AItuberの作り方を調べる・考える・触ってみる
3DベースはUnityならいくらでもやりようがあるが、2Dベースに詳しくないので周辺技術を調べるところから。
参考になりそうな記事
必要になりそう・使った方が良さそうなツール類
- LLM
- Avatar
- Voice Synthesis
- Live
所感:
LLM、音声合成周辺は既に触っているので大体把握している。
Live2D周り、Live2DとOBSの連携周り(or VTuver Studioの利用イメージ)、Live2DとLangChainの連携周り、YouTubeのAPI周りはまだイメージがついていない。
3Dならアバター周辺がUnityに置き換わるだけ。
LangChainを使うならPythonでサーバーを書くのが直感的ではあるが、しっかり作る・長期メンテするならGoやRustなどで書きたい感もある。(FastAPIなどでAPI化して独立させれば可能。)
とりあえずプロトタイプを作ることを想定して、構成を考えてみる。
- キャラクターの中身・会話部分はLangChain
- キャラクターの見た目はLive2D
- SDKがあるので何ができるのか調べる必要がありそう
-
配信はVTuber Studio?- APIからも色々触れそう:https://note.com/mega_gorilla/n/n927a17a40d36
- 配信部分はOBSでやるだけで、本領は簡易トラッキグらしいのでAItuberには必要なさそうかも
- 音声合成はPCのスペックを考慮してとりあえずKoeiromapを使用する
- 配信はOBS
- YouTube APIを使ってコメントを収集する仕組み(サーバー)
↓
PythonでLangChain、Live2D SDK、Koeiromap API、YouTube APIを取り回して、最終的にはOBSでYouTube Liveに配信をする、というイメージ。
Live2DのSDK周りをもうちょっと調べる。
- 対応プラットフォーム広くてしっかりしてる
- モノリス構成だとWeb Frontendに出すのが早そう?
- Unity触れるんだからUnity使った方が手っ取り早い説もある(2D <-> 3Dの使い回しもできるし)
Live2DのUnity SDKがあって、結局SDKを使うだけということを踏まえて構成を再考する。
- Unityベース
- 慣れているので早い
- 既に作っているライブラリがある
- C#で安全に書ける(個人的に)
- LangChain部分は最低限別サーバーを立てて分ける必要があるが、既にある程度作っているので大変ではない
- 3Dベースでも使い回しができる
- Webベース
- あんまり慣れていないので調べながら
- 一から機能を作る必要があるが、そんなに難しくないはず
- Pythonで書くのがしんどい(個人的に)
- モノリスで作れるので取り回しは良い
- 3DベースにしようとするとLive2D部分をUnityに置き換えることになる
プロトタイプはUnity使った方が早そうなので切り替える。
そうなるとまだ手をつけてないのは下記。
- Live2Dのモデル作成
- https://docs.live2d.com/cubism-editor-tutorials/top/
- サンプルモデルがあるようなので、とりあえず動かし方を把握するだけならモデル作成は後回しでも良さそう
- Live2DのUnity SDKの触り方
- https://note.com/live2dnote/n/n5ec92561e02b
- SDK本体をUnityプロジェクトに取り込む部分はライセンスに注意が必要かも
- YouTube Data APIの触り方
- .NET実装も用意はされているが、そんなに多く使わないなら自分で書いた方が取り回し良さそう
- https://github.com/googleapis/google-api-dotnet-client
Live2DのUnity SDKをもう少し詳しく調べる。
商用利用はライセンス契約が必要になるので注意が必要そう。
出版許諾契約の締結
コンテンツへのCubism SDKの導入決定後から正式リリースの1ヶ月前までに以下フォームからの申請及び出版許諾契約の締結が必須となります。
チュートリアルをざっと眺める。
SDKはGithubでも公開しておりますがこちらにはライブラリが含まれないため、モデルを組み込む際にはパッケージを使用してください。
謎。
ネイティブプラグイン部分は .unitypackage にしか入ってないということ?
SDKでは、モデルと同様に.motion3.json用のImporterも用意しており、.motion3.jsonはインポート時にUnityのアニメーション形式であるAnimationClipに自動で変換されます。
モーションは AnimationClip でインポートされるよう。
//Load model.
var path = Application.streamingAssetsPath + "/koharu.model3.json";
var model3Json = CubismModel3Json.LoadAtPath(path, BuiltinLoadAssetAtPath);
var model = model3Json.ToModel();
ランタイムでの読み込みもサポートされているよう、これはありがたい。
Live2Dにおけるパラメータが何なのかまだ理解できていない。
他にも制御用コンポーネントが用意されているよう。
雰囲気的にはRenderingはLegacy Pipelineのみ?
URP対応しているのか要確認。
AssetBundleとは相性が悪いみたい。
↓
ざっくりは把握できたので実際に触ってみる。
環境
- macOS ARM64
- Unity 2021.3.0f1
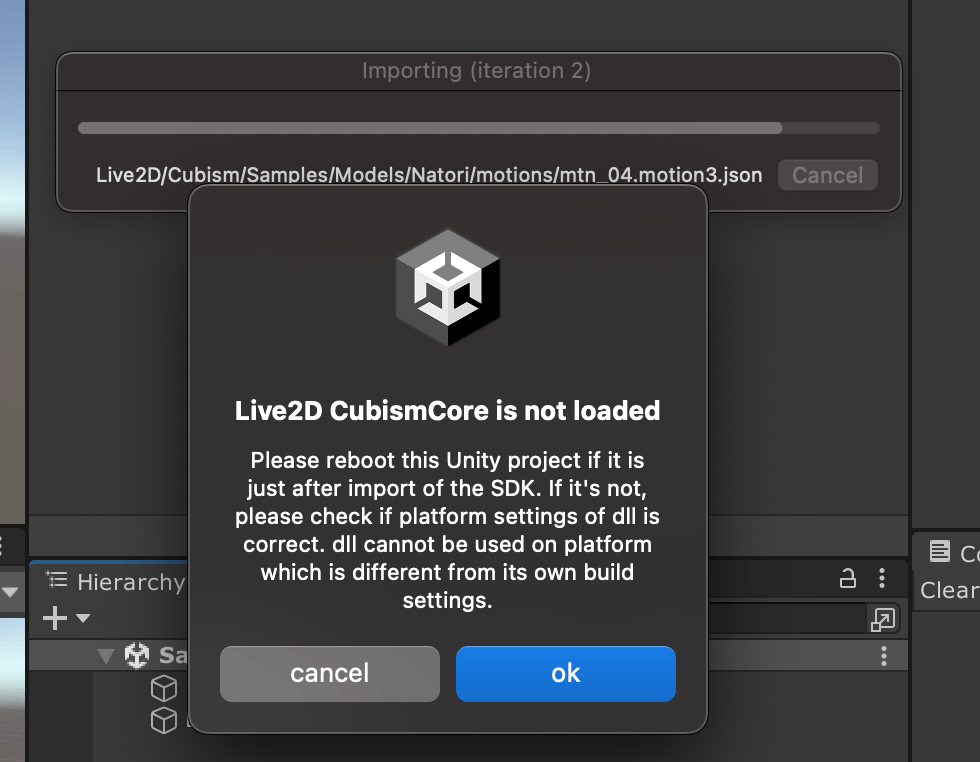
インポート時に警告が出るが、Unityを再起動しろってことっぽい。
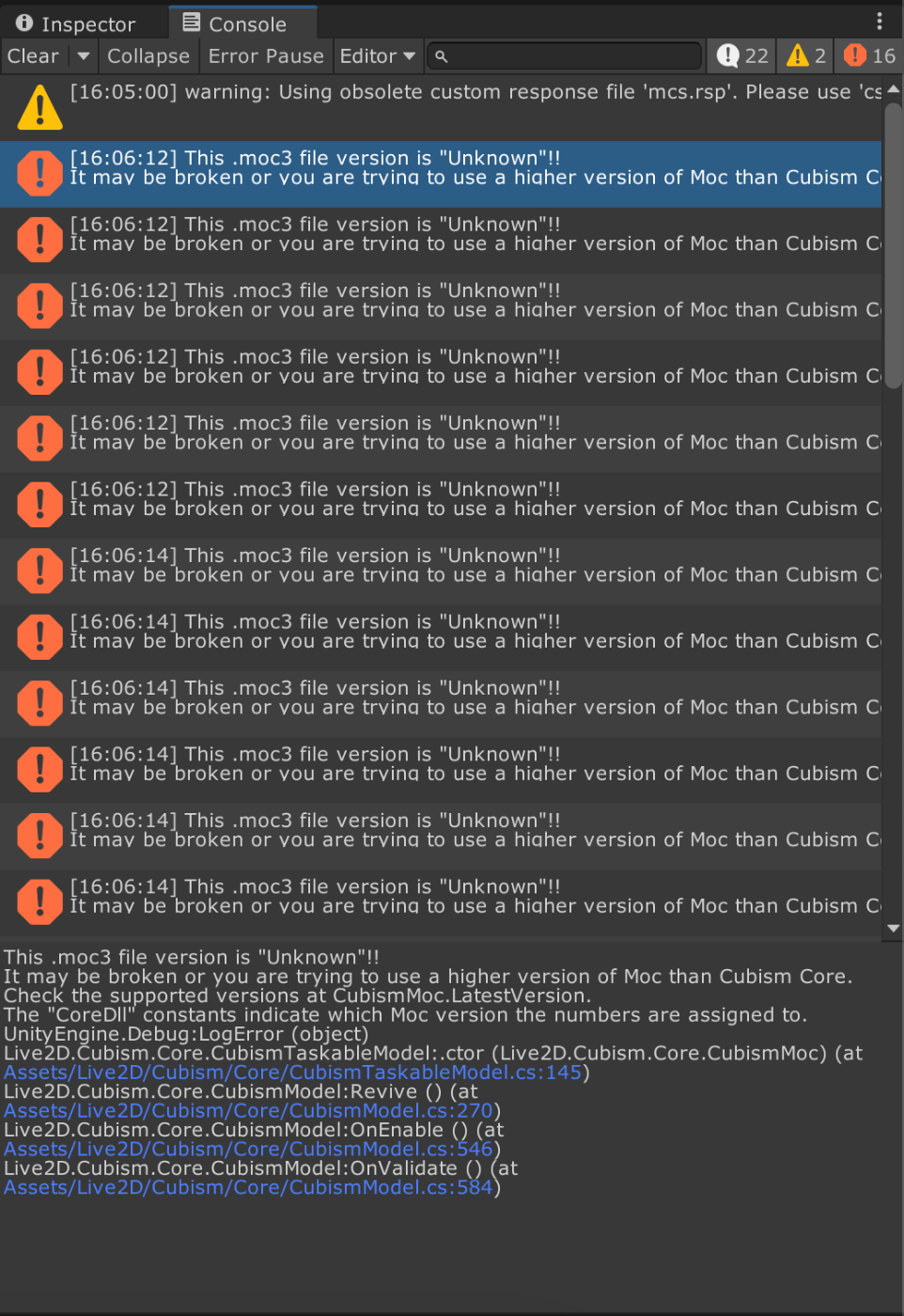
インポート時にエラーが出るが、コンパイルエラーなどの致命的なものではなさそう。
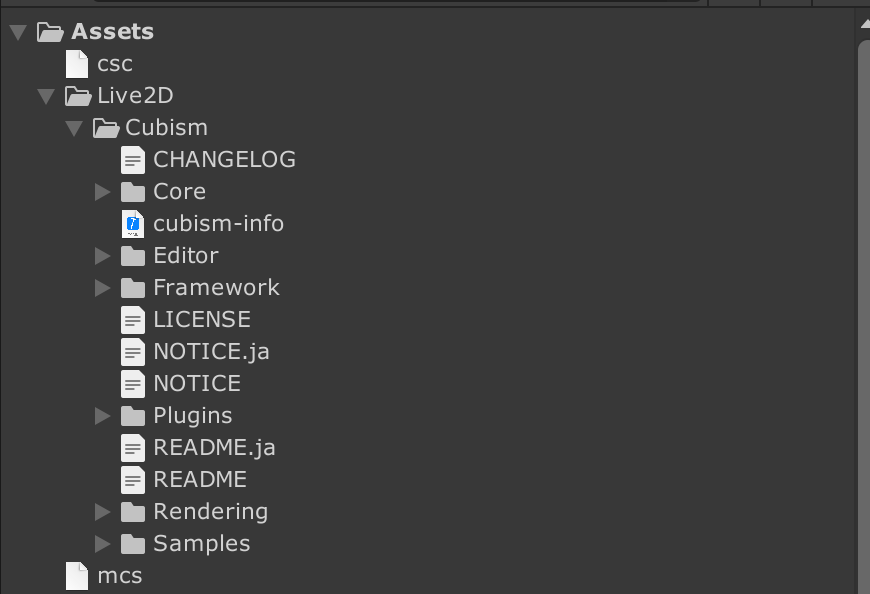
中にはScript、Plugins、Sampleなどが含まれているが、AssemblyDefinitionは置かれていない。

ランタイムロードはサポートがあるが、非同期ロードはサポートされていない。
サンプルのSceneを再生しても、始めの警告とそれに起因するエラーが出て何もできない。
原因はmacOS向けのEditor設定が、Intelのみになっていることのよう。

Unity2019だとRosettaしか対応していないはずなので仕方ない。

AnyCPUに変更して、Unityを再起動してリトライする。
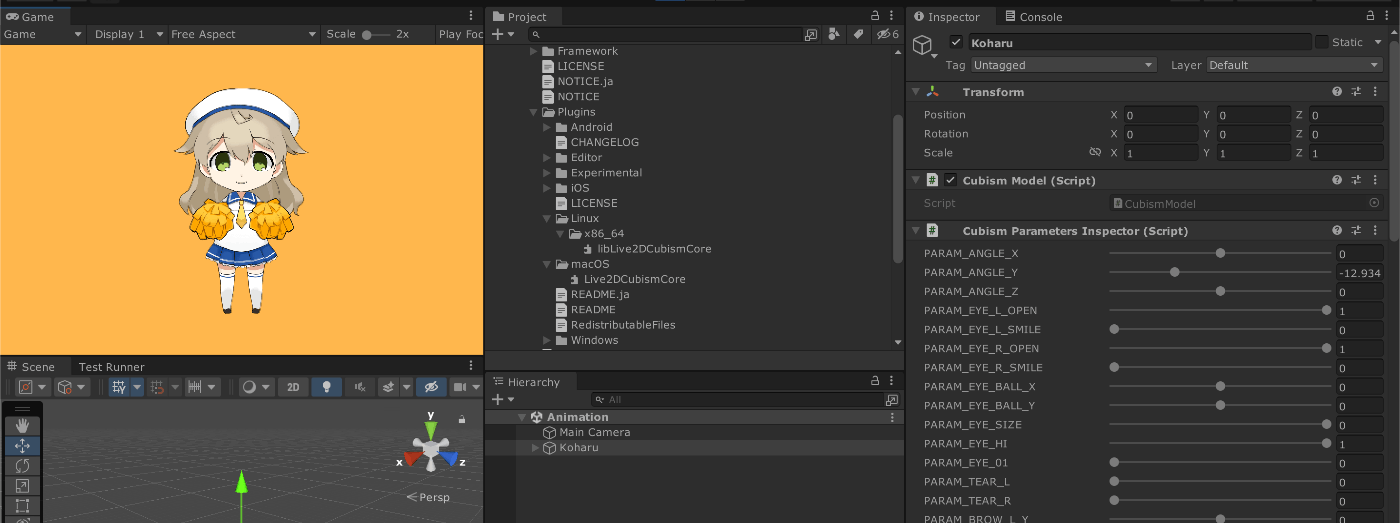
ちゃんと動いていれば成功。
とりあえずSDKの管理が大変そう。
Plugins以外はGitHubに上がっているが、package.jsonがないのでUPMで利用は不可能。
Private Repositoryに置いて、
-
package.jsonの配置 - Assembly Definitionの作成
- macOS向けのDLLのインポート設定の修正
をすれば良さそうだが、Pathに依存した処理がないか動作確認する必要がある。
Proprietaryのライセンスは再配布が禁止されている?かもしれないので、注意が必要。
Virtual Motion Captureみたいにユーザーに.packageインポートさせる、.gitignoreする、という手もあるが。
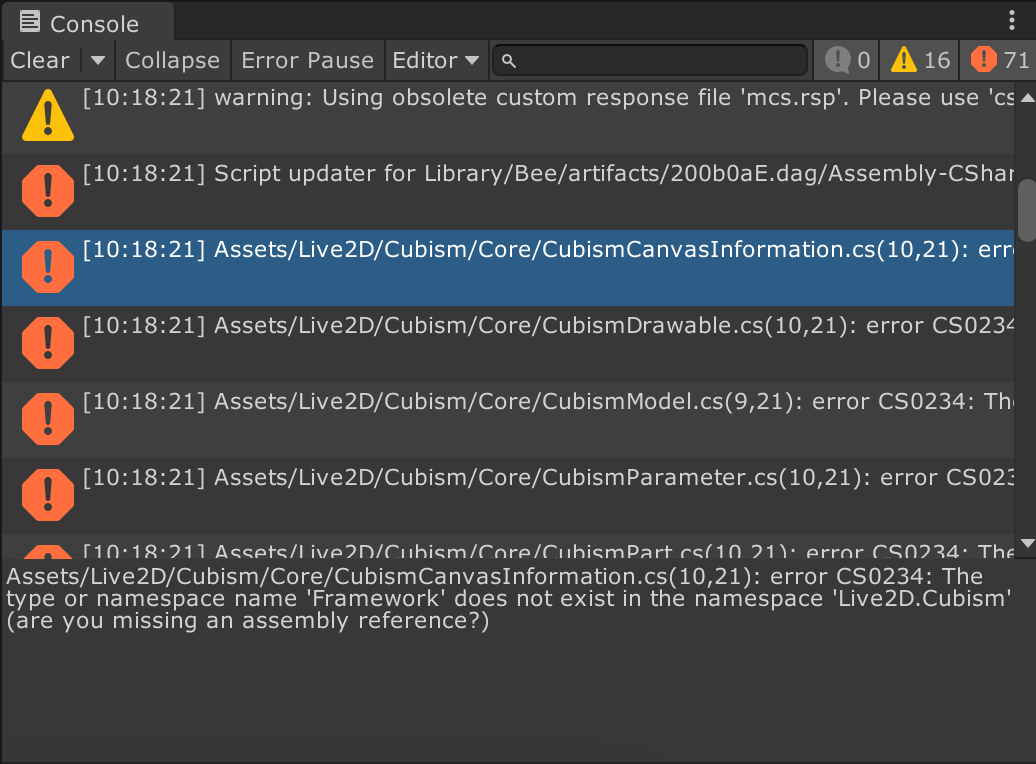
Core -> Frameworkの参照がなぜかあるので綺麗にAssemblyを分けられなさそう。(どんな作りになってるんだ)
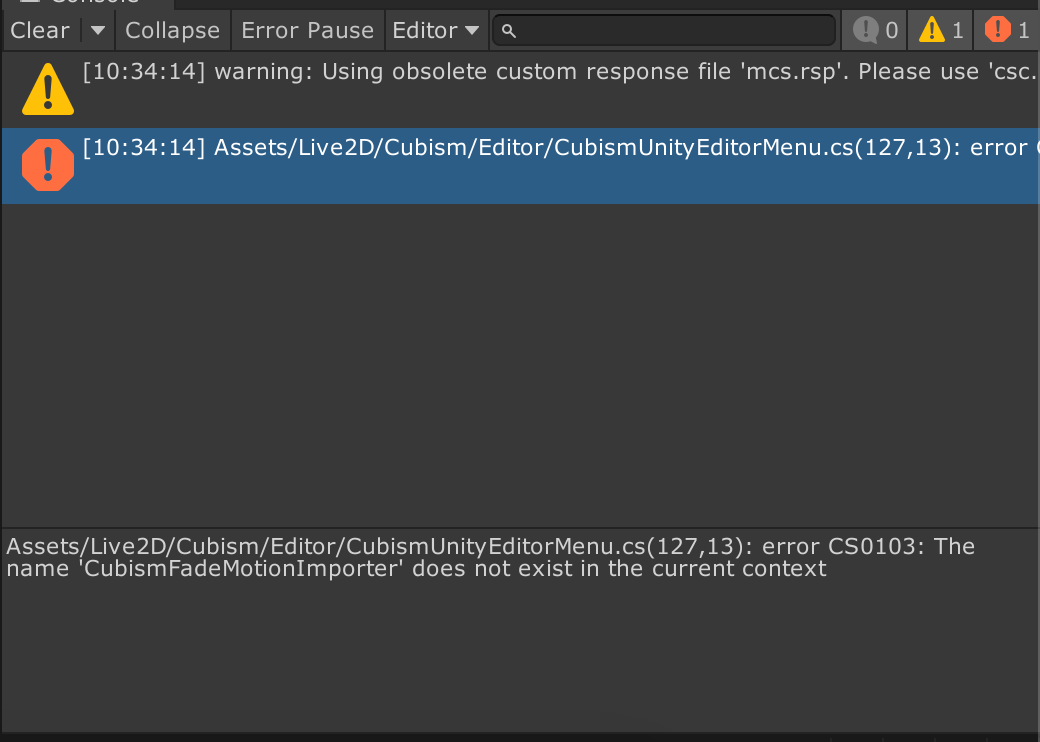
Editorスクリプト間にも循環参照があるので、単純に分けるのはダメでAssembyReferenceでまとめないといけなさそう。
package.json を配置して、/Packages フォルダに移動、File: でLocal Package参照する形に変更して、サンプルを動かしてみる -> OK
UPMで利用する形にしても問題なさそう。
結果的に?.unitypackageに含まれていた .rsp がなくても動いているが、これらは何の目的で置かれているんだろう?
Native Plugin系は,gitattributesでのGit LFSの設定を忘れないように注意。
別UnityProejctでのインポートの動作確認 -> OK
目や口の動かし方を調べる。
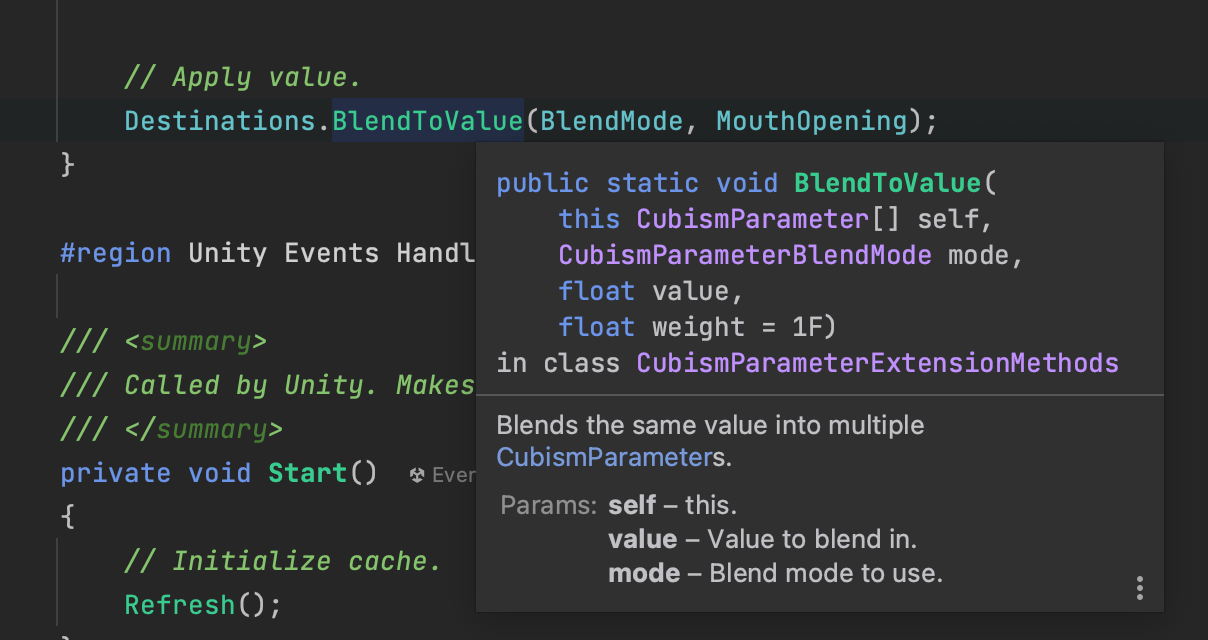
Parameter単位でComponentになっているらしい。
なので動かしたいParameterを取得して、Valueを操作してあげれば良さそう。
サンプルやドキュメントでは、〇〇Controller的なもので動かす部分を管理していて、Inputは別のComponentになっている、という作りになっている。
ParameterのComponentの対応関係:
- Lip ->
CubismMouthParameter- 口を動かす
- Eye ->
CubismEyeBlinkParameter- 目を動かす
- Pose ->
CubismPosePart- ポーズをつける
- Expression ->
CubismExpressionData- 表情をつける
- 表情はParameterの組み合わせなのでデータセットを事前に用意する流れ?
- Animation ->
AnimatorController- アニメーションは通常通り
- 動的にセットアップした時にどうなるかはまだ想像つかないかも
想定とそれほど大きく離れていはいないので、自作の表情制御ライブラリで基本的には問題なく吸収できそう。

Renderingは独自Shaderなので、URP対応はしてなさそう。
以前作ったVRMベースのプロトタイプと同じ要領で、VRM -> Live2Dの仕組みはパッとできた。
ChatGPT -> LangChainにして。
あとはYouTube Data APIからコメント等を拾う仕組みがあれば基本は完成するはず。
YouTube Data APIをまず理解するところから。
Clientライブラリを使えば実装は楽になりそうだが、Unityで実装した方がイベントなどの取り回しが良さそうな気がするので使用しない。
OAuth 2.0の認証の仕組みがある。
Live関連の項目がないと思ったら、Streaming関連は別APIっぽい?
これが参考になりそう?
Live Streaming APIのLiveChatMessagesリソースを使うと生配信中のチャットを取得できます。ただしアーカイブされたライブ配信のチャットは取得できず。公式が提供している唯一のチャット取得機能ではあるけど、クォータ数も消費するしAPIキー用意しなきゃいけないしイマイチ使いづらい。
流れ的には、
YouTube Data APIのvideosメソッドでactiveLiveChatId取得
activeLiveChatIdをキーにLiveChatMessagesを叩く
でチャットが取れる。配信が終わるとactiveLiveChatIdが消滅するのでAPI経由ではチャットを拾えなくなっちゃいます。
流れ
- (事前にAPI Keyを発行する)
- API Keyを使って、YouTube Data APIの認証を通す
- Video IDを使って、YouTube Data APIの
/videosAPIからActive Live Chat IDを取得する - Active Live Chat IDを使って、YouTube Live Streaming APIの
/liveChat/messagesからコメントを取得する
Data / 認証 API
自分で実装するのは結構大変そうだけど、そもそも認証は本当に必要?
API は、2 種類の認証情報をサポートしています。 自分のプロジェクトに必要な、いずれかの認証情報を作成します。
OAuth 2.0: アプリケーションは OAuth 2.0 トークンを、非公開のユーザー情報にアクセスするリクエストと共に送信しなければなりません。アプリケーションはクライアント ID と、場合によってクライアント シークレットを、トークンを取得するために送信します。ウェブ アプリケーション、サービス アカウント、インストール型アプリケーションで使用する OAuth 2.0 認証情報を作成できます。詳細はこちら
API キー: OAuth 2.0 トークンを提供しないリクエストは、API キーを送信しなければなりません。 キーはプロジェクトを識別し、API アクセス、割り当て、およびレポートを提供します。既存のキーの中に必要なキー タイプがない場合は、[新しいキーを作成] を選択して API キーを作成してから、適切なキー タイプを選択します。次に、そのキー タイプに必要な追加データを入力します。
詳細はこちら
API Keyを使う方式ならやっぱりOAuthの認証は不要のよう。安心。
Data / Videos API
ここを参考に、VideoIDからActiveLiveChatIDを取り出すためにVideos APIを叩いてみる。
YouTube LiveのURLが https://www.youtube.com/watch?v=xCyeWN6pSNc だとすると、VideoIDはPath Parameterの xCyeWN6pSNc の部分。
実際のResponse
{
"kind": "youtube#videoListResponse",
"etag": "******************************",
"items": [
{
"kind": "youtube#video",
"etag": "******************************",
"id": "xCyeWN6pSNc",
"liveStreamingDetails": {
"actualStartTime": "2023-05-07T10:33:17Z",
"scheduledStartTime": "2023-05-07T11:00:00Z",
"concurrentViewers": "206",
"activeLiveChatId": "***********************************************************"
}
}
],
"pageInfo": {
"totalResults": 1,
"resultsPerPage": 1
}
}
******* には実際のIDが入る。
response["items"][0]["liveStreamingDetails"]["activeLiveChatId"] が目的のActiveLiveChatID。
Live Streaming / Live Chat Messages API
スパチャもitemsには含まれているが、snippet.typeで判定できるよう。
メッセージの古い方から一定数毎にリストで取得する形式のようだが、新しい方のメッセージを取得するためにはResponseに含まれているnextPageTokenを利用する必要がある。
nextPageTokenを利用しながらPollingをすれば、最新のメッセージも拾える。
とりあえずライブラリは作ったので、ピックアップの仕方などはユースケース次第で実装できる。
進捗
- LangChainでシンプルなConversationChainを実装、短期記憶のみ
- LangChainのChatをFastAPIでAPI化して、Unityから利用できるようにする
- Live2DのUnity向けSDKのLipSync制御をfacial-expresssions-unityで実装
- UnityでLangChain、VOICEVOXのAPI、Live2Dのモデル制御を繋いで動く状態にする
- YouTube Liveのメッセージを収集するライブラリを作成
残り作業
- YouTube Liveのメッセージを適度に拾ってLangChainに渡すフローの作成
- StateMachineでちゃんと管理した方が見通しが良さそう
後回し
- facial-expresssions-unityの細かい改善
- 感情エンジンの追加
- 長期記憶の追加
- 配信の画面や演出の作成
しばらく追記していなかったので一応進捗メモ。
もうすでに仕組みはほぼ完成しているが、さすがにAIのコア部分をそのままPublicに出すのはためらわれる&当初触っていたLive2D SDKのライセンスの確認がちゃんとできていなかったことから、Private Repositoryで実装している。
構成としては下記のイメージ
- Python, FastAPI, OpenAIのライブラリ, ChromaDBのライブラリを自分で叩く独自のAPIの作成
- VectorDBを使用した簡易的なSession, Persistentのメモリの実装
- 会話のコンテキストを利用した感情出力APIの作成
- Unity, VRM, VOICEVOX, YouTube APIを使用したクライアント実装
- 基本は自分で作成したライブラリの組み合わせだけ
- State管理やタスクのQueueの管理などを丁寧目に実装
ChatAPIのStream版のクライアント実装だけ作業中だが、それが終われば当初想定していたシステムは完成する予定。
コードの内容的にはユースケースによる部分が多いので見せても参考になるか怪しいが、個別に相談があれば共有は可能。