💨
機械学習に役立つ画像収集ライブラリの紹介



検証動画
検証
皆さん、機械学習をするにあたり学習データの収集に苦労したことはないでしょうか。
今回は、学習するにあたり役に立つライブラリ「icrawler」を紹介します。
ライブラリの詳細については、github(@gist
)を確認して頂ければ良いですが、簡単に言えばWebクローラーです。
画像サイトのFlickrだけでなく、Google、Bing、Baiduの検索エンジンも利用することができます。
では、実際にサンプルコードを書いていきます。
まずは、インストールをしましょう。
pip install icrawler
インストールができましたら、コードを書いていきます。
from icrawler.builtin import GoogleImageCrawler
google_crawler = GoogleImageCrawler(storage={'root_dir': 'test'})
google_crawler.crawl(keyword='aurora', max_num=100)
たった3行で書くことができました。
では、中身を見ていきましょう。
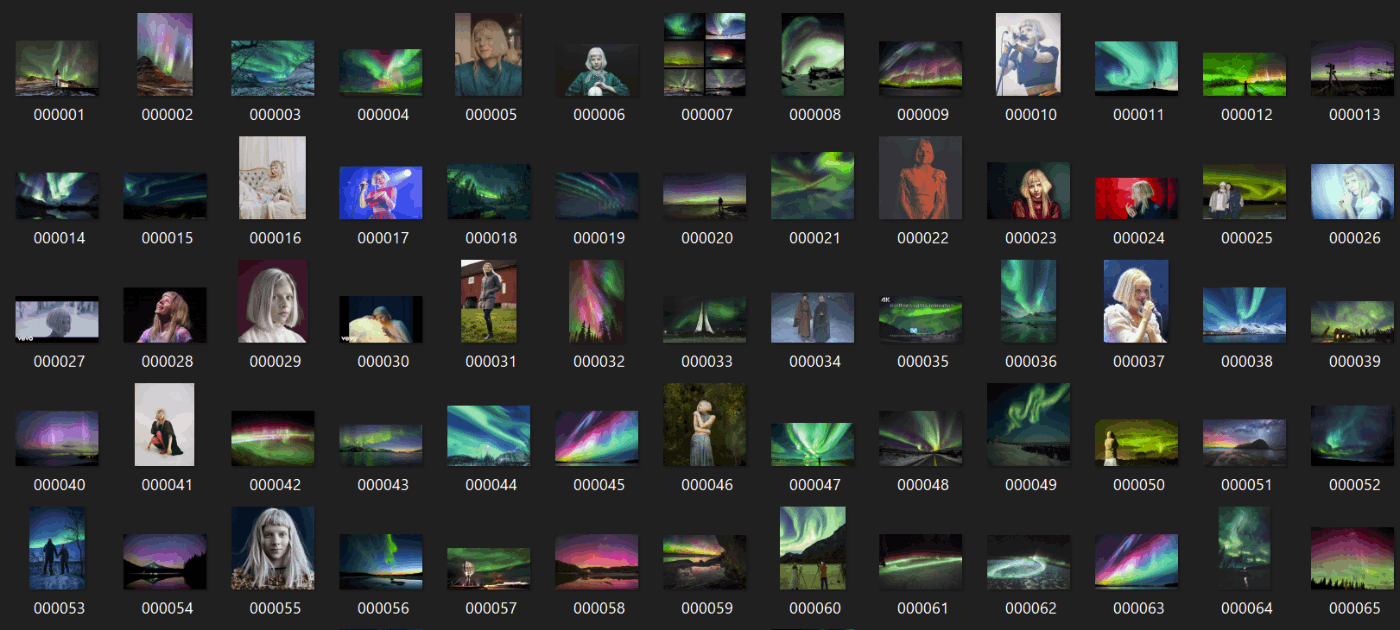
見て頂くと確認できると思うのですが、約20%ほどノルウェー出身のシンガーソングライターのAURORAが含まれていることができますね。
もし、機械学習をするのであれば、データクレンジングをしていく必要がありますね。
Discussion