📚
Amazon BedrockをPythonアプリとAPI連携させてみた。
はじめに
- AWS, Python, Django初学者です。
- Amazon Bedrockのモデルアクセスまでは完了しました。
- 今回の記事ではDjangoアプリとのAPI連携についてまとめていきたいと思います。
- Bedrockのモデルアクセスのやり方は前回の記事を参照してください。
https://zenn.dev/monaka0309/articles/1698d879acae0f
使用技術
- Python
- Django
- Amazon Bedrock
流れ
- Boto3のインストール
- ポリシーの作成
- AWSのアクセスキーの用意
- Djangoから呼び出す
1. Boto3のインストール
- Boto3を使用することで、Pythonのアプリケーション、ライブラリ、スクリプトをAWSの各種サービス(Amazon S3、Amazon EC2、Amazon DynamoDB など)と容易に統合できます。
pip install boto3
2. IAMポリシーの作成
- 以下のコードが実装した内容です。
- 今回のAIモデルは
amazon.titan-text-premier-v1で進めていきます。 -
InvokeModel- リクエスト本文で提供された入力を使用して推論を実行するために、指定された Bedrock モデルを呼び出すための許可を付与します。
-
InvokeModelWithResponseStream- ストリーミングレスポンスとともにリクエスト本文で提供された入力を使用して推論を実行するために、指定されたBedrockモデルを呼び出すための許可を付与します
-
ListFoundationModels- 使用できるBedrockの基盤モデルを一覧表示するための許可を付与します。
json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowSpecificBedrockActions",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-text-premier-v1"
},
{
"Sid": "AllowAdditionalBedrockActions",
"Effect": "Allow",
"Action": [
"bedrock:ListFoundationModels"
],
"Resource": "*"
}
]
}
3. AWSのアクセスキーの用意
-
アクセスキーがない場合は作成してください。
-
IAMのユーザーから対象のユーザーを選択してください。
-
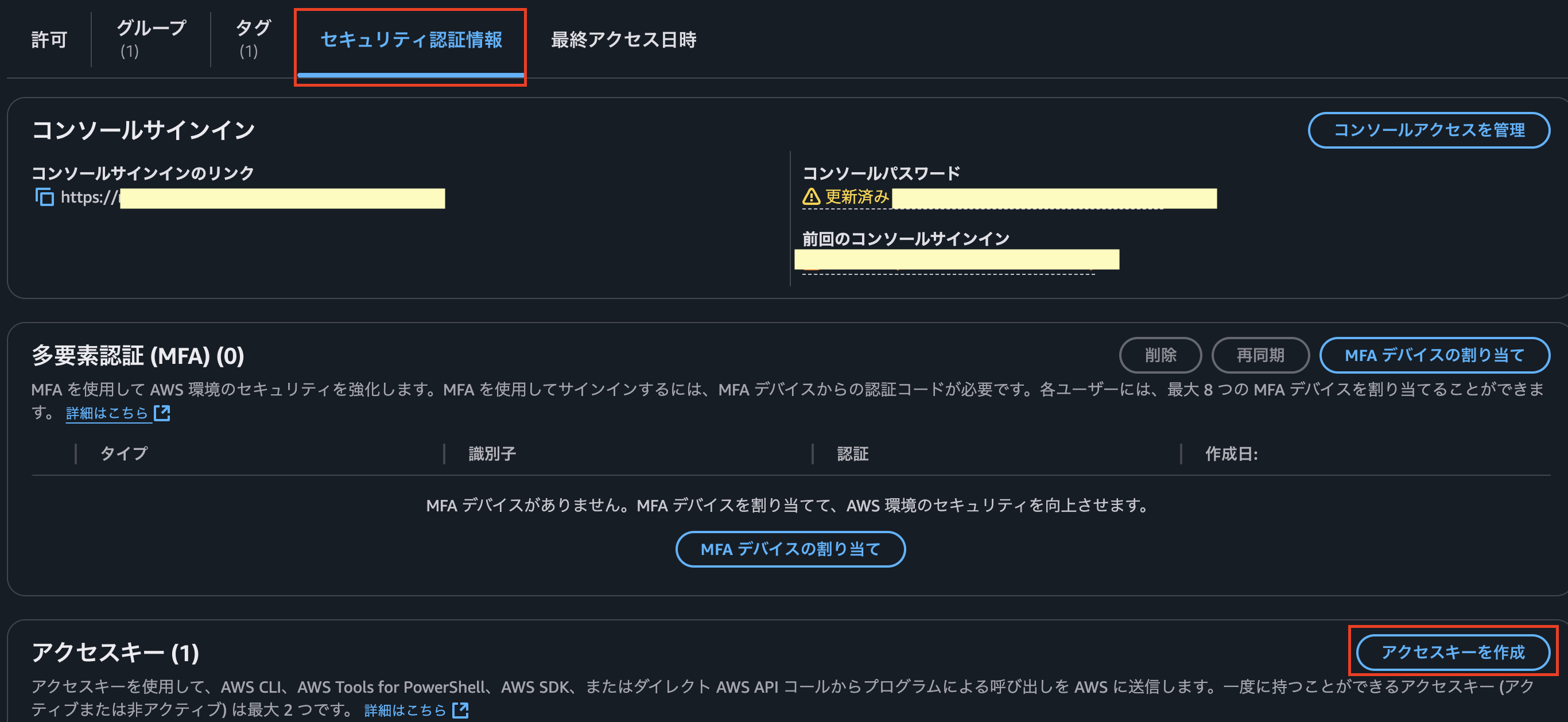
「セキュリティ認証情報」の項目からアクセスキーの作成を選択。
-
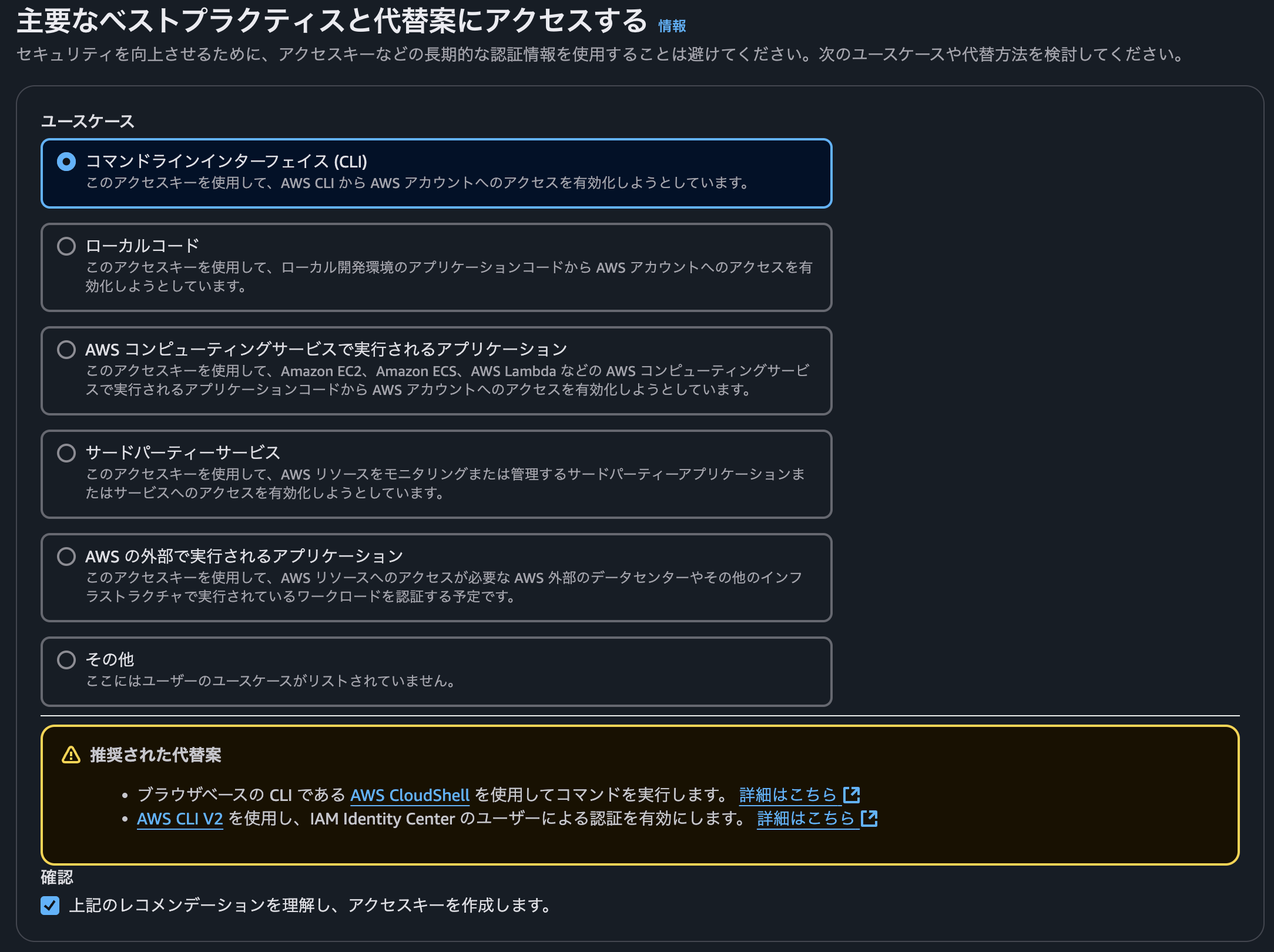
「主要なベストプラクティスと代替案にアクセスする」の画面が表示されるので、自分のユースケースに合わせて選んでください。
-
「上記のレコメンデーションを理解し、アクセスキーを作成します。」にチェックを入れたら作成します。
-
アクセスキー、シークレットアクセスキーは控えておきましょう。
4. DjangoからAPIを呼び出す
-
.envファイルにAWSの値を記載する。
.env
AWS_ACCESS_KEY_ID=~~~~~~~
AWS_SECRET_ACCESS_KEY=~~~~~~~~
AWS_REGION=us-east-1
-
django-environで.envファイルから情報を取り出します。
pip install django-environ
settings.py
import environ
#.envファイル読み込み
env = environ.Env()
env.read_env('.env')
AWS_ACCESS_KEY_ID = env('AWS_ACCESS_KEY_ID')
AWS_SECRET_ACCESS_KEY = env('AWS_SECRET_ACCESS_KEY')
AWS_REGION = env('AWS_REGION')
- 入力値をAIモデルに渡して、AIモデルからのレスポンスを返す。
forms.py
class AiForm(forms.Form):
content = forms.CharField(widget=forms.Textarea, label="天気について相談を書いてください")
widgets = {
'content': forms.Textarea()}
-
invoke_modelメソッドで指定されたテキストの埋め込みを生成します。 -
model_idでAIモデルを指定します。 -
maxTokenCountは、AIが出力できる最大の単語数。 -
stopSequencesは、出力を止める特定の文字列や記号のリスト。 -
temperatureは、ランダムさの度合いを0〜1で表す。0に近いと堅実な出力、1に近いと創造的な出力になる。 -
topPは、確率の高い単語の中から選ぶ割合。
views.py
import boto3
~~~
def generate_text(model_id, body):
bedrock = boto3.client(
service_name='bedrock-runtime',
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),
region_name=os.getenv('AWS_REGION'),
)
accept = "application/json"
content_type = "application/json"
response = bedrock.invoke_model(
body=body, modelId=model_id, accept=accept, contentType=content_type
)
response_body = json.loads(response.get("body").read())
return response_body
def ask(request):
model_id = 'amazon.titan-text-premier-v1:0'
aiForm = forms.AiForm(request.POST or None)
if aiForm.is_valid():
prompt = aiForm.cleaned_data["content"]
else:
return render(request, "ai/ask.html", context={
"aiForm": aiForm,
})
body = json.dumps({
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 3072,
"stopSequences": [],
"temperature": 0.7,
"topP": 0.9
}
})
response_body = generate_text(model_id, body)
output_text = response_body['results'][0]['outputText'] if response_body['results'] else "結果なし"
# コンソールで出力確認。
print(f"入力トークン: {response_body['inputTextTokenCount']}")
for result in response_body['results']:
print(f"トークン数: {result['tokenCount']}")
print(f"結果: {result['outputText']}")
print(f"Completion reason: {result['completionReason']}")
return render(request, "ai/result.html", context={
"content": prompt,
"output_text": output_text
})
最後に
- 最後まで読んでいただいてありがとうございました。
- 初めてだったので間違いがあるかもしれません。
- 誤り等ありましたらご指摘いただけると幸いです。
参考文献
Discussion