この記事は、Money Forward Engineering 1 Advent Calendar 2023 7日目の投稿です。
6日目は kikuchi.kodai さんで「Gradle Pluginの作成のすゝめ」でした。
本日は私が「コネクテッドシート周りのコスト管理」について書いていきたいと思います。
はじめに
初めまして、株式会社MoneyForwardのCTO室分析基盤部でデータエンジニアを行っているNakamoriです。
私は22新卒でこの分析基盤部に配属されてから1年半の間、データ分析基盤の開発と運用を行っています。
今回はGoogleスプレッドシートの1機能であるコネクテッドシートのコスト管理を行ったのでそれについてお話ししたいと思います。
この記事が想定する読者
- コスト管理を始めたいがどこから始めていいかわからない人
- 社員がコネクテッドシートを使い始めたのは嬉しいが、管理が追いついていない人
コネクテッドシートのコスト課題の実態
Googleスプレッドシートのコネクテッドシート機能は、BigQueryデータを直接扱えるためデータ分析において非常に便利です。しかしこれらの機能を使う際、BQ側では料金が発生しています。主なものとしては、グラフ、ピボットテーブル、関数、計算された列、列の抽出といったタスクの作成時や更新時が挙げられます。そして、この機能は裏側の状況が把握しづらくコストが急増する原因にもなっています。コスト管理を始めるにあたって、注意したい点を述べていきます。
プレビューの扱いについて
注意すべき点の一つは、プレビュー機能も課金されることです。プレビュー機能とは基本的な使い方としては列を抽出してデータを全件取ってくると思いますが、その際はプレビューが含まれるのでBQのUI上でクエリする場合と比べて2倍支払っていることになります。
それぞれの機能でコストが発生する
コネクテッドシートの各機能はそれぞれでお金がかかります。もし、あなたが抽出してさらにピボットテーブルで集計したテーブルも作成したい場合、追加でクエリコストを支払う必要があります。抽出した場合でも抽出されたシートに対してピボットしているわけではなく、BQを用いてビボットを行っているので注意が必要です。
監査ログの活用とコスト監視
BQを利用した際のコスト調査は監査ログを利用して行うのが一般的です。なので、そこに一手間加えてスプレッドシートのコストも計測できるようにしましょう。監査ログを分析するためにデータアクセス監査ログをBigQueryに移しておいてください。ログを貯める方法は今回は割愛します。
データアクセス監査ログの種類
データアクセス監査ログは大きく分けて3つに分類されます。Metadataの中に含まれる要素によって分けることができます。今回使うのはjobInsertionとjobChangeのみです。
| 要素 | 内容 |
|---|---|
| jobInsertion | BigQueryにジョブ(クエリやデータのロードなど)が作成された際に記録されるログ。ジョブの実行に関する詳細が含まれます。 |
| jobChange | 既存のジョブの状態が変更されたとき(例えば、ジョブが完了または失敗したとき)に記録されるログ。ジョブの結果に関する情報を提供します。 |
| tableDataRead | ユーザーがテーブルデータを読み取ったときに記録されます。どのテーブルがアクセスされたか、どのようにデータが使用されたかを示します。 |
スプレッドシートのIDを抽出する
まず、データコネクタを利用しているスプレッドシートのリストを出すためにjobInsertionから情報を抽出します。スプレッドシートのIDはjobInsertionにしかないので注意が必要です。
# standard_sql
SELECT
protopayload_auditlog.authenticationInfo.principalEmail,
json_value(protopayload_auditlog.metadataJson, "$.jobInsertion.job.jobName") jobName,
json_value(protopayload_auditlog.metadataJson, "$.firstPartyAppMetadata.sheetsMetadata.docId") docId,
cast(json_value(protopayload_auditlog.metadataJson, "$.jobInsertion.job.jobStats.createTime") as TIMESTAMP) createTime
FROM `cloudaudit_googleapis_com_data_accessのテーブル`
WHERE
1=1
and protopayload_auditlog.serviceName = "bigquery.googleapis.com"
and protopayload_auditlog.methodName = "google.cloud.bigquery.v2.JobService.InsertJob"
and json_value(protopayload_auditlog.metadataJson, "$.jobInsertion.job.jobConfig.type") = "QUERY"
and json_value(protopayload_auditlog.metadataJson, "$.jobInsertion.job.jobConfig.labels.sheets_connector") = "connected_sheets"
ネイティブJSON型難しいので旧型で...
ポイント
- 先にwhere句でlabelがconnected_sheetsになっているレコードを探して絞る
- firstPartyAppMetadataからDocIdを抽出する
-
https://docs.google.com/spreadsheets/d/{DocId}でURLになる
-
- principalEmailとjobNameでJOINするので忘れずに抽出する
たまに、jobInsertionの時点でステータスがDoneになっているものがありますが、完了時にちゃんとjobChangeも発行されているので特に気にしなくて大丈夫です。
コストの算出
次はコストの算出です。jobChangeから完了タスクを抽出しかかった費用を計算します。今回はオンデマンドの例を掲載しますので、お好みの形で抽出してください。
select
protopayload_auditlog.authenticationInfo.principalEmail,
resource.labels.project_id as projectId,
json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobConfig.queryConfig.query") as query,
cast(json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobStats.startTime") as TIMESTAMP) as startTime,
cast(json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobStats.endTime") as TIMESTAMP) as endTime,
5 * (
cast(
json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobStats.queryStats.totalBilledBytes") as INT64
) / power(2, 40)
) as estimatedCosts,
json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobName") as jobName,
json_extract(protopayload_auditlog.metadataJson, "$.jobChange.job.jobConfig.labels") as labels
from
`cloudaudit_googleapis_com_data_accessのテーブル`
where
1 = 1
and protopayload_auditlog.serviceName = "bigquery.googleapis.com"
and json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobConfig.type") = "QUERY"
and json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobStatus.jobState") = "DONE"
and json_value(protopayload_auditlog.metadataJson, "$.jobChange.job.jobConfig.queryConfig.statementType") != 'SCRIPT'
ポイント
- 計算した結果をestimatedCostsとして保存
- 5($/TB)はUSなのでTokyoの場合は変更してください
- projectIdも取っておくと便利
- スプレッドシートのみのレコードでいい場合は前クエリ同様labelカラムでフィルタ
コストを分析する
あとはこの2つのテーブルを組み合わせると分析の完了です。Joinする際は念の為、jobNameとprincipalEmailで行ってください。SheetIdごとにGroup byして金額をsumするのが一般的ですが、レコード数をカウントしておくとクエリ頻度も計測できて便利です。
コストがかかっているシートがわかったとしてもシートの権限がない場合もあるので、principalEmailから利用状況を問い合わせるのが今後の流れかなと思います。
効果的なコスト対策
これでコストが算出できました。このテーブルを定期的に確認することで簡単にコスト最適化を行うことができます。
最適化の方法として2点ほど例を挙げておきます。
マートテーブルの作成
コネクテッドシートのクエリ時のコストは、容易に2倍や3倍に膨れ上がります。これを避けるためには、マートテーブルを作成して、事前にデータを処理しておくことが効果的です。これにより、コネクテッドシートでのクエリ実行時のコストを抑えることができます。
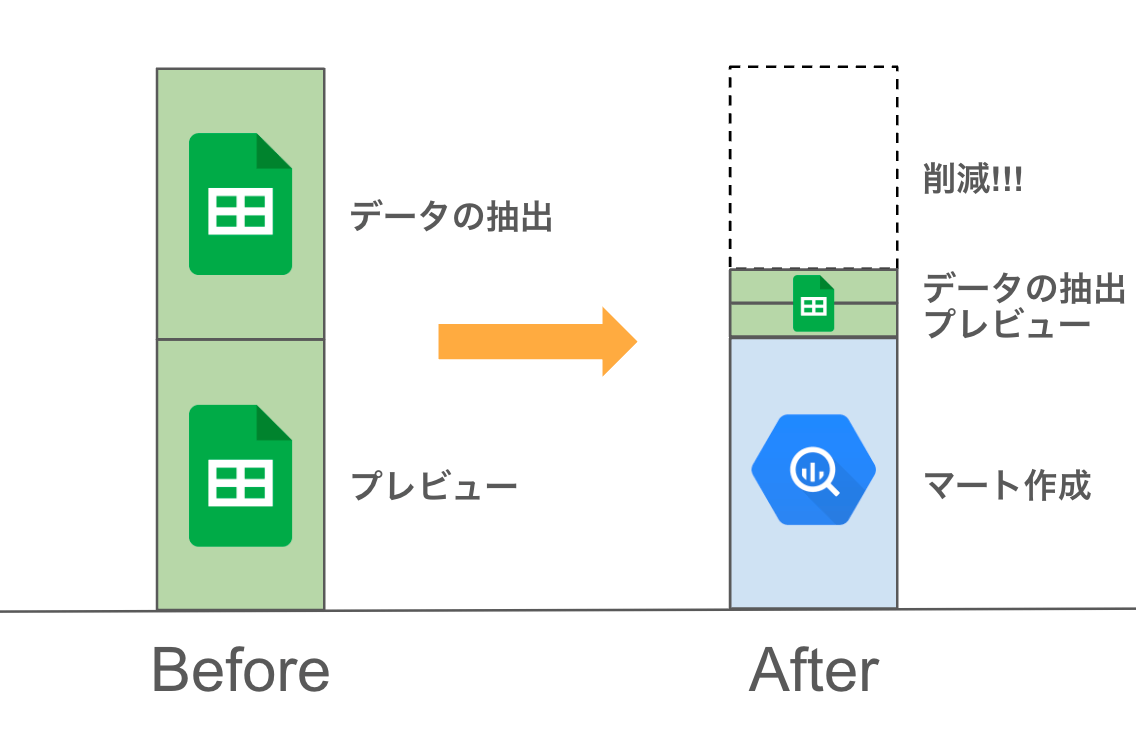
マートテーブル作成によるコスト削減のイメージ図
更新頻度の見直し
コネクテッドシートのコスト感がわからない人は更新頻度をなるべく多くしてしまいがちです。高頻度の更新が必要ない場合は日次更新ぐらいまで下げるように進めるだけでかなりのコストが削減されます。
結論
BigQueryと連携するGoogleスプレッドシートのコネクテッドシートは、データ分析において非常に強力なツールです。しかし、より効果的に利用するにはその裏でコスト管理を行うことが不可欠です。また、BigQueryだけでなく、LookerStudioなど他のツールも活用することで、さらにコスト最適化の幅を広げることができます。ぜひ皆さんもこれを機にコスト管理をしてみてください。

Discussion