Snowflakeに入門してみる①
職種がデータエンジニアに変わり、Snowflakeをガッツリ触ることになりそうです。
せっかくなので公式チュートリアルを主に自分用にまとめ直しつつ、自分なりの見解も添えてみました。
公式の引用がメインですが、重要なポイントをピックアップできた気もするのでかいつまんで眺めていただけたら嬉しいです。
Snowflakeとは?
そもそもSnowflakeがどんなものか、ざっと調べた内容をまとめておきます。
- クラウドベースのSaaS型データウェアハウス(DWH)であり、ハードウェアやソフトウェアの導入・管理が不要
- 類似製品にAmazon Redshift、Google BigQuery、Azure Synapse Analyticsなどがある
- コンピュートリソースとストレージが分離
- 各クラスターはすべてのストレージにアクセスでき、それぞれを独立して拡張可能
- このアーキテクチャーにより、アクセスの競合を防ぎ、ストレージへのアクセスが統一されつつ(シェアード・エブリシング方式のメリットを得つつ)も、一方でノードの拡張を可能にする(シェアード・ナッシング方式の利点も併せ持つ)
Snowflakeの優位性
以下のようなメリットが得られるようです。
- 高いスケーラビリティ: 仮想ウェアハウスという計算リソース(クラスター)を追加したり、そのサイズや数を自動で増減させたりすることで、目的・組織に応じて負荷対策が可能
- 高速なパフォーマンス: 各クラスターが並列処理を行い、負荷に応じて最適化される。また、複数の層でキャッシュを保持することで、即座に応答可能。マイクロパーティショニングにより、面倒なチューニングなしで検索が最適化される
- 柔軟なデータ管理: 異なる組織間でデータを共有したり(Data Sharing)、地域間でデータを複製したり(Data Replication)できる。また、ゼロコピー・クローンやタイムトラベル機能により、データ管理の効率化と履歴からのデータ復旧が可能
-
従量課金: ウェアハウスが稼働している時間のみ費用が発生する従量課金モデルのため、費用を抑えることができる
- クラスターごとに消費リソースが最適化されている前提で、不要なコストも削減できそう
始める前に
早速、公式チュートリアルに沿って進めていきます。
アクセス方法
- 【推奨】ブラウザベースのウェブインターフェイス Snowsight
- インターネットの使用
- プライベート接続の使用
- クイックツアーでできることがざっくりわかる
- SnowSQL、Snowflakeコマンドラインクライアント
- Snowflake CLI、開発者中心のワークロードのためのコマンドラインクライアント
- Snowflakeコネクターとドライバー、およびサードパーティのクライアントサービスとアプリケーションを使用して開発されたアプリケーション
推奨されているSnowsight(ブラウザ利用)を試してみます。
アカウント作成
こちらから無料トライアルに申し込めます。支払い方法の登録は不要です。個人情報の入力後、届いたメールに従ってアカウントを有効化します。
30日間無料かつ、400ドル分のクエリ実行などに使えるクレジットが貰えます(ありがたい…!)。
料金プランページを見る限り、マルチテナント環境を避けたい場合のみ、営業に問い合わせてのアカウント作成が必要なようです。
無事にアカウントが作成できたら、そのままSnowsightに遷移できました。この際にアカウント識別子(以後、アカウントID)が与えられます。
次の要件で一意となるようです。
アカウント識別子は、 組織 内だけでなく、Snowflakeがサポートする クラウドプラットフォーム と クラウドリージョン のネットワーク全体で、Snowflakeアカウントを一意に識別します。
優先アカウント識別子は、アカウント 名 の前に組織名(例:myorg-account123)を付けたものです。Snowflakeが割り当てた ロケーター をアカウント識別子として使用することもできますが、このレガシ形式の使用は 推奨されません 。
Snowsight クイックツアー
詳細は見出しのリンク先にまとめられてますが、Snowsightでは次のようなことができます。
Snowsight では、データ分析とエンジニアリングタスクの実行、クエリとデータロードおよび変換アクティビティのモニター、Snowflakeデータベースオブジェクトの探索、コストの管理、ユーザーとロールの追加などのSnowflakeデータベースの管理を実行できます。
重要な概念およびアーキテクチャ
優位性の項で説明した部分もありますが、特に重要と感じた部分を書き出しておきます。
Snowflakeのサービスのコンポーネントすべて(オプションのコマンドラインクライアント、ドライバー、コネクタを除く)は、パブリッククラウドインフラストラクチャで実行されます。
アカウント作成時に AWS・GCP・Azureのいずれかのクラウドプラットフォームを選択することからもわかるように、オンプレミスでの実行は前提とされていません。
独自アーキテクチャ
Snowflakeの独自のアーキテクチャは、従来の共有ディスク型とシェアードナッシング型のハイブリッドであり、以下の3つの主要な層で構成されています。
データベースストレージ
データがロードされると、Snowflakeが自動的に最適化、圧縮、列指向形式に変換し、クラウドストレージに保存します。ユーザーはこれらのデータに直接アクセスできず、SQLクエリを通じてのみ操作可能です。
クエリ処理
「仮想ウェアハウス」と呼ばれるMPPコンピューティングクラスターでクエリが実行されます。各仮想ウェアハウスは独立しているため、他のウェアハウスのパフォーマンスに影響を与えることはありません。
クラウドサービス
プラットフォーム全体の調整を行うサービス層です。認証、インフラ管理、メタデータ管理、クエリの最適化、アクセス制御といった主要な機能がこの層で処理されます。
その他
ウェブUI、コマンドラインクライアント、各種ドライバーやコネクタなど、多様な方法でサービスに接続できるため、データの統合が容易になります。
サポート対象のクラウドプラットフォーム
3つのレイヤー(ストレージ、コンピューティング、およびクラウドサービス)のすべてが次のクラウドプラットフォームのいずれでもホストでき、リージョンの指定が必要となります。複数のSnowflakeアカウントを同一のクラウドプラットフォームにホストすることも、バラバラにホストすることも可能とのことです。
データロード
- Snowflake独自のステージを利用する(ストレージではなく、ステージで合っています。イメージを掴むにはこちらの記事が参考になりました)
- S3、Google Cloud Storageなどプラットフォームのストレージを利用する
異なるプラットフォーム間でステージングされたファイルからデータをロードする場合、データ転送請求料金が適用される場合があります。詳細については、 データ転送のコストについて をご参照ください。
HITRUST CSF 証明
この証明は、規制順守とリスク管理におけるSnowflakeのセキュリティ体制を強化し、Business Critical(またはそれ以上)のSnowflakeエディションに適用されます。詳細については、 Snowflake セキュリティおよびトラストセンター をご覧ください。
サポートされているクラウドリージョン
nowflakeがサポートするすべての クラウドプラットフォーム でリージョンをサポートしており、3つのグローバルな地理的セグメント(北米/南米、ヨーロッパ/中東、およびアジア太平洋/中国)にグループ化されています。
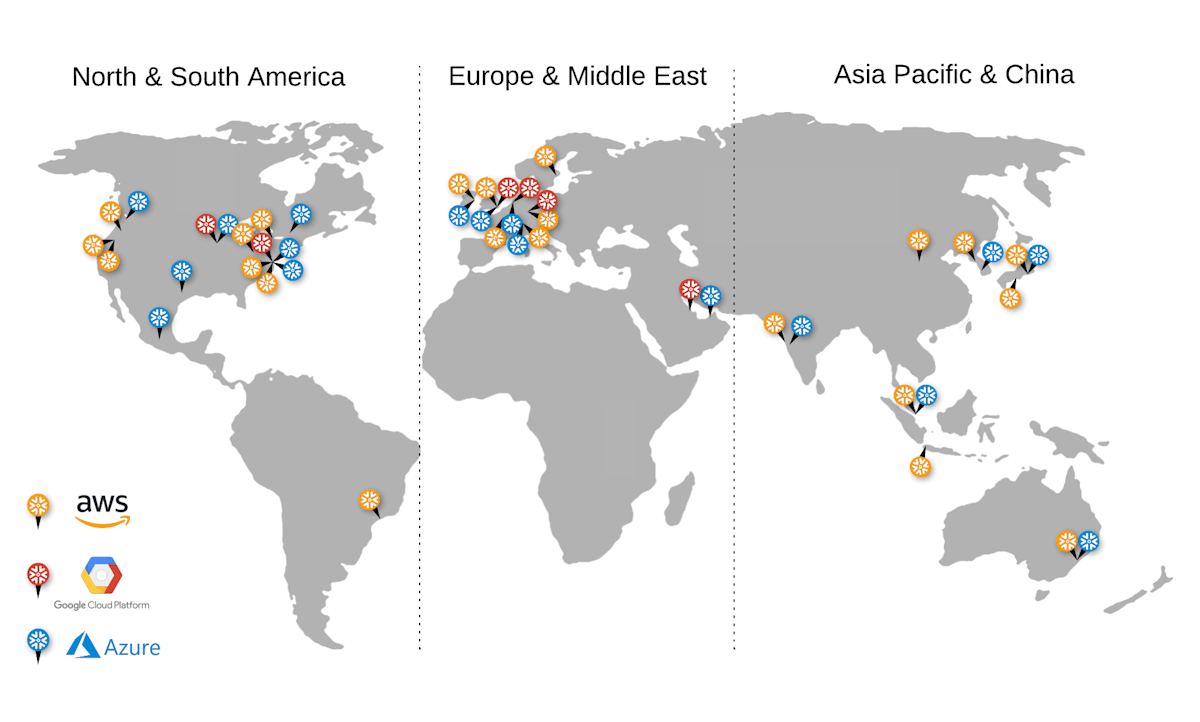
公式ドキュメントより
エディション(プラン)
料金プランです。必要に応じて比較表を確認するのが良いと思います。
エディションの確認方法
Snowsight:Admin » Accounts を選択します。
SQL:SHOW ACCOUNTS コマンドを実行します。アカウントのエディションを変更する場合は、 Snowflakeサポート にお問い合わせください。
リリース
ダウンタイムなしで透過的に更新されるとのことです 🙌 リリースノートはこちらです。
毎週2つという頻度でリリースがあること、段階的リリースが行われること、以下のタイミングで動作変更を含むリリースがされることは抑えておきたいです。
毎月(11月と12月を除く)、Snowflakeはその月における毎週の総合リリースの1つを選択して、動作の変更を導入します。動作変更のために選択される週次リリースは異なる場合がありますが、通常はその月の3回目または4回目のリリースです。
主な機能の概要
多機能すぎて紹介しきれませんが、Snowflake独自っぽい観点や、特に気になった点だけ箇条書きにしておきます。
- Icebergテーブル
- 地理空間データのサポート
- アカウントと一般的な管理、リソースとシステム使用状況のモニター、およびデータのクエリのための Snowsight
- SnowSQL (Pythonベースのコマンドラインクライアント)
- ウェアハウスの 作成、サイズ変更(ダウンタイムなし)、一時停止、およびドロップ を含む、 GUI またはコマンドラインからの仮想ウェアハウスの管理
- Snowflake Extension for Visual Studio Code --- Snowflake Extension for Visual Studio Code をインストール、構成、および使用するための詳細な手順
- StreamlitアプリをSnowflakeでネイティブに 実行し、機械学習やデータサイエンスのためのカスタムWebアプリを作成、共有できます
- プロシージャおよびユーザー定義関数(UDFs) を、いくつかのプログラミング言語のうちの1つでハンドラを使って開発することをサポート
- 他のSnowflakeアカウントとの、 セキュリティで保護されたオブジェクトでのデータ共有 と、 セキュリティで保護されていないビューでのデータ共有 の両方をサポート:
- 消費する他のアカウントへのデータの提供
- 他のアカウントから提供されたデータの利用
- Snowflake Data Clean Rooms を使用する共同研究者が、プライバシー保護された環境でデータを共有することをサポート
- 異なる リージョン および クラウドプラットフォーム にある複数のSnowflakeアカウントにわたる 複製とフェールオーバー のサポート
- Snowflakeアカウント間(同じ組織内)でオブジェクトを複製し、オブジェクトと格納されたデータの同期を維持します
- ビジネス継続性と障害復旧のために、1つ以上のSnowflakeアカウントへのフェールオーバーを構成します
データライフサイクルの概要
COPY INTOとCLONEはSnowflake独自の概念ですが、それ以外は特に変わったことはないと思います。継続的なデータ保護もAWS・GCP・Azureなどのクラウドプラットフォームと同様です。
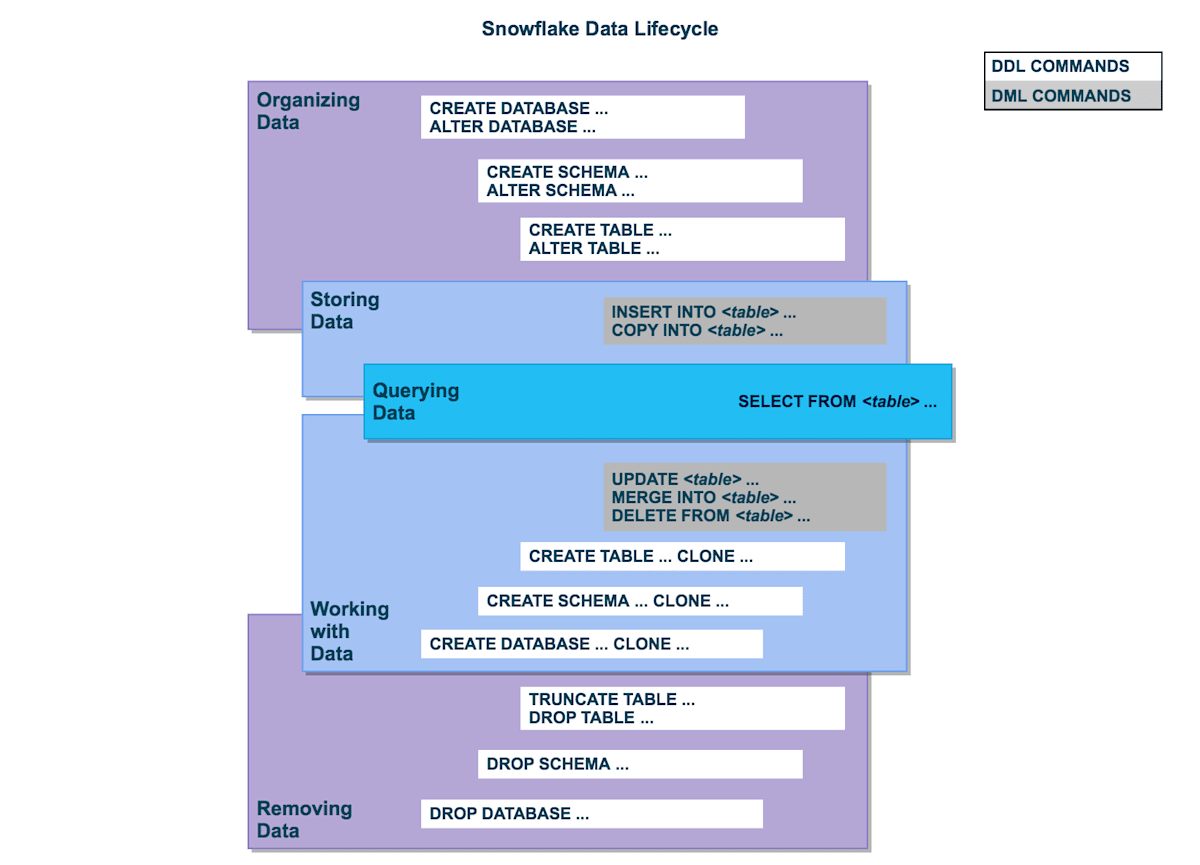
一般的なRDBMSのデータライフサイクルとほぼ同様
コンプライアンス対応の表明
規制コンプライアンスのページにて、世界各国の要件を満たしている旨の記載がありました。
おわりに
やっと長〜い概要・概念のセクションが終わりました。お疲れ様でした。
次回の記事では、より実践的な公式チュートリアルを触ってみる予定です。お楽しみに!
Discussion