「システム運用の基本と戦略」についてただまとめる
23卒でバックエンドエンジニアをしているたかしゅんです。https://x.com/moko_poi
先日、株式会社サイバーエージェントAI事業本部の2024年度 エンジニア新卒研修でシステム運用に関する講義を行いました。
そこで話した内容とスライドを完全公開したので、内容について解説します。
90分の内容のため、かなり長いですが、個人的にぜひ一読して欲しい内容になっています。
実際の資料はこちらになります↓
自己紹介
こんにちは、たかしゅんと言います。2023年度入社で今年で2年目になります。
入社して最初に広告プロダクトに配属し、PipeCDの導入などのDevOps業務を中心に行なっておりました。
記事もあるのでもしよろしければ、ご覧ください。
2月中旬から移動し、新規立ち上げのインフラ環境の構築からCI/CDの整備などに取り組み、リリースを行いました。
業務外では来年開催の「SRE Kaigi」のコアスタッフとして活動しております。
1.はじめに
新卒研修では以下の内容を目的としています。
- 運用に対する知識を増やす
- クラウドネイティブ化の歴史を理解する
- DevOpsやSREなどの最新の運用戦略を学ぶ
1年間の業務を通じて、学生時代やインターン時との最も大きな違いは、プロダクトに対する当事者意識と、お金を動かしているという責任感でした。
学生時代は開発に注力していたため、運用について学ぶことが多く、運用の重要性について今回は取り上げました。
運用に求められるスキル
エンジニアとして必要な知識は変わりません。ネットワークの構成、トラフィックの流れ、サーバーやOSに関するコンピュータサイエンスの基礎知識などが含まれます。しかし、最も重要なスキルは「高い当事者意識」を持つことです。
技術力が高くても、それを発揮できなければ意味がありません。運用は、システムをより良くしたいという強い意欲があって初めて成り立ちます。プロダクトを自分が支え、動かしているという責任感を持つことが大切です。
日々技術は進化しているため、最新の技術やツールを常に追いかけ、改善を図る必要があります。このため、クラウド技術が登場しました。コンテナ、サーバーレス、フルマネージドサービスなどがその例です。
これらの技術は非常に便利ですが、注意が必要です。適当に使ってしまうと、問題が発生した際に対応できなかったり、システムがブラックボックス化してしまうリスクがあります。
しかし、OSやカーネル、メモリ、ネットワークなどの基本的な技術を理解していれば、新しい技術の変化にも迅速に適応でき、最適な選択や対処が可能です。
最新技術を学ぶ際には、その歴史や背景を理解することが重要です。これにより、より深い理解と最適な応用が可能になります。
2.システム運用
システム運用とは、システムがリリースされてからサービス提供が終了するまでの間、システムを安定的に稼働させ続けるための維持・管理を指します。
これには、運用を開始する前に、機能要件と非機能要件の両方を理解し、定義することが重要です。
2.1 機能要件と非機能要件
機能要件:
システムが実行すべき具体的な機能や操作を定義します。
例えば、ログイン機能や決済データの分析などです。
非機能要件:
システムの品質を定義する要件であり、パフォーマンス、セキュリティ、スケーラビリティなどが含まれます。
例えば、システム障害時に3秒以内に復旧することや、検索ボタンを押してから3秒以内に結果を表示することなどです。
これらの要件を定義することで、プロジェクトのスコープを明確にし、予算やリソースの計画、リスク管理を効率的に行うことができます
2.2 運用の種類
システム運用には、いくつかの種類があります。以下に代表的なものを挙げます。
業務運用
ユーザーやシステム管理者が円滑に業務を行えるようにするための運用です。具体例として、サポートデスクの運用やPCの貸し出し管理などがあります。
基盤運用
アプリケーションが安定して稼働するための基盤を支える運用です。これには、パッチ管理、バックアップ、リストアなどが含まれます。基盤運用は、システムの安定性を維持し、障害発生時のリカバリーを迅速に行うために不可欠です。
2.3 基盤運用の具体例
基盤運用の原則とプラクティスは、システムの安定性と信頼性を確保するために不可欠です。これらの原則はどんなドメインやサービスにも適用可能です。なぜなら、システム運用における基本的な課題やリスクは、業種やサービスの内容に関わらず共通しているからです。例えば、アカウント管理、ログ管理、パッチ適用、バックアップとリストア、コスト最適化などの運用タスクは、どのようなシステムでも重要です。これらの基本的な運用スキルと知識を習得しておくことで、異なるドメインやサービスにおいても迅速に適応し、適切に運用管理を行うことが可能になります。
アカウント運用:
認証(本人確認)と認可(権限付与)を管理します。適切なアカウント運用により、不正アクセスやデータ漏洩のリスクを最小限に抑えます。
ログ運用:
システムの各種ログを収集、管理し、異常検知やトラブルシューティングに利用します。効果的なログ運用により、システムの問題を早期に発見し、対応することが可能です。
パッチ適用:
OSやソフトウェアの更新を行い、セキュリティホールを修正します。計画的なパッチ適用作業が、システムの信頼性を維持するために重要です。
バックアップとリストア:
データの消失や破損に備えて、定期的にバックアップを取得し、必要に応じてリストアします。これにより、データの保全とシステムの継続的な稼働を確保します。
コスト最適化:
クラウドサービスの利用コストを最適化し、不要なリソースを削減することで、効率的な運用を実現します。
エンジニアが目に見える形で直接的にすぐにお金に影響を与えられるのはコスト削減です。無駄なものを使わないことは重要であり、リソースの最適化を行うことはエンジニアとしての大きな強みになります。
コストの最適化を通じて、運用効率を向上させることで、ビジネスに対して直接的な価値を提供することができます。
3.監視
はじめに
本題に入る前にお伝えしたいのは、この講義の前にオブザーバビリティに関する講義が行われたことです。
そのため、今回の内容は運用視点から監視に関する重要なポイントにフォーカスしています。
オブザーバビリティについての詳細な資料はこちらをご参照ください
3.1 監視の重要性
システム運用において、監視はシステムのパフォーマンスを維持し、潜在的な問題を早期に発見して対処するために不可欠です。適切な監視により、ユーザー体験を向上させ、運用コストを削減することができます。
監視は、単にシステムが動作しているかを確認するだけでなく、システムの健全性を維持するための重要な手段です。
3.2 監視のアンチパターン
ツール依存
監視ツールに過度に依存すると、ツール自体の制約に縛られてしまいます。銀の弾丸となる監視ツールはないため、必要に応じてツールを増やしたり、自作することも検討します。
チェックボックス監視
「これを監視しています」と誰かに言うための監視は、実質的な価値を生みません。監視する理由が明確でない場合、その監視を見直すべきです。
監視を支えにする
監視しているからといって安心するのではなく、監視結果を元にシステムの改善を行うことが重要です。監視は状況の確認手段であり、改善のためのアクションが必要です。
監視の目的は「問題を予防し、迅速に対応できるようにすること」であり、「単にシステムが動作しているかを確認するもの」ではありません。義務的にダッシュボードを眺めているだけの監視は、システムの改善に繋がりづらく、無駄な人件費がかかるだけです。
監視は、システムの健全性を維持し、ユーザー体験を向上させるための積極的なツールであるべきです。効果的な監視を実践することで、システムの信頼性を高め、迅速な問題解決を実現しましょう。
3.3 監視のデザインパターン
ユーザー視点での監視
監視の目的は、ユーザーの体験を直接的に改善することです。例えば、HTTPのレスポンスコードやリクエスト時間など、ユーザーに直接影響を与えるメトリクスを最優先に監視します。
組み合わせ可能な監視
監視システム全体のカスタマイズ性と拡張性を向上させるために、各コンポーネントを個別に扱うアプローチを採用します。これにより、データ収集、データストレージ、可視化、分析とレポート、アラートの各要素を専門的に対応することが可能になります。
作るのではなく買う
高機能な監視ツールを使用することで、コストと時間を節約し、製品や機能の改善に集中できます。市場に出回っている信頼性の高いツールを利用することで、監視体制を迅速に整えることができます。
3.4 監視の具体的な実践
アラート
緊急性に応じて、SMSやPagerDutyを使用し、日常の通知は社内チャットで行います。アラートの内容や修復の手順が分かるリンクを含めることで、迅速な対応が可能になります。対応が自動化できるものは自動化し、人的負担を減らします。
オンコール体制
エンジニアを含めてオンコールローテーションを行い、アラート対応を分散させます。オンコールデータを分析し、アラートの設定を最適化することで、効率的な対応体制を構築します。
インシデント管理
サービスの特性に合わせてカスタマイズされたITILフレームワークを使用します。役割分担を事前に明確にし、迅速な対応を行います。インシデントが発生した際には、詳細な記録を取り、後にポストモーテムを行い、再発防止策を講じます。
参照:入門 監視 ―モダンなモニタリングのためのデザインパターン
補足:
監視は直接的にビジネスの売り上げを生み出すものではないため、ビジネス側の人間からは「本当に必要なのか」「そのコストに見合う価値があるのか」と疑問に思われがちです。
ここで重要なのは、エンジニアがどのようなメリットがあるのか、導入によってプロダクトがどのように良くなるのかを明確に示し、ビジネス側の納得を得ることです。
エンジニアは、監視の導入がもたらす具体的なメリットを説明し、システムの信頼性やユーザー体験の向上、ダウンタイムの削減などを強調する必要があります。
監視がプロダクトの品質向上に直接寄与することをビジネス側に理解させ、必要な予算を確保することが重要です。
エンジニアは技術的な利点だけでなく、ビジネス的な視点からも監視の重要性を説明し、納得させる役割を果たすべきだと考えます。
4. クラウドネイティブ時代の運用戦略
そもそも「クラウドネイティブ」とは何でしょうか?クラウドネイティブは、クラウド環境を最大限に活用してアプリケーションを設計、開発、運用するアプローチを指します。これには、スケーラビリティ、柔軟性、回復力の向上を目指すための様々な技術とプラクティスが含まれます。
クラウドネイティブの基本要素として、コンテナ、マイクロサービス、サーバーレスアーキテクチャ、継続的デリバリーなどがあります。これらの技術は、アプリケーションの開発と運用を迅速かつ効率的に行うために設計されています。
また、クラウド環境がより一般的になったことで、様々な運用戦略が登場しました。代表的なものに以下があります。
DevOps: 開発と運用のサイロを解消し、協力して迅速に高品質なソフトウェアを提供するための一連のプラクティスです。
SRE (Site Reliability Engineering): Googleが提唱する運用手法で、ソフトウェアエンジニアリングのアプローチを使って信頼性の高いシステムを構築します。
MicroService Architecture: アプリケーションを小さな独立したサービスに分割し、それぞれを独立してデプロイおよびスケールできるようにするアーキテクチャです。
Platform Engineering: 開発者が効率的に作業できるように、セルフサービスプラットフォームを構築する手法です。
これらの戦略を活用することで、クラウドネイティブの利点を最大限に引き出し、迅速かつ効率的なアプリケーション開発と運用を実現できます。クラウドネイティブのアプローチは、現代のアプリケーション開発において欠かせないものとなっています。
5. DevとOpsのサイロ化
従来の組織体系では、開発チーム(Dev)と運用チーム(Ops)が明確に分かれており、それぞれが独立して作業を行っていました。
開発チームは設計、開発、テスト、リリースを担当し、機能開発に責任を持ちます。
一方、運用チームは運用、保守、障害対応を担当し、システムの稼働率に責任を持ちます。
しかし、この役割分担はサイロ化を招き、コミュニケーション不足や目標の相違が生じることがありました。
このような問題を解決するために生まれたのが「DevOps」という考え
6 DevOps
DevOpsの教科書では以下のように定義されておりました。
DevOpsは、高品質を保ちつつ、システムに変更をコミットしてからその変更が通常の本番システムに組み込まれるまでの時間を短縮することを目的とした一連の実践である
参照:DevOpsの教科書
DevOpsは、開発と運用のサイロ化を解消し、協力して迅速に高品質なソフトウェアを提供するための一連のプラクティスです。
主な目的は、システムに変更をコミットしてからその変更が本番システムに組み込まれるまでの時間を短縮することです。
これにより、頻繁なリリースと稼働率の向上という相反する目標を達成します。
またDevOpsの4つの原則は次の通りです:
- ソフトウェア開発ライフサイクルの自動化:CI/CDやIaCを使用して、1日に何度もコードをリリースすることが可能です。
- コラボレーションとコミュニケーション:開発担当者と運用担当者が一体となり、協力します。
- 継続的な改善と無駄の最小化:常に改善を行い、無駄を最小化します。
- ユーザーニーズの重視とフィードバックループの最短化:ユーザーニーズを中心に開発を進め、迅速にフィードバックを取り入れます。
これらの原則を守ることで、迅速なリリースサイクル、高い品質と信頼性、効率的なチームワーク、ユーザー中心の製品開発が実現し、ユーザーのニーズに迅速に対応しながらシステムの信頼性と競争力を向上させることができます。また、何から始めれば良いかわからない場合は、これらの指針を参考にしてください。
参照:https://www.pagerduty.co.jp/blog/what-is-devops
DevOpsではない例、DevOpsの例
では実際にDevOpsを実践する方法として、どのようなものがあるのでしょうか?
それらをわかりやすくするために、DevOpsではない例とDevOpsの例についてご紹介したいと思います。
DevOpsではない例
- 手作業での一貫性のないソフトウェアのデプロイ
- 不十分な手作業での品質保証
- 障害時のロールバック計画がない
- リリースを行うのに管理者の手動での承認が必須
上記の方法では以下のような問題を引き起こす可能性があります。
- デプロイ手順がドキュメント化されておらず、担当者によって方法が異なるため、一貫性がありません。
- デプロイ時にミスが発生しやすく、稼働中のシステムに影響を与えるリスクがあります。
- 問題が発生した際に迅速にロールバックできる計画がなく、復旧に時間がかかります。
DevOpsの例
- ブランチ戦略
- フィーチャーフラグ
- 継続的インテグレーション(CI)
- 継続的デリバリー(CD)
- IaC
- GitOps
それでは一つずつ詳しく解説したいと思います。
6.1 ブランチ戦略
ブランチ戦略は、ソースコード管理システム(例:Git)において、開発の流れを整理し、効率的に作業を進めるための方法です。主なブランチ戦略には以下があります:
メインブランチ:常にデプロイ可能な状態を維持します。
デベロップブランチ:次のリリース候補となる機能や修正を統合するためのブランチです。
フィーチャーブランチ:個々の機能や修正のために一時的に作成されるブランチです。作業が完了したらデベロップブランチにマージされます。
リリースブランチ:リリース準備が整った機能を安定させるためのブランチです。最終的なテストとバグ修正が行われます。
ホットフィックスブランチ:本番環境で発生した緊急のバグ修正のためのブランチです。修正が完了したら、メインブランチとデベロップブランチにマージされます。
これらのブランチ戦略を活用することで、開発プロセスが整理され、チーム全体の効率が向上します。
6.2 GitFlow
GitFlowは、Vincent Driessenが提案したブランチ戦略であり、複雑なリリースサイクルを持つプロジェクトに適しています。以下のブランチを使用します:
- メインブランチ(master):常に安定したリリース可能な状態を維持します。
- デベロップブランチ(develop):次のリリース候補となる機能を統合します。
- フィーチャーブランチ(feature):個々の機能開発用のブランチです。developブランチから作成し、完了後にdevelopブランチにマージします。
- リリースブランチ(release):リリース準備のためのブランチです。developブランチから作成し、テストと修正を行い、最終的にmasterとdevelopブランチにマージします。
- ホットフィックスブランチ(hotfix):本番環境での緊急修正用のブランチです。masterブランチから作成し、修正後にmasterとdevelopブランチにマージします。
GitFlowは、リリース管理を厳格に行いたい場合に有効です。

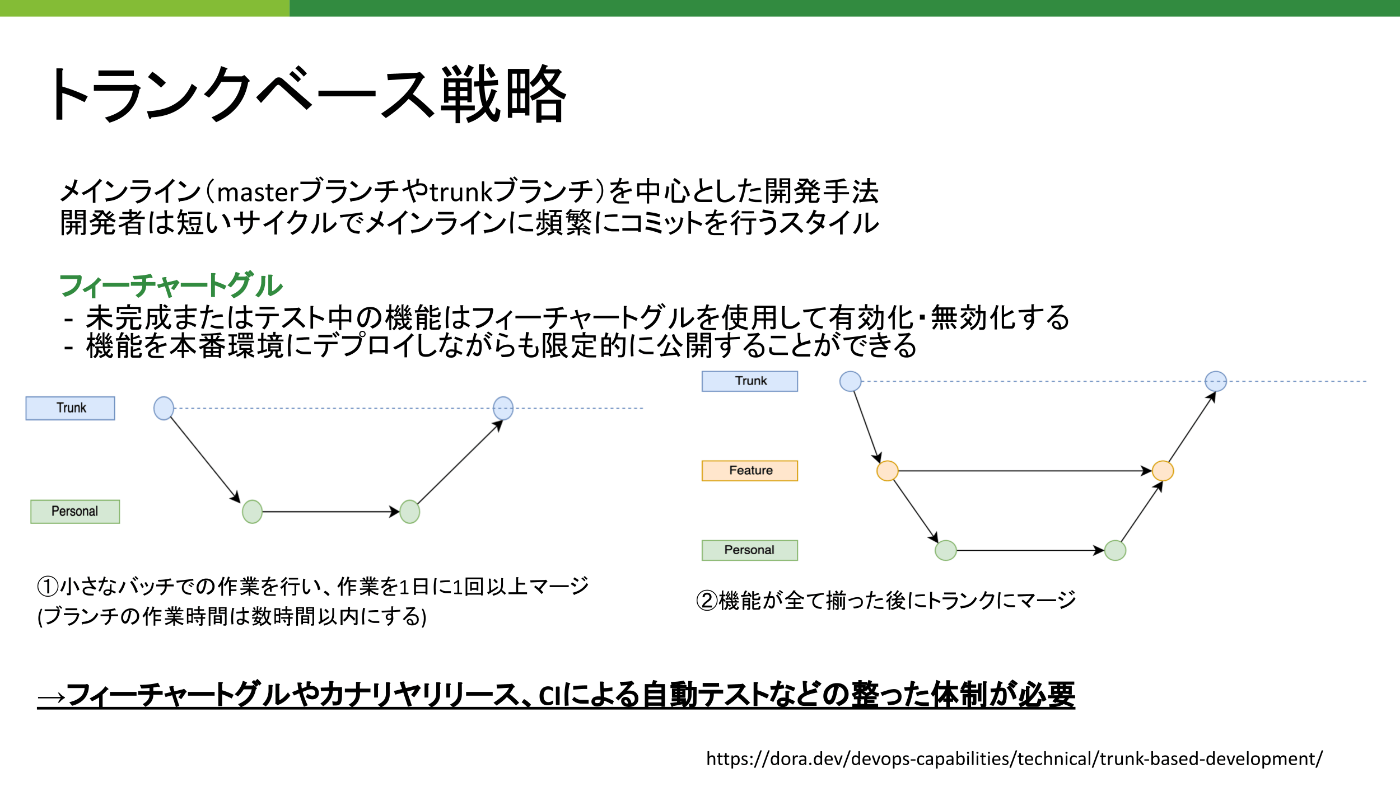
6.3 トランクベース開発
トランクベース開発(Trunk-Based Development)は、短いフィーチャーブランチを使用し、頻繁にメインブランチ(トランク)にマージする開発手法です。以下の特徴があります:
短いフィーチャーブランチ:フィーチャーブランチは数日以内に完了し、メインブランチにマージされます。
頻繁なマージ:開発者は頻繁にコードをメインブランチにマージし、継続的にインテグレーションを行います。
継続的デリバリー:自動化されたテストとデプロイメントパイプラインを使用して、頻繁にリリースを行います。
トランクベース開発は、迅速なリリースサイクルと高いアジリティを求めるプロジェクトに適しています。これにより、コンフリクトの発生を最小限に抑え、コードの品質と安定性を維持しながら開発速度を向上させることができます。
6.4 フィーチャーフラグ
フィーチャーフラグは、ソフトウェア開発において特定の機能を動的にオンまたはオフにするための仕組みです。これにより、デプロイとリリースを分離し、安全かつ柔軟に機能を管理できます。
利用例と利点
- 限定的なリリース:一部のユーザーにのみ新機能を提供し、フィードバックを得ることで、問題を早期に発見できます。
- トランクベース開発:開発中の機能を無効化した状態でデプロイし、必要に応じて有効化できます。
- 'A/Bテスト:異なるバージョンの機能をユーザーに提供し、その効果を比較できます。
具体的な実装
フィーチャーフラグを実装するためのツールとして、CA発のOSS「Bucketeer」やAWSの「Amazon CloudWatch Evidently」などがあります。これらを利用することで、柔軟かつ効率的なフィーチャーフラグの管理が可能になります。
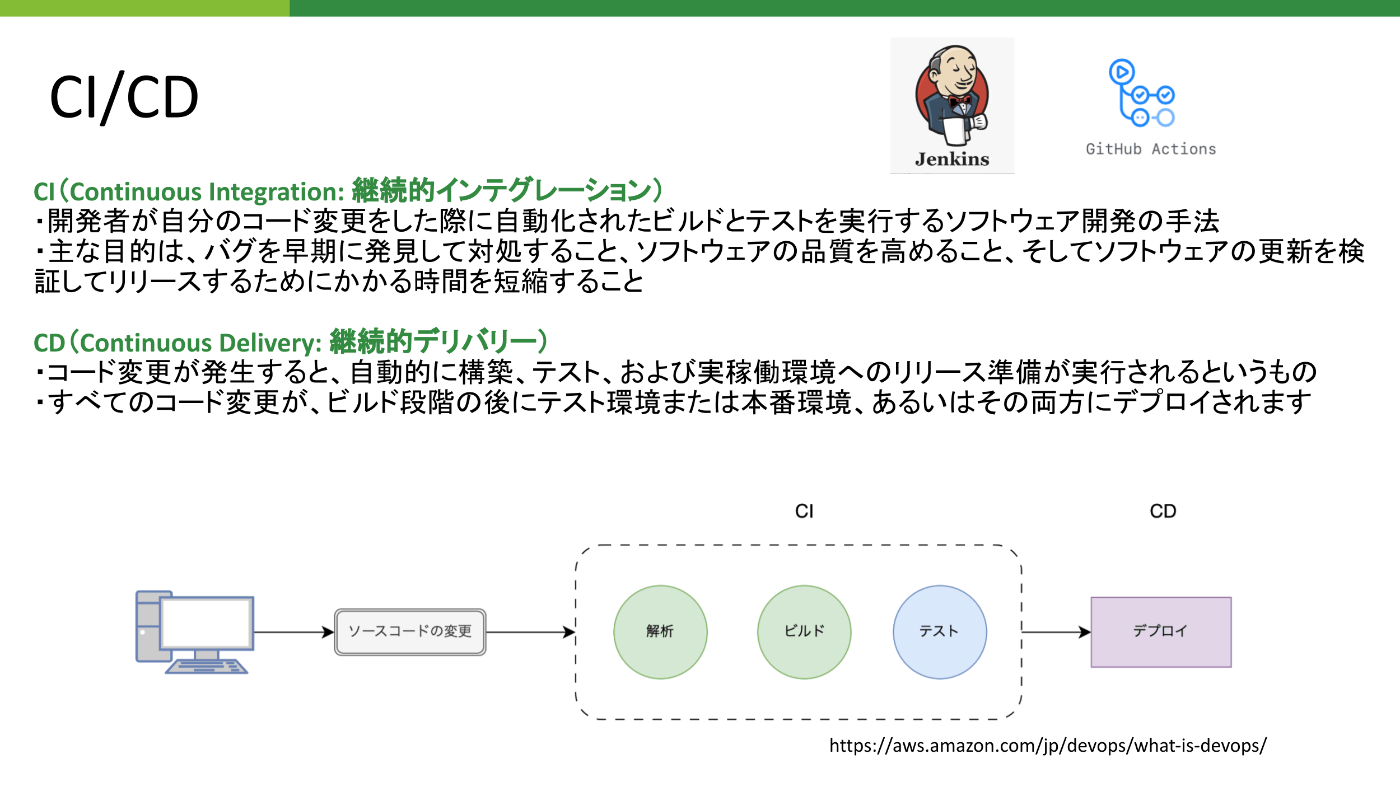
6.5 CI/CD
継続的インテグレーション(CI)と継続的デリバリー(CD)は、ソフトウェア開発プロセスの自動化と品質向上を目指すプラクティスです。
継続的インテグレーション(CI)
- 目的:開発者がコードをコミットするたびに自動ビルドとテストを実行し、バグを早期に発見します。
- 利点:コードの品質を保ちながら、開発スピードを向上させることができます。代表的なツールとして、Jenkins、Travis CI、GitHub Actionsなどがあります。
’継続的デリバリー(CD)
- 目的:コード変更が発生すると自動的に構築、テスト、および実稼働環境へのリリース準備を行います。
- 利点:すべてのコード変更がリリース可能な状態に保たれ、頻繁にリリースできるようになります。CircleCIやGitLab CI/CDなどのツールを使用します。
'
6.6 IaCとGitOps
IaCは、インフラストラクチャをコードとして管理する手法で、一貫性と再現性を確保します。
利用例と利点
- 環境の一貫性:環境構築がコードで定義されているため、同じ設定を何度でも再現できます。
- エラーの減少:手動設定によるヒューマンエラーが減少し、信頼性が向上します。
- 文書化と管理:コードがそのまま文書として機能し、状態の追跡と管理が容易になります。
具体的なツール
- Terraform:インフラストラクチャの設定をコードで管理するツール。
- AWS CloudFormation:AWSリソースをコードで管理し、一貫した設定を実現します。
- Ansible:構成管理ツールとして、インフラの自動化を支援します。
GitOpsは、Gitリポジトリをインフラストラクチャおよびアプリケーションの単一の信頼できる情報源(ソースオブトゥルース)として使用するプラクティスです。
利用例と利点
- 一貫性:Gitリポジトリの状態を基に環境が管理されるため、一貫性が保たれます。
- 監査性:すべての変更がGitの履歴に記録され、変更の追跡と監査が容易になります。
- 自動化:Argo CDやFluxなどのツールを使用して、Gitリポジトリの状態を自動的にデプロイし、管理します。
具体的なツール
- Argo CD:Gitリポジトリの状態を基に、自動でアプリケーションをデプロイするツール。
- Flux:Kubernetes上でGitOpsを実践するためのツール。
- PipeCD:CA発のOSSで、複数のデプロイメント手法に対応し、継続的デリバリーを支援します。

6.7 DevOpsを実践する
DevOpsを実践することで、システムの稼働率を下げることなくリリース頻度を高めることが可能になります。これにより、迅速なリリースサイクルが実現し、ユーザーのニーズに迅速に対応できるようになります。頻繁なリリースは継続的なフィードバックを可能にし、システムの改善と高い品質・信頼性の維持を助けます。
ではリリース頻度を高めるにはどのような方法があるのでしょうか?
さまざまな方法がありますが、その中でも一つの考え方としてSite Reliability Engineering(SRE)というものがあります。
7. SREとは
7.1 DevOpsとSREの違い
まず初めにDevOpsとSREの違いについて説明したいと思います。
“class SRE implements interface DevOps”
参照:https://sre.google/workbook/how-sre-relates/?_fsi=XoYJpNx5
上記のように説明されており、要するに「DevOpsの実現方法の一つがSRE」と説明されております。
具体的には、DevOpsは文化とプロセスの改善に重点を置き、組織全体の変革を目指すことであるが、SREは具体的な運用の実践とサービスの可用性に焦点を当て、エラーバジェットなどの具体的な概念を導入するといった違いです。
要するにDevOpsとSREは、多くの共通点を持ちながらも、それぞれ異なる焦点と手法を持つアプローチです。
どちらも運用を改善するための手段であり、組織の支持と文化的な変革が不可欠です。
ではSREとはどう言ったものなのでしょうか?
7.2 SRE(Site Reliability Engineering)
Googleが提唱したものであり、定義として以下のように記述されております。
So SRE is fundamentally doing work that has historically been done by an operations team, but using engineers with software expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to, substitute automation for human labor.
参照: https://sre.google/in-conversation/
要約すると「オペレーションをソフトウェアの問題として扱う手法」ということです。さらにわかりやすく言うと、運用の問題をソフトウェアで解決するということです。
SREは、歴史的にオペレーションチームが行ってきた作業をソフトウェアエンジニアの視点で再構築したものです。Googleでは、SREチームはシステムの可用性、遅延、性能、効率、変更管理、監視、緊急対応、容量計画などを担当します。このような役割は多くのオペレーションチームでも見られますが、SREのアプローチは大きく異なります。
7.3 Reliability(信頼性)とは?
Site Reliability Engineering (SRE) を日本語に直訳すると、サイト信頼性エンジニアリングになります。
ここで重要なのは「Reliability (信頼性)」という概念です。つまり、SREの目的はサイトの信頼性を高めることにあります。
では、信頼性を高めるとはどういうことでしょうか?
信頼性に深く関わってくる重要な要素の一つが「可用性」です。
可用性とは、システムが利用可能な状態であり、継続的に稼働できることを指します。
サービスが利用できることによって売上が上がり、利益につながります。逆に、サービスが利用できない状態では、売上が上がらず、利益が減少したり、失われたりします。
可用性は信頼性に対して大きな影響を与えるため、非常に重要な要素といえます。
7.4 よくある誤解:SRE=職種?
ここで、よくある誤解や分かりにくい部分について触れておきたいと思います。
求人情報などでSREという職種を目にすることが多いと思います。
そのため、「SRE=職種(ポジション)」という誤解が生まれ、SRE以外の人はSREに関わる業務をする必要がないと思ってしまうことがあります。実際、私自身も以前はそのように勘違いしていました。
しかし、実際にはSREとして募集されているポジションは、SRE(インフラ)のような表記がされていることが多く、業務内容としてサイトの信頼性向上を中心に行うことは確かですが、だからといって他のポジションの人がSREに関わる必要がないというわけではありません。
SREはロールであり、技術であり、概念でもあります。そのため、開発者も、管理者も、SREを理解し、実践することが重要です。なぜなら、可用性が担保されて初めて、ユーザーはサービスを利用できるようになるからです。
8.SREを実践する上で必要な知識
SREを実践するためには、さまざまな知識が必要です。
ここでは、以下の項目について解説します。
- 可用性
- 信頼性
- SLI/SLO/SLA
- エラーバジェット(エラー予算)
- ポストモーテム
- トイル
8.1 可用性
可用性とは、「システムが継続して稼働できる度合いや能力」を指します。
具体的な数値として、以下の表は可用性レベルと年間の最大利用不可能時間の関係を示しています。
| 可用性 | 最大利用不可能時間 (年間) | アプリケーションのカテゴリ |
|---|---|---|
| 99% | 3 日と 15 時間 | バッチ処理、データの抽出、転送、ロードのジョブ |
| 99.9% | 8 時間 45 分 | ナレッジ管理、プロジェクト追跡などの社内ツール |
| 99.95% | 4 時間 22 分 | オンラインコマース、POS |
| 99.99% | 52 分間 | 動画配信、ブロードキャストのワークロード |
| 99.999% | 5 分間 | ATM トランザクション、通信のワークロード |
参照:https://docs.aws.amazon.com/ja_jp/wellarchitected/latest/reliability-pillar/availability.html
99%の可用性は十分に思えるかもしれませんが、年間の利用不可能時間は3日と15時間にもなります。一方、99.999%(ファイブナイン)の可用性では、年間の利用不可能時間はわずか5分です。
ただし、可用性は高ければ高いほど良いというわけではありません。サービスの目的、影響度、ユーザーの期待を考慮し、適切な可用性レベルを選定することが重要です。
全てのサービスに同じレベルの可用性を適用する必要はありません。
例えば、クリティカルな金融システムでは99.99%の可用性が求められるかもしれませんが、内部用の文書管理システムでは99.9%で十分な場合もあります。
また、高い可用性を実現するためには、より多くのインフラ投資と継続的な保守が必要になります。
例えば、99.9%から99.99%への向上には、大幅なインフラ投資、より高度な冗長性の設計、継続的な保守管理が求められます。そのため、可用性向上のコストがそのサービスから得られる利益を超えないように、費用対効果を考慮して、サービスごとに最適な可用性レベルを定めることが重要です。
補足:AWS のサービスの可用性設計
AWS では、各サービスごとに可用性の設計目標が設定されています。ただし、これらの値はサービスレベルアグリーメント (SLA) や保証を表すものではなく、あくまでも設計上の目標値であることに注意が必要です。
一部のサービス、例えば Amazon CloudFront、Amazon Route 53、AWS Global Accelerator、AWS Identity and Access Management のコントロールプレーンは、グローバルなサービスを展開しており、これに基づいてコンポーネントの可用性の設計目標が示されます。
一方、多くのサービスは AWS リージョン内で提供され、それに応じて可用性の目標が定められています。さらに、単一のアベイラビリティーゾーン内で運用されるサービスと、複数のアベイラビリティーゾーンにまたがって運用されるサービスでは、可用性の設計目標が異なる場合があります。
AWS では、サービスごとに可用性の設計目標を定め、それぞれのサービスの特性に合わせた可用性設計を行っていますが、このリストはすべてのサービスを網羅しているわけではなく、今後も新しいサービスの追加に伴い、定期的に更新される予定です。
'
| | データプレーン | 99.950% |
| Amazon CloudWatch | CW メトリクス (サービス) | 99.990% |
| | CW イベント (サービス) | 99.990% |
| | CW Logs (サービス) | 99.950% |
| Amazon DynamoDB | サービス (標準) | 99.990% |
| | サービス (グローバルテーブル) | 99.999% |
| Amazon Elastic Block Store | コントロールプレーン | 99.950% |
| | データプレーン (ボリュームアベイラビリティー) | 99.999% |
| Amazon Elastic Compute Cloud (Amazon EC2) | コントロールプレーン | 99.950% |
| | シングル AZ データプレーン | 99.950% |
| | マルチ AZ データプレーン | 99.990% |
| Amazon Elastic Container Service (Amazon ECS) | コントロールプレーン | 99.900% |
| | EC2 Container Registry | 99.990% |
| | EC2 Container Service | 99.990% |
| Amazon Elastic File System | コントロールプレーン | 99.950% |
| | データプレーン | 99.990% |
| Amazon ElastiCache | サービス | 99.990% |
| Amazon EMR | コントロールプレーン | 99.950% |
| Amazon Data Firehose | サービス | 99.900% |
| Amazon Kinesis Data Streams | サービス | 99.990% |
| Amazon Kinesis Video Streams | サービス | 99.900% |
| Amazon Managed Streaming for Apache Kafka (Amazon MSK) | コントロールプレーン | 99.950% |
| | 3 AZ データプレーン | 99.990% |
| | 2 AZ データプレーン | 99.950% |
| Amazon MQ | データプレーン | 99.950% |
| | コントロールプレーン | 99.950% |
| Amazon Neptune | サービス | 99.900% |
| Amazon OpenSearch Service | コントロールプレーン | 99.950% |
| | データプレーン | 99.950% |
| Amazon Redshift | コントロールプレーン | 99.950% |
| | データプレーン | 99.950% |
| Amazon Rekognition | サービス | 99.980% |
| Amazon Relational Database Service (Amazon RDS) | コントロールプレーン | 99.950% |
| | シングル AZ データプレーン | 99.950% |
| | マルチ AZ データプレーン | 99.990% |
| Amazon Route 53 | コントロールプレーン | 99.950% |
| | データプレーン (クエリ解決) | 100.000% |
| Amazon SageMaker | データプレーン (モデルホスト) | 99.990% |
| | コントロールプレーン | 99.950% |
| Amazon Simple Notification Service (Amazon SNS) | データプレーン | 99.990% |
| | コントロールプレーン | 99.900% |
| Amazon Simple Queue Service (Amazon SQS) | データプレーン | 99.980% |
| | コントロールプレーン | 99.900% |
| Amazon Simple Storage Service (Amazon S3) | サービス (標準) | 99.990% |
| AWS Auto Scaling | コントロールプレーン | 99.900% |
| | データプレーン | 99.990% |
| AWS Batch | コントロールプレーン | 99.900% |
| | データプレーン | 99.950% |
| AWS CloudFormation | サービス | 99.950% |
| AWS CloudHSM | コントロールプレーン | 99.900% |
| | シングル AZ データプレーン | 99.900% |
| | マルチ AZ データプレーン | 99.990% |
| AWS CloudTrail | コントロールプレーン (config) | 99.900% |
| | データプレーン (データイベント) | 99.990% |
| | データプレーン (管理イベント) | 99.999% |
| AWS Config | サービス | 99.950% |
| AWS Data Pipeline | サービス | 99.990% |
| AWS Database Migration Service (AWS DMS) | コントロールプレーン | 99.900% |
| | データプレーン | 99.950% |
| AWS Direct Connect | コントロールプレーン | 99.900% |
| | 単一ロケーションデータプレーン | 99.900% |
| | マルチロケーションデータプレーン | 99.990% |
| AWS Global Accelerator | コントロールプレーン | 99.900% |
| | 単一ネットワークゾーンデータプレーン | 99.950% |
| | 2 ネットワークゾーンデータプレーン | 99.995% |
| AWS Glue | サービス | 99.990% |
| AWS Identity and Access Management | コントロールプレーン | 99.900% |
| | データプレーン (認証) | 99.995% |
| AWS IAM Identity Center | コントロールプレーン | 99.900% |
| | データプレーン (サインインを含む) | 99.950% |
| AWS IoT Core | サービス | 99.900% |
| AWS IoT Device Management | サービス | 99.900% |
| AWS IoT Greengrass | サービス | 99.900% |
| AWS Key Management Service (AWS KMS) | コントロールプレーン | 99.990% |
| | データプレーン | 99.995% |
| AWS Lambda | 関数の呼び出し | 99.990% |
| AWS Secrets Manager | サービス | 99.990% |
| AWS Shield | コントロールプレーン | 99.500% |
| | データプレーン (検出) | 99.000% |
| | データプレーン (軽減) | 99.900% |
| AWS Storage Gateway | コントロールプレーン | 99.950% |
| | データプレーン | 99.950% |
| AWS X-Ray | コントロールプレーン (コンソール) | 99.900% |
| | データプレーン | 99.950% |
| Elastic Load Balancing | コントロ
8.2 信頼性
信頼性と可用性は密接に関連していますが、システムにおいて最も重要な要素は信頼性です。
信頼性とは、システムがユーザーの期待通りに動作し、継続的に利用可能であることを指します。つまり、ユーザーがシステムを使える状態を維持することが大切なのです。信頼性は、監視などの指標だけで決まるものではなく、ユーザーの満足度によって評価されます。
例えば、CPU使用率が100%であっても、サービスが問題なく利用できれば、ユーザーは満足するでしょう。逆に、CPU使用率に余裕があっても、サービスが利用できなければ、ユーザーは不満を抱くことになります。
したがって、ログや監視などの実績値に問題がなくても、ユーザーが不満を感じているようであれば、それは信頼性に欠けていると言えます。
ユーザーの信頼性を測定する方法には、以下のようなものがあります:
-
ユーザーフィードバックの収集と分析:ユーザーからの直接的なフィードバックを収集し、満足度や不満点を把握します。アンケートやインタビューなどの手法が有効です。
-
ユーザー行動の分析:ユーザーがシステムをどのように利用しているかを分析します。利用頻度の変化や、特定の機能の利用率などから、ユーザーの満足度を推測できます。
-
エラー率やパフォーマンス指標の監視:エラー率が高かったり、レスポンス時間が長かったりする場合、ユーザーの満足度が低下する可能性があります。これらの指標を監視し、問題があれば速やかに対処することが重要です。
-
サポート問い合わせの分析:ユーザーからのサポート問い合わせの内容や件数を分析することで、システムの問題点や改善点を見つけることができます。
これらの方法を組み合わせることで、ユーザーの信頼性を総合的に評価し、システムの改善につなげることができます。信頼性の向上には、可用性はもちろんのことユーザーの視点に立ち、継続的にシステムを改善していく姿勢が不可欠です。
8.3 SLI/SLO/SLA
-
SLI (Service Level Indicators):サービスレベル指標
- SLIは、ユーザーが利用するサービスのパフォーマンスを測定するための指標です。
- これらの指標は、ユーザーが許容できる範囲内でサービスが完了するまでの時間や、サービスの可用性などを示します。
例えば、DSP(デマンドサイドプラットフォーム)がSSP(サプライサイドプラットフォーム)から入札リクエストを受け取ってから、広告の入札単価を提示するまでの時間がSLIの一例です。
多くの場合、SSPは0.1秒以内にレスポンスが返ってこないDSPをそのリクエストから除外します。
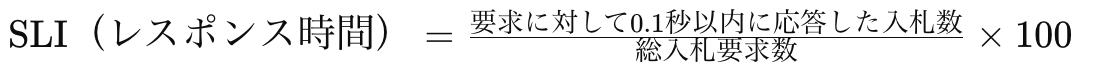
-
SLO (Service Level Objectives):サービスレベル目標
- SLOは、SLIで設定した値以内でサービスを提供できる割合の目標値です。
- つまり、全てのサービス提供回数のうち、どの程度の割合でSLIを満たせばよいかを定義します。
- 例えば、「DSPが受けた入札リクエストの少なくとも99%に対して、0.1秒以内に応答する」というSLOを設定できます。
- この場合、SLO(レスポンス時間)= 99% となります。
-
SLA (Service Level Agreement):サービスレベル契約
- SLAは、サービスプロバイダーがユーザーに対して提供するサービスレベルの保証を定めた契約です。
- SLOが達成できなかった場合、サービスプロバイダーはユーザーに対して何らかの補償を行うことを約束します。
- これにより、ユーザーはサービスの品質について一定の保証を得ることができます。
SLI、SLO、SLAを決める順番は、以下の通りです:
- SLI(サービスレベル指標)を定義する
- SLO(サービスレベル目標)を設定する
- SLA(サービスレベル契約)を締結する
まず、サービスのパフォーマンスを測定するための指標(SLI)を定義し、次にその指標に基づいて目標値(SLO)を設定します。最後に、SLOが達成できない場合の補償内容を含むサービスレベル契約(SLA)を締結します。
これらの指標や目標値は、サービスの種類や要件に応じて適切に設定する必要があります。また、定期的に見直しを行い、必要に応じて調整することが重要です。
8.4 エラーバジェット
エラーバジェット(エラー予算)は、サービスのダウンタイムやエラーの許容範囲を定量的に表す重要な指標です。具体的には、エラーバジェットはサービスのSLO(Service Level Objectives、サービスレベル目標)を基にして定義されます。SLOを超えるサービスの不具合が「許容範囲」内であるかどうかを測定し、システムの信頼性を評価します。
エラーバジェットの定義と計算方法
エラーバジェットの計算は以下の式で表されます:
SLO - SLI = エラーバジェット
SLO(Service Level Objectives):サービスの性能や可用性に関する具体的な目標値です。例えば、サービスのアップタイムが99.9%であることを目標とする場合、この99.9%がSLOとなります。
SLI(Service Level Indicators):実際のサービスの性能や可用性を示す指標です。例えば、実際のアップタイムが99.8%である場合、この99.8%がSLIとなります。
この場合、エラーバジェットは0.1%(99.9% - 99.8%)となります。
エラーバジェットが「余っている」場合
エラーバジェットが余っている場合、すなわちSLOを超える不具合が少なく、サービスの安定性が高い場合には、以下のような活動を行うことが推奨されます:
- 新機能のリリース:余裕があるときに新しい機能を追加することで、ユーザー体験の向上を図ります。
- 実験:新しい技術や手法を試すための実験を行い、サービスの改善に繋げます。
- 課題解決:サービスのボトルネックやユーザーからのフィードバックに基づく課題を解決し、全体的な品質を向上させます。
エラーバジェットが「なくなった」場合
一方で、エラーバジェットがなくなった場合、すなわちSLOを超える不具合が多発し、サービスの信頼性が低下している場合には、以下のような対策を講じる必要があります:
- 新機能のリリースを控える:新しい変更を加えることでさらに不具合が発生するリスクを避け、サービスの安定性を最優先にします。
- システムの安定性の向上:既存のシステムの問題を解決し、サービスの信頼性と可用性を改善します。
- 信頼性の確保:エラーバジェットの枠内でサービスを運用し続けることで、ユーザーの信頼を回復し、満足度を向上させます。
エラーバジェットは、システムの信頼性を管理し、適切なバランスで新機能の追加とシステムの安定性を保つための重要なツールです。サービスの運用において、エラーバジェットを効果的に活用することで、ユーザーの期待に応え続けることが可能になります。
8.5 ポストモーテム
ポストモーテムは、システム障害やインシデント発生後に行われる重要な分析プロセスです。このプロセスを通じて、何が起こったのか、なぜ起こったのかを理解し、将来同様の問題を防ぐための改善策を特定します。
ポストモーテムは問題を解決するためのものではなく、問題から学び、組織のプロセスやシステムを改善するための機会です。
以下では、ポストモーテムの具体的なステップと具体例について詳しく説明します。'
「ポストモーテムのステップ」
1.インシデントの記録
- 発生した問題の詳細な記録を作成します。何が起こったか、いつ起こったか、どのようにして発見されたかなどを記録し、正確なデータを収集します。
- 影響の評価
- インシデントがビジネスやエンドユーザーに与えた影響を評価します。これには、売上損失、ユーザー満足度の低下、ブランドへの悪影響などが含まれます。
- 根本原因の分析
- インシデントの根本原因を特定します。これは、単一の原因に限らず、複数の要因が組み合わさって発生することもあります。
- 解決策と改善策の議論
- 問題を解決するために取られた短期的な措置と、将来同様のインシデントを防ぐための長期的な改善策を議論します。
- 報告書の作成
- 分析の結果と推奨される改善策を文書化し、関係者に共有します。この報告書は、組織全体での学びを促進するための重要なドキュメントです。
- フォローアップ
- 推奨された改善策が実施されているかを追跡し、必要に応じて追加のアクションを取ります。継続的な改善を行うための重要なステップです。
注意事項
- 定期的なレビュー: ポストモーテムの結果は定期的にレビューし、継続的な改善を図ります。
- ミスをした人の追求をしない: 問題の根本原因を追求し、個人のミスを責めない文化を醸成します。
ポストモーテムの具体的な形式
ポストモーテムを残す際には、以下のような形式を使用することが推奨されます:
| 項目 | 内容 |
|---|---|
| タイトル | インシデントの名称 |
| 日付と時間 | 発生日時と解決日時 |
| 概要 | インシデントの簡潔な説明 |
| 影響 | ビジネスおよびユーザーへの影響 |
| タイムライン | インシデント発生から解決までの詳細なタイムライン |
| 原因 | 根本原因とその説明 |
| 対策 | 取られた短期的な措置と長期的な改善策 |
| 教訓 | 学んだことと将来の改善点 |
| フォローアップ | 推奨されるフォローアップアクションとそのステータス |
詳細: 各レコードの詳細
タイムラインの具体例
| 時刻 | 出来事の詳細 |
|---|---|
| 発生日時 | インシデント発生 |
| 発見時刻 | インシデント発見 |
| 初期対応 | 初期対応内容 |
| 解決時刻 | インシデント解決 |
| 完了時刻 | フォローアップ完了 |
原因の具体例
| 根本原因 | 説明 |
|---|---|
| サーバー過負荷 | 特定プロモーションによる想定以上のトラフィックが原因 |
対策の具体例
| 対策の種類 | 措置内容 |
|---|---|
| 短期的な措置 | 追加サーバーリソースの確保 |
| 長期的な改善策 | トラフィック予測モデルの見直しと自動スケーリング機能の導入 |
教訓の具体例
| 学んだこと | 将来の改善点 |
|---|---|
| トラフィック予測の重要性 | 定期的な予測モデルの見直しとシステムの強化 |
フォローアップアクションの具体例
| アクション | ステータス |
|---|---|
| トラフィック予測モデルの改善 | 実施中 |
| 自動スケーリング機能の導入 | 検討中 |
重要な点は、ポストモーテムが問題の責任を追及するためではなく、学びと改善の機会であることを強調することです。ポストモーテムを定期的に実施し、組織全体で共有することで、システムの信頼性を向上させ、ユーザーの満足度を高めることができます。
8.6 トイル
トイルとは、手動で反復的かつ自動化可能な、価値を生み出さない作業のことです。トイルはチームの効率性を低下させ、技術的な成長や新しいプロジェクトへの障害になるため、できるだけ減らすべきものです。
トイルの特徴
- 反復的: 同じ作業を何度も繰り返す必要がある
- 手動: 自動化されていないため、人の手による介入が必要
- スケーラブルでない: システムが成長するにつれて、トイルの量は比例して増加する
- 戦術的: 短期的な問題解決にはなるが、長期的な価値はほとんどまたは全くない
- 自動化可能: 作業の性質上、プロセスを自動化することでトイルを減らすことが可能
具体例
システム監視とアラート処理
-
状況: ITチームがサーバーの健康状態やアプリケーションのパフォーマンスを監視するために、定期的にシステムログを手動でチェックしています。アラートが発生するたびに、エンジニアは手動でログを分析し、問題を特定して対応策を講じます。
-
トイルの要素: このプロセスは反復的であり、成長するシステムに対応して作業量が増加し、自動化によって解決可能なタスクです。
-
改善策: モニタリングツールを導入してログを自動で監視し、異常を検出した場合には自動でアラートを生成します。さらに、一般的な問題に対する自動応答システムを開発して、手動介入を減らすことができます。
トイルは、組織やチームの成長を妨げる要因となるため、可能な限り自動化し、削減することが重要です。自動化ツールやシステムを導入することで、トイルを効果的に減らし、チームの生産性と技術的成長を促進することができます。継続的な改善と効率化を図り、より高度な技術やプロジェクトに注力できる環境を整えることが、成功への鍵となります。
8.5 SREとしての代表的な職務内容
SREの職務は多岐にわたり、システムの信頼性と性能を維持・向上させるために必要なさまざまなタスクを含みます。
以下では、SREとしての代表的な職務内容について詳しく説明します。
システムの信頼性と性能の監視
- システムの健全性の確認: システムの状態を定期的にチェックし、異常や問題が発生していないかを確認します。これにより、潜在的な問題を早期に発見し、対策を講じることができます。
- KPIの定義と監視: 重要な業績指標(KPI)を定義し、これらの指標を継続的に監視します。KPIは、システムのパフォーマンスや信頼性を測るための重要な指標です。
- パフォーマンスボトルネックの特定: システムのパフォーマンスを分析し、ボトルネックとなっている部分を特定します。これにより、パフォーマンスの改善策を講じることができます。
障害発生時の迅速な対応
- ダウンタイムを最小限にし、ユーザー影響を低減する: 障害が発生した際には、迅速に対応してシステムを復旧させ、ユーザーへの影響を最小限に抑えます。
- 障害のアラート対応: 自動化されたアラートシステムを用いて、障害発生時に即座に対応します。その後、ポストモーテム分析を行い、再発防止策を講じます。
サービスレベル目標(SLO)、サービスレベル指標(SLI)の定義と監視
- サービスの期待される品質の明確化: サービスに対するユーザーの期待を明確にし、それに基づいて品質目標を設定します。
- SLIを定義し、顧客約束を明確にする: サービスレベル指標(SLI)を定義し、これに基づいて顧客との約束を明確にします。
- 監視のダッシュボードを作成し、SLOの達成率を調整する: SLIに基づいて監視ダッシュボードを作成し、サービスレベル目標(SLO)の達成状況を継続的に監視し、必要に応じて調整します。
自動化の推進
- 手動のエラーを削減: 自動化することで、人為的なエラーを減らし、作業の精度を向上させます。
- 運用効率を向上させる: 自動化されたプロセスにより、作業の迅速化と効率化を図ります。これにより、SREはより高度なタスクに集中できるようになります。
SREの役割は、システムの信頼性と性能を維持し、障害発生時に迅速に対応し、サービスレベルを保証することです。これらのタスクを効果的に実行するためには、継続的な監視、自動化の推進、ポストモーテム分析による再発防止策の実施が不可欠です。
SREとしての知識とスキルを駆使し、システムの健全性を維持することが、ユーザー満足度の向上とビジネスの成功につながります。
8.6 SREを実践することでサービスの信頼性を向上
これらの取り組みにより、システムの安定性と可用性を高めます。最終的に、SREを実践することは、サービスの稼働率を向上させ、ユーザーの信頼を獲得することに繋がります。
8.7 課題点と解決策
サービスが拡大するにつれ、フロントエンド、バックエンド、SRE、QA各チーム間で新たなサイロが発生する可能性があります。一つの機能をリリースする際には、すべてのチームの共同作業が必須となります。しかし、この過程でいくつかの課題が浮上します。
- コミュニケーションコストが大きい: チーム間の連携や情報共有が増えることで、コミュニケーションにかかる時間と労力が増加します。
- リンゲルマン効果: チームが大きくなると、メンバー個々の士気やパフォーマンスが低下する傾向があります。
- 優先順位の共有不足: 各チーム間で優先順位が共有されない場合、リソースの割り当てやタスクの進行に支障をきたします。
これらの課題を解決するためには、効果的なコミュニケーション戦略や明確な優先順位の設定、チームの士気を維持するための取り組みが必要です。
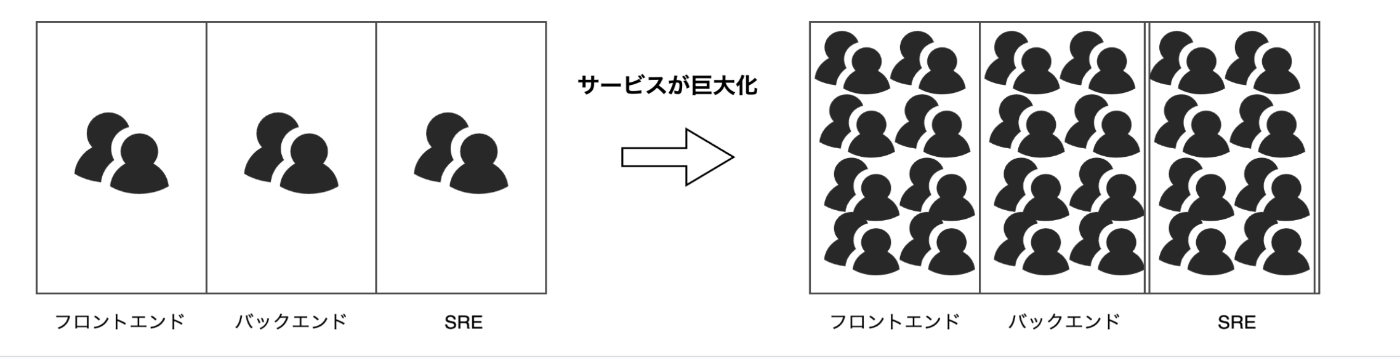
これらの課題を解決する一つの方法として、マイクロサービスアーキテクチャの採用があります。マイクロサービスアーキテクチャを採用することで、スケーラビリティと柔軟性を高め、新たなサイロの発生を防ぐことができます。
具体的には、各チームが独立してサービスを開発、デプロイ、運用できるようにすることで、チーム間の依存関係を最小限に抑えます。これにより、コミュニケーションコストの削減、リンゲルマン効果の緩和、優先順位の明確化が期待できます。
さらに、チームをクラウドネイティブ化することで、クラウドの利点を最大限に活用し、迅速なスケーリングとリソースの効率的な管理が可能になります。これにより、各チームが自律的に機能し、全体のシステムの信頼性と可用性を向上させることができます。
9. Microservices Architecture
まず代表的なアーキテクチャについて紹介させてください。今回は以下の三つについて軽く紹介させていただきます。
- モノリシックアーキテクチャ
- サービス指向アーキテクチャ(SOA)
- マイクロサービスアーキテクチャ
モノリシック
特性:
モノリシックアーキテクチャは、全ての機能が一つのコードベースに統合されたアプローチです。システム全体が一つのプロジェクトとして構築され、単一のデプロイメントユニットとして運用されます。
メリット:
- 単一のコードベースで管理が容易
- 開発の初期段階ではシンプルで効率的
- 単一の環境でのデバッグが簡単
デメリット:
- スケーリングが難しい
- デプロイが大規模になり、リリースサイクルが長くなる
- 一部の障害が全体に影響を及ぼす

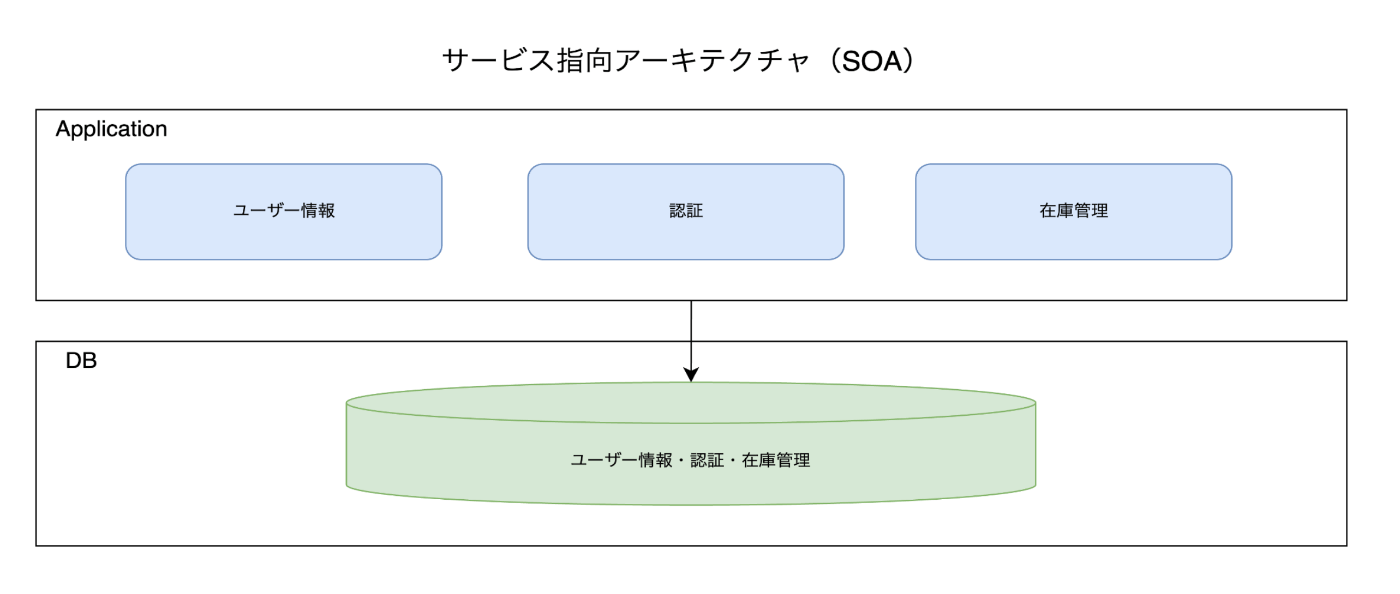
サービス指向アーキテクチャ(SOA)
特性:
SOAは、機能をサービスと呼ばれる分離されたコンポーネントに分割するアプローチです。これらのサービスは、異なる技術で構築されることがあり、標準化された通信プロトコル(例えばSOAPやREST)を介して相互作用します。
メリット:
- サービスの再利用性が高い
- 異なる技術スタックの統合が可能
- 大規模なシステムの管理が容易
デメリット:
- サービス間の通信が複雑化
- オーバーヘッドが発生する場合がある
- 適切なガバナンスが必要
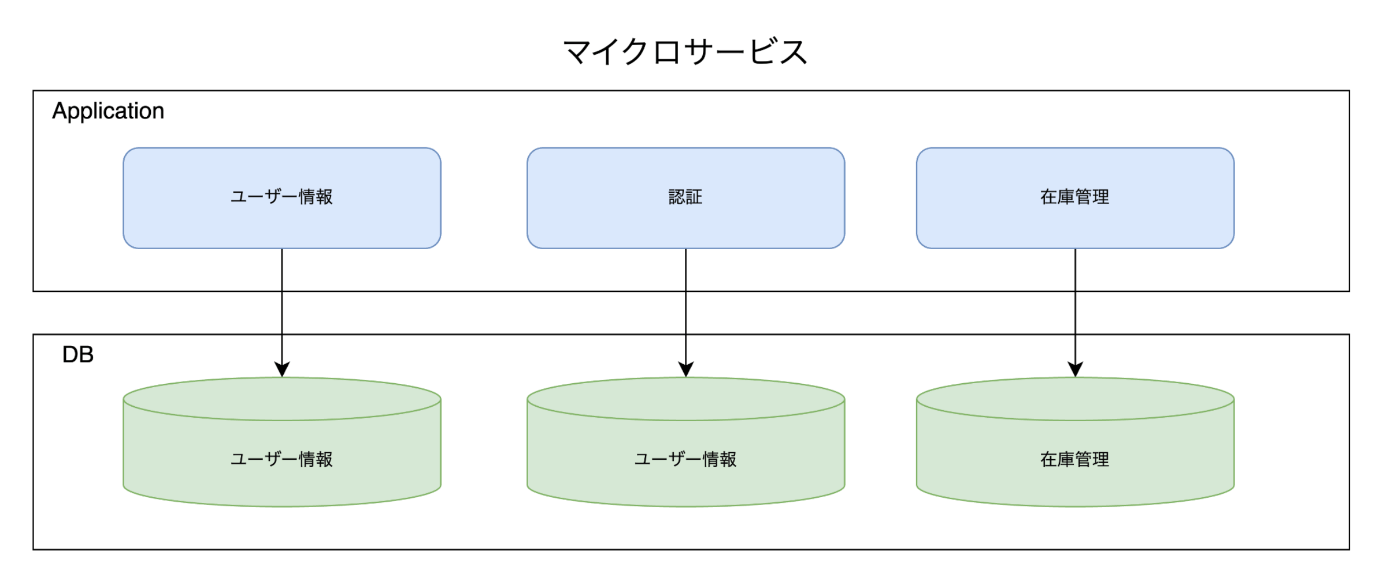
マイクロサービスアーキテクチャ
特性:
マイクロサービスアーキテクチャは、ビジネスロジックを細分化して個々のサービスとしたアプローチです。各サービスは特定のビジネス機能を担い、独立して開発・デプロイされます。サービス間は通常、軽量な通信プロトコル(例えばHTTP/REST)を介して相互作用します。
メリット:
- 各サービスは独立しており、需要が高い部分だけを個別にスケールできる
- デプロイが迅速で、障害があっても全体の稼働に影響が少なくリスクが低い
- 開発チームがサービスごとに独立して動けるため、開発スピードが向上
- 継続的デプロイメントが容易になり、アジリティが高い
デメリット:
- サービス間通信の管理が複雑
- 分散トランザクションの管理が困難
- 適切なモニタリングとロギングが必要
9.1 新たな組織の形成
しかし、ここで一番お伝えしたいのは、マイクロサービスアーキテクチャの究極的な成果物が新たな組織の形成であるということです。独立したサービスを開発・運用するためには、各サービスに対応する独立したチームが必要となります。
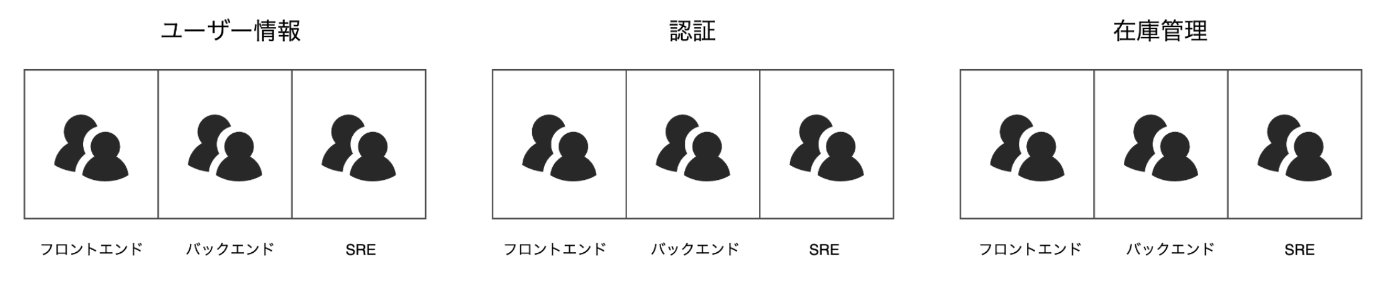
このようにして形成される組織は、各チームが自律的に機能する主体的な組織となります。
自律的な組織の特徴とは?
- 迅速な意思決定と効率的な作業:各チームが独自に機能し、迅速な意思決定が可能になります。また、効率的な作業が進みます。
- 専門分野に特化:各チームが専門分野に特化することで、技術的な深さと品質が向上します。
- 責任の明確化:チームはE2Eでサービスのライフサイクルに対する責任を持つようになり、自ら課題を見つけ解決します。
- コミュニケーションの効率化:少数構成のチームはコミュニケーションのオーバーヘッドを減らし、チーム内での情報共有がスムーズになります。
最も重要なことは、各チームが「自律性と説明責任」を持つことです。チームは自主的に機能するための権限と環境を与えられ、責任を持ってサービスの開発・運用を行います。
9.2 最適なチーム構成例
多くの企業が、自律性と説明責任を持つ組織を作るために、さまざまなルールを定義し実践しています。ここでは、いくつかの具体例を紹介します。
Amazon: "You Build It, You Run It"
- オーナーシップの強化: 自分たちで開発したマイクロサービスへのオーナーシップを強く持つことで、サービス品質が向上します。これは、ユーザー目線でもテクノロジー目線でも有益です。
- "Two pizza rule": 1つのチームは二つのピザで満足できる人数にするというルールで、具体的には6から10人程度が理想的です。
Netflix: Full Cycle Developers
- 全ライフサイクルへの関与: ソフトウェアの設計、開発、デプロイ、運用、サポートまでのすべての面に開発者が関与します。これにより、チームは一貫してプロジェクト全体を把握し、効率的に進めることができます。
- "Operate what you build": 機能を開発したチームが、その運用とサポートの責任を持つという原則です。このアプローチにより、開発者は運用上の負荷を軽減しつつ、開発上の問題、キャパシティプランニング、アラートの問題、サポートに対するオーナーシップを持つことができます。
これらの企業の取り組みから、自律的に機能する主体的な組織の形成が、いかにしてスケーラビリティと柔軟性を高めるかが理解できます。企業が変化するビジネス環境に柔軟に対応し、競争力を維持するための有効なアプローチとして、マイクロサービスアーキテクチャの導入をぜひ検討してみてください。
参照:https://engineering.mercari.com/blog/entry/2018-12-01-200159/
9.3 課題点
これで全ての課題が解決されたと言いたいところですが、もちろんいくつかの課題点や問題点も存在します。
技術的な負担の増加
マイクロサービスアーキテクチャを導入すると、チームごとの技術レベルが均一でないため、技術的な負担が増加します。さらに、各チームが独自に開発を進めるため、車輪の再発明が至る所で行われることになり、各チームの認知負荷が大きくなります。
認知負荷(Cognitive Load)
認知負荷とは、ユーザーが情報を処理し理解する際にかかる負荷のことです。人間の脳にはワーキングメモリがあり、その容量は限られています。認知負荷には以下の種類があります。
-
学習対象そのものの複雑さによる負荷
- 例:マイクロサービスアーキテクチャにおける複雑な分散合意の実装
- 解決策:この負荷は仕組みで解決するべきです。具体的には、ツールやフレームワークを利用して複雑さを抽象化し、開発者の負担を軽減します。
-
業務や学習に無関係な余分な負荷
- 例:ドキュメント不足による情報収集、手動による作業
- 解決策:この負荷も仕組みで解決するべきです。ドキュメントの充実化や自動化ツールの導入により、無駄な作業を減らします。
-
理解や学習が進行する際に発生する適切な負荷
- 例:サービスの正確な理解、ドメイン理解
- 解決策:少数チームはこの負荷に集中すべきです。適切な学習環境とサポートを提供することで、理解を深めます。
参照:https://theelearningcoach.com/learning/what-is-cognitive-load/
9.4 課題を低減するためには?
これらの問題を低減するためには、Platform Engineeringが有効です。Platform Engineeringは、開発者が効率的に仕事を進めるための共通基盤を提供し、技術的な負担を軽減します。具体的には、以下のような取り組みが含まれます。
- 自動化ツールの導入:手動作業を減らし、効率化を図る
- 統一された開発環境の提供:各チームが同じ基盤で開発を行うことで、技術レベルの差を縮める
- ドキュメントの充実化:必要な情報を迅速に取得できるようにする
これらの取り組みにより、認知負荷を低減し、マイクロサービスアーキテクチャの効果を最大限に引き出すことが可能となります。
10. Platform Engineering
Platform Engineeringは、先進的なテクノロジーを活用したプラットフォームにより、アプリケーションの迅速なデリバリとビジネス価値の創出を可能にする手法です
【参考】Gartner。
これは、開発チームの開発者体験と生産性を向上させることを目的とし、セルフサービスで利用できるプロダクトを設計・構築します
【参考】AWS。
セルフサービスとは?
セルフサービスとは、開発チームが自律的に設計・開発を行えるようになり、開発生産性の向上につながるサービスのことです。
10.1 Platform Engineeringが提供するもの
ウェブポータル
プラットフォーム機能を提供するためのポータルサイトを構築します。このポータルを通じて、開発チームは必要なツールやリソースにアクセスできます。
ゴールデンパス
ゴールデンパスとは、迅速なプロジェクト開発に役立つ巧みに統合されたコードと機能のテンプレート構成です。これには、CI/CDパイプラインのテンプレート、Terraform(IaC)のテンプレート、Kubernetes YAMLファイルなどが含まれます
【参考】Google Cloud。
これにより、開発チームにオーナーシップを委ねることができます。
アーティファクト
アーティファクトは、開発プロセスで生成される成果物やそれらを管理するためのものです。具体的には、コンテナイメージ、ライブラリ、ソースコードなどが含まれます。これらを効率的に生成、管理、配布することが目的です。
インフラストラクチャ
インフラストラクチャは、開発チームがアプリケーションを効率的に開発、デプロイ、運用するための基盤技術を提供します。具体的には、コンピューティングリソース、ストレージ、モニタリングなどが含まれます。
Platform Engineeringの導入により、開発チームは迅速かつ効率的にアプリケーションを開発・運用できるようになります。
10.2 共通基盤やパブリッククラウドとの違い
「Platform Engineering」と聞くと、共通基盤やパブリッククラウドとの違いは何だろう?という疑問が生まれるかもしれません。特徴としては似ている部分もありますが、いくつかの重要な違いがあります。
共通基盤との違い
従来のインフラ共通基盤は、利用が強制されることが多く、柔軟性に欠けることがあります。共通基盤は標準化された環境を提供する反面、開発チームが個別のニーズに対応するための自由度が制限されがちです。
パブリッククラウドとの違い
パブリッククラウドは、さまざまなケースに対応する汎用的な技術を提供しています。一方で、Platform Engineeringはプロダクトとして提供され、開発チームがプラットフォームを使用するかどうかを選択できる点が異なります。
Platform Engineeringの特徴
- 選択の自由: プラットフォームを使用するかどうかは開発チームが選択できます。これにより、必要に応じて最適なサービスを選択し、組み合わせることができます。
- 継続的な改善: ユーザー目線で価値ある機能を備えており、継続的に改善されます。これにより、開発チームは最新の技術とベストプラクティスを活用することができます。
IDP(Internal Developer Platform)
Internal Developer Platform(IDP)は、内部開発者プラットフォームの略です。IDPは、開発チームが効率的に開発を進めるための内部ツールやリソースを提供し、Platform Engineeringの一部として機能します。

これらの違いを理解することで、Platform Engineeringが開発チームにとっていかに価値のあるアプローチであるかをより深く理解することができます。共通基盤やパブリッククラウドと比較して、Platform Engineeringは柔軟性と選択の自由度が高く、開発チームが自律的に最適な開発環境を構築できる点が大きな利点です。
10.3 Platform Engineeringの限界とEmbedded SREの役割
Platform Engineeringによって全体の生産性と信頼性が向上する一方で、局所的で特殊な要件に対応するのは難しい場合があります。
Embedded SREの導入
この問題を解決するために、Embedded SREというアプローチが効果的です。Embedded SREは、一時的にプロダクトチーム内に配置され、サイロ化を防ぎつつ、プロダクト固有の課題に対応します。
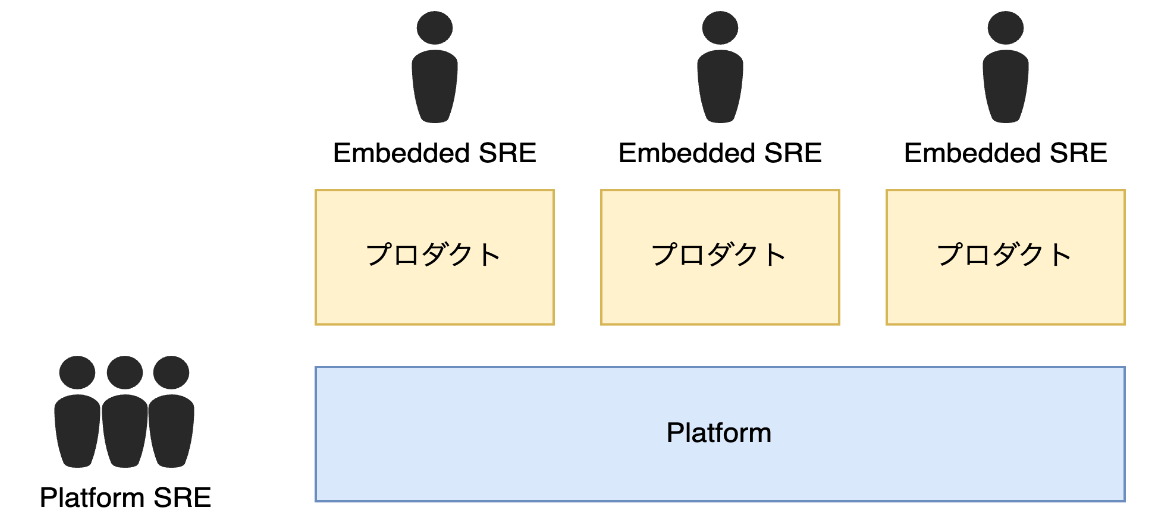
Embedded SREのメリット
- プロダクトへの深い関与: SREはプロダクトに深く関与し、特有の課題を理解して直接対応することが可能です。
- 知見の共有: 定期的なローテーションにより、異なるプロダクトチーム間でベストプラクティスや成功事例を共有し、組織全体の知見を広げます。
- フィードバックループの確立: 継続的なフィードバックループを確立し、開発と運用の間のギャップを縮小します。
参照:https://chroju.dev/blog/types_of_sre_teams
組み合わせたアプローチの効果
Platform Engineeringを活用することで、全体の80%程度の生産性や信頼性に関わる認知負荷を解消できます。しかし、残りの20%のドメインにおける局所的な問題はEmbedded SREが解決します。これにより、組織全体の効率性と信頼性がさらに向上します。
Platformというプロダクトを基盤として使用し、Embedded SREがプロダクト固有の課題に対応することで、開発チームはより効果的かつ迅速に問題を解決し、最適なソフトウェアを提供できるようになります。
11. まとめ:クラウドネイティブの歴史
クラウドネイティブ時代の運用戦略についてお話しさせていただきました。革新的な技術が次々と登場し、システムは単純なものから複雑なものへと進化してきています。その歴史や背景を理解することで、運用の応用が効き、次なる改善点を発見できるかもしれません。
DevとOpsのサイロ化 → DevOps
- 開発(Dev)と運用(Ops)の間のサイロ化を解消: DevOpsを導入することで、両者の協力と連携を強化し、よりスムーズな開発と運用を実現します。
サービスの稼働率 → SRE
- サービスの稼働率向上: Site Reliability Engineering(SRE)を活用し、サービスの信頼性と可用性を確保します。
サービス拡大につれ各チーム間でサイロ → マイクロサービス
- チーム間のサイロ化を防ぐ: サービスが拡大するにつれて、マイクロサービスアーキテクチャを採用し、柔軟性とスケーラビリティを実現します。
技術的負担、チームごとの技術レベルが揃わない、車輪の再発明 → Platform Engineering
- 技術的負担を軽減: Platform Engineeringを導入することで、技術的負担を軽減し、チームごとの技術レベルを均一に保ちます。また、共通基盤の提供と技術的サポートを強化し、開発プロセスを効率化します。
クラウドネイティブの歴史を理解し、これらの運用戦略を実践することで、より効率的で信頼性の高いシステム運用が可能となります。
5. 最後に
長々とお話ししてきましたが、結論としてお伝えしたいことは以下の通りです。
-
開発するだけがエンジニアの仕事ではない
- エンジニアは機能開発だけでなく、運用にも積極的に関与するべきです。
-
機能開発も重要だが、運用あってこそのプロダクト
- 機能開発は重要ですが、運用があって初めてプロダクトが価値を持ちます。
-
ポジション関係なく、全員で運用する
- すべてのメンバーが運用に関わり、チーム全体で責任を持つことが重要です。
-
プロダクトに対して当事者意識を持つ
- 責任感、ビジネスへの影響、コスト意識を持ってプロダクトに取り組むことが求められます。
-
モダン技術を使えば良いというわけではない
- 単に最新の技術を導入するのではなく、組織やチームのフェーズ、体制、規模に合わせた最適な運用を行うことが重要です。
これらのポイントが少しでも皆さんの役に立てば幸いです。
Discussion