フロントエンド開発でのコード分割とアーキテクチャ設計
フロントエンドエンジニアとしての経験はまだ浅い私ですが、さまざまなプロジェクトを経験し、常に新しい技術やアーキテクチャに挑戦してきました。
そして、その経験を通して、コードの分割とアーキテクチャの設計が、可読性、保守性、拡張性を向上させるためにどれほど重要なものかを実感してきました。
それらの経験を共有するため、今回はChatGPTと共同で、私の考えを言語化し
私がフロントエンド開発におけるコードの分割とアーキテクチャの設計について学んだ経験を共有したいと思います。
それでは、なぜコードの分割が重要なのか、分ける必要があるのか、そしてどのようにして分割すればいいのかについて詳しく見ていきましょう。
そもそも、なぜコードを分割するのか?
ソフトウェアエンジニアリングの世界では、コードの分割は重要な概念であり、それはさまざまな理由から推奨されています。
コードを適切に分割することには、多くのメリットがあります。以下にそのいくつかをご紹介します。
-
可読性の向上
コードが適切に分割されていると、各部分の役割や責任が明確になります。これにより、コードの全体像を把握しやすくなります。また、関連するコードが一つの場所にまとまっているため、特定の機能や概念を探すのが容易になります。 -
保守性の向上
分割されたコードは、変更や修正が必要な場合に特定の部分だけを修正できます。それにより、関連しないコードに影響を及ぼすリスクを最小限に抑えることができます。また、各部分が独立しているため、修正や機能追加が容易になります。 -
再利用性の向上
コードを適切に分割することで、特定の機能や処理を別のプロジェクトや場所で再利用できます。独立したコンポーネントやユーティリティ関数として分割されたコードは、他のプロジェクトでの開発効率を高めるのに役立ちます。 -
テスト容易性の向上
小さな単位に分割されたコードは、単体テストやユニットテストを容易にします。各部分を個別にテストすることで、バグの早期発見や修正の容易性が高まります。また、モックやスタブを使用して依存関係を置き換えることも簡単になります。 -
チーム協力の向上
コードの分割は、複数の開発者が同時に作業する場合の競合や衝突を最小限に抑えることができます。異なる部分を担当する開発者は、独立して作業を進めることができます。それにより、チーム全体の生産性と効率が向上します。
では、どのようにコードを分割すればいいのでしょうか?
これは、あなたがどのような問題を解決しようとしているか、あなたのコードが何を達成しようとしているかに大きく依存します。
このブログでは、フロントエンド開発におけるコードの分割に焦点を当て、レイヤードアーキテクチャの原則に基づいて、コードをどのように分割し、整理することができるかを示します。
ソフトウェアのアーキテクチャを設計するとき、そのアプリケーションの成長と拡張を容易にするために、アーキテクチャの原則を適用することは重要です。
今回はフロントエンドのプロジェクトにおいて、レイヤードアーキテクチャをどのように適用するかについて説明していきます。
フロントエンドにおけるレイヤードアーキテクチャを考える
レイヤードアーキテクチャの抑えておくべきポイントは2つです。
- 依存性は、上位レベルの方針にのみ向ける
- 制御の流れと依存方向を分離し制御
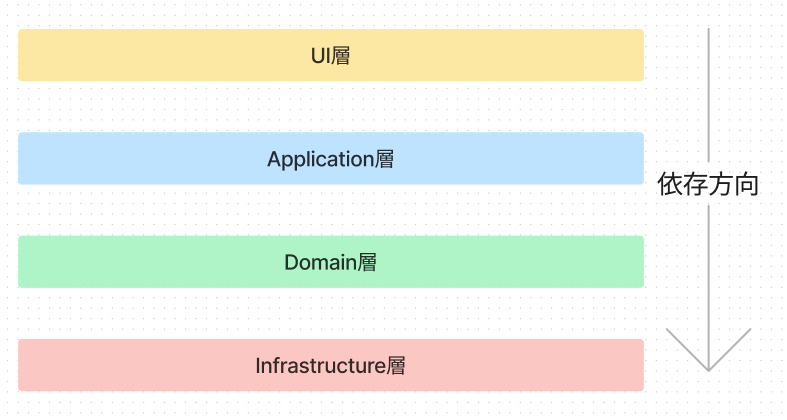
依存性の方向を理解したところで各層の説明をしていきます。
UI層
UI層は、ユーザーとの直接的なインタラクションを管理します。Next.jsでの具体的な例としては、pagesディレクトリとcomponentsディレクトリがこれに該当します。これらは表示のためのコンポーネントやページを含んでいます。
Application層
Application層は、ビジネスロジックの一部と各種ユースケースを管理します。具体的には、データの取得、変換、送信などの処理が含まれます。この層は一般的にサービスとして表現されます。
Domain層
Domain層は、ビジネスの主要なロジックとデータモデルを含みます。ドメインエンティティや値オブジェクトをこの層に配置します。
Infrastructure層
フロントエンドのコンテクストでは、Infrastructure層は外部のAPIとの通信など、技術的な詳細を管理します。APIクライアントやリポジトリがここに位置付けられます。
ディレクトリ構造とレイヤードアーキテクチャ
レイヤードアーキテクチャの基本的な原則は、特定のディレクトリ構造に縛られるものではありません。むしろ、それは依存関係の逆転の原則を遵守し、各レイヤーが明確に定義された責任と関心を持つことを推奨します。
具体的なディレクトリ構造はプロジェクトの要件やチームの好みによって異なるかもしれませんが、その基本的な原則は同じです。
実際、この記事で提案するディレクトリ構造はあくまで一例です。
主要な考え方は、各部分が明確に定義された責任を持ち、必要に応じて他の部分から独立して開発、テスト、および理解できるようにすることです。
これは、コードの再利用性とメンテナンス性を向上させるだけでなく、大規模なプロジェクトでの協業を容易にします。
依存関係の逆転の原則を遵守することで、各レイヤーは他のレイヤーに影響を受けず、また自身の変更が他のレイヤーに影響を及ぼすことなく、自己完結型で柔軟なコードを作成することが可能になります。
このような考え方と構造が、フロントエンド開発の新たな視点を提供し、より良いソフトウェアアーキテクチャを設計する手助けとなれば幸いです。
ディレクトリ構造の例
以上の各層をベースに、以下のようなディレクトリ構造を考えることができます
├── src
│ ├── components # UI層:React コンポーネントを配置
│ │ ├── Button.tsx
│ │ ├── Header.tsx
│ │ └── ...
│ ├── pages # UI層:Next.js のルーティングに基づくページコンポーネント
│ │ ├── index.tsx
│ │ ├── about.tsx
│ │ └── ...
│ ├── hooks # UI層:カスタムReact Hooks
│ │ ├── useUser.ts
│ │ └── ...
│ ├── services # Application層:ユースケースに基づくサービスやクエリを管理
│ │ ├── userService.ts
│ │ ├── orderService.ts
│ │ └── ...
│ ├── domain # Domain層:ビジネスロジックやエンティティを配置
│ │ ├── User.ts
│ │ ├── Order.ts
│ │ └── ...
│ ├── infrastructure # Infrastructure層:APIクライアント、データ永続化等のロジックを管理
│ │ ├── apiClient.ts
│ │ ├── localStorage.ts
│ │ ├── repositories # Infrastructure層:データストアへのアクセスと操作
│ │ │ ├── userRepository.ts
│ │ │ ├── orderRepository.ts
│ │ │ └── ...
│ │ └── ...
│ ├── utils # 一般的なユーティリティ関数
│ │ ├── dateUtils.ts
│ │ ├── arrayUtils.ts
│ │ └── ...
│ ├── models # データモデルや型定義
│ │ ├── user.model.ts
│ │ ├── order.model.ts
│ │ └── ...
このディレクトリ構造では、各層がそれぞれの役割に従って明確に分離されています。
React コンポーネントや Next.js のページは UI 層に属し、ユースケースに基づくサービスやクエリは Application 層に属します。
ビジネスロジックは Domain 層で扱い、API クライアントやデータストアなどの外部リソースとの接続は Infrastructure 層で扱います。
なお、この構造は一例であり、プロジェクトの要件や規模によって変わる可能性があります。また、実際のアプリケーションでは、各層間で適切にインターフェイスを定義し、依存性を最小限に抑えることが重要です。
各ディレクトリに対応するコード
以下に各ディレクトリに対応する TypeScript/Next.js の基本的なコードの一部を示します。
ただし、全てのコードを書ききることは難しいので、各層の主要な役割を示すサンプルコードとなります。
components/Button.tsx
このファイルでは、再利用可能なボタンコンポーネントを定義しています。UI層に相当し、ユーザーとのインタラクションを扱います。
import React from 'react';
interface ButtonProps {
onClick: () => void;
label: string;
}
const Button: React.FC<ButtonProps> = ({ onClick, label }) => (
<button onClick={onClick}>{label}</button>
);
export default Button;
pages/index.tsx
Next.jsのホームページコンポーネントであり、UI層に位置します。ユーザーに表示するページ全体のレイアウトと動作を定義しています。
import React from 'react';
import Button from '../components/Button';
import { useUser } from '../hooks/useUser';
const HomePage: React.FC = () => {
const { user, fetchUser } = useUser();
return (
<div>
<h1>Welcome, {user ? user.name : 'Guest'}!</h1>
<Button onClick={fetchUser} label="Fetch User" />
</div>
);
};
export default HomePage;
hooks/useUser.ts
useUserはカスタムフックで、アプリケーション層に相当します。ユーザーデータの取得とその状態の管理を行います。ビジネスロジックを含むためApplication層に位置します。
import { useState } from 'react';
import { userService } from '../services/userService';
export const useUser = () => {
const [user, setUser] = useState(null);
const fetchUser = async () => {
const user = await userService.getUser();
setUser(user);
};
return { user, fetchUser };
};
services/userService.ts
このファイルでは、ドメイン層(User)とインフラストラクチャ層(userRepository)をつなぐ役割を果たしています。ここでは依存性の逆転の原則を実装しており、ドメイン層が具体的なインフラストラクチャ層の実装に依存することなく、ユーザデータを取得できます。
import { userRepository } from '../infrastructure/repositories/userRepository';
export const userService = {
async getUser() {
const user = await userRepository.getUser();
return user;
},
};
domain/User.ts
ここで定義されているUserクラスは、ビジネスルールを表現するドメイン層の一部です。これはアプリケーションの中心的な部分で、ビジネスロジックやビジネスの要件を表現しています。
export class User {
constructor(
public id: string,
public name: string,
public email: string,
) {}
}
infrastructure/repositories/userRepository.ts
userRepositoryはインフラストラクチャ層に位置し、具体的なデータの取得方法(この場合はAPIからの取得)を定義しています。これはドメイン層から隔離され、APIの詳細を隠蔽しています。
import apiClient from '../apiClient';
import { User } from '../../domain/User';
export const userRepository = {
async getUser(): Promise<User> {
const response = await apiClient.get('/user');
return new User(response.id, response.name, response.email);
},
};
infrastructure/apiClient.ts
このファイルでは、axiosを使ってAPIクライアントを作成しています。これもインフラストラクチャ層に位置し、APIとの通信の詳細を管理します。
import axios from 'axios';
const apiClient = axios.create({
baseURL: 'https://example.com/api',
timeout: 1000,
});
export default apiClient;
utils/dateUtils.ts
utilsディレクトリもユーティリティ関数やヘルパー関数を提供しますが、ここでは日付関連の機能が定義されています。
export const formatDate = (date: Date, format: string) => {
// 日付を指定されたフォーマットで整形します。
// ここでは簡単のため、formatは無視し、年-月-日形式で返します。
return `${date.getFullYear()}-${date.getMonth() + 1}-${date.getDate()}`;
};
models/user.model.ts
モデルは、フロントエンドで扱うデータの形状を定義します。このUserModelはアプリケーション全体で使用されるユーザデータの形状を定義します。アプリケーション層とインターフェースを共有することで、コード全体で一貫性を保つことができます。
export interface UserModel {
id: string;
name: string;
email: string;
}
以上が各コードの役割とレイヤードアーキテクチャにおける位置付けになります。
これらのコードは、レイヤードアーキテクチャの原則に基づいて設計されており、依存関係の逆転の原則を尊重しています。
それぞれのレイヤーは他のレイヤーから独立していて、その役割に専念できるようになっています。
最後に
ここまで、フロントエンドエンジニアリングにおけるコードの分割とレイヤードアーキテクチャの重要性についてお話ししました。その背後にあるメリットや実装の方法について考察し、具体的なディレクトリ構造とコードサンプルを通じてレイヤードアーキテクチャを適用する方法をご紹介しました。
しかし、最も大切なのは、これらの原則やアプローチがあくまでツールであるということを忘れないことです。
これらを適用することで、コードの可読性や保守性が向上し、再利用性が高まり、テストが容易になることは確かです。
しかし、それらは全て最終的には我々が目指すゴール、すなわち「より良いソフトウェアを構築し、持続可能な開発を実現する」ことを助けるためのものです。
さらに、すべてのプロジェクトやチームが同じ形状を持つわけではないため、この記事で紹介した概念やアプローチが必ずしも全ての状況に適用可能であるとは限りません。
それらを理解し、適切に自身のプロジェクトやチームに適応させることが重要です。
今回の内容が、あなたのフロントエンド開発に役立つヒントやインスピレーションとなれば幸いです。
今回の記事を読んでくださった皆さま、ありがとうございました。
Discussion