ホテルの客室検索APIのアーキテクチャ設計時に考えたこと
作ったもののイメージ
ホテルの客室検索APIとは、チェックイン日やその他の条件を入力として受け取り、マッチするホテルの客室を返すものです。以下の画像はExpediaのものですが、赤枠で囲っている部分(他にもたくさんある)が入力になります。2022年4月頃に無事リリースされました。
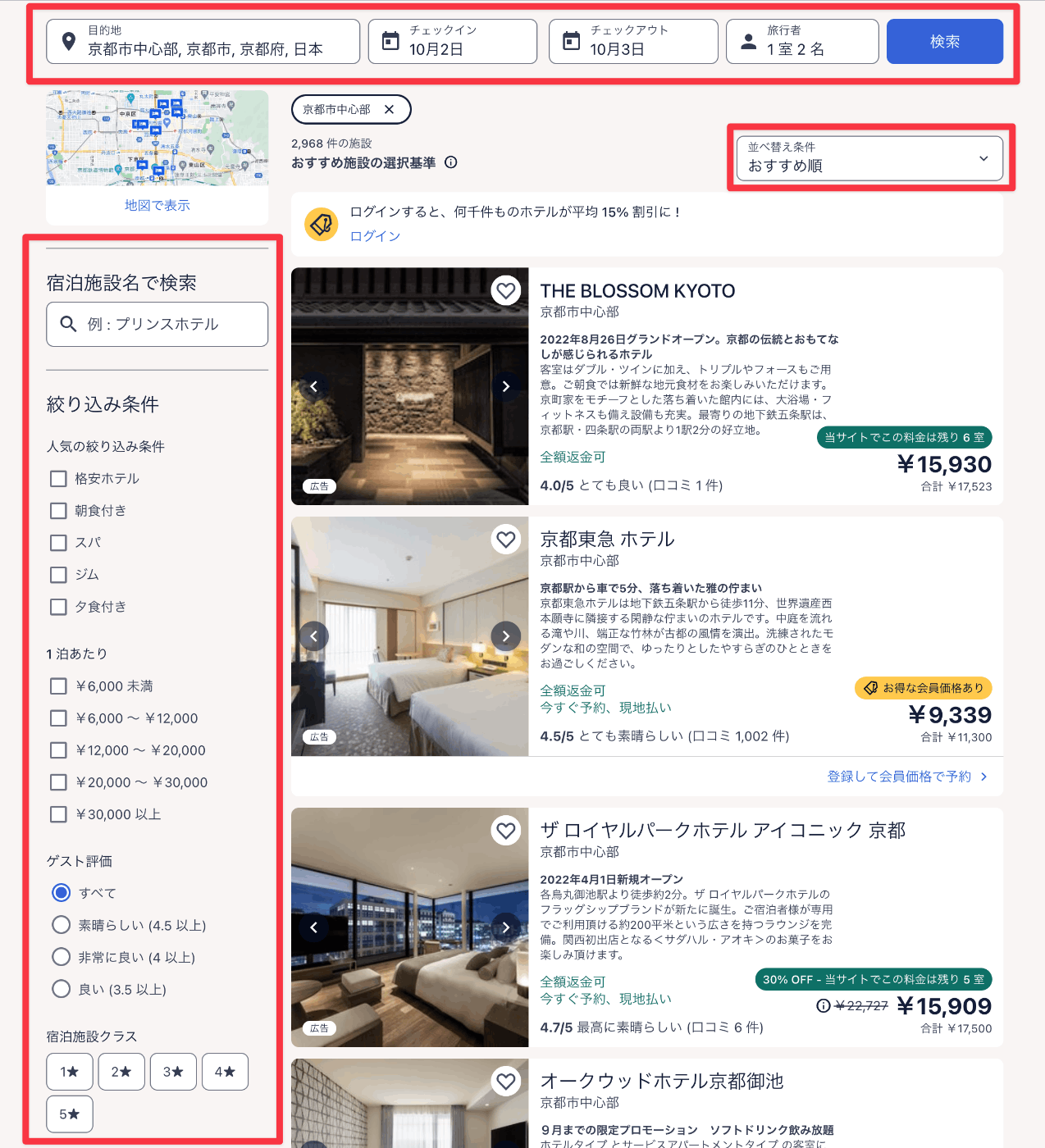
この検索APIを構築を任された際に、何を考えて設計していったのかを以下に示していきます。
顧客からの要望
顧客の会社は当時エンジニアがおらず(やりとりしている社長は元エンジニアだが)、これまでも私と仕事をしたことがあったので依頼が来ました。顧客と密にコミュニケーションを取りわかったのは、以下のような要望でした。
- このAPIは自社サービスとして第3者(要契約)に使ってもらえるようにしたい
- 完全に一般公開ではなくちゃんと契約を結ばないと利用できないようなもの
- 検索条件を柔軟に、かつ使いやすい感じで指定できるようにしたい
- ホテル名や地名を入力されたときのサジェストを表示できるようにしたい
- サーバー費・人件費を含め運用時のコストはできれば低いほうが利益率があがるので嬉しい
- APIレスポンスはそれなりに速くしたい
某旅行サービスAPIのドキュメントを見ていると、柔軟に検索できるようなものではなかったので「ホテル情報・客室情報・料金・地名など必要な情報は、某旅行サービスのAPIから取得できるデータをマスターデータとして良いということが某旅行サービスとも話がついている」とのことでした。ここまでの情報では、おそらく以下のような構成要素が必要そうです。
- 検索データを保持するデータストア
- クライアントが叩くAPIサーバー
- 某旅行サービスAPIからデータを取ってきてデータストアに貯めるバッチ処理サーバー
- APIサーバーと兼用も可
- バッチ処理が1番大変そうな予感
検索APIを構築するので、やはり1つ目の検索データを保持するデータストアを何にするかというのが肝になりそうです。顧客の要望を満たせるように技術選定をしていきました。
検索データを保持するデータストア
運用の人的コストを下げるためにはフルマネージドがよく、候補として上がってきたのは以下の2つです。
- Elasticsearch
- Algolia
その他にも選択肢はあるかと思いますが、公式のサポートが受けられたり、ある程度世の中に知見が溜まっているものがよかったのでこの2つになりました(オススメがあればコメントください)。
Elasticsearchは、設定が柔軟に行なえ、コストもインスタンスの時間課金というわかりやすさがあります。また、広く使われておりわりと枯れている印象でした。一方、設定が複雑で、使いこなすには一定の学習コストが必要です。
Algoliaは、シンプルでわかりやすく高速に動作し、ブラウザからでも使えるのがサジェスト機能に合っていそうでした。一方、ソートしたいフィールドのDirection(ASC/DESC)ごとにインデックスが必要で、それは実質レコードをコピーする扱いになり、保存しているレコード数&検索操作数課金で利用料が高くつきそうでした。
検索データとして保存するものは大きく分けて2つで、ホテルと地名(場所)です。ホテルだけでも約60万件あり、検索条件も多岐にわたるためインデックス数も膨大なため、Algoliaの場合だと軽く試算しただけでも利用料が月200万円くらいになります。
Elasticsearchはストレージサイズはインスタンスタイプに寄るのですが、前述の2つのデータをすべて保存しても2〜30GBというところなのでわりと余裕がありそうでした。サポートを受けるためにElastic Cloudを使う想定で、こちらの料金シミュレーターで試算したところ、負荷のかかり具合にもよりますが月10万以下で利用できそうでした。
今後エンジニアを増やす事を考えても、できれば学習容易なものを使いたかったのですが、サービスのコアとして機能が提供できることを担保しつつ運用費を下げるという点で、Elasticsearchを採用することにしました。
(結果的に、ElasticsearchをElastic Cloudで運用している現在、運用費は本番だけで4〜5万というところに収まっています。)
インフラをおくクラウド
これは顧客の要望(と私の技術スキル)からGCPになりました。
APIサーバー
通信部分
私の中に「APIサーバーとの通信は、スキーマから自動生成されたコードを使って行うほうがよい」という考えがあります。よって通信部分は以下のどれかを利用したいと考えました(他にもあったら教えて下さい)。
- GraphQL
- gRPC
- OpenAPI
このAPIを利用する人が簡単に使えるのがまず第1であったので、RESTful APIをOpenAPI Specificationで定義することにしました。
GraphQLやgRPCや通信容量が減り、レスポンスが早くなることが期待できましたが、まず初手として提供するのは前述の理由からOpenAPIにしました。エンドポイントを増やせばGraphQLやgRPCも提供できるためです(スキーマの同期が難しそうではありますが)。また、SDKを提供して通信処理は完全に隠蔽するという手段も考えられましたが、メジャーどころの言語のSDKを提供するには人的リソースが圧倒的に足りず、運用コストもかなりのものになると予想できたので、採用しませんでした。
プログラミング言語
今サーバーサイドを1から作るならGoという印象が私の中にはありました。ですが、顧客の会社のエンジニア採用は当時、サーバーサイドだけできる人をとるというよりもわりと何でもやれる人をとろうとされていました。Webサービスの開発案件もやられていたし、ここはTypeScriptで実装することにしました。
この判断が顧客にとって良かったのかは執筆時点でもまだわかりません。某旅行サービスAPIもOpenAPI Specでスキーマを提供してくれているのですが、実際に返ってくるレスポンスと定義が違うことがわりとあり、そういうときでも型情報を柔軟にパズルしてなおせたので開発の観点で、個人的にはわりとよかったかなと思っています。
インフラ
コンテナベースで動かしたかったので、GCPならばCloud RunかGKEになると思います。Cloud Runの場合、運用が楽で料金も安く済みます。しかし、バッチ処理はタイムアウトを気にした構成が必要になり、バッチ処理を増やしたい時に用意する必要があるものが増えます(詳しくは後述します)。
GKEの場合、バッチ処理はCronJobのyamlを用意するだけで済み、タイムアウト等の制限もないので非常に楽です(もちろんその分バッチ処理のプログラムのエラーハンドリング等を工夫する必要はあります)。一方、人的・サーバー費の運用コストは高くついてきますし、Kubernetesは理解して使えば素晴らしい技術ですがどうしても学習コストも高くなります。バージョンアップ作業もなかなか大変だという話も聞きます(私は自分がメインでKubernetesを運用したことはないのでわからない)。
以上のことを踏まえ、Cloud Runを選択しました。APIサーバーを提供する分にはCloud Runで十分で、バッチ処理を考えると他のサービス(SchedulerやTasksなど)を組み合わせて利用する必要はあるものの、一度ベースをTerraformで作ってしまえば横展開は簡単なのでそこまで問題にはならないと判断しました。もし、Runで限界を感じた場合はGKEに移行するつもりでいます。
バッチ処理
バッチ処理は最低でも以下の2種類が必要なことがわかっていました。
- ホテルの客室料金を取得しElasticsearchに登録する
- 1件のホテルあたり、宿泊人数 x チェックイン日 x 宿泊日数 x ... とパラメーターの組み合わせが多く、1リクエストで1つの組み合わせしか取得できない
- ホテル自体の情報が更新されているものを取得しElasticsearchに登録する
- カスタマーレビューによる点数などは定期的に更新されており、検索条件として指定できるためElasticsearchの更新が必要
これらのバッチ処理でElasticsearchに登録するデータ数はそこそこ多いです(少なくともホテル数なので60万件)。どう組むかを考えるときに考慮したことは以下です。
- どれくらいの実行時間で終わらせる必要があるか
- 検索データをインデックスをしたいだけので今回は気にする必要はそこまでない
- 利用者が増えてくれば利益も出てくるので、バッチ処理の頻度をあげて常に最新データになるようにする可能性はある
- ボトルネックはどこか
- 某旅行サービスAPIは負荷をかけても問題ないらしかった
- バッチ処理をAPIサーバーとは別のCloud Runサービスを使えば負荷は気にしすぎなくてよさそう
- ということはElasticsearchが耐えられる程度の流量でデータを流す必要がありそう?
- リトライ可能か
- Elasticsearchにインデックスするデータはその時点で最新のものであればよい
- あまり気にせず実装しても自然に冪等になりそう
以上の考慮したことを踏まえると、このバッチ処理で1番大変そうなのは「Elasticsearchが耐えられる程度の流量でデータを流す」ことだと考えました。GCPにはトークンバケットアルゴリズムで流量を調整できるCloud Tasksというサービスがあるのでこれを活用します。1つのTaskにIDを振ることができ、Cloud Tasksが重複したTaskの登録を弾いてくれます。また、リトライ回数やそのタイミングまで細かく調整できるため、GCPのサーバーレス(今回はCloud Run)でバッチ処理を行う際には非常に便利なサービスです。
今回は以下のような流れでバッチ処理を行います。Cloud Schedulerでバッチ処理対象をTaskに分割してCloud Tasksに登録し、流量制御された状態でまたCloud Runへ投げて1件づつ処理していきます。Elasticsearchのbulk update APIを利用するほうがインデキシングのパフォーマンスがよいことがわかっていたので、今回は1つのTaskに複数のIDを含めて処理するようにしました。

検索リクエストによる負荷よりもバッチ処理でのインデキシングのほうが負荷が高くなるので、Elasticsearchのスペックと流量の調整は実際にバッチ処理を動かしてみて調整というかなり地道な作業でした(結構大変でした)。
少しだけ実装よりの話になりますが、Cloud Tasksは登録されたTaskをもとにHTTPリクエストをCloud Runに送るようになっており、リクエストヘッダーにこのTaskは何度目の試行かを載せてくれています(詳細はこちら)。最後の試行で失敗した場合にはアラートログを出力するなども可能です。この構成をさっとTerraformで構築できるようになっていると、他のサービスでバッチ処理を組む際にも割と便利なので重宝しています。ただ、Taskを登録するエンドポイント(Schedulerに呼ばせるところ)とTaskを受け取るエンドポイントの2つを実装する必要があるのが少し手間です。また、Cloud Runの1リクエストに対するタイムアウトは最大1時間なのですが、Schedulerのタイムアウトは30分までなので、30分以内にCloud Tasksへ全Taskを登録する必要があるのでそこは注意が必要です。
実装
ここまで考えたらあとは実装するだけでした。かなり細かい話になってしまうので割愛しますが、Elasticsearchのindexの設定や日本語の文字解析の設定から始まり、某旅行サービスAPIの仕様の把握と膨大な数のフィールドが存在するデータを使いやすい形でフィルターできるようにしたりと非常に大変でした。色々ありなんだかんだ1人で実装しましたがいい経験でした。
おわりに
ソフトウェアアーキテクチャの基礎(オライリーのサイトへ飛びます)を現在読んでいて刺激を受け、自分が何を考えてアーキテクチャを設計しているのかをアウトプットしてみたくてこの記事を書くことにしました。「ソフトウェアアーキテクチャはトレードオフがすべてだ。(中略)アーキテクトが、トレードオフではない何かを見出したと考えているなら、まだトレードオフを特定していないだけの可能性が高い。」などと書かれており、本当にそのとおりであることを実感します。すべてを解決することができるアーキテクチャは存在しないし、サービスやチームにあった最適なアーキテクチャを常に考え続ける必要があると思います。そして私はこういったアーキテクチャを設計することがとても好きなことに気がつきました。長くサービスを見ていないと自分の選択が正解だったかどうかはわからないし、頻繁に挑戦できるものでもないのがもどかしいところです。
この本には「アーキテクチャとは、Googleで答えを見つけられないものだ。」とも書かれています。この記事が、誰かの答えにはならないにしろ、誰かの参考になれば幸いです。
Discussion
開発期間はどのぐらいでしょうか。
私一人では、とても構築できそうにありません。
コメントありがとうございます~!
正直あんまり覚えてないんですが、たぶん1〜2ヶ月くらいだと思います!
爆速ですね!
ご回答ありがとうございます。
面白い記事ありがとうございました!
本題から外れるかもしれませんが、Algolia に関して一点気になりました。
インデックスのコピーが必要になるのは、「検索したいフィールドを増やすごと」ではなく、「並び替え方法を増やすごと」のはずですね。例えば、客室インデックスがあったとして、それを料金の昇順に並び替える、広さの降順に並び替える、の2パターンをサポートしようとすると、追加で2つ分のインデックスコピーが必要になります。
参考: https://www.algolia.com/doc/guides/managing-results/refine-results/sorting/how-to/creating-replicas/
いずれにしても Algolia の定価料金は尋常じゃなく高いですが笑
おおおお、ご指摘ありがとうございます!!曖昧な記憶で書いた箇所でした…修正しました、助かります🙏
めちゃくちゃ参考になります!私自身Elastic Cloudを初めて触るので血眼になって見てました。
初歩的な質問で申し訳ないんですが、ホテル検索においてElastic Cloudで提供されるElasticsearchのAPIをAlgoliaのようにフロントエンドから直接読ぶようなかたちで組まれているのでしょうか?(API Keyのロール制限等をして)
そういうのもできそうではありますが、今回はサーバーを通して呼んでますね。
ありがとうございます!参考にさせていただきます💪