews-levelのattentionを組み合わせたモデルが最も性能が高かった。
-
multi-head self-attentionとadditive attentionに関するablation study(figure 3 b):
- multi-head self-attentionが性能向上に寄与する事がわかった。
- また、additive attentionも、multi-head self-attentionほどではないが、性能向上に寄与する事がわかった。
- そして、multi-head self-attentionとadditive attentionを組み合わせたモデルが最も性能が高かった。
今後の拡張性の話
- 単語やニュースのsequenceの順序情報の活用:
-
実はNRMSは、単語やニュースのsequenceの順序情報を考慮していない。
- (NRMSだと、attentionに入力する前にpositional encodingみたいな事をやってないので...!:thinking:)
- (ニュースのsequenceの順序情報を使うってことは、つまりsequential recommenderへ拡張するってことか:thinking:)
-
実はNRMSは、単語やニュースのsequenceの順序情報を考慮していない。
- ニュースタイトル以外の属性情報の活用:
- 特に、self-attentionネットワークの効率性を脅かす可能性のあるニュース本文などの長いsequence情報をいかに効果的に扱うか。
次に読むべき論文は?
お気持ち実装
recboleで実験することを想定して、お気持ち実装。
news encoder。
class NewsEncoder(nn.Module):
def __init__(self, config: Config, word_embedding: nn.Embedding) -> None:
super().__init__()
self.config = config
self.word_embedding = word_embedding
self.dropout_prob = config["dropout_prob"] # 0.2
self.dim_per_head = config["embedding_size"] // config["num_attention_heads"]
assert config["embedding_size"] == self.dim_per_head * config["num_attention_heads"] # ちょうど割り切れてほしいってことか。
self.multi_head_self_attn = MultiHeadSelfAttention(
config["embedding_size"],
config["num_attention_heads"],
self.dim_per_head,
self.dim_per_head,
)
self.additive_attn = AdditiveAttention(
config["embedding_size"],
config["news_query_vector_dim"],
)
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x: (batch_size, word_num_per_news) (tokenizeは完了済み)
Returns:
(shape): batch_size, embedding_size
"""
# word embedding layer
word_vecs = F.dropout(
self.word_embedding(x),
p=self.dropout_prob,
training=self.training,
) # (shape): batch_size, word_num_per_news, word_dim
# word-level multi-head self-attention layer
multihead_word_vecs = F.dropout(
self.multi_head_self_attn(word_vecs, word_vecs, word_vecs),
p=self.dropout_prob,
training=self.training,
) # (shape): batch_size, word_num_per_news, embedding_size
# word-level additive attention layer
return self.additive_attn(multihead_word_vecs) # (shape): batch_size, embedding_size
user encoder。
class UserEncoder(nn.Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.config = config
self.dim_per_head = config["embedding_size"] // config["num_attention_heads"]
self.multi_head_self_attn = MultiHeadSelfAttention(
config["embedding_size"],
config["num_attention_heads"],
self.dim_per_head,
self.dim_per_head,
)
self.additive_attn = AdditiveAttention(
config["embedding_size"],
config["news_query_vector_dim"],
)
# reading histroyの欠損をpaddingするためのベクトルを初期化
self.padding_vector: Tensor = nn.Parameter(torch.empty(1, config["embedding_size"]).uniform_(-1, 1)).type(
torch.FloatTensor
) # (shape): 1, embedding_size
def forward(self, news_vectors: Tensor) -> Tensor:
"""
Args:
news_vectors: (batch_size, history_length, news_dim)
Returns:
(shape): batch_size, news_dim
"""
batch_size = news_vectors.shape[0]
padding_doc = self.padding_vector.unsqueeze(0).expand(
batch_size, self.config["history_length"], -1
) # (shape): batch_size, history_length, news_dim
padded_news_vecs = news_vectors + padding_doc # (shape): batch_size, history_length, news_dim
multi_head_news_vecs = self.multi_head_self_attn(padded_news_vecs, padded_news_vecs, padded_news_vecs)
return self.additive_attn(multi_head_news_vecs)
recboleのAbstractRecommenderを継承したNRMSクラス。
class NRMS(AbstractRecommender):
def __init__(self, config: Config, dataset: Dataset) -> None:
super(NRMS, self).__init__(config, dataset)
self.config = config
pretrained_word_embedding = torch.from_numpy().float()
word_embedding = nn.Embedding.from_pretrained(pretrained_word_embedding, freeze=True)
self.news_encoder = NewsEncoder(config, word_embedding)
self.user_encoder = UserEncoder(config)
self.loss_fn = nn.CrossEntropyLoss()
def calculate_loss(self, interaction: Interaction) -> Tensor:
"""
Args:
interaction: Interaction (batch_size, history_length, num_words_per_news)
データローダーから渡されるレコード集合。
Returns:
loss: Tensor (1)
"""
reading_histories = interaction[self.reading_history] # (batch_size, history_length, num_words_per_news)
candidates = interaction[self.news_candidate] # (batch_size, 1+K, num_words_per_news)
labels = interaction[self.label] # (batch_size, 1+K)
candidate_news_vecs = self.news_encoder(candidates) # (batch_size, 1+K, news_vec_dim)
history_news_vecs = self.news_encoder(reading_histories) # (batch_size, history_length, news_vec_dim)
user_vectors = self.user_encoder(history_news_vecs) # (batch_size, news_vec_dim)
scores = torch.bmm(candidate_news_vecs, user_vectors) # (batch_size, 1+K, 1)
return self.loss_fn(scores, labels)
def predict(self, interaction: Interaction) -> Tensor:
reading_histories = interaction[self.reading_history] # (batch_size, history_length, num_words_per_news)
candidates = interaction[self.news_candidate] # (batch_size, num_words_per_news)
user_vectors = self.user_encoder(self.news_encoder(reading_histories)) # (batch_size, news_vec_dim)
candidate_news_vectors = self.news_encoder(candidates) # (batch_size, news_vec_dim)
return torch.bmm(user_vectors, candidate_news_vectors) # (batch_size, 1)
Discussion