こんにちは! 私はしばもと(@handle-name silverbirder)と申します。株式会社マネーフォワードでWebフロントエンド開発を担当しています。最近、ChatGPTの進化に驚くばかりですね。このブログ記事は、ChatGPTの力を借りて執筆しています。
今回、私が3ヶ月間取り組んできたWebフロントエンドのレイヤードアーキテクチャを用いたリアーキテクチャについてお話ししたいと思います。Webフロントエンド分野は他の分野に比べて変化が激しいため、適切なコードベース設計がなされないと、保守性がすぐに低下してしまいます。
次のような苦労をされた経験がある方々に、ぜひこの記事を読んで頂きたいです。
- 「どこからコードを読んだら良いか、書いたら良いか悩む」
- 「何かを変更すると、関係ない部分も変更してしまう」
- 「無駄にGraphQLのデータを参照している」
今回お話する設計題材となる対象プロダクトについては、以下のリンク先の記事がわかりやすくまとめられています。本記事では主にWebフロントエンド設計に焦点を当てるため、プロダクトやMicroFrontendsに関する話は割愛しますので、ぜひ下記の記事をご覧ください。
さらに、この記事は次の勉強会でも資料として使用されます。もし興味がある方は、ぜひ勉強会にもご参加くださいね。
背景
2022年12月に、私は新しいプロダクト開発プロジェクトにフロントエンドエンジニアとして参加しました。このプロダクトは(2023年3月23日現在)まだリリースされていません。プロダクト開発では、MicroFrontendsというまだ世の中に知見が少ない設計に挑戦しています。実現に向けて多くの試行錯誤をしているため、その影響でフロントエンドのコードベースの状態はあまり良くありませんでした。具体的には、以下のような課題がありました。
- Storybookが機能していない
- プロダクションコードに対してテストコードが不十分
- フォルダ構造に一貫性がない
- GraphQLで不要なデータの参照・受け渡しが行われている
- コンポーネントの命名規則が不規則
- さまざまなデータに密結合し、再利用性が低いコンポーネント
これらの課題に対して、チームメンバーのフラストレーションが高まっていました。私は、リアーキテクチャ経験があるため、これらの課題を解決したいと考えました。私は綺麗好きで、テスト主義や安全性を重視する性格のため、コードベースの整理、リアーキテクチャに取り組むことを決めました。
リアーキテクチャ化
それでは、リアーキテクチャ化について紹介したいと思います。その前に、プロダクトで使用している技術スタックを簡潔にご紹介させていただきます。
| カテゴリ | 名前 |
|---|---|
| UI Framework | React |
| Type Safe | TypeScript |
| Form | React Hook Form,Zod |
| API | GraphQL,urql |
| Test | Jest |
| Demo | Storybook |
リアーキテクチャの取り組みは、主にコードベースの分析、理想的なフォルダ構造の設計、そしてそのフォルダ構造へ既存コードの移行作業でした。この記事では、フォルダ構造の設計と移行後の感想についてお話します。
フォルダ構造設計
チームメンバーとの議論を通して、Webフロントエンドのフォルダ構造を次の設計思想を参考に検討しました。
これら2つの設計から、プロダクトに合うようにアレンジし、以下の図のようなフォルダ構造に落ち着きました。
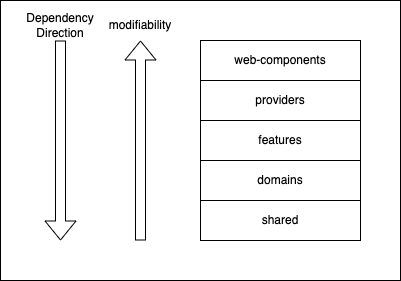
重要な点は、上位フォルダから下位フォルダへの参照(依存)のみを許可するレイヤー構造になっていることです。
それぞれのフォルダの説明をする前に、依存の方向性について(Dependency Direction)と改修容易性について(Modifiability)説明します。
依存の方向について
依存関係の整備は、開発を効率的に進める上で非常に重要な要素です。スパゲッティコードはメンテナンスが困難であり、誰も望むものではありません。
依存関係は、上位層から下位層へ一方向に依存するように統一します。もし異なる方向からの依存が許容されてしまうと、次のような問題が生じることがあります。
- コード改修時の影響範囲調査コストが増える
- テストコード記述時にモッキングやスタビングのコストが増える
上位層(web-components)から下位層(providers)への依存は許可されるケースの一例を示します。
// OKケース
// web-components/your-web-component.tsx
import * from '@/providers';
一方で、下位層(providers)から上位層(web-components)への依存はNGです。
// NGケース
// providers/urql-provider.tsx
import * from '@/web-components';
同じ階層での依存に関しては、原則許可しています。しかし、featuresやdomainsは禁止しています。理由は、それぞれのフォルダ紹介で説明します。
依存関係のLintツール
ESLintのプラグインには、依存関係の整備に役立つものが存在します。例えば、よしこさんが次の記事で紹介している「eslint-plugin-strict-dependencies」を利用することで、依存関係のLintを定義できます。
アーキテクチャテスト
余談ですが、アーキテクチャのテストについて触れておきます。特に、レイヤー構造の維持が重要な場合、ArchUnitというテスト手法を利用するのが良い選択肢の1つです。
これらの方法を実践することで、依存関係のメンテナンスが容易になります。
改修容易性
レイヤー構造を採用することで、上位層は下位層よりも変更しやすくなる設計が可能です。そのため、再利用性の高いコンポーネントを下位層で作成し、それらを上位層が使用することで、安全に変更が行えます。
例えば、プロフィール閲覧機能のfeatureと、Avatarというdomainがある場合、以下のようなコードが考えられます。
// features/view-profile.tsx
import { AvatarCircle } from '@/domains';
export const ViewProfile = () => {
...
return (
<AvatarCircle />
);
};
表示するAvatarをCircle形式からCard形式に変更したい場合、次のように変更します。
// features/view-profile.tsx
import { AvatarCard } from '@/domains'; // AvatarCardを新規作成する
export const ViewProfile = () => {
...
return (
<AvatarCard />
);
};
ここで重要な点は次の通りです。
- 上位層の変更であり、下位層の変更ではない
- 改修の容易さが高い層で変更する
上位層は、下位層に比べて依存される数が少なく、変更しやすいです。
逆に、下位層は上位層から多くの依存があるため、変更が難しいです。
保守改修を行う際には、品質、コスト、納期(以下、QCD)をバランスよく維持したいと考えます。レイヤー構造による設計は万能ではありませんが、改修の容易さが高い(上位層)ものを選択して修正することは、QCDの観点から良いバランスが保たれると思われます。
次に、フォルダ構造について紹介していきます。
フォルダ構造
私達が設計したフォルダ構造は以下の通りです。各フォルダの詳細は後ほど説明します。
| フォルダ名 | 説明 | 補足 |
|---|---|---|
| web-components | WebComponents向けにカスタム要素を定義するためのフォルダ | featureやproviderを組み合わせてカスタム要素を定義します |
| providers | アプリケーションに必要なProviderを格納するフォルダ | urqlなどのライブラリをshared/libで定義し、providersがそれらを参照します |
| features | ビジネス価値を提供するための機能を格納するフォルダ | domainsやsharedを組み合わせます。API呼び出しや状態管理、zodバリデーションを担当します |
| domains | プロダクトのドメインUIを格納するフォルダ | ドメインは、GraphQL Schemaに該当します。与えられたデータ・状態操作を入力にUIを表現します |
| shared | 再利用可能なプロダクト非依存のコードを格納するフォルダ | ライブラリやユーティリティを配置します |
web-componentsは私達のプロダクト固有の設計になりますが、それ以外のフォルダ名は他のプロダクトにも適用できる設計だと思っています。web-componentsは、Next.jsのpagesと相当する部分に近いため、適宜読み替えて利用することも可能です。
features,domainsには以下の構造のサブフォルダが含まれます。
| フォルダ名 | 説明 | 例 |
|---|---|---|
| api | API通信用のコードを格納するフォルダ | useQuery |
| hooks | UIに依存するhooksを格納するフォルダ | useDisclosure |
| stores | ドメイン依存の状態管理を格納するフォルダ | useReducer,React Hook Form |
| ui | ReactのUIコードを格納するフォルダ | *.(stories|test|).tsx |
例えば、featuresの場合、features/view-profile/api/useGetProfile/のような構造になります。
各フォルダにはindex.tsを配置し、フォルダ単位でインポートできるようにします。また、階層構造を作らずフラットに配置することを推奨します。
NGケース:
ui/
├ ComponentA/
│ ├ ComponentA.stories.tsx
│ ├ ComponentA.test.tsx
│ ├ ComponentA.tsx
│ ├ ComponentB/ (👎)
│ │ ├ ComponentB.stories.tsx
│ │ ├ ComponentB.test.tsx
│ │ ├ ComponentB.tsx.tsx
│ │ └ index.ts
│ └ index.ts
└ index.ts
OKケース:
ui/
├ ComponentA/
│ ├ ComponentA.stories.tsx
│ ├ ComponentA.test.tsx
│ ├ ComponentA.tsx
│ └ index.ts
├ ComponentB/ (👍)
│ ├ ComponentB.stories.tsx
│ ├ ComponentB.test.tsx
│ ├ ComponentB.tsx
│ └ index.ts
└ index.ts
もしComponentBが外部から参照されたくないプライベートなものであれば、次のようにindex.tsを記述します。
// ui/ComponentA/index.ts
export { ComponentA } from "./ComponentA";
// ui/ComponentB/index.ts
export { ComponentB } from "./ComponentB";
// ui/index.ts
export { ComponentA } from "./ui";
// 以下のようにComponentBをexportしない
// export { ComponentA, ComponentB } from "./ui";
余談ですが、uiのテンプレートからコードを自動生成するplopjs/plopも導入済みです。
これで基本的なフォルダ構造について紹介しました。次からは、それぞれのフォルダについて詳しく説明します。
web-components
プロダクトの最終アウトプットはWeb Componentsです。featuresとprovidersを組み合わせてWeb Componentsを定義し、web-componentsフォルダにそれらの定義ファイルを配置します。
命名規則は <prefix>-<free>-<suffix> を採用しています。
<prefix> は、プロダクト固有の名詞を紐づけることで、他のWeb Componentsとの競合を避けます。
<suffix> は、buttonやtextareaなどのHTMLタグ名を付けることを推奨します。これは、Web標準の要素をカスタム拡張していることを示すためです。ただし、対象となる内容によってはHTMLタグ名で表現できないものもあるため、必ずしも強制されません。
サンプルコードを以下に示します。
// web-components/xx-your-web-components.tsx
import React from 'react';
import { FeatureA } from '@/features';
import { UrqlProvider } from '@/providers';
import { registerWebComponent } from '@/web-components/lib/integration';
registerWebComponent({
render: (props) => {
return (
<UrqlProvider>
<FeatureA {...props} />
</UrqlProvider>
);
},
tag: 'xx-your-web-components',
});
registerWebComponentは、ReactコンポーネントをWebComponentsのカスタム要素として登録する関数です。features層とproviders層を利用して、カスタム要素を定義されます。
※ registerWebcomponent の詳細は、https://zenn.dev/moneyforward/articles/2022-12-14-micro-frontends-in-moneyforward の記事で中身を紹介していますので、興味がある方はご覧ください。
providers
providersフォルダは、ReactのコンテキストにおけるProviderを定義する場所です。この部分については、チーム内での議論が十分でなかったため、本記事ではコード例の提示のみになります。例として、urqlのProviderを紹介します。以下のようなコードをProviderフォルダで定義します。
// providers/urql-provider.tsx
import React from 'react';
import { ClientOptions } from 'urql';
import {Provider, makeClient} from '@/shared/lib/urql';
type UrqlProviderProps = {
children: JSX.Element;
clientOptions?: ClientOptions;
};
export const UrqlProvider = ({ children, clientOptions }: UrqlProviderProps) => {
const client = makeClient(clientOptions);
return (
<Provider value={client}>{children}</Provider>
);
};
このUrqlProviderをweb-components層で、<UrqlProvider><Feature /></UrqlProvider> のようにWrapして使います。
features
featuresは、ユーザーにビジネス価値を提供する機能を定義します。 featureの命名は、<action>(動詞) で始まる形式に統一します。
featureを開発する際には、以下の役割を果たす層を考慮します。
- API通信
- 状態管理
- フォームバリデーション(Zodスキーマ)管理
- ドメインUIと組み合わせたUI構築
サンプルコードを以下に示します。
// features/view-profile/ui/ViewProfile/ViewProfile.tsx
import React, { FC } from 'react';
import { AvatarCircle } from '@/domains';
import { useGetProfile } from '@/features/view-profile/api';
import { useViewProfileStore } from '@/features/view-profile/stores';
type ViewProfileProps = {};
export const ViewProfile: FC<ViewProfileProps> = () => {
const {
data: { profile },
loading: getProfileLoading,
} = useGetProfile();
const {
state,
actions,
} = useViewProfileStore({ profile });
if (getProfileLoading) return <>loading..</>;
return <AvatarCircle avatar={profile.avatar} />;
};
このfeaturesでは、 @/features/view-profile/api でAPI通信を行い、@/features/view-profile/stores で状態管理を実施します。さらに、@/domainsから<AvatarCircle />を利用します。
featuresは、1つの機能として完結しています。現時点では、あるfeatureから別のfeatureを利用するケースは存在していません。
GraphQL Fragment
domains層には、ドメインに必要なデータを示すGraphQL Fragmentを定義しています。features層は、domains層のGraphQL Fragmentを用いてAPI通信のクエリを記述します。
例えば、先ほどの例であるAvatarCircleドメインでは、以下のGraphQL Fragmentを定義します。
# domains/avatar/avatar-circle/api/AvatarCircle_Avatar.graphql
fragment AvatarCircle_Avatar on Avatar {
name
}
AvatarCircle_Avatarフラグメントは、@/features/view-profile/api/useGetProfile のAPI通信のクエリで、以下のように記述します。
# features/view-profile/api/useGetProfile/GetProfile.graphql
query GetProfile {
profile {
avatar {
...AvatarCircle_Avatar
}
}
}
このように記述することで、features層で参照されるデータは、domainsに必要なデータのみとなります。
GraphQL Fragmentに関しては、弊社のエンジニアが分かりやすくまとめた記事がございますので、ぜひご一読ください。
domains
ここでのdomainは、プロダクトのドメインUIを指します。domainの命名は、<domain>-<property>-<ui> となります。
<domain> は、GraphQL SchemaにおけるType名です。
<property> は、ドメインの範囲を限定するために使用されますが、不要な場合は使用しません。
<ui> は、tableやcardなどのUI表現名です。
重要な点として、異なるドメイン間の依存関係は禁止されています。1つのドメインが他のドメインに依存すると、関心事が拡大し、保守する側のスキルが求められ、やがてファットなコンポーネントが誕生します。ここでのGraphQLのTypeは、そのプロダクトのコアサブドメイン(コアドメイン)を選択すると良いでしょう。
コンポーネントコンポジション
異なるドメイン間で参照したい場合は、features層で、コンポーネント・コンポジションやコンポーネント・インジェクションと呼ばれるパターンを使用します。
具体例を以下に示します。
import React, { ReactNode } from "react";
interface DomainAProps {
content: ReactNode;
}
const DomainA: React.FC<DomainAProps> = ({ content }) => {
return <div>{content}</div>;
};
interface DomainBProps {
text: string;
}
const DomainB: React.FC<DomainBProps> = ({ text }) => {
return <p>{text}</p>;
};
const FeatureA: React.FC = () => {
return <DomainA content={<DomainB text="TEXT" />} />;
};
export default FeatureA;
DomainAコンポーネントは、DomainBについて認識していません。DomainAとDomainBの両方を理解しているのは、FeatureAのみです。
余談になりますが、もしtext属性がFeatureAではなくDomainA内で決定される場合、DomainA内でReact.cloneElementを使用してtext属性を更新する方法があります。
shared
sharedは、プロダクトに依存しない再利用可能なコードのみを格納します。そのため、sharedフォルダにはプロダクトのドメイン情報が一切含まれません。
以下は、sharedフォルダに含まれる典型的なコードの例です。
- テストで使用するユーティリティ関数
- デザインシステムに準拠したUI部品
- React Hook Formのフォーム部品(TextField、Selectなど)
次に、フォルダ構造とは別の観点で、開発効率を高める上で重要な3要素、テスト、Storybook、ドキュメントについて紹介します。
テスト
テストコード設計
テストコードは、以下の価値があるため、基本的に記述するようにしています。
- テストによる動作確認のフィードバックが高速
- 境界値チェックなどのロジックが特に便利です
- 保守のために、機能を保証することが可能
- 保守する人には、将来の自分も含まれます
- 仕様書として、テストコードが役立つ
- describe、test、itを適切に記述することが重要です
テストコードでは、必ずAAAパターン(Arrange, Act, Assert)をコメントに記述し、上から下に読めるように心掛けています。また、入力値のバリエーションが多い機能には、パラメタライズドテストを使用します。
他にも、テストコードのベストプラクティスが知りたい人は、次の記事を参照ください。
さらに、テストコードでは過不足のない網羅的なテストを目指すのではなく、重複を許容して網羅的にテストを記述することを推奨しています。過不足のないテストは、確かに綺麗で美しいかもしれませんが、実際の運用は非常に大変です。そのため、重複を許容しながら網羅的にテストを記述することで、費用対効果を高めることができます。
テストパターン
フロントエンドのテストパターンは、現時点では以下の3つのカテゴリに分けて考慮しています。
- ビジュアルリグレッションテスト
- 見た目の変化をテスト
- インタラクションテスト
- インタラクションをトリガーとしたテスト
- ロジックテスト
- 条件分岐など複雑なロジックをテスト
ビジュアルリグレッションテストは、アイコンなど見た目が重要なコンポーネントのテストに最適です。具体的には、Chromaticを使ってビジュアルリグレッションを検出しています。
インタラクションテストは、クリックや入力などのユーザーからのインタラクションをトリガーに、どのような結果が期待されるかをテストします。具体的には、StorybookのInteraction testsを利用しています。ただし、テストとStorybookが混在するのは紛らわしいため、次の2つで棲み分けしています。
- Storybookでは、play関数でインタラクションを書く
- 1.のStoryをJest側に取り込み、アサーションで検証する
取り込むには、@storybook/testing-react Addon のcomposeStoriesを利用します。
ロジックテストは、hooksやstoresなどで複雑な条件分岐がある場合に適用されます。hooksを使う場合は、testing-library/react-hooks-testing-library を使います。
基本的に、全てのプロダクトコードに対して、テストコードを書くようにします。
他のテストパターン
他にも、以下のようなテストパターンを取り入れることを検討しています。
- プロパティベースドテスト
- Zodスキーマに対して、網羅的なテストを行いたい
- dubzzz/fast-check
- モンキーテスト
- features層に対して、ランダムなモンキーテストを任意の時間実行したい
- marmelab/gremlins.js
- 突然変異テスト
- 嘘のテストカバレッジをあぶり出すために、テストコードをテストしたい
- stryker-mutator/stryker-js
Storybook
私達のチームでは、UI開発にStorybookを使用します。もともと、リアーキテクチャ前にStorybookは導入されていたのですが、ほとんどメンテナンスされておらず、動かないStoryが大半でした。
今回のリアーキテクチャ対応により、ほとんど全てのUIがStorybookで確認できるようになりました。全てと言えないのは、まだリアーキテクチャ対応が残っているからです。
Storybookの活用方法については、弊社チームのメンバーが素晴らしい記事を書いていますので、よければご覧ください。
UI Stack
StorybookでUI開発を進めていくと、Storyオブジェクトの単位を考えることになると思います。
私達のチームでは、試験的にUI Stackという考え方でStoryを整理しています。具体的には、次の6つのパターンで分類しています。
- ✨ Ideal State
- ⏳ Loading State
- 🫥 Blank State
- 🍕 Partial State
- 🔥 Error State
- 🤖 (Interaction)Testing
どういうStateか判断するために、Storybookの名前のプレフィックスに絵文字を追加しています。
ドキュメント
今回のリアーキテクチャ化で決定した内容は、Markdownドキュメントとして記録しています。将来のメンバーに向けて、なぜこのような設計を採用したのか説明を残すことで、個人の記憶に依存しない情報共有が可能になります。
ドキュメントの構造は、alan2207/bulletproof-reactをコピペして 参考にしました。
ドキュメントをいきなり書き起こすのではなく、次の流れで進めました。
- Miroのようなビジュアルコラボレーションツールを用いて、たたき台を作成する。
- チームメンバーと議論を通じて、設計を決定する。
- 決定した内容やMiroのリンクを、Markdownにまとめる。
最初からたたき台をMarkdownで書き起こすことも可能ですが、たたき台の段階では大幅な修正や変更が多く、手直しがたくさん発生します。ある程度内容が固まった段階で、清書する方が効率的です。
Documentation Testing
もちろん、作成したドキュメントもメンテナンス対象です。そのため、作成したドキュメントは、Documentation testing | GitLab を実施しています。
具体的には、以下の3つの検証を行っています。
- デッドリンクのチェック
- Markdown構文のチェック
- テキストのチェック
これらのチェックをCIに組み込むことで、ドキュメントの品質を一定程度保証することができます。
リアーキテクチャ化の成果
リアーキテクチャ化を通じて、以下の課題に対して、良い点(👍)と悪い点(👎)を発見しました。
- Storybookが機能していない
- 👍 すべてのUIをStorybookで確認できるようになりました。
- プロダクションコードに対してテストコードが不十分
- 👍 テストパターンに基づいて、網羅的にテストコードを作成しました。
- 👎 features層のテストコード行数が大きくなりました。(後述します)
- ディレクトリ構造に一貫性がない
- 👍 レイヤー構造とサブフォルダを用いて、一貫した構成が実現されました。
- GraphQLで不要なデータの参照・受け渡しが行われている
- 👍 GraphQL Fragmentを利用し、必要最小限のデータのみ参照・受け渡しできるようになりました。
- コンポーネントの命名規則が不規則
- 👍 featuresやdomainsに関して、命名ルールに基づくネーミングが実現されました。
- 👎 features層におけるactionのネーミングで、適切なものを見つけるのが困難でした。
- さまざまなデータに密結合し、再利用性が低いコンポーネント
- 👍 featuresとdomainsの役割分担により、domainsはデータの表示に特化し、再利用性が向上しました。
features層の肥大化の整理
features層は多くの責務を担当し、プロダクトコードやテストコードが肥大化している問題があります。
プロダクトコードの整理
api、stores、およびhooksは整理されていますが、uiコードはapiやstoresを統合するために、コード行数が多くなりがちです。多いコード行数は必ずしも悪いとは限りませんが、全体像の把握に時間がかかるため、可能ならコンパクトにしたいと思っています。もちろん、何でも1つのファイルに詰め込んで行数を減らすEasyではなく、責務に応じたSimpleな設計にしたいです。 (SimpleとEasyは違う という記事が好きです)
uiコードでは以下のような処理が行われています。
- apiからdataとfetchingを取得
- storesやhooksからstateとactionを取得
- domainUIにdataやstate、actionを渡す
現時点では解決策が見つかっていませんが、features層とproviders層の間に新しい層を作成することも選択肢の一つと考えられます。
テストコードの整理
テストコードの肥大化は、features層がすべての機能を持っているためにテストが書きやすくなっていることが原因です。これは良い結果ではありますが、多くのインタラクションテストが書かれているため、一つの*.test.tsxファイルのコード行数が大きくなっています。
インタラクションテストを純粋に切り出す(*.scenario.test.tsx)ことにより、コードの分割を試みています。
副次的な効果の発見
副次的な効果として、以下の2つの効果が見られました。
- レイヤー構造による制約が設計をより深く意識させる
- テストコードやStorybookが開発時に自然に書かれるようになり、意識改革が起こった
第一の効果については、機能改修を行う際に、これまで紹介した制約(依存の一方向性やdomains間の依存禁止など)によって、レイヤー構造に適合する設計が求められるようになりました。例えば、フォルダやコンポーネントの名前を慎重に検討するようになったり、適切な場所へロジックを配置することなどです。これは責務を考える良い機会となります。
第二の効果では、チームメンバーが開発する際、これまではプロダクトコードの実装が主でしたが、テストコードやStorybookも自然に書かれるようになりました。この意識改革は非常に素晴らしい変化だと考えます。
今後の展望
現時点では、リアーキテクチャの対応はまだ完了していませんが、これを終わらせる予定です。また、features層の肥大化に関しても、層の見直しにチャレンジすることも検討しようと思っています。
一方で、私はプロダクトへの受け入れテストの設計と実施に挑戦したいと考えています。ATDDの考え方に基づいて、ビジネス観点で重要な機能を担保できる仕組みを試してみたいと思います。具体的には、cucumber-jsとマークダウン形式の仕様書を用いてテストコードを記述し、screenplay設計とPlaywrightを統合して、仕様書ベースのE2Eテストに挑戦したいと考えています。
以下のリンクは、先ほど紹介した技術スタックのリンクです。
- https://github.com/cucumber/cucumber-js
- https://github.com/cucumber/gherkin/blob/main/MARKDOWN_WITH_GHERKIN.md
- https://github.com/microsoft/playwright
- https://github.com/cucumber/screenplay.js
終わりに
本記事を最後までお読みいただき、ありがとうございます。Webフロントエンドは、バックエンド、インフラ、データとは異なり、コードベースの変更頻度が高く、非常にダイナミックな分野です。完璧な設計を網羅する銀の弾丸は存在しないため、トレードオフを伴う設計が一般的です。プロダクトの特性に応じた設計力が重要となります。
さらに、メンテナンスを担当する人々や組織の観点、プロダクトの背景や成り立ちを含めると、設計の難易度はさらに高まります。しかし、このような要素があるからこそ、Webフロントエンド設計はやりがいのある魅力的な領域であると私は考えています。
この記事に少しでもご興味を持たれた方がいらっしゃいましたら、ぜひ以下のリンクから求人ページをご覧いただき、ご応募をお待ちしております。カジュアル面談からでも大歓迎です!
あとがき
ChatGPTに「次の文書を清書してください。」と依頼し、清書された文書を確認して置き換える作業を行いました。さらなるチューニングが可能なプロンプトエンジニアリングがあると思いますが、私にとってはこれで十分でした。

Discussion