前置き
こんにちは、マネーフォワード名古屋拠点でエンジニアをしている @sainu です。
今回は私のプロジェクトで約2年間運用して比較的上手くいっていると自負しているGraphQLのエラー設計を紹介します。
GraphQLのエラーハンドリングや設計は、GraphQLスキーマを導入する時に必ずと言っていいほど悩むポイントだと思いますので、上手くいっている実績のある設計を紹介することで参考になればと思います。
とは言っても、私も全てをゼロから考えたわけではありません。Production Ready GraphQLというGitHubでGraphQLサーバーを作った方が執筆した書籍をベースにしています。この本はGraphQLを運用する人にとってとても実践的な内容が書かれているので、是非一度読んでいただくことをお勧めします。英語で書かれているので、私は会社で輪読会を開催して読破しました。
ではそろそろ本題に入ります。
「エラー」を考える
まず、GraphQLスキーマを設計する前に、私たちが呼んでいる「エラー」をもう少し整理する必要があります。
例えば、以下のようなエラーは私たちがよく目にするものです。
Internal Server ErrorBad GatewayUserName Too LongUserName Was Taken
私たちはこれらを「エラー」と一括りに呼びますが厳密には差分があります。
-
Internal Server Error/Bad Gateway: リクエストを処理する前or時に予期せぬ事が起きた -
Name Too Long/Name Was Taken: リクエストを正しく処理した結果
つまり、このように言い換えられます。
-
Internal Server Error/Bad Gateway: APIの機能ではない例外的なエラー -
Name Too Long/Name Was Taken: APIの機能の一部である業務エラー
そのエラー、誰がどんな対処をすべきか?
-
Internal Server Error/Bad Gateway: 開発者が問題の対処をする -
Name Too Long: エンドユーザーが名前の文字数を減らす -
Name Was Taken: エンドユーザーが違う名前を入力し直す
したがって、このように整理すると「エラー」を2つに分類することができます。
- 開発者向け例外的なエラー
- エンドユーザー向けドメインエラー
GraphQL作者はなんと言っているか
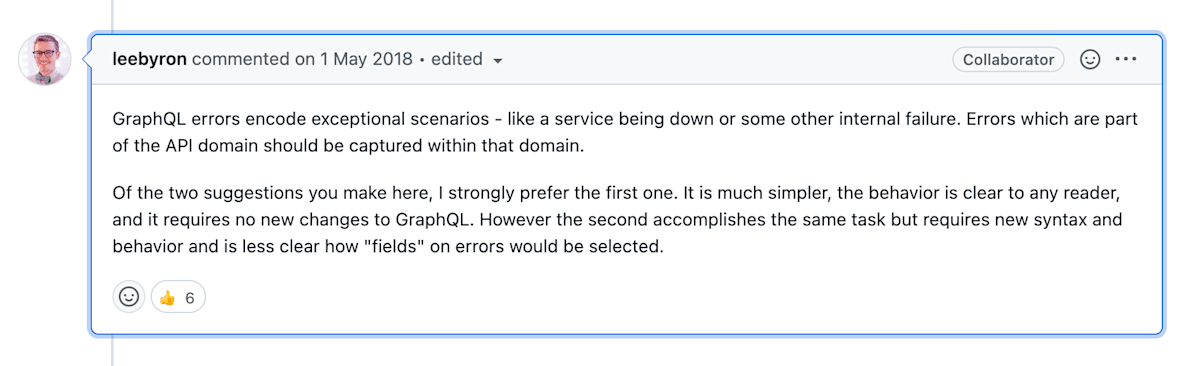
GraphQLエラーは、例外的なシナリオ(サービスダウンやその他の内部障害など)をコード化したものです。APIドメインに含まれるエラーは、そのドメイン内で捕捉されるべきです。...(略)...
[RFC] Typed error #391
...(略)...
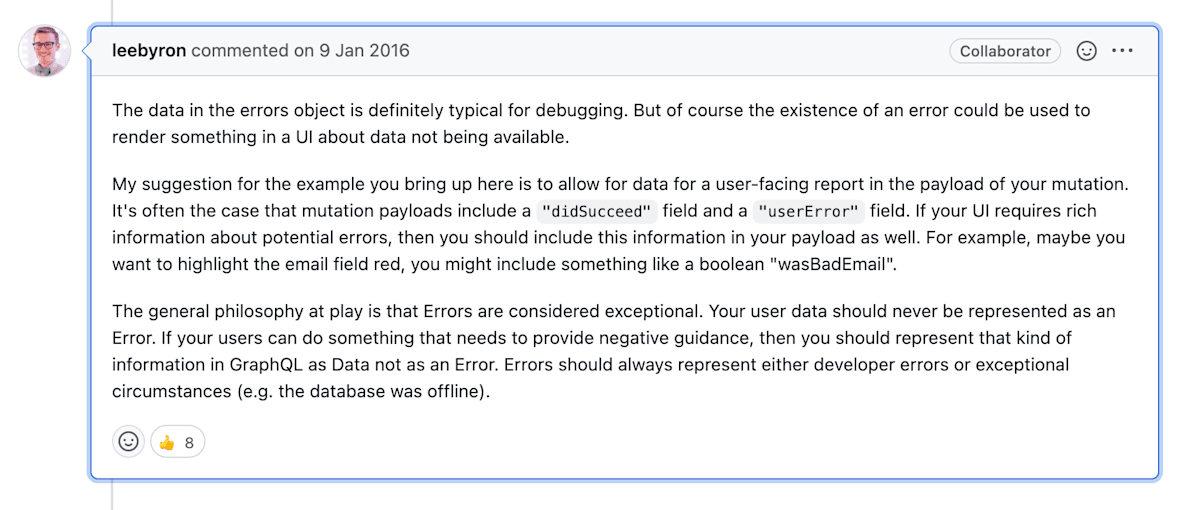
一般的な考え方として、エラーは例外的なものであると考えられています。ユーザーデータは決してErrorとして表現されるべきではありません。もしユーザーがネガティブなガイダンスを提供する必要があるようなことをした場合、そのような情報はErrorとしてではなくDataとしてGraphQLで表現すべきです。Errorは常に開発者のエラーか例外的な状況(データベースがオフラインになったなど)を表すべきです。
Validations that cannot be ran on the client side and the errors object #117
ここまでの整理とGraphQL作者のコメントを踏まえると、GraphQLにおいては以下のような設計が望ましいと言えます。
- ✅ 例外エラー: GraphQL Errors(Top-level "error"とも呼ばれる)に含める
- ✅ ドメインエラー: スキーマの一部として設計する
このように見ていくと、ドメインエラーをGraphQL標準仕様のTop-level "errors"に含めることは適切ではないと言えます。
GraphQLにおけるエラー設計の具体例紹介
それでは、具体的な例を見ていきましょう。
例外エラー
前述した通り、例外エラーは、GraphQL Errors(Top-level "error"とも呼ばれる)に含めることが望ましいです。
クライアントが安定した識別子に依存してエラー処理ができるように、extensionsキーにcodeを追加するのが一般的に良いアイデアとされています。
{
"errors": [
{
"message": "Service is down",
"locations": [ { "line": 2, "column": 2 } ],
"path": [ "createProduct" ],
"extensions": {
"code": "SERVICE_CONNECT_ERROR"
}
}
],
"data": {
"createProduct": null
}
}
-
message: エラーの詳細を説明する人間が読むためのメッセージ -
location: クエリ文字ドキュメントのどこで発生したかを示す(ライブラリがやります) -
path: クエリのルートからエラーがあったフィールドにつながる文字列の配列(ライブラリがやります) -
extensions: GraphQLエラーにより多くの情報を含めるため拡張が許されたキー。GraphQLの仕様変化に伴い命名の衝突を避けるため用意されている。
ドメインエラー
ドメインエラーは、スキーマの一部として設計することが望ましいです。
私は現在InterfaceとUnionを使ってこのようにエラーを設計しています。
type Mutation {
updateProduct(input: UpdateProductInput!): UpdateProductResult!
}
interface UserError {
message: String!
}
input UpdateProductInput {
name: String!
}
union UpdateProductResult = Product | UpdateProductErrors
union UpdateProductError =
UnauthorizedError
| LackOfPermissionError
| OptimisticLockError
enum InputValueErrorCode {
TOO_LONG
TAKEN
}
type InputValueError implements UserError {
message: String!
field: [String!]!
code: InputValueErrorCode!
}
type UnauthorizedError implements UserError {
message: String!
}
type LackOfPermissionError implements UserError {
message: String!
}
type OptimisticLockError implements UserError {
message: String!
expectedVersion: Int!
actualVersion: Int!
}
type UpdateProductErrors {
errors: [UpdateProductError!]!
}
type Product {
id: ID!
name: String!
}
✅ Pros: 不可能な状態がない
例えば、以下のようにPayloadを設計するパターンを考えてみます。
type Mutation {
createUser(input: CreateUserInput!): CreateUserPayload!
}
type CreateUserPayload {
userErrors: [UserError!]!
user: User
}
type UserError {
message: String!
field: [String!]
code: UserErrorCode
}
この場合、CreateUserPayloadはuserとuserErrorsフィールドをnullableで定義する必要があるので、以下のようなあり得ない結果がスキーマ上で許容されてしまいます。
{
"data": {
"createUser": {
"user": null,
"userErrors": []
}
}
}
or
{
"data": {
"createUser": {
"user": { "id": "U001" },
"userErrors": [{ "message": "エラー", "field": ["input", "name"] }]
}
}
}
このようなスキーマの場合、クライアントはどちらか一方しか存在しないという暗黙ルールの前提で実装しなければなりません。
このような状態を許容しないスキーマ定義をすることで、クライアントの実装はより安全になります。これを防ぎたい場合は、Result型パターンを採用することが望ましいです。これは、200 OK! Error Handling in GraphQLで紹介されています。
Result型パターンを採用すると、以下のようなスキーマ定義になります。
type Mutation {
updateProduct(input: UpdateProductInput!): UpdateProductResult!
}
union UpdateProductResult = Product | UpdateProductErrors
union UpdateProductError =
UnauthorizedError
| LackOfPermissionError
| OptimisticLockError
type UpdateProductErrors {
errors: [UpdateProductError!]!
}
✅ Pros: スキーマを見れば得られる可能性のある結果がわかる
このようにUnionを使うことで、クライアントはスキーマを見るだけで得られる可能性のある結果がわかります。
union UpdateProductResult = Product | UpdateProductErrors
union UpdateProductError =
UnauthorizedError
| LackOfPermissionError
| OptimisticLockError
このResult型パターンは、Mutationだけでなく、Queryにも適用することができます。
type Query {
userResult(username: String!): UserResult
}
union UserResult = User | IsBlocked | Suspended
type User {
id: ID!
name: String
}
type Suspended {
reason: String
}
type IsBlocked {
message: String
blockedByUser: User
}
✅ Pros: エラーの種類が増えてもスキーマの変更が少ない
エラーの種類が増えても、スキーマの変更が少なくて済むのもこのパターンの利点です。このようにUnionの中にエラーを追加していくだけで、スキーマの変更が少なくて済みます。また、どのクエリにどのエラーが追加されたかも一目瞭然なので、スキーマだけを見てクライアントのエラーハンドリングの変更ができます。
union CreateProductError =
UnauthorizedError
| LackOfPermissionError
| NameTooLongError
| NameWasTakenError
union UpdateProductError =
UnauthorizedError
| LackOfPermissionError
| NameTooLongError
| NameWasTakenError
| OptimisticLockError <--- NEW!
enumを使ってエラーコードなどで一元的に管理することもできますが、その場合、どのエラーコードがどのクエリで使われているかがわかりにくく、影響のあるクエリを特定するためにAPIの動作を別の情報源から知る必要があるため、私はenumよりもunionを使うことをお勧めします。
type Mutation {
createUser(input: CreateUserInput!): CreateUserResult!
updateUser(input: UpdateUserInput!): UpdateUserResult!
}
union CreateUserResult = User | CreateUserErrors
union UpdateUserResult = User | UpdateUserErrors
type CreateUserErrors {
errors: [UserError!]! <-- ここにOPTIMISTIC_LOCKが追加?
}
type UpdateUserErrors {
errors: [UserError!]! <--- それともここに追加?
}
type UserError {
message: String!
code: ErrorCode!
}
enum ErrorCode {
UNAUTHORIZED
OPTIMISTIC_LOCK <--- NEW!
}
✅ Pros: クエリの変更が不要
クライアントは特定のドメインエラーを選択できるだけでなく、インターフェイスコントラクトにフォールバックできるため、新しいエラータイプを見逃すことがありません。
例えば、このようにクエリすることで、新しいエラータイプが追加されてもクエリを変更することなくCreateUserErrorsの中に新しい型が追加されます。
mutation {
createUser(input: {}) {
... on User {
id
}
... on CreateUserErrors {
errors {
# Specific cases
... on UserNameTaken {
message
path
suggestion
}
# Interface contract
... on UserError {
message
path
}
}
}
}
}
Cons?: スキーマの見通しが悪くならない?
現在私が運用するシステムのGraphQLスキーマファイルは約4500行なので、まだファイルを開くのに不自由を感じていません。また、統一されたルールによってスキーマが定義されているため、スキーマを読むことはそれほど難しくありません。
ただ、10000行を超えるようなスキーマファイルになると、ファイルを操作すること自体が難しくなるかもしれません。その場合は、GraphiQLやGraphQL Playgroundなどのツールを使うとスキーマの参照が容易になります。GitHub GraphQL APIのエクスプローラーを参照するとイメージしやすいかもしれません。
Cons?: スキーマが膨大になって変更が大変じゃない?
コードファーストでスキーマを管理していますが、コードは適切な階層構造で管理されているので、スキーマの変更は難しくありません。むしろ、コードファーストでスキーマを管理することを推奨します。コードファーストであればコードの抽象化(モジュール機能など)によってスキーマの冗長さが解消され、スキーマ変更は容易です。
スキーマファーストでスキーマファイルを直接編集すると、なるべくスキーマをDRYに保ちたくなる心理が働き、暗黙のルールが増えてしまう可能性があります。また、どこに何を書くかの判断を人間が行うため、逆にスキーマファーストの方がスキーマサイズが大きくなった時に辛くなるかもしれません。
Cons?: 冗長なスキーマになるのでは?
私はしばらくGraphQLを運用してきて、スキーマが冗長で情報量が多いほどクライアントの実装が安全になると感じています。適切に表現されたスキーマが膨大になることは悪いことではなく、むしろスキーマから生成されるクライアントの型情報に必要な情報が全てあることになるので、クライアントの実装を安全にするために非常に価値があります。また、クライアントの実装者は、スキーマを読むことでAPIから何が返ってくるかを理解できるため、スキーマが冗長であることはむしろプラスに働くと感じています。
逆にスキーマがDRYになり暗黙的なルールが増えるほど、クライアントは型で表現されない暗黙的なルールに依存してしまい、実装が脆弱になると感じています。また、スキーマに表現されていないルールをどこかに書かなければならないため、スキーマ以外のドキュメントを作る羽目になるかもしれません。そういったコードと切り離されたドキュメントの運用は非常にコストです。
以上のことから、私はスキーマが冗長であることを恐れず、むしろスキーマが冗長でリッチであることを受け入れるべきだと考えています。
まとめ
GraphQLにおける例外エラーとドメインエラーの扱いについて整理し、私のプロジェクトで実践しているエラー設計について紹介しました。
スキーマ上で表現する方法は、他にもいくつかのパターンがあります。ここでは全てを紹介することはできませんが、Production Ready GraphQLを読むことで、より多くのパターンを知ることができると思います。それでも今回私が紹介したスキーマ設計は、その書籍の中で紹介されている良いパターンを組み合わせているものなので、是非参考にしていただければと思います。
いきなりこのような大掛かりに見えるスキーマ設計を導入するのはハードルに感じるかもしれません。より簡単で低コストにエラーを表現することも可能ですが、大抵のプロジェクトは数年のうちに想定外に大きく複雑になります。そして、複雑な要求に答えるのが辛くなっていき、リアーキテクチャなるコストを払うことになるのが常です。なので、私としては目先のコストに惑わされずに、初めから良いとされる設計を取り入れて柔軟で拡張が効く設計にしておくことは、結果的にプロジェクトのトータル運用コストを下げることにつながると考えています。
あと、良く構造化された設計は複雑に見えても、一定の規則に従っているため、実際には予想以上に理解しやすいものです。私はこのような設計を取り入れることで、プロジェクトの運用が楽になったと感じています。
最後に、GraphQLのエラー設計は、GraphQLスキーマを導入する時に必ずと言っていいほど悩むポイントだと思います。この記事が、GraphQLエラー設計に悩むエンジニアの一助になれば幸いです。

Discussion