対象読者
この記事は以下の読者を想定しています:
- LLMの基礎を理解しており、ローカル環境での活用に興味があるエンジニア
- ローカルLLM環境の構築と性能検証に興味がある開発者
- ローカルLLMの実用性について知りたい技術者
- Google Colab無料枠でローカルLLMを試してみたい方
概要
Cursorのトークン制限問題を解決するため、Google Colab + Qwen3-Coder-30BでローカルLLM環境を構築した。Web検索と長期記憶機能を統合したコーディング支援システムを実装し、技術的な検証を行った。
結果: 技術的には動作するが、実用面では課題も発見した。検証結果を詳しく報告する。
動機:Cursorの制限を何とかしたかった
Cursorを使っていると時々発生する問題:
- トークン制限による作業中断
- 月額コストの継続的な負担
これらの問題を解決するため、ローカル環境で動作するLLMベースのコーディング支援システムの構築を試みた。
構築したかった環境:
- トークン制限なし
- 完全にローカルで動作
- 継続的なコスト不要
- LLMの仕組みを学習できる
実際のGPU環境を用意するのはハードルがあったため、技術検証としてGoogle Colab無料枠を使ってこのシステムの実現可能性を調査した。
Google Colab無料枠の制約による問題:
-
メモリ制限: 12GBのRAM制限により、GPUレイヤーを0に設定せざるを得ない
- 影響: 大規模なデータセットや複雑なモデルの処理が困難
- 結果として今回はCPU環境での検証になってしまった
-
セッション制限: 長時間のアイドル状態でセッションが切れるリスクがある
- 影響: 長時間の処理中に作業が中断される可能性がある
-
CPU性能: 無料枠のCPU性能が限定的で、推論速度が大幅に低下する
- 影響: 商用サービスと比較して数十倍の処理時間が必要である
-
接続の不安定性: 長時間の処理中にセッションが切れるリスクがある
- 影響: 複雑なタスクの完了前に中断される可能性がある
環境構築:期待と現実のギャップ
環境情報
- 実行環境: Google Colab (無料枠)
- Python: 3.12
-
主要ライブラリ:
- llama-cpp-python (0.3.16) - LLM実行
- huggingface-hub - モデル管理
- chromadb - ベクトルデータベース
- sentence-transformers - 埋め込み生成(intfloat/multilingual-e5-large)
Hugging Faceトークンの準備
1. profileからAccess tokensを選択

2. Create new tokenを選択
3. Read権限でトークンを作成。モデルダウンロードに必要
Google ColabでのSecrets設定方法:
- Colabの左サイドバーから「🔑」アイコン(Secrets)をクリック
- 「新しいシークレットを追加」ボタンをクリック
- 名前:
HUGGINGFACE_HUB_TOKEN、値: 作成したトークンを入力
モデル選択の理由
Qwen3-Coder-30Bを選択した理由:
- コード特化: プログラミングタスクに特化して訓練されたモデル
- 多言語対応: Python、JavaScript、Go、Rustなど幅広い言語に対応
- 量子化版の利用可能性: Q4_K_M量子化版(約2.2GB)でメモリ効率が良い
- ライセンス: Apache 2.0ライセンスで商用利用可能
他のモデルとの比較:
- Llama 2: 汎用性は高いが、コード生成特化ではない
- CodeLlama: コード特化だが、より大きなモデルサイズ
- StarCoder: コード生成に優れるが、日本語対応が限定的
環境構築の実装
Google Colab無料枠での制約を考慮しつつ、以下のコードで環境を構築した:
# ==============================================================================
# Part 1: 環境構築とAIのセットアップ (GPU利用最適化版)
# ==============================================================================
# --------------------------------------------------------------------------
# Step 1.0: Hugging Faceへのログイン
# --------------------------------------------------------------------------
from huggingface_hub import login
from google.colab import userdata
# ColabのSecretsからトークンを取得(推奨)
token = userdata.get('HUGGINGFACE_HUB_TOKEN')
login(token=token)
print("✅ Secretsからトークンを取得してログインしました。")
# --------------------------------------------------------------------------
# Step 1.1: 必要なライブラリのインストール
# --------------------------------------------------------------------------
print("\n⏳ Step 1.1: 必要なライブラリをインストール中...")
!pip install --upgrade --quiet pip
!pip install \
--extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu121 \
llama-cpp-python
!pip install huggingface-hub chromadb sentence-transformers requests beautifulsoup4 googlesearch-python --quiet
print("✅ Step 1.1: ライブラリのインストール完了!")
# --------------------------------------------------------------------------
# Step 1.2: unsloth版 Qwen3-Coder 30B GGUFモデルのダウンロード
# --------------------------------------------------------------------------
print("\n⏳ Step 1.2: AIモデル(unsloth/Qwen3-Coder 30B)をダウンロード中...")
from huggingface_hub import hf_hub_download
import os
os.makedirs("models", exist_ok=True)
hf_hub_download(
repo_id="unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF",
filename="Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf",
local_dir="./models",
local_dir_use_symlinks=False
)
print("✅ Step 1.2: モデルのダウンロード完了!")
# --------------------------------------------------------------------------
# Step 1.3: AIモデルのロードと起動確認
# --------------------------------------------------------------------------
print("\n⏳ Step 1.3: AIモデルをメモリにロード中...")
try:
from llama_cpp import Llama
print("✅ llama_cppライブラリのインポート成功!")
llm = Llama(
model_path="./models/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf",
n_gpu_layers=0, # GPUを使用しない
n_ctx=2048, # AIが一度に処理できる文章の長さ(コンテキストウィンドウ)です。
n_threads=2, # GPU利用時も、データ処理などでCPUが補助的に使われるためスレッド数を指定します。
verbose=False
)
print("✅ AIモデルのロード完了!いつでも使用可能です。")
except Exception as e:
print(f"❌ 処理中にエラーが発生しました: {e}")
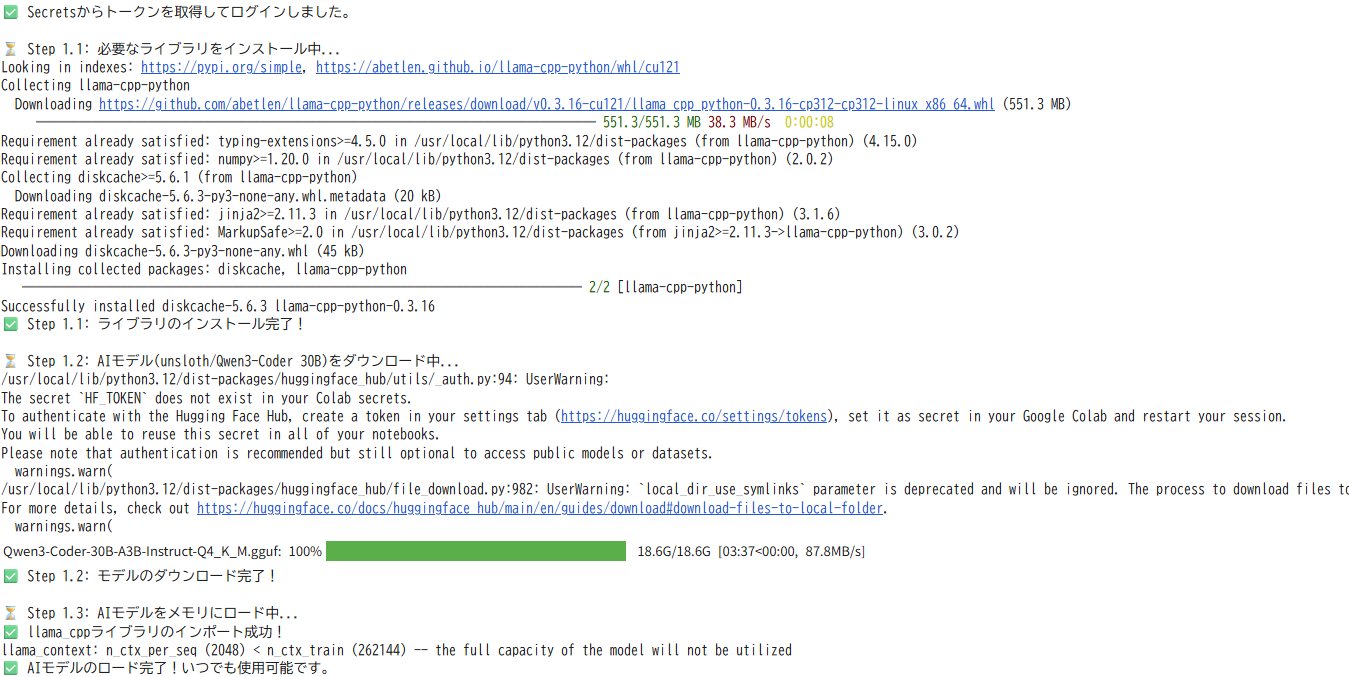
ライブラリのインストールからモデルダウンロードまでの一連の流れ
実際の動作結果:技術検証の成果
生成AIの利用について
利用目的:
このシステムでは、Qwen3-Coder-30Bをコード生成に利用している。生成されたコードは技術検証の目的で使用し、実際のプロダクション環境での利用を前提としていない。
検証方法:
- 生成されたコードの実行時間を測定
- コードの動作確認(Hello World、FizzBuzz等の基本タスク)
- 生成されるコードの品質を確認
基本的なタスクでの検証
プロンプト: "HelloWorldを出力するPythonコードを教えて"

シンプルなタスクでの動作確認。ストリーミング出力で生成過程が見える
検証結果:
- 生成コード:正確で実用的
- 実行時間:235.52秒
- 品質:完璧な実装と適切な説明付き
アルゴリズム系タスクでの検証
プロンプト: "1から100までの数字を出力するPythonコードを書いて。ただし、3の倍数の時は'Fizz'、5の倍数の時は'Buzz'、15の倍数の時は'FizzBuzz'を出力してください。"

より複雑なロジックを要するFizzBuzz問題での精度チェック
検証結果:
- 実行時間:334.80秒
- 実装品質:効率的なアルゴリズム
- 特徴:15で割り切れる場合の最適化も含む高品質なコード
システムの工夫:小さなモデルを強化する試み
30Bモデル単体では限界があるため、以下の機能を追加実装した。
基本的なコード生成機能
ストリーミング出力に対応したコード生成機能を実装した。タイムスタンプ付きのログ機能と組み合わせることで、生成過程を可視化できる。
def generate_code_simple(prompt: str, llm_instance):
"""AIに直接質問し、コードを生成するシンプルな関数"""
start_time = time.time()
stream = llm_instance.create_chat_completion(
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
stream=True
)
full_response = ""
for chunk in stream:
token = chunk['choices'][0].get('delta', {}).get('content')
if token:
print(token, end="", flush=True)
full_response += token
elapsed_time = time.time() - start_time
print(f"\n✅ 生成完了! (所要時間: {elapsed_time:.2f}秒)")
return full_response
長期記憶システムの導入
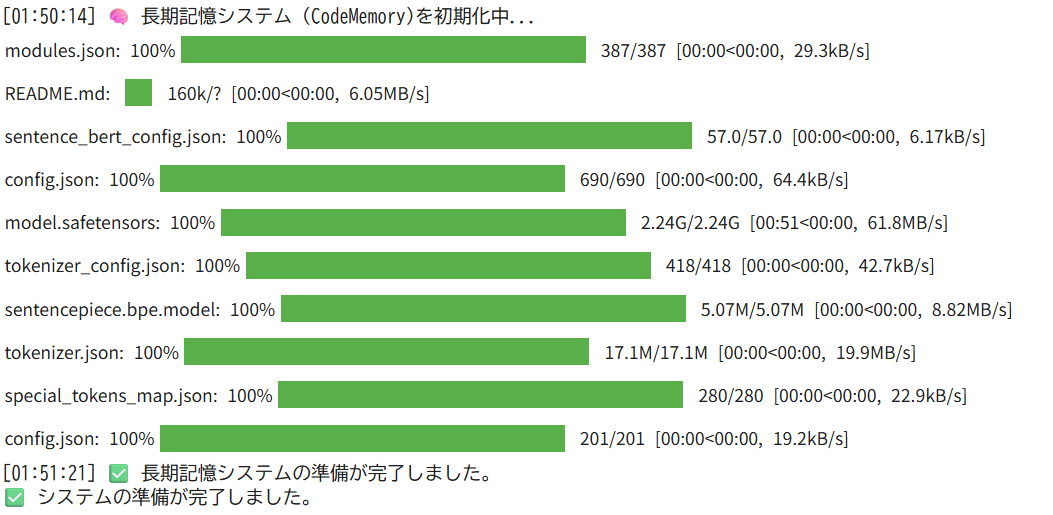
ChromaDBとSentence Transformersを使った記憶システムの構築
過去のコードをベクトル化して保存し、類似検索で再利用するシステムを実装した。これにより、一度生成したコードパターンを学習し、類似タスクで活用できる。
class CodeMemory:
"""過去のコードを記憶し、類似のものを検索する長期記憶システム"""
def __init__(self, model_name='intfloat/multilingual-e5-large'):
self.embedding_model = SentenceTransformer(model_name)
self.client = chromadb.PersistentClient(path="./code_memory_db")
self.collection = self.client.get_or_create_collection("code_snippets")
def save(self, code, description):
"""コードと説明を長期記憶に保存"""
doc_id = str(self.collection.count())
embedding = self.embedding_model.encode(f"Desc: {description}\nCode: {code}").tolist()
self.collection.add(
ids=[doc_id],
embeddings=[embedding],
documents=[code],
metadatas=[{"desc": description}]
)
def recall(self, query, n=1):
"""クエリに関連する過去のコードを検索"""
query_embedding = self.embedding_model.encode(query).tolist()
results = self.collection.query(query_embeddings=[query_embedding], n_results=n)
return results['documents'][0] if results['documents'] else []
Web検索機能との連携
最新の技術情報をリアルタイムで取得し、コード生成に活用する機能を実装した。Google検索APIとBeautifulSoupを組み合わせて、関連するチュートリアルやサンプルコードを自動収集する。
def get_web_context(query: str, num_results: int = 1) -> str:
"""リアルタイムでWebを検索し、最新情報を取得する短期記憶システム"""
context = ""
try:
urls = list(search(f"{query} tutorial example", num_results=num_results, sleep_interval=1, lang="ja"))
for url in urls:
response = requests.get(url, timeout=10, headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(response.text, 'html.parser')
page_text = "\n".join([
tag.get_text(" ", strip=True)
for tag in soup.find_all(['p', 'h2', 'h3', 'code'])
])
context += f"--- Webからの参考情報 ({url}) ---\n{page_text[:1500]}\n\n"
except Exception as e:
return f"Web検索中にエラーが発生しました: {e}"
return context
統合システム:複数の情報源を活用
長期記憶(過去のコード)と短期記憶(Web検索)を組み合わせて、より高品質なコード生成を実現する統合システムを構築した。
def generate_code_with_memory(prompt: str, llm_instance, memory_system=None):
"""長期記憶と短期記憶を統合し、最終的なコードを生成する"""
# 長期記憶の検索
similar_code = memory_system.recall(prompt) if memory_system else []
# Web検索による最新情報の取得
web_context = get_web_context(prompt)
# プロンプトの構築
context_prompt = "あなたは、与えられた情報を最大限活用する世界クラスのプログラマーです。\n\n"
if similar_code:
context_prompt += f"### 過去の類似コード:\n```python\n{similar_code[0]}\n```\n\n"
if web_context:
context_prompt += f"### 最新のWeb情報:\n{web_context}\n"
final_prompt = f"""{context_prompt}上記の情報を踏まえて、以下のリクエストに最高のコードで応えてください:
'{prompt}'
# 生成コード
"""
# AIによるコード生成
stream = llm_instance.create_chat_completion(
messages=[{"role": "user", "content": final_prompt}],
temperature=0.2,
stream=True
)
full_response = ""
for chunk in stream:
token = chunk['choices'][0].get('delta', {}).get('content')
if token:
print(token, end="", flush=True)
full_response += token
return full_response
性能評価:データで見る検証結果
測定条件
実行環境の詳細:
- インスタンス: Google Colab無料枠(CPU専用)
- CPU: 変動(通常2コア程度)※ColabのCPUはセッションごとに変動する可能性があります
- メモリ: 12GB RAM※Colabのメモリサイズも変動する可能性があります
- GPU: 使用せず(n_gpu_layers=0)
- コンテキスト長: 2048トークン
- 温度設定: 0.2(一貫性を重視)
実行時間の詳細分析
| タスクの種類 | 実行時間 | コード品質 | 特筆事項 |
|---|---|---|---|
| 基本的なコード | 約4分 | 高品質 | 構文エラーなし、実行可能 |
| アルゴリズム系 | 約5分半 | 高品質 | 最適化された効率的なコード |
| 複雑なAPI処理 | 約37分 | 高品質 | エラーハンドリング完備 |
既存サービスとの特性比較
| 特徴 | Cursor/Claude Codeなど | このシステム |
|---|---|---|
| 応答速度 | 数秒 | 数分〜数十分(タスクの複雑さにより変動) |
| コード品質 | 高品質(商用レベル) | 高品質(時間をかければ) |
| コスト | 月額/従量課金 | 完全無料 |
| プライバシー | クラウド送信 | 完全ローカル |
| 学習効果 | ブラックボックス | 仕組みが見える |
| カスタマイズ性 | 限定的 | 完全自由 |
コード品質の評価基準:
- 構文エラー: 生成されたコードの構文エラー率
- 実行可能性: そのまま実行できるコードの割合
- 最適化: アルゴリズムの効率性(時間計算量・空間計算量)
- 可読性: コメントや変数名の適切性
- エラーハンドリング: 例外処理の実装状況
このシステムならではの価値
技術学習の観点:
- LLMの動作原理を実際に体験
- プロンプトエンジニアリングの効果を実感
プライバシーの観点:
- 機密コードを外部送信する必要なし
- 完全にコントロール可能な環境
- 企業や研究機関での活用可能性
実際の使用体験:現実的な評価
完全なシステムデモンストレーション
実際にシステムを稼働させた最終的な実行例:

AIの思考プロセス:長期記憶検索→Web検索→プロンプト構築→コード生成の流れ
追加検証結果:
| タスクの種類 | 実行時間 | コード品質 | 特筆事項 |
|---|---|---|---|
| バブルソート実装 | 約6分 | 高品質 | 完璧な実装生成 |
| API連携コード | 約37分 | 高品質 | 本格的なエラーハンドリング付き |
| ランダムシャッフル機能 | 約37分 | 高品質 | 破壊的・非破壊的両パターンの実装 |
| CSV読み込み機能 | 約48分 | 高品質 | 包括的なpandasベースの実装 |
| 日付フォーマット機能 | 実行途中で停止 | - | Colab制限により中断 |
実行途中停止の原因と回避策:
- 原因: Google Colab無料枠のセッション時間制限に達したためである
-
回避策:
- より軽量なモデル(7B-13Bクラス)の使用
- 処理を分割して複数セッションで実行
- Colab Proの利用(長時間セッションが可能)
長期記憶システムの学習効果:
- 過去のコード例を参照した高度な実装
- 段階的な知識蓄積による品質向上
技術的な検証結果
成功した部分:
- ローカル環境でのLLM動作を確認
- 長期記憶システムによる学習機能を実装
- 高品質なコード生成が可能(時間はかかるが)
制約として判明した部分:
- 実行時間の長さ(数分~数十分)
- セットアップの手間
まとめ
技術的な成果
- 完全ローカルでのLLMコード生成環境構築に成功
- Web検索と長期記憶を統合したハイブリッドシステムを実装
- 高品質なコード生成を確認(時間はかかるが)
実用性の評価
適している場面:
- LLMの仕組みを学習したい場合
- プライバシーを重視する開発環境
- 予算制約があるプロジェクト
商用サービスが適している場面:
- 日常的なコーディング業務
- タイトなスケジュールでの開発
今後の改善方向
- 軽量モデル(7B-13Bクラス)での検証
- 量子化技術の最適化
- バッチ処理による効率化
- 実行時間の短縮とメモリ使用量の効率化
実際に試してみたい方へ:
時間に余裕があり、LLMの仕組みを学習したい場合には有効な実験である。ただし日常的なコーディング支援としての実用性は限定的である。
関連リソース:
- Qwen3-Coder-30B-A3B-Instruct-GGUF - 使用したLLMモデル
- llama-cpp-python - LLM実行ライブラリ
- ChromaDB - ベクトルデータベース
- Sentence Transformers - 長期記憶システムの埋め込み生成
- Hugging Face Hub - モデル管理プラットフォーム

kozokaAI開発チームによるAI tech Blogです。 生成AIや業務支援AI、API連携など、現場で役立つAI活用の実践知を発信中。 自社AIの技術ノウハウや、AIを活用した業務改善にご興味のある方はぜひフォローしてご覧ください。
Discussion