Cognitive Services の Form Recognizer とラベリングもできる便利ツールでカスタムなOCRモデルを作ってみる
こんにちは、もっちゃんと申します。
AzureにはCognitive Servicesという優れたAI系のサービスがありますね。
その中で最近ちまちまと触っておりました、Form Recognizerのカスタムモデルを作るのがなかなか面白かったので本エントリーにて情報を残しておこうと思います。
Form Recognizerとは

Azure Form Recognizer は、機械学習テクノロジを利用して自動データ処理ソフトウェアを構築ことを可能にするコグニティブ サービスです。 ドキュメントからテキスト、キーと値のペア、選択マーク、テーブル、構造を特定して抽出します。このサービスによって、元のファイル、境界ボックス、信頼度などのリレーションシップを含む構造化データが出力されます。 手作業による操作やデータ サイエンスに関する専門知識があまりなくても、特定のコンテンツに合わせた正確な結果がすばやく得られます。 Form Recognizer を使用して、アプリケーションのデータ入力を自動化し、ドキュメントの検索機能を強化します。
Form Recognizer は、カスタム ドキュメント処理モデル、および請求書、レシート、名刺に対する事前構築済みモデル、およびレイアウト モデルで構成されています。 REST API またはクライアント ライブラリ SDK を使用して Form Recognizer モデルを呼び出すことにより、複雑さを軽減し、自分のワークフローやアプリケーションに統合することができます。
帳票などのドキュメントから文字情報を取得する所謂OCRのサービスですね。
Form Recognizerでは、次の機能を提供しています。
- Layout API
- カスタム モデル
-
事前構築済みモデル
- Invoices
- レシート
- 名刺
- ID カード
カスタムなOCRモデルを作ってみる
公式のドキュメントを参考にしながら、下記の流れで作業を進めていきます。
- 事前準備
- ラベリングもできる便利ツール(OCR-Form-Tools)の設定
- フォームにラベル付け
- カスタム モデルのトレーニングと作成
事前準備
まずForm Recognizer サービスを試すために、Cognitive Servicesのリソースを作成します。公式のドキュメントを参考にしながら下記のように、キーとエンドポイントを取得します。


また、ラベリング時に必要(ラベル付け元の画像、ラベル付け結果の置き場所)なストレージ アカウントとBlob Storage コンテナーを作成します。こちらも公式ドキュメントを参考にしながら進めます。

ストレージアカウントにはCORSの設定も必要ですので忘れずに設定しておきましょう。
- [許可されたドメイン] = *
- [許可されたメソッド] = [すべて選択]
- [許可されたヘッダー] = *
- [公開されるヘッダー] = *
- [最長有効期間] = 200

そして、Blob Storage コンテナーを作成します。

作成した Blob Storage コンテナー を選択して右クリックし、SAS の生成から SAS URLを取得していきます。
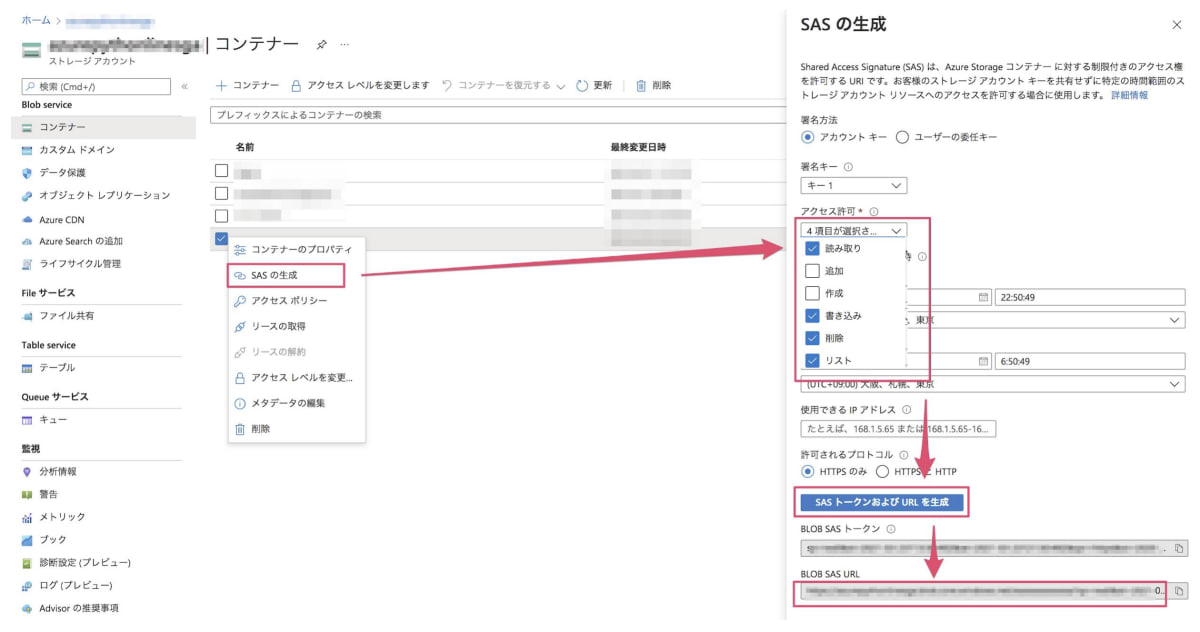
これで便利ツール(OCR-Form-Tools)に設定に必要な情報は全て揃いました。
便利ツール(OCR-Form-Tools)の設定
便利ツール(OCR-Form-Tools)ですが、Web上ですぐ使える状態のものが公開されているので今回はそちらを使っていきます!下記のURLからアクセスしてください。
ここから便利ツール(OCR-Form-Tools)の設定です。こちらもサクッと実施していきましょう。公式ドキュメントのこの辺りを参考に。
まずはConnectionsの設定です。先ほど取得したSAS URLを使用します。

次にProject を作成します。ここでは先ほど作成したConnectionsと事前準備で取得したCognitive Servicesのキーとエンドポイントを設定していきます。


最後にSave Projectを押して設定完了です!
また、ラベル付けをする画像ファイルを最低5つ、先ほど事前準備で作成したBlob Storageにアップロードしましょう。

フォームにラベル付け
さて、いよいよラベル付け作業に入っていきます!
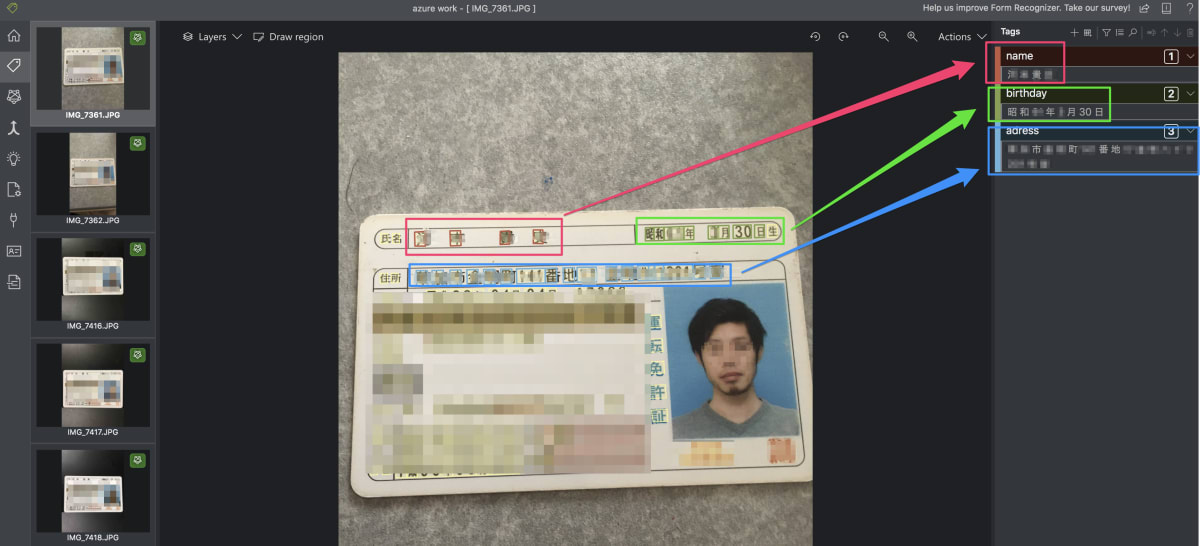
今回は〜、免許証の一部(名前、生年月日、住所)をテキストで取得できるようにラベル付けをしていきます。(先ほどBlob Storageにアップロードした画像データが表示されていると思います)
ラベル付けのやり方としてはこちらの動画のような感じです。ちなみに、ラベル付けされたフォーム(画像データ)は最低5つ必要です。また、型の定義も適宜行っていただければと思います。(今回は全てstringにします)
カスタム モデルのトレーニングと作成
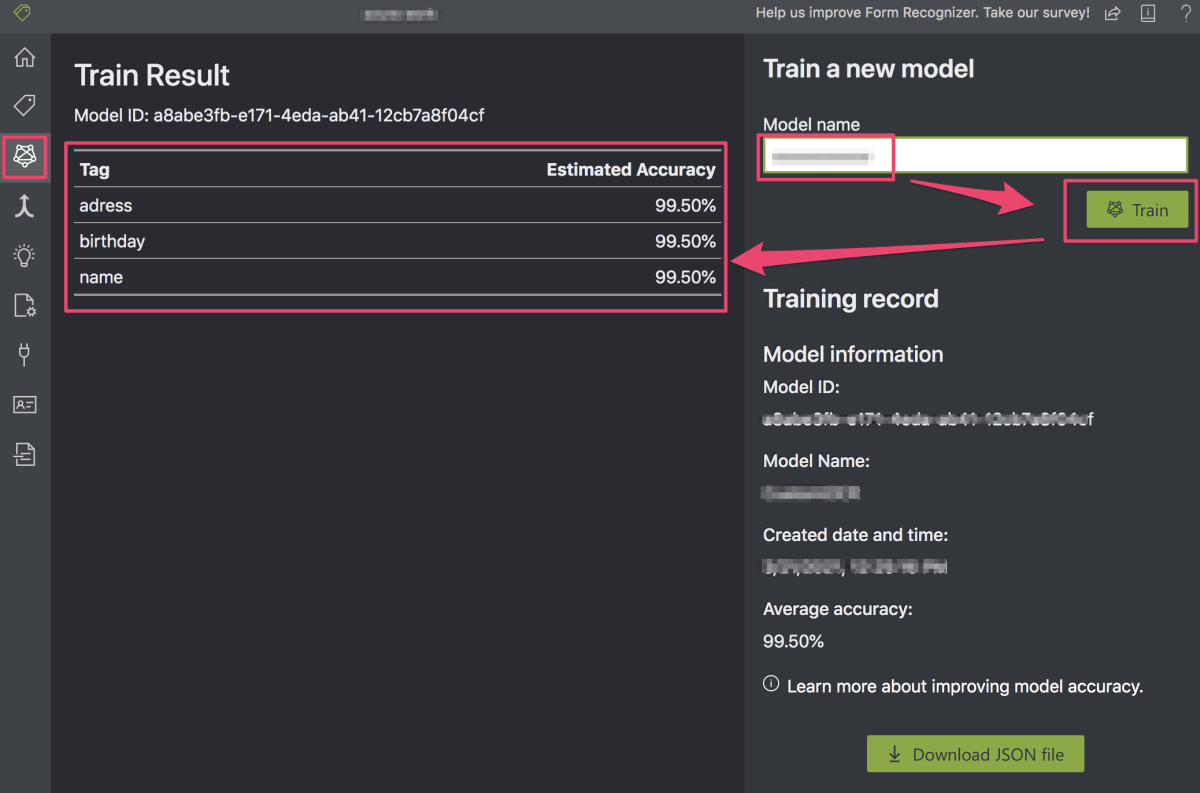
下記がトレーニングを行う画面です。Model nameを入力してTrainボタンを押すだけでトレーニングが開始されます。しばらくすると左のようにトレーニングが終了してこのモデルのAccuracy(精度)が表示されます。(99.5%とはなかなか高いですね...) ここで精度があまり良くなければラベル付けのフォームを増やして再度トレーニングを行ったりを繰り返す感じですね。
ここまででトレーニングが終わりましたので、次にトレーニング済みのモデルの作成にうつります。下記のようにトレーニング済みのものを複数選択してComposeを押すと、青枠の「人」みたいなマークが付いているモデルが作成されるといった流れです。

さっそくカスタムモデルを使ってみよう
さっそくこのカスタムなOCRモデルを試してみましょう!下記は妻の免許証を借りてこのモデルにかけてみた結果が出ているとことですが、青枠の部分を見ていただくと名前、生年月日、住所がキレイに取得できています!(モザイクばかりでわかりにくいとは思いますが...^^;)

なお、右上にあるDownloadボタンからカスタムモデルを使ったPythonコードのサンプルも取得することができます。(次の記事で使います)
おわりに
5枚だけラベリングすれば良い手軽さと、日本語もちゃんと読み取れる精度に驚きました!
次はいよいよプログラムで使っていきますよー、続きを下記の記事で見ていただければと思います。お楽しみに!
Discussion