Redmineのナレッジ一覧をCSVで取る
概要
Redmineのナレッジベースのホーム(一覧)画面に表示しているものをCSVでダウンロードする。
ブラウザのデバッグモードでjavascriptコードを入力して実行する。
CSVファイルの文字コードはUTF-8。(RedmineのページがUTF-8であるため)
制限事項
Redmineのナレッジベースプラグイン(Redmine knowledgebase)が対象。
画面に表示している内容のみ取得できる。
このため、以下の制限がある。
- 記事の登録が多すぎて画面に表示されない場合、非表示の記事は取得できない。
- 記事の概要が長すぎる場合、途中で切れて「...」が末尾に付く
使い方
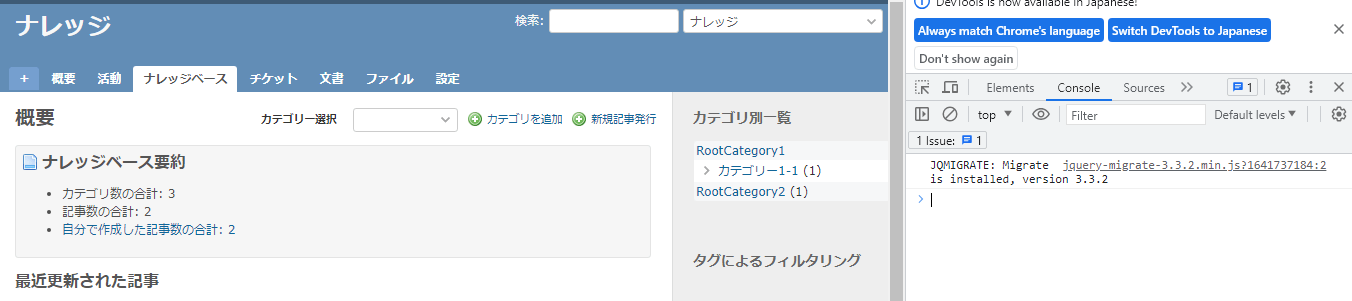
- ブラウザでナレッジーベースのホームを開く
- ブラウザをデバッグモードに変更
- コンソールにjavascriptコードを貼り付ける
※出所不明なソースコードを貼り付けて実行してはいけません(自己矛盾)
ソースコード
ソース全量。
この方式には「IIFE(即時実行関数式)」という名前が付いているらしい。
(function () {
/** 記事種類 */
const 記事種別 = {
"最近更新された記事": ".recently-changed",
"人気の記事": ".popular",
"評価の高い記事": ".top-rated"
};
/** 記事アイテムクラス */
class KnowledgeItem {
/** @param {string} category 記事のカテゴリー */
setCategory(category) {
this._category = category;
return this;
}
/** @param {string} title 記事のタイトル */
setTitle(title) {
this._title = title;
return this;
}
/** @param {string} url 記事のURL */
setLink(url) {
this._url = url;
return this;
}
/** @param {string} summary 記事の概要 */
setSummary(summary) {
this._summary = summary;
return this;
}
/** @return {string} CSV文字列(1レコード分) */
toCsvString() {
return `"${this._category}","${this._title}","${this._summary}","${this._url}"`;
}
}
/**
* HTMLを解析して記事アイテムクラスの配列を生成.
* @returns {array<KnowledgeItem} 記事アイテムクラスの配列
*/
function analyze() {
const articleList = document.querySelectorAll(記事種別.最近更新された記事);
let knowledgeItemArray = [];
for (knowledgeItem of articleList) {
const category = getCategory(knowledgeItem.className);
const linkTag = knowledgeItem.querySelector("a");
const summary = knowledgeItem.querySelector(".summary p");
knowledgeItemArray.push(new KnowledgeItem()
.setCategory(category)
.setTitle(linkTag.title)
.setLink(linkTag.href)
.setSummary(summary.textContent)
);
}
return knowledgeItemArray;
}
/**
* カテゴリのフルパス文字列を取得
* @param {string} className ナレッジアイテムのclassName
* @returns {string} カテゴリのフルパス文字列
*/
function getCategory(className) {
const categoryArray = className.split(" ");
const category = categoryArray[categoryArray.length - 1];
return category.trim().substring(9);
}
/**
* CSV文字列生成
* @param {array<knowledgeItem>} knowledgeItemArray 記事アイテムクラスの配列
* @returns {string} CSV文字列
*/
function toCsvString(knowledgeItemArray) {
let csv = `"カテゴリー","題名","概要","リンク"\r\n`;
for (v of knowledgeItemArray) {
csv += v.toCsvString();
csv += "\r\n";
}
return csv;
}
/**
* CSVファイルをダウンロード
*/
function download() {
const knowledgeItemArray = analyze();
const csvString = toCsvString(knowledgeItemArray);
const blob = new Blob([csvString], { "type": "text/plain" });
const link = document.createElement("a");
link.href = URL.createObjectURL(blob);
link.download = "knowledgebase.csv";
link.click();
}
// ダウンロード処理を実行
return download();
})(this);
ナレッジベースのHTML解析
記事毎に次の構造をしている。
<div class="article-icon recently-changed category-rootcategory1 category-rootcategory1-カテゴリー1-1">
<a title="カテゴリー1-1の記事" href="/redmine/projects/knowledge-base/knowledgebase/articles/1">カテゴリー1-1の記事</a>
<div class="summary"><p>カテゴリー1>1>記事
概要
あああああああああああああああああああああああああああああああああああああああああああああああああああああああああああああああああ
いいいいいいいいいいいいい...</p>29分前に更新</div>
</div>
外側のdivタグのclassには以下が設定される
- アイコン(article-icon)
- 分類(最近更新された記事はrecently-changed)
- カテゴリー
これを踏まえ、document.querySelectorAllを利用して記事を配列で取得する。
「最近更新された記事」のみ取得
最近更新された記事、人気の記事、評価の高い記事、は順番違いで同じものが表示されている。
登録されているナレッジが全件表示されているのであれば、どれか一種類だけ取得で良い。
const articleList = document.querySelectorAll(記事種別.最近更新された記事);
取りたいものを変更しやすいように定数宣言している。
日本語名にしているのは、良さげな定数名を思いつかなかったため。
※オブジェクトなので、厳密には定数とは言えない
/** 記事種類 */
const 記事種別 = {
"最近更新された記事": ".recently-changed",
"人気の記事": ".popular",
"評価の高い記事": ".top-rated"
};
カテゴリー取得
カテゴリーは階層の数だけ設定される。
「category-」が先頭に付き、親階層側から順に半角ハイフンつなぎでその階層までのフルパスとなる。
上の例は「RootCategory1 > カテゴリー1-1」、2階層目のカテゴリーの記事の場合。
classには「category-rootcategory1」と「category-rootcategory1-カテゴリー1-1」が設定される。
classを半角スペースで分割し、最後の項目を取得することで一番深い階層までのフル階層名を取得し、取得した文字列から先頭の「category-」を削る。
function getCategory(className) {
const categoryArray = className.split(" ");
const category = categoryArray[categoryArray.length - 1];
return category.trim().substring(9);
}
カテゴリ名をclassに設定する際に、
- アルファベットはすべて小文字に変換される
- 半角ハイフンが入っていてもそのまま使われる
というナレッジベースの仕様がある。
カテゴリを階層毎に再分割する処理を作りたい場合、半角ハイフン入りのカテゴリー名を使っていると、半角ハイフンを階層の境目とし判断する処理は出来なくなる点に注意。
実装の追加説明
ソースコードの中から、追加説明が必要そうな部分をピックアップ。
CSV文字列生成
`"${this._category}","${this._title}","${this._summary}","${this._url}"`;
全項目をダブルクオーテーション付きにしている。
タイトルや概要に半角カンマや改行が含まれていても問題なく扱えるように対策した。
概要に改行が入っていた場合、画面上は半角スペースで表示されるが、ダウンロードしたファイル内では改行(\n)が入っている。
エクセル等ではCSVを読み込んだ際に、次のように扱う。
- ダブルクオーテーション内の半角カンマはセル内の文字として扱う
- ダブルクオーテーション内の「\n」はセル内改行として扱う
- 「\r\n」は改行(次のレコード)として扱う
※注意
CSVを直接エクセルで開くと「MS932」として開いて文字化けする。
「UTF-8」で読ませる必要がある。
- 「データ>テキストまたはCSVから」でCSVファイルを指定
- 「元のファイル」で「UTF-8」を指定


メソッドチェーン
KnowledgeItemクラスのセッターはすべて自インスタンを返すように作った。
setCategory(category) {
this._category = category;
return this;
}
このように実装すると、コンストラクタからセッターをすべてつなげて実行でき、一度変数にKnowledgeItemのインスタンスを設定しなくても配列に追加ができる。
knowledgeItemArray.push(new KnowledgeItem()
.setCategory(category)
.setTitle(linkTag.title)
.setLink(linkTag.href)
.setSummary(summary.textContent)
);
見た目が綺麗かと言われると微妙。
利点があるかと言われても微妙。
CSVダウンロード
const blob = new Blob([csvString], { "type": "text/plain" });
const link = document.createElement("a");
link.href = URL.createObjectURL(blob);
link.download = "knowledgebase.csv";
link.click();
- Blobを生成
- リンクタグを作成
- リンクタグのリンク先はBlobに指定
- ダウンロードするファイル名を指定
- 作成したリンクタグをクリック
なぜ作ったか
ナレッジベースを整理したくなったので。
全ての記事を読む前に当たりを付けるために、一覧を取得しようと思った。
Discussion