[SageMaker Clarify] 機械学習モデルの解釈可能性・公平性を確認できるSageMakerの新機能を使ってみた
こんにちは、もっちゃんと申します。
re:Invent 2020で発表された新しいサービスや新機能の1つに「Amazon SageMaker Clarify」というSageMakerの新しい機能があります。こちらはブラックボックスになりがちな機械学習のモデルの解釈可能性・公平性を明らかにする際の支援をする機能です。実際に使いながらどのようなものか見ていきたいと思います。
Amazon SageMaker Clarifyとは?

Amazon SageMaker Clarify は、潜在的なバイアスを検出し、モデルが行う予測の説明を支援することで、機械学習モデルの改善を支援します。SageMaker Clarify は、トレーニング前のデータやトレーニング後のデータに含まれる様々なタイプのバイアスを特定し、モデルのトレーニング中や本番中に発生する可能性のあるバイアスを特定するのに役立ちます。SageMaker Clarify は、特徴量帰属アプローチを使用して、モデルがどのように予測を行うかを説明するのに役立ちます。また、本番でモデルが行う推論のバイアスや特徴属性のドリフトを監視します。SageMaker Clarifyが提供する公平性と説明可能性の機能は、AWSの顧客がより偏りが少なく、より理解しやすい機械学習モデルを構築するためのコンポーネントを提供します。また、モデルガバナンスレポートの作成を支援するツールも提供しており、リスクやコンプライアンスチームや外部の規制当局に情報を提供するために利用することができます。
機械学習は今や様々な分野で活用されており、非常に優れた効力を発揮しています。一方でディープラーニングなどはその内容がブラックボックスになりがちで、モデルの挙動を把握していないと出力した結果次第では想定外の事態も招く恐れがあります。その結果として、個人の尊厳が損なわれたり、あるいは企業の信頼性に傷がつく可能性も出てきます。機械学習のモデルに潜在的な影響が潜んでいないかしっかり把握しておく必要があるんですね。
昨今はこういった機械学習がもたらす倫理的・政策的な課題についての意識が高まってきています。Amazon SageMaker Clarify ではデータセットや予測結果の偏り、各特徴量が予測結果にどの程度影響をもたらしているのか...解釈と公平性を確認することができます。こういった機能を活用し機械学習のモデルの透明性を高めていきましょう。
使いながら学ぶ Amazon SageMaker Clarify
それではさっそく使っていきます。公式でサンプルノートブックが提供されています。こちらを参考にして見ていきます。
ここでは主に下記の機能を見ていきます。
- トレーニング後のモデルのバイアスを測定
- モデルの構築で使用した特徴量の影響度を確認
扱うデータは、UCIリポジトリで公開されているとある国勢調査のデータセットを使用します。(年齢、性別、学歴、保有資産の状況などなどの情報を持つデータ)
今回のシナリオは上記のデータから、年収が一定以上の人を予測するというものです。
まずはモデルの構築作業を進める
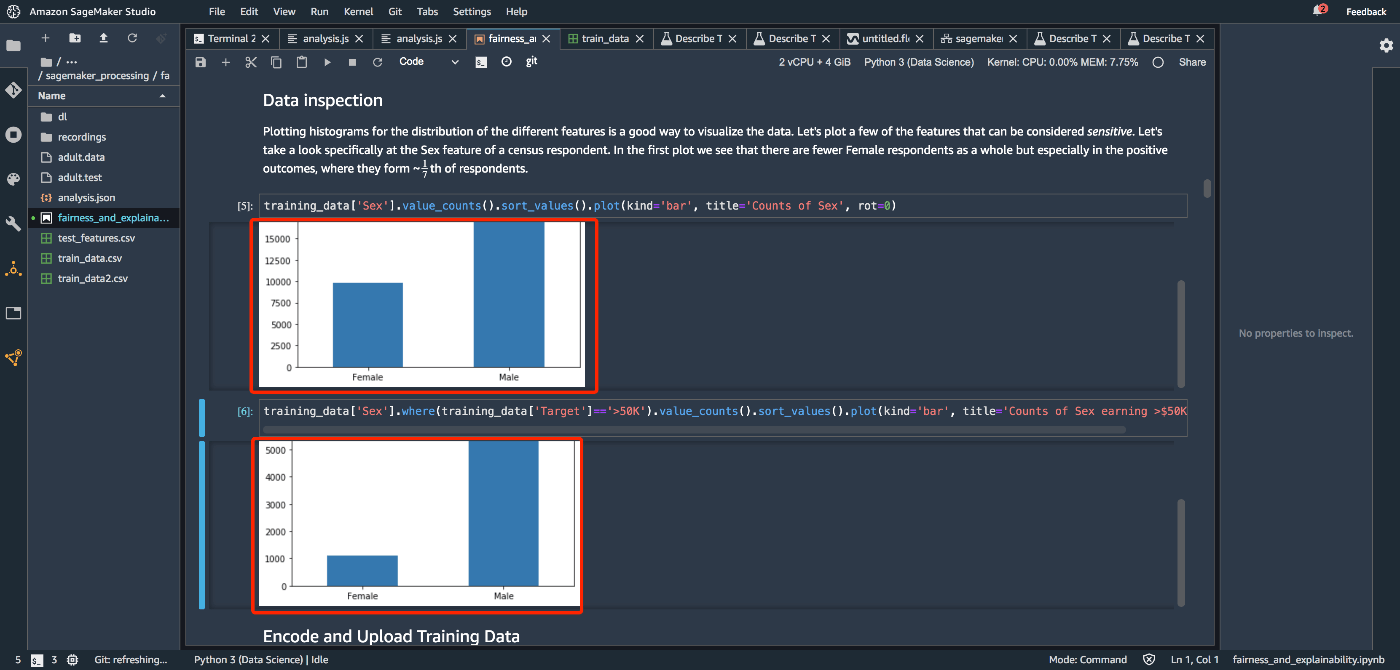
まずはいつものようにモデル構築を進めます。と、その前にデータのとある部分を見ておきます。下記の画像から男女比に偏りがあることがわかります。一定の年収以上で見ると女性の比率がさらに低くなっているようですね。
モデルのトレーニングを実施します。トレーニングデータとテストデータに分けてS3にアップロードします。アルゴリズムはSageMaker組み込みのXGBoostを使いますね。
モデルが構築できました。
Amazon SageMaker Clarify によるモデルのバイアスの測定
SageMaker Clarifyの実行はSageMaker SDKで簡単に行うことができるようです。
まずはSageMakerClarifyProcessorを呼び出してバイアスメトリクスの計算を行うインスタンスを生成します。
from sagemaker import clarify
clarify_processor = clarify.SageMakerClarifyProcessor(role=role,
instance_count=1,
instance_type='ml.c4.xlarge',
sagemaker_session=session)
次に、バイアスの検出を行うにはいくつか情報を渡す必要があります。 DataConfigを使ってデータセットに関する情報と、ModelConfigとModelPredictedLabelConfigを使ってモデルに関する情報をそれぞれ設定します。
bias_report_output_path = 's3://{}/{}/clarify-bias'.format(bucket, prefix)
bias_data_config = clarify.DataConfig(s3_data_input_path=train_uri,
s3_output_path=bias_report_output_path,
label='Target',
headers=training_data.columns.to_list(),
dataset_type='text/csv')
model_config = clarify.ModelConfig(model_name=model_name,
instance_type='ml.c5.xlarge',
instance_count=1,
accept_type='text/csv')
predictions_config = clarify.ModelPredictedLabelConfig(probability_threshold=0.8)
さらに、バイアスをどの切り口で検出するかを設定します。BiasConfigを使い、ここでは一定の年収以上を予測するにあたり性別、特に女性の場合はどのような傾向になっているのかが気になるところですので、下記のように設定します。(上の方でデータを男性と女性の観点で少しデータを見ていましたね)
bias_config = clarify.BiasConfig(label_values_or_threshold=[1],
facet_name='Sex',
facet_values_or_threshold=[0])
あとはrun_biasメソッドに上記で設定した情報を渡して実行するだけです。(他にもトレーニングの前に使用するrun_pre_training_biasやトレーニング後に使用するrun_post_training_biasのメソッドが用意されています。)
clarify_processor.run_bias(data_config=bias_data_config,
bias_config=bias_config,
model_config=model_config,
model_predicted_label_config=predictions_config,
pre_training_methods='all',
post_training_methods='all')
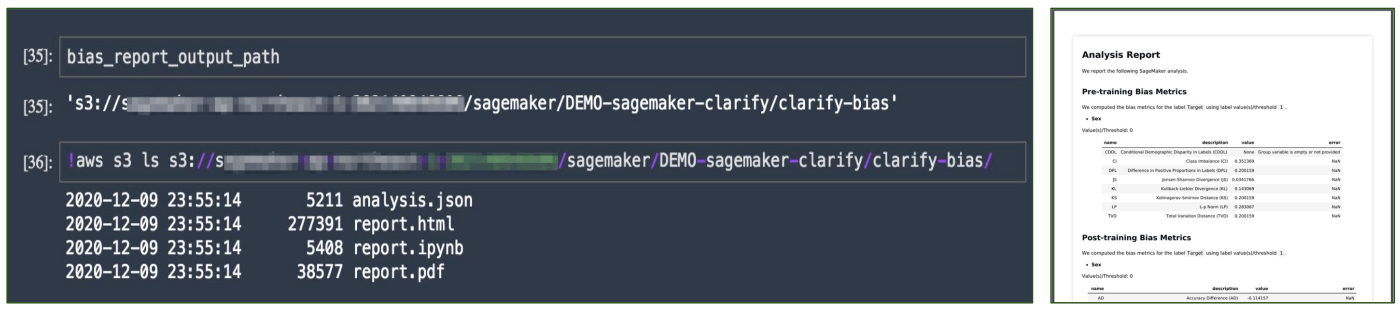
すると下記のようにデータセットと予測結果について、バイアスに関する情報を表示してくれます。Class Imbalance (CI)やDisparate Impact (DI)あたりの数値が高く出ていることから、それぞれデータセットについては女性より男性の割合が多く(この場合1に近い値になるほど反するデータの割合が多いという意味)、予測結果もデータセットに影響されるように女性の場合よりも男性の場合の方が一定の年収以上であるという予測をだしやすい状態のようですね(この場合1より小さいとデータ量で優勢である男性の方が一定以上の年収と判定されやすいということ、1より大きい場合はその逆)。

その他、詳細情報は公式のドキュメントをご覧ください。
ちなみに、SageMaker Studio上でなくても結果の確認ができるようにレポートも出力してくれます!
特徴量の重要度確認
こちらも、SageMaker SDKで簡単に行うことができるようです。
機械学習のモデルがどうしてこの予測結果を出力したのか。その動きを解釈することが難しいケースがあります。Amazon SageMaker Clarifyの機能を使うと、モデルの解釈を助けてくれるんですね。さっそく使っていきます。
shap_config = clarify.SHAPConfig(baseline=[test_features.iloc[0].values.tolist()],
num_samples=15,
agg_method='mean_abs')
explainability_output_path = 's3://{}/{}/clarify-explainability'.format(bucket, prefix)
explainability_data_config = clarify.DataConfig(s3_data_input_path=train_uri,
s3_output_path=explainability_output_path,
label='Target',
headers=training_data.columns.to_list(),
dataset_type='text/csv')
clarify_processor.run_explainability(data_config=explainability_data_config,
model_config=model_config,
explainability_config=shap_config)
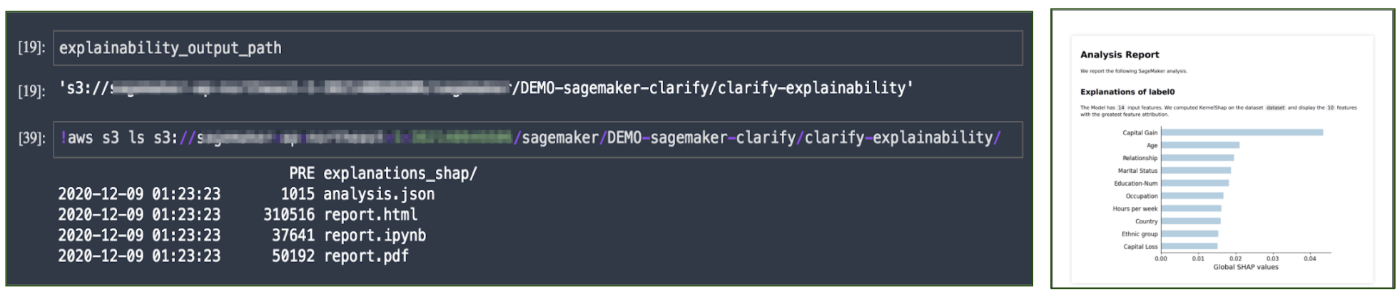
上記のコードを実行すると、下記のように各特徴量が、予測結果にどのくらい寄与しているかが可視化されています。こういった情報を元に、なぜ今回のような予測結果が出力されたのかを解釈できればモデルの挙動を説明することもできそうですね。
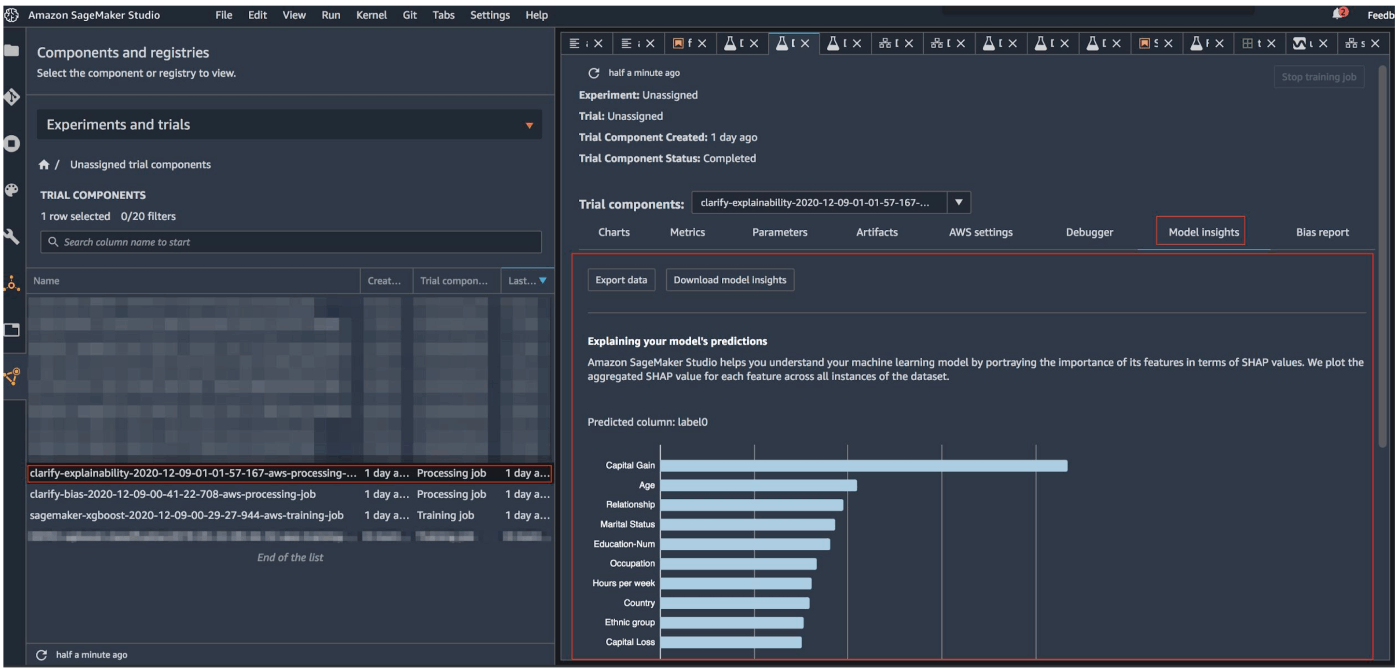
詳細については公式ドキュメントも読んでいただくのが良いと思います。
ちなみに、こちらもSageMaker Studio上でなくても結果の確認ができるようにレポートも出力してくれます!
その他
ちなみにAmazon SageMaker Clarifyの機能はSageMakerの他の機能と組み合わせて使用することもできます。
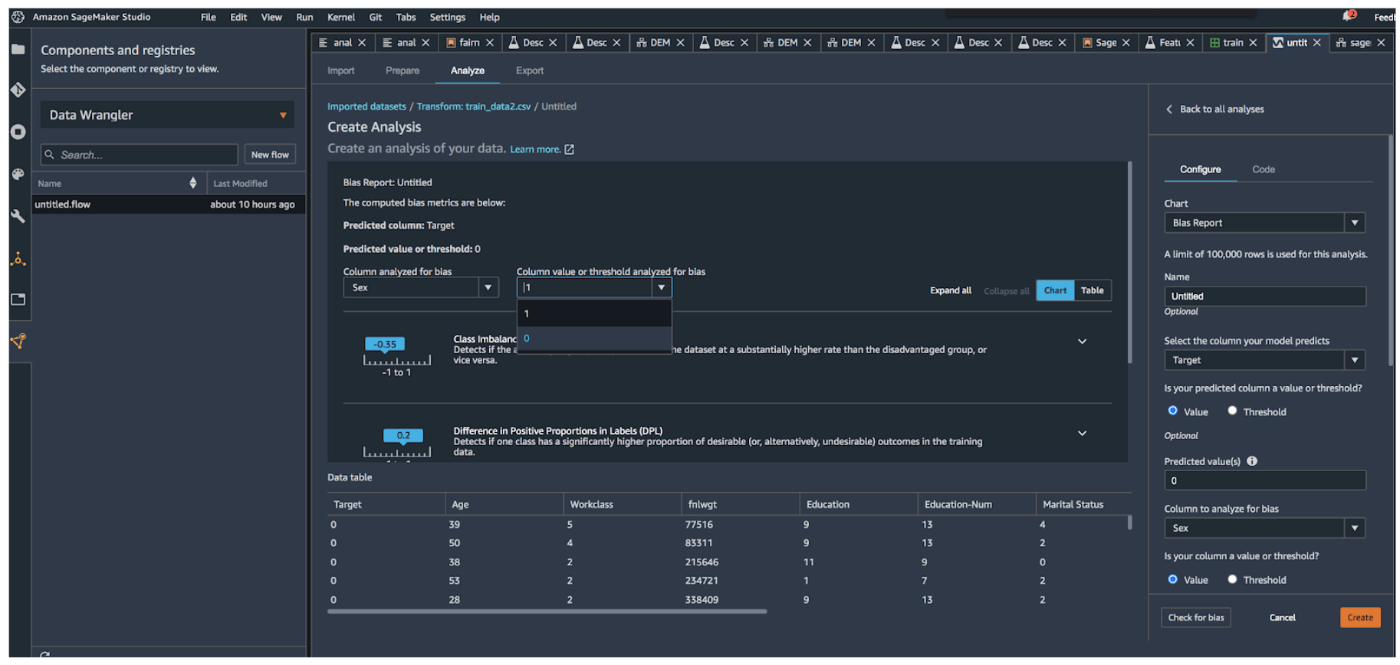

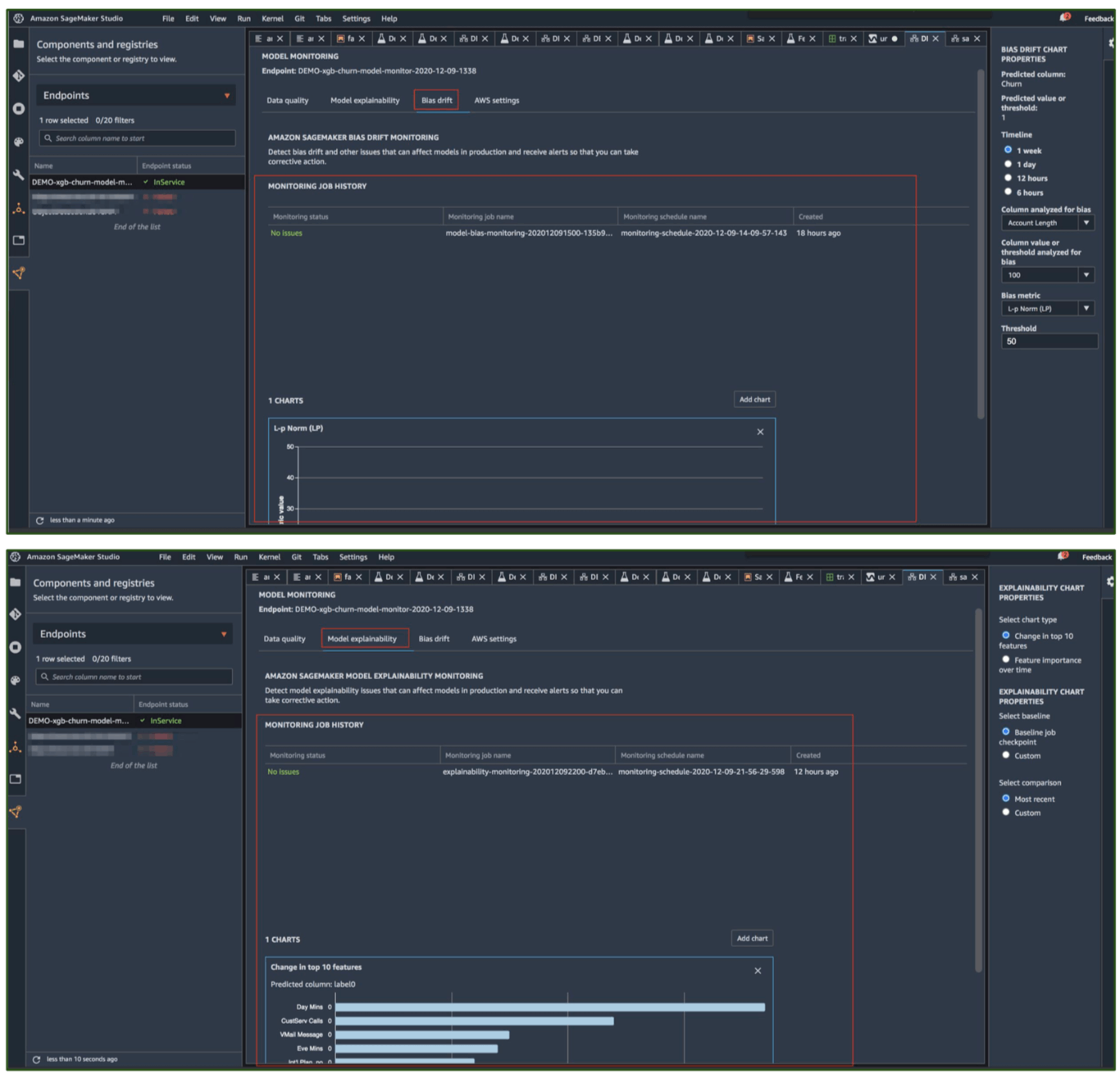
こういった機能との連携も、別の機会で詳しく見ていければと思っています。
まとめ
Amazon SageMaker Clarifyを使えば、機械学習モデルの解釈可能性・公平性というところが視覚的にわかりやすく確認できることがわかりました。今後もこの分野は研究が進んでいくと思われますので、Amazon SageMaker Clarifyの機能とともにウォッチしていく必要がありそうです。
参考
- https://aws.amazon.com/jp/blogs/aws/new-amazon-sagemaker-clarify-detects-bias-and-increases-the-transparency-of-machine-learning-models/
- https://github.com/aws/amazon-sagemaker-examples/tree/master/sagemaker_processing/fairness_and_explainability
- https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-fairness-and-explainability.html
- https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-measure-data-bias.html
- https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-measure-post-training-bias.html
- https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-model-explainability.html
- https://sagemaker.readthedocs.io/en/stable/api/training/processing.html?highlight=Clarify#module-sagemaker.clarify
- https://aws.amazon.com/jp/about-aws/whats-new/2020/12/detect-bias-in-ml-models-and-explain-model-behavior-with-amazon-sagemaker-clarify/
Discussion