RFC 9614: プライバシーのためのアーキテクチャとしての分割
要旨
本文書は、プライバシー分割の原則について説明する。プライバシー分割とは、プライバシーを向上させる手段として、ユーザ・アイデンティティをユーザ・データから分離することで、データと通信を複数の関係者に選択的に分散させるものである。本文書では、プロトコルのやり取りを通じてどのようなデータとメタデータが明らかにされるかを分割するためのプロトコルにおける新たなパターンについて説明し、共通の用語を提供し、そのようなモデルを分析する方法を説明する。
本文書の位置付け
本文書はインターネット標準化過程の仕様書ではなく、情報提供を目的で公開する。
本文書は、インターネット・リサーチ・タスクフォース(IRTF)の成果物である。IRTFは、インターネット関連の研究開発活動の成果を公開している。これらの成果は、展開に適さないかも知れない。このRFCは、インターネット・リサーチ・タスクフォース(IRTF)のQIRG研究グループの合意を表す。IRSGによって公開が承認された文書は、インターネット標準のいかなるレベルにも該当しない。RFC 7841のセクション2を参照のこと。
文書の現在の位置付け、正誤表、フィードバックの提供方法に関する情報は、<https://www.rfc-editor.org/info/rfc9614>で入手できる。
著作権表示
Copyright (c) 2024 IETFトラストおよび文書の著者として特定された人物。無断転載を禁じる。
本文書は、BCP 78および文書の発行日において有効なIETF文書に関するIETFトラストの法的規定(<https://trustee.ietf.org/license-info>)に従うものとする。これらの文書には、本文書に関するあなたの権利と制限が記載されているため、注意深く確認して欲しい。
1. はじめに
TLSやIPsecのようなプロトコルは、エンドポイント間で情報を転送するためのセキュアな(認証され、暗号化された)チャネルを提供する。転送中のデータの暗号化と認証は、意図したプロトコルの参加者以外の関係者が情報を閲覧したり、変更したりすることから守るために必要である。そのため、この種のセキュリティは、このようなチャネルを介して転送される情報がプライベートのままであることを保証するために必要である。
しかし、エンドポイント間のセキュアなチャネルだけでは、エンドポイント自体のプライバシー保護には不十分である。近年、プライバシー要件は、エンドポイント間の転送中のデータを保護する必要性を超えて拡大している。この拡大の例には以下のようなものがある:
-
ウェブサイト上のサービスにアクセスするユーザは、自分の位置情報を明らかにすることに同意しないかも知れないが、そのサービスがクライアントのIPアドレスを監視できれば、ユーザの位置情報に関する何らかの情報を知ることができる。サービスがユーザ・データとユーザの位置情報を結び付けることができるため、プライバシーにとって問題となる。
-
ユーザは、ニュース記事のような、許可されたコンテンツにアクセスできることを望むかも知れない。しかし、ニュース・サービスは、たとえユーザが自分の行動を追跡されることを望んでいなくても、どのユーザがどの記事にアクセスしたかを追跡するかも知れない。これは、サービスがユーザの活動をユーザ・アカウントに結び付けることができるため、プライバシーの観点から問題となる。
-
クライアント・デバイスは、指標(メトリック)を集約サービスにアップロードする必要があるかも知れず、そうすることで、サービスが特定の指標の寄与をそのクライアント・デバイスに帰属させることができる。これは、サービスがクライアントの貢献を特定のクライアントに結び付けることができるため、プライバシーの観点から問題となる。
これらの例に共通するのは、利用者はユーザ固有の情報や識別情報をサービスにあまり公開せずに、サービスとやり取りしたり、サービスを利用したいと望んでいることである。特に、ユーザ固有のアイデンティティ情報をユーザ固有のデータから分離することは、プライバシーのために必要である。したがって、ユーザのプライバシーを保護するには、アイデンティティ (誰)とデータ(何)を分離しておくことが重要である。
本文書では、「プライバシー分割」 (「デカップリング原則」[DECOUPLING]とも呼ばれることがある)を、ユーザのプライバシーを向上させる目的で、ネットワーク通信においてさまざまな関係者に表示されるデータとメタデータを分離するために使用する一般的な手法として定義する。プライバシー分割は、ユーザ固有のアイデンティティとユーザ固有のデータの間に結び付きがないことを保証することはできないが、適切に適用すれば、ユーザのプライバシー侵害が時間の経過とともに技術的に難しくなることを保証するのに役立つ。
Oblivious HTTP Application Intermediation (OHAI)、Multiplexed Application Substrate over QUIC Encryption (MASQUE)、Privacy Pass、Privacy Preserving Measurement (PPM)など、IETFのいくつかのワーキング・グループが、プライバシー分割の原則に準拠したプロトコルやシステムに取り組んでいる。この文書では、これらのグループでの作業を要約し、実際のさまざまなエンドポイントの結果として生じるプライバシーの姿勢について考えるためのフレームワークを説明する。
⚠️ プライバシー強化技術
| WG | 技術 | 概要 |
|---|---|---|
| TLS | TLS Encrypted Client Hello (ECH) | TLSハンドシェイクにおけるSNI (Server Name Indication)の秘匿化 |
| DPRIVE | Oblivious DNS over HTTPS | NSリゾルバでのクライアントの送信IPアドレスの秘匿化 ODoHは実験の位置づけでRFC化 (RFC 9230)。 |
| OHAI | Oblivious HTTP | HTTPサーバでのクライアントの送信IPアドレスの秘匿化 OHTTPはRFC 9458としてRFC化 |
| MASQUE | Multiplexed Application Substrate over QUIC Encryption | HTTP/3上で動作し、通信のトンネリングを行う |
| PrivacyPass | PrivacyPass | プライバシー保護されたCAPTCHAに応用されるトークン発行等のアーキテクチャ、プロトコル アーキテクチャがRFC 9576、認証スキームがRFC 9577、プロトコルがRFC 9578としてRFC化 |
| PPM | Distributed Aggregation Protocol for Privacy Preserving Measurement (DAP) | プライバシーを保護しつつメトリクス収集‧集約するためのアーキテクチャ、プロトコル Divvi Upというサービス開発と並行してDAPというプロトコル開発が活発に進められている |
プライバシー分割は、[RFC6973]のセクション6.1で説明しているデータ最小化のツールとして特に関連している。[RFC6973]は、[RFC6973]のセクション7.1において、プロトコルのデータ最小化をどのように評価するかに関する一連の質問とともに、インターネット・プロトコルにおけるプライバシーの考慮事項に関するガイダンスを提供している。プライバシー分割を採用するプロトコルは、その設計を評価する際、特に、分割された各コンテキストにおいて、プロトコルの参加者とオブザーバが識別子とデータをどのように関連付けることができるかに関して、そのセクションの質問を考慮する必要がある。プライバシー分割は、プライバシー・パスの場合(セクション3.3を参照)のように、アイデンティティ・プロバイダをリライング・パーティーから分離する方法としても使用できる([RFC6973]のセクション6.1.4を参照)。
プライバシー分割は万能薬ではない。それをうまく適用するには、問題となっているシステムを全体的に分析し、分割がツールとして、また実装された場合に、プライバシーが意味のある改善をもたらすかどうかを判断する必要がある。詳細はセクション5を参照のこと。
2. プライバシー分割
ユーザのプライバシー保護の観点から、本文書ではユーザ固有の情報に焦点を当てる。これには、電子メール・アドレスやIPアドレスのようなユーザ固有の識別情報や、生年月日のようなユーザに関するデータが含まれる。非公式には、プライバシー分割の目的は、ユーザ自身以外のシステム内の各関係者が、1種類のユーザ固有の情報のみにアクセスできるようにすることである。
これは、最小権限の原則の単純な応用であり、システム内のすべての関係者が、その機能を果たすために必要な最小限の情報にのみアクセスできるというものである。プライバシー分割は、プロトコル、アプリケーション、システムが、意図した目的のために情報へのアクセスを必要とする関係者にのみ、ユーザ固有の情報を公開することを保証することで、この最小化を推進する。
簡単に言えば、プライバシー分割は、その人が誰であるかということと、その人が何をしているかということを切り離すことを目的としている。このセクションの残りの部分では、プライバシー分割がこの目的を達成するためにどのように使用できるかを説明する。
2.1. プライバシー・コンテキスト
ユーザ固有の情報は、それぞれ何らかのコンテキスト内に存在する。ここで、コンテキストとは、データ、メタデータ、およびその情報へのアクセスを共有するエンティティの集合として抽象的に定義する。コンテキスト間のユーザ固有情報の相関付けを防ぐには、分割(パーティション)は、(クライアント自体を除く)シングル・エンティティが、情報が見える複数のコンテキストに参加しないことを保証する必要がある。
[RFC6973]は、プライバシーを向上させる方法として、相関関係を減らすための識別子の重要性について説明している。
相関とは、個人に関連する、あるいは組み合わせるとその特徴が得られるさまざまな情報の組み合わせのことである ...
相関は識別と密接に関係している。インターネット・プロトコルを使用すると、個人の活動を時系列に追跡し、組み合わせることが可能になるため、相関が容易になる ...
仮名性が強化されるのは、仮名にリンクできる個人データが少ない場合、そして、同じ仮名が使用される頻度や状況が少ない場合、また、独自に選択された仮名が、より頻繁に新たな行動に使用される場合(オブザーバーや攻撃者の観点からは、それらを結び付けられなくなる)である。
コンテキストの分離は、プライバシー分割と相関の低減の基礎となる。例として、TCP経由の暗号化されていないHTTPセッションを考えてみる。コンテキストには、トランザクションの内容と、トランスポート及びIPヘッダのメタデータの両方を含む。参加者には、クライアント、ルータ、他のネットワーク・ミドルボックス、仲介者、サーバが含まれる。ミドルボックスや仲介者は、単にトラフィックを転送することもあれば、任意のレイヤでトラフィックを終了させる可能性もある(クライアントからのTCP接続を終了し、サーバへの別のTCP接続を作成するなど)。ミドルボックスがどのようにトラフィックとやり取りするかに関係なく、プライバシー分割の目的で、ミドルボックスはコンテキスト内のすべてのデータを観察できる。

図1: ミドルボックスを使った、暗号化されていない基本的なクライアントとサーバ間の接続図
HTTPセッションにTLS暗号を追加することは、以前のコンテキストを2つの別々のコンテキストに分割する単純な分割手法である。トランザクションの内容は、クライアント、TLS終了仲介者、サーバだけが見ることができる一方で、トランスポートとIPヘッダのメタデータはオリジナルのコンテキストに残る。このシナリオでは、それ以上の分割を行わなくても、両方のコンテキストに参加するエンティティは、両方のコンテキストのデータを相関させることができる。

図2: 暗号化を追加するとコンテキストが2つに分割される様子を示す図
分割を作るもう一つの方法は、単に別の接続を使うことである。例えば、2つの別々のHTTPリクエストを互いに分割するには、クライアントはそれぞれ異なるネットワークと異なる時間に別々のTCP接続でリクエストを発行し、HTTPクッキーのような明らかな識別子をリクエストにまたがるように含めないようにできる。
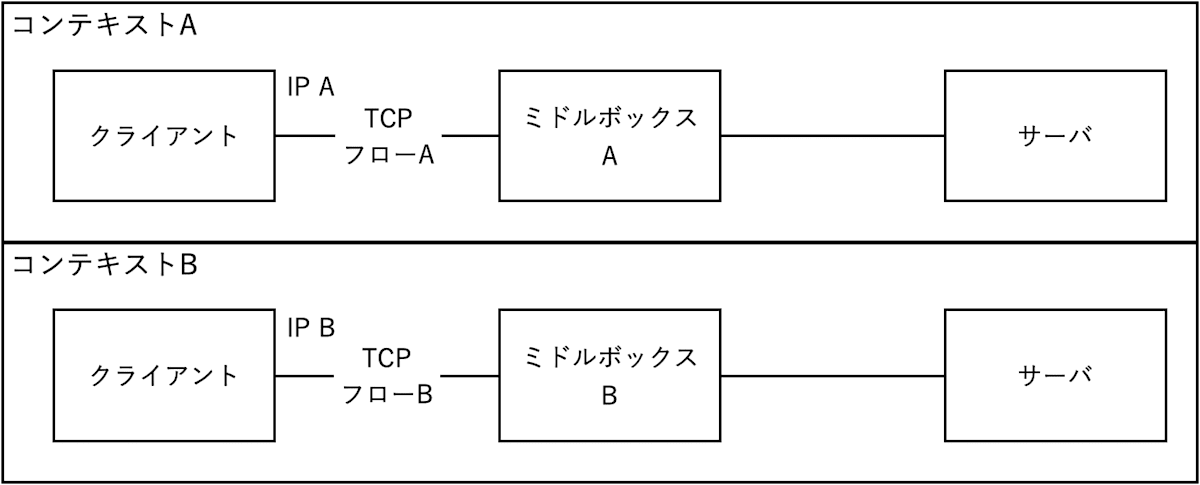
図3: 別々の接続を作ることで別々のコンテキストを生成する図
別々のコンテキストを生成するために別々の接続を使用すると、特定の関係者がコンテキスト間で活動を相関させる能力が低下したり、なくなる可能性がある。しかし、異なるコンテキスト間で共通する任意のレイヤの識別子は、活動を相関させる方法として使用できる。IPアドレス以外にも、他の多くの要素を組み合わせて、特定のデバイスのフィンガープリントを作成できる(メディア・アクセス制御(MAC)アドレス、デバイスのプロパティ、ソフトウェアのプロパティと動作、アプリケーションの状態など)。
2.2. コンテキストの分割
さまざまな分割手法がどのように機能するかを定義して分析するには、分割されるものの境界を確立する必要がある。これがコンテキスト分離の役割である。特に、コンテキスト間でのユーザ固有の情報の相関を防ぐために、分割は、両方の識別子が見えるコンテキストに(クライアント自体以外の)シングル・エンティティが参加しないようにする必要がある。
コンテキストの分離は、例えば、時間の経過、ネットワーク・パスの横断、コード化に基づくなど、さまざまな方法で実現できる。本文書で説明するプライバシー指向のプロトコルは、一般に、より複雑な分割を含むが、通信コンテキストを分割する手法は、依然として同じ手法を採用している。
- 特定の関係者に対する暗号の使用などの暗号化保護により、異なる関係者(暗号保護を解除できる関係者と解除できない関係者)間でコンテキストを分割できる。
- 時間や空間をまたいだ接続の分離により、ネットワーク上のさまざまなアプリケーション・ トランザクションでコンテキストの分割ができる。
これらのテクニックは、コンテキストの分離と組み合わせて使用することが多い。例えば、クライアントとTLS終端サーバ間でTLSを使用してHTTP交換を暗号化すると、クライアントのIPアドレスを見るネットワーク・ミドルボックスがユーザ・アカウント識別子を見ることを防ぐかも知れないが、TLS終端サーバが両方の識別子を観察し、それらを相関させることを防ぐことはできない。そのため、相関を防ぐには、プロキシを使用して、識別子として使用されるクライアントのIPアドレスを隠すなど、コンテキストを分離する必要がある。
2.3. 分割のアプローチ
本文書で説明するすべての分割プロトコルは、暗号化保護や接続分離を使用して個別のコンテキストを作成するが、それぞれが独自のアプローチを持つため、結果としてコンテキストのセットは異なる。これらのプロトコルの多くは新しいものであるため、各アプローチがインターネット全体でどのように大規模に使用できるか、また将来的にどのような新しいモデルが登場するかはまだ分からない。
分割のアプローチに多様性をもたらす要因は複数ある:
- 既存のプロトコル・エコシステムにプライバシー分割を追加すると、コンテキストがどのように構築されるかに要件と制約が課せられる。CONNECTスタイルのプロキシは、プライバシー・コンテキストを認識しないサーバと連携することを目的としており、強力な分離保証を提供するためにより多くの仲介者を必要とする。一方、Oblivious HTTPは、コンテキスト分離に協力するサーバを想定しており、そのためソリューションの全体的な要素数を削減できる。
- 情報交換が双方向でインタラクティブに行われる必要があるかどうかによって、コンテキストをどのように分離できるかが決まる。PPMのメトリック収集のようなユースケースの中には、情報がクライアントからサーバにのみ流れ、クライアントが接続されていなくても機能するものがある。プライバシー・パスは、トークンをキャッシュして再利用できるかどうかによって、インタラクティブになるかならないかが決まるケースの一例である。CONNECTスタイルのプロキシとOblivious HTTPは、しばしば双方向でインタラクティブな通信を必要とする。
- コンテキストをどの程度分割する必要があるかは、クライアントの脅威モデルと、さまざまなプロトコル参加者に対する信頼度によって決まる。例えば、Oblivious HTTPでは、クライアントは特定のアプリケーション固有のゲートウェイにアクセスしていることをリレーが知ることを許可する。クライアントがこの情報でリレーを信頼しない場合、代わりにマルチホップCONNECTスタイルのプロキシ・アプローチを使用でき、このアプローチでは、特定のクライアントが特定のアプリケーションにアクセスしているかどうかを単一の関係者が知ることはない。これは、Torのようなシステムのデフォルトの信頼モデルであり、マルチホップは共謀や関連攻撃によるプライバシー侵害の可能性を下げるために使用される。
3. 分割を使用するプロトコルの調査
以下のセクションでは、プライバシー分割を適用している、IETFの現在進行中の作業について説明する。
3.1. CONNECTプロキシとMASQUE
クライアントとプロキシ間の接続で暗号を使用するとき、HTTPフォワード・プロキシは接続を複数のセグメントに分割することでプライバシー分割を提供する。プロキシ経由のターゲットへの接続自体が暗号化されているとき、プロキシはエンドツーエンドのコンテンツを見ることができない。HTTPは歴史的に、CONNECTメソッドを介したTCPのようなストリームのためのフォワード・プロキシをサポートしてきた。最近では、Multiplexed Application Substrate over QUIC Encryption (MASQUE)ワーキンググループが、トンネリングに基づいてUDP[CONNECT-UDP]やIPパケット[CONNECT-IP]を同様にプロキシ化するプロトコルを開発した。
シングル・プロキシの設定では、クライアントとプロキシの間にトンネル接続があり、クライアントとターゲットの間にエンドツーエンド接続がトンネル化されている。この設定は、図4に示すように、通信を以下のように分割する:
- クライアントからターゲットへの暗号化コンテキスト。これには、HTTPコンテンツなど、ターゲットへのTLSセッション内のエンドツーエンドのコンテンツを含む。
- クライアントからターゲットへのプロキシ・コンテキスト。これは、TLSセッションのようなプロキシにも見えるターゲットと交換されるエンドツーエンドのデータである。
- クライアントとターゲット間のトランスポート・メタデータと、ターゲットへの接続をオープンするためのプロキシへのリクエストを含むクライアントからプロキシへのコンテキスト。そして、
- プロキシからターゲットへのコンテキスト。TCPとUDPのプロキシの場合、プロキシによって追加または修正されたパケット・ヘッダ情報(IPヘッダやTCP/UDPヘッダなど)を含む。

図4: ワンホップのプロキシ・コンテキストの図
2台(またはそれ以上)のプロキシを使用することで、より優れたプライバシーの分割が実現する。特に、2台のプロキシを使用すると、各プロキシはクライアントのメタデータを見ることができるが、ターゲットを見ることができない。また、ターゲットを見ることができるが、クライアントのメタデータは見ることができない。あるいは、どちらも見ることができない。
図5に示す2ホップ・プロキシの場合、単一プロキシの場合について上で説明したコンテキストに加えて、いくつかの方法でコンテキストを変更する:
- クライアントからターゲットへのプロキシ・コンテキストは、第2のプロキシ(ここでは「プロキシB」と呼ぶ)のみを含む。
- 新しいクライアントからプロキシBへのコンテキストが追加される。これは、クライアントからプロキシBへのTLSセッションであり、最初のプロキシ(ここでは「プロキシA」と呼ぶ)からも見ることができる。
- トランスポート・データ(TCPまたはUDP over IP)のみを見るコンテキストは、クライアントからプロキシAへのコンテキスト、プロキシAからプロキシBへのコンテキスト、プロキシBからターゲットへのコンテキストの3つの個別のコンテキストに分離される。

図5: 2ホップ・プロキシ・コンテキストの図
MASQUEで開発されたプロトコルのプロキシ・モードのようなフォワード・プロキシは、暗号化(TLS経由)と接続の分離(次のホップだけを見ることができるプロキシ・ホップ経由)の両方を使用してプライバシー分割を実現する。
3.2. Oblivious HTTPとDNS
Oblivious HTTP Application Intermediation (OHAI)ワーキンググループで開発されたOblivious HTTP[OHTTP]は、リレーシステムを介してHTTP交換にメッセージごとの暗号化を追加する。クライアントは、メッセージの内容を読み取ることができないOblivious Relayを介してOblivious Gatewayにリクエストを送信する。Oblivious Gatewayはメッセージを復号化できるが、クライアントと直接通信したり、IP アドレスなどのクライアントのメタデータを見ることはできない。Oblivious HTTPは、暗号化を行うためにハイブリッド公開鍵暗号化 [HPKE]に依存している。
Oblivious HTTPは、暗号化と接続の分離の両方を使用してプライバシー分割を実現する。
- エンドツーエンドのメッセージは、クライアントとゲートウェイ間で暗号化される。これらの内部メッセージの内容は、クライアント、ゲートウェイ、ターゲットで見ることができる。これがクライアントからターゲットへのコンテキストである。
- クライアントとゲートウェイ間で交換される暗号化されたメッセージはリレーで見ることができるが、リレーはメッセージを復号化できない。これがクライアントからゲートウェイへのコンテキストである。
- クライアント、リレー、ゲートウェイ間のトランスポート(TCPやTLSなど)接続は、クライアントからリレーへのコンテキストとリレーからゲートウェイへのコンテキストという2つの別個のコンテキストを形成する。リレーに多数の別個のクライアントが存在する場合でも、リレーからゲートウェイへの接続はシングル接続になる可能性があることに留意することが重要である。これにより、リレーが提示する仮名が多くのクライアント間で共有されるため、匿名性が向上する。
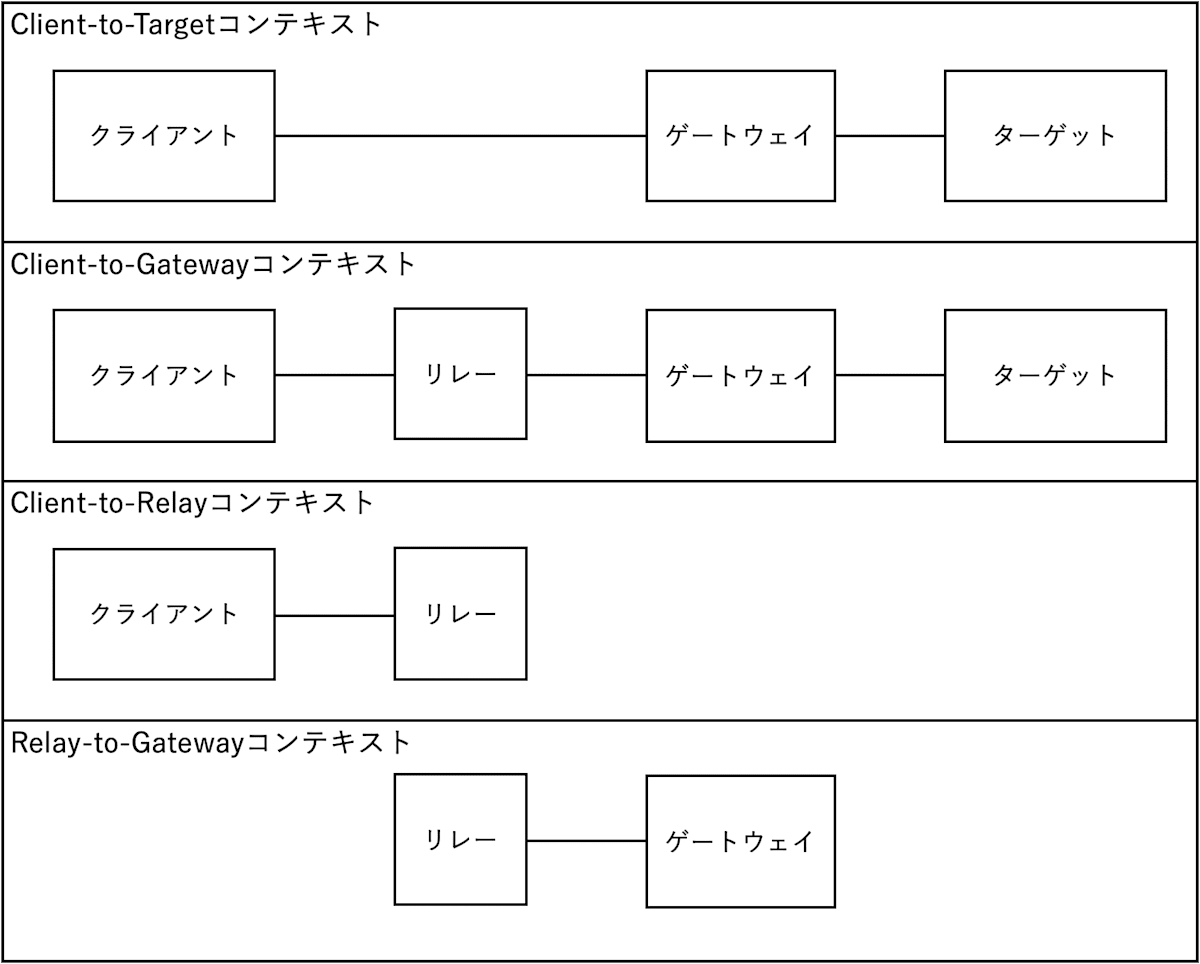
図6: Oblivious HTTPコンテキストの図
Oblivious DNS over HTTPS(ODoH)[ODOH]はOblivious HTTPと同じ原理を適用しているが、DNSメッセージのみで動作する。より一般化されたOblivious HTTPの先駆けとして、同じHPKE暗号プリミティブに依存し、同じ方法で分析できる。
3.3. プライバシー・パス
プライバシー・パスは、Privacy Passワーキンググループで開発されているアーキテクチャ[RFC9576]とプロトコルのセットであり、クライアントがトークンを介して匿名かつリンク不可能な方法で検証証明を提示できるようにするものである。これらのトークンは、もともとクライアントがCAPTCHAを解決したことを証明する方法として設計されたが、他の種類のユーザやデバイスの認証チェックにも適用できる。プライバシー・パスでは、クライアントはトークンを発行するために認証者や発行者とやり取りし、その後、クライアントはオリジン・サーバとやり取りしてそのトークンを交換する。
プライバシー・パスは、暗号化保護(ブラインド署名プロトコルなどの形式)と2つのコンテキストにまたがる接続の分離によってプライバシー分割が実現する。2つのコンテキストとは、クライアントとオリジン(トークンを要求し、受け取るサーバ)間の「償還コンテキスト(redemption context)」と、クライアント、認証サーバ、トークン発行サーバー間の「発行コンテキスト(issuance context)」である。暗号化保護は、発行コンテキストで公開された情報が、引き換えコンテキストで公開された情報から分離されることを保証する。

図7: プライバシー・パスにおけるコンテキストの図
償還コンテキストと発行コンテキストは別々のエンティティが関与する別々の接続であるため、プロトコルのこれらの部分を異なる時間に実行することで、さらに分離することもできる。クライアントは、発行コンテキストを通じてトークンを早期に取得し、後で償還コンテキストで使用するためにトークンをキャッシュできる。これは識別子とデータの分割に役立つ。
[RFC9576]は、オリジン、アテスター、発行者を操作するエンティティがさまざまな展開モデルを説明している。一部のモデルでは、これらはすべて別々のエンティティであり、別のモデルでは、同じエンティティによって操作できる。モデルは分割の有効性に影響を与え、一部のモデル(3つすべてが同じエンティティによって操作される場合など)では、2つのコンテキストでの接続のタイミングが相関していないときと、クライアントが各コンテキストで異なる識別子(異なるIPアドレスなど)を使用するときにのみ、有効な分割を提供する。
3.4. プライバシー保護測定
プライバシー保護測定(PPM)ワーキンググループは、データ集約や収集サーバ(または複数の非共謀サーバ)が、クライアントの個々の測定値を知ることなく集約値を計算することを支援するプロトコルとシステムを開発することを目的としている。分散集約プロトコル(DAP)は、このグループの主要な作業項目である。
高レベルでは、DAPは2つのコンテキストを確立するために、(非共謀サーバ間での秘密共有という形で)暗号保護の組み合わせを使用する:
- クライアントと非共謀集約サーバ間の「アップロード・コンテキスト」(サーバは「ヘルパー」と「リーダー」の役割に分かれている)では、集約サーバはクライアントのアイデンティティを知ることはできるが、個々の測定レポートについては何も知らない。そして、
- コレクタが集計した測定結果を学習し、個々のクライアント・データについては何も学習しない「収集コンテキスト」

図8 : DAPのコンテキストの図
4. プライバシー分割の適用
既存または新しいシステムやプロトコルにプライバシー分割を適用するには、以下の手順が必要である:
- システムまたはプロトコルで使用される、または公開される情報のタイプを識別する。これらの情報の一部は、ユーザを識別したり、他のコンテキストと相関させたりするために使用できる。
- データを分割して、特定のコンテキスト内のユーザを識別または相関可能な情報量を最小限に抑え、そのコンテキストに必要なものだけを含めるようにし、可能な限りコンテキスト間でのデータ共有を防ぐ。
分割に最も影響力を与える情報のタイプは、(a) ユーザ識別情報(アカウント名やIPアドレスを含む)など、リンク可能な情報と、(b) 非ユーザ識別情報(ユーザが生成またはアクセスしたコンテンツを含む)である。これらは、ユーザ識別子と組み合わされた場合、機密性が高くなりがちなである。
このセクションでは、これらの種類の情報を分割するための考慮事項について説明する。
4.1. ユーザ識別情報
ユーザデータはそれ自体がユーザを特定できることもあり、識別子として扱う必要がある。例えば、Oblivious DoHとOblivious HTTPは、クライアントのIPアドレスとクライアントのリクエスト・データを別々のコンテキストに分割することで、クライアント以外のエンティティが両方を分からないようにする。コンテキストをまたがる共謀により、この分割を逆にして、ユーザを特定しない情報がユーザを特定する情報になる可能性がある。例えば、QUICを使用するCONNECTプロキシ・システムでは、QUIC接続IDはランダムに生成されるため、本質的にユーザを特定しない([QUIC]のセクション5.1)。しかし、クライアントのIPアドレスのようなユーザを特定する情報を持つ他のコンテキストと組み合わされた場合、QUIC接続IDがユーザを特定する情報になる可能性がある。
いくつかの情報は、ネットワークの場所やハードウェアとソフトウェアにおけるプロトコルの実装の詳細など、クライアントのユーザ・エージェントに固有のものが含まれている。この情報は、ユーザを特定する情報を作成するために使われることがあり、「フィンガープリンティング」と呼ばれるプロセスである。アプリケーションやシステムの制約によっては、プライバシーの文脈でフィンガープリンティングを防ぐことができない場合がある。その結果、フィンガープリンティング情報がユーザを識別しないユーザデータと組み合わされると、本来は無害なユーザデータがユーザ識別情報に変わる可能性がある。
4.2. クライアント識別子の選択
プライバシー分割に使用されるコンテキストで使用されるクライアント識別子の選択は、分割の有効性に大きな影響を与える。識別子の選択によって、分割の価値が損なわれることも、向上することもある。通常、各コンテキストには何らかの形式のクライアント識別子が含まれる。この識別子は、クライアントIDに直接関連付けられることもあるが、仮名やランダムな1回限りの識別子であることもある。
複数のコンテキストで同じクライアント識別子を使用すると、さまざまなコンテキストを同じクライアントにリンクバックされる可能性があるため、分割の有効性が部分的または全体的に損なわれる可能性がある。例えば、クライアントがセクション3.1で説明されているようにプロキシを使用して接続を分離しているが、異なるコンテキストで2つのサーバに認証するために同じ電子メールアドレスを使用している場合、それらのアクションは同じクライアントにリンクバックされる可能性がある。これによって、プロキシによって達成された分割のすべてが損なわれるわけではないが(ネットワーク・パスに沿ったコンテキストは、クライアントIDとどのサーバにアクセスしているかをまだ関連付けることはできない)、分割の全体的な効果は減少する。
可能であれば、コンテキストごとに一意なクライアント識別子を使用することで、分割特性が向上する。例えば、クライアントは、ログインする必要がある各サーバで、アカウント識別子として一意の電子メールアドレスを使用することができる。ネットワークごとのMACアドレスのランダム化[RANDOM-MAC]、接続間や時間経過に伴う複数の一時IPアドレスの使用[RFC8981]、及びHTTP Web Pushのためのサブスクリプションごとの一意の識別子の使用[RFC8030]などに見られるように、同じアプローチが多くのレイヤに適用できる。
4.3. 不正確または不完全な分割
プライバシー分割は、不正確または不完全に適用される可能性がある。コンテキストにユーザを特定する情報が必要以上に含まれていたり、コンテキスト内の一部の情報が意図した以上にユーザを識別する可能性がある。さらに、ユーザ識別情報を複数のコンテキストに分割する場合は、コンテキストを増やすと、共謀しないことを信頼する必要があるエンティティの数が増える可能性があるため、慎重に行う必要がある。しかし、分割を慎重に適用すれば、クライアントのプライバシー体制を改善するのに役立つ。
プライバシー分割を適用したシステムやプロトコルの結果として得られるプライバシーの評価と適格性は、存在するコンテキストと各コンテキストにおけるユーザ識別情報のタイプに依存する。このような評価は、システムやプロトコルがプライバシーの姿勢を改善する方法を特定するのに役立つ。例えば、クライアントのIPアドレスとクライアントのクエリの両方を含む単一のコンテキストを生成するDNS over HTTPS [DOH]を考えてみる。プライバシー分割の1つの応用としてODoHがある。ODoHはクライアントのIPアドレスとクライアントのクエリを含む2つのコンテキストを生成する。
4.4. コンテキスト内の情報の選択
プライバシー分割の潜在的な用途を認識するには、使用されているコンテキスト、コンテキストで公開される情報、コンテキストで公開される情報の意図を特定する必要がある。残念ながら、与えられたコンテキストにどのような情報を含めるかを決定することは、簡単な作業ではない。原則として、コンテキストに含まれる情報は目的に適合していなければならない。そのため、開発される新しいシステムやプロトコルは、コンテキストで公開されるすべての情報が、可能な限り少ない目的しか果たさないようにすることを目指す必要がある。最初からこの原則に基づいて設計することで、システムやプロトコルのユーザが不注意にコンテキストで利用可能な情報を骨抜きにした場合に生じる問題を軽減することができる。コンテキストで利用可能な情報を骨抜きにしたレガシー・システムは、実際には変更が難しいかも知れない。例えば、既存の多くの不正使用防止システムは、クライアントのIPアドレスなどのクライアント識別子とクライアント・データを組み合わせて価値を提供する。このようなシステムで、クライアントの識別子を決定しないようにコンテキストを分割するには、不正使用防止問題に対する新しいソリューションが必要である。
5. プライバシー分割の限界
プライバシー分割は、ユーザのプライバシーを向上させることを目的としているが、前述のように、プライバシー・リスクの管理に役立つ多くのアーキテクチャ・ツールの1つに過ぎない。その利点の限界を理解するには、問題のシステムをより包括的に分析する必要がある。このような分析は、ツールが正しく適用されているかどうかを判断するのにも役立つ。特に、プライバシー分割の価値は、以下に限定されないが、さまざまな要因に依存する:
- コンテキスト間の共謀の禁止
- 各コンテキストで公開される情報の種類
以下のセクションでそれぞれについては詳しく説明する。
5.1. 共謀による違反
プライバシー分割により、クライアント、つまり分割の責任を負うエンティティだけが、すべてのユーザ固有の情報を独立して結び付けることができることを保証する。他のエンティティは、コンテキスト間で互いに共謀しない限り、すべてのユーザ固有情報を結び付ける方法を個別に知ることはできない。したがって、共謀しないことは、プライバシー分割がエンドユーザに意味のあるプライバシーを提供するための基本的な要件である。特に、ユーザがさまざまな関係者と持つ信頼関係は、結果としてユーザのプライバシーに影響を与える。
例として、Oblivious HTTP(OHTTP)を考えてみる。Oblivious Relayはクライアントのアイデンティティは知っているが、クライアントのデータは知らないし、Oblivious Gatewayはクライアント・データは知っているが、クライアントのアイデンティティは知らない。Oblivious RelayとGatewayが共謀すれば、転送中のリクエストを観察するだけで、リクエストとレスポンスのトランザクションごとにクライアントのアイデンティティとデータを結び付けることができる。
現在のところ、技術的なプロトコル対策によって、2つのエンティティが共謀していないことを保証することはできない。2つのエンティティが直接共謀していなくても、両エンティティが他の関係者に情報を公開した場合、その情報が組み合わされないことを保証することはできない。しかし、実際に共謀が起こるリスクを軽減するために適用できる緩和策はいくつかある:
- 分割に関与するエンティティ間で、ログの記録やデータ共有を禁止するポリシーや契約上の合意がなされ、ポリシーが遵守されていることを検証するための監査を行う。ログの記録が必要な場合(サービスの運用のためなど)、ログ記録されたデータは共謀に利用されないように最小限に抑え、匿名化する必要がある。
- 共謀やデータ共有をより困難にするプロトコル要件。
- 分割やコンテキストをさらに追加することで、アイデンティティを回復するのに十分な数の関係者と共謀することがますます困難になる。
5.2. 不十分なまたは不正確な分割による違反
プライバシー分割の不十分な適用や不適切な適用は、ユーザへのメリットを減少させたり、打ち消したりする可能性がある。特に、意味のあるプライバシーには不十分な、または不適切な方法で分割を適用する可能性がある。例えば、スタック内の1つのレイヤで分割を行うと、スタック内の別のレイヤにある結び付け可能な情報が考慮されない可能性がある。プライバシーの侵害は、さまざまな方法で分割の失敗から発生する可能性がある。そのうちのいくつかについては、以下のセクションで説明する:
5.2.1. アプリケーション情報からの違反
アプリケーション層が適切に分割できない場合、ネットワーク層での分割は不十分になる可能性がある。例として、ブラウザのテレメトリ・システムでクライアントの識別情報を隠す目的で使用されるOHTTPを考えてみる。このようなテレメトリ・システムのレポートは、クライアント固有のテレメトリ・データ(特定のブラウザ・インスタンスに関する情報など)とクライアント識別情報(クライアントのメールアドレス、場所、IPアドレスなど)の両方を含む可能性がある。OHTTPがリレーを介してクライアントのIPアドレスをサーバから分離しても、サーバはクライアントのテレメトリ・レポートから直接この情報を得ることができる。
5.2.2. ネットワーク情報からの違反
ネットワーク層での分割が不適切な場合もある。例として、TLS Encrypted Client Hello (ECH)[TLS-ESNI]とVPNの両方について考えてみる。ECHは暗号保護(暗号化)を利用して権限のないパーティから情報を隠すが、クライアントとサーバ(2つのエンティティ)のどちらもユーザ固有のデータをユーザ固有の識別子(IPアドレス)に結び付けることができる。同様に、VPNはエンドサーバから識別子を隠すが、VPNサーバはクライアントとサーバの両方の識別子を見ることができる。プライバシー分割を適用すると、関係する各パーティからID(誰)とユーザの行動(何)の両方が明らかになるのを避けるため、少なくとも2つの追加エンティティが必要になる。
5.2.3. サイドチャネルからの違反
プライバシー分割を適用することで、意図的に公開される情報以外にも、サイドチャネルを通じて意図せずに情報が明らかになる可能性もある。例えば、セクション3.1で説明した2ホップ・プロキシ構成において、プロキシAはクライアントとプロキシB間のTLSデータを見たり、プロキシしたりする。プロキシBが見る情報を直接知ることはないが、プロキシされる暗号データのタイミングやサイズなどのメタデータを通じて情報を知る。トラフィック分析を利用すれば、そのようなメタデータからさらに多くの情報(場合によっては、プロキシAが見るはずのないアプリケーション・データを含む)を学習できる。プライバシー分割は、このような攻撃がなくなるわけではないが、実際に攻撃を実行するために必要なコストは増加する。このトピックの詳細については、セクション7を参照のこと。
5.2.4. 分割の識別
不十分な分割に起因するユーザのプライバシー侵害は、簡単に軽減できるように思えるかも知れないが、意味のあるプライバシーのためにどの情報を分割する必要があるかを厳密に判断し、望ましい特性を実現する方法でそれを実装することは、依然として未解決の問題のままである。要するに、ある情報セットが特定のユーザについて「あまりにも多くの」情報を明らかにしているかどうかを判断することは難しく、分割の実装が意図したとおりに機能しているかどうかを判断することも同様に難しい。データが「プライベート」または「匿名」と想定されているが、後から考えてみると、個々のクライアントに結び付けることができるような情報を明らかにし過ぎていた、という証拠はたくさんある。現実世界でのこのような例の詳細については、 [DataSetReconstruction]と[CensusReconstruction]を参照のこと。
6. 分割の影響
通信プロトコルにプライバシー分割を適用すると、通信パターンが大幅に変わる。例えば、トラフィックをサービスに直接送信するのではなく、基本的にすべてのユーザ・トラフィックが一連の仲介者を介してルーティングされ、プロセス中にエンドツーエンドのラウンドトリップが増える可能性がある(システムとプロトコルによる)。これは、以下で説明するいくつかの実用的な影響がある。
-
サービス運用や管理上の課題: 通常、ネットワークで受動的に観察される情報や、サービス・プロバイダに意図せず公開されたメタデータは利用できなくなる。例えば、アプリケーションのレート制限やDDoS緩和など、既存のセキュリティ手順に影響を与える可能性がある。現在導入されているネットワーク管理手法は、保証や正確性に欠ける一般的なトラフィックによって公開される情報に依存することが多い。
プライバシー分割は、プライバシーを保護しながら各エンティティと情報を積極的に交換し、意図せずに明らかにされた限られた情報群から得られる情報に依存するのではなく、特定のタスクや機能に必要な情報を正確に要求することで、これらの管理手法を改善する機会を提供する。これらの情報は、利用可能であることが保証されず、将来削除される可能性がある。
-
さまざまなパフォーマンスへの影響とコスト: コンテキスト分離の方法によっては、プライバシー分割がアプリケーションのパフォーマンスに影響を与える可能性がある。例えば、プライバシー・パスは、トークンを発行してから引き換えるまでにエンドツーエンドのラウンドトリップが発生するため、パフォーマンスが低下する。対照的に、CONNECTプロキシのようなシステムはパフォーマンスを低下させるように思われるかもしれないが、プロキシ間のパスの高度に最適化された性質により、パフォーマンスが向上することが多い。
パフォーマンスの低下は、プロトコルや展開がプライバシー分割を適用しない理由の1つとなり得る。例えば、HTTPS接続の再利用([HTTP2]のセクション9.1.1)により、クライアントが1つのオリジンに対して作成された既存のHTTPSセッションを使用して、別のオリジンとやり取りすることができる(元のオリジンがこれらの代替オリジンに対して権限を持つことが条件)。接続を再利用することで、接続確立のコストは節約できるが、サーバはこれらの2つ以上のオリジンでのクライアントの活動を結び付けることができるようになる。プライバシー分割を適用すれば、これを防ぐことができるが、通常はパフォーマンスを犠牲にすることになる。
一般的に、パフォーマンスとプライバシーのトレードオフは、ゼロサムゲームとして扱われることが多いが、実際にはそうではないことが多い。プライバシーとパフォーマンスの関係は、アプリケーションの特性やネットワーク・パスの特性など、関連するさまざまな要因によって変化する。
-
攻撃対象領域の拡大: たとえ情報が共謀していない関係者間で適切に分割されていたとしても、結果としてエンドユーザにもたらされる影響は必ずしもポジティブなものになるとは限らない。例えば、OHTTPを例に挙げて、Oblivious Gatewayに実装上の欠陥があり、すべての復号化リクエストが公開されている場所または他の危険な場所に不適切に記録されるという架空のシナリオを考えてみる。さらに、これらのリクエストの宛先であるターゲット・リソースには、このような実装上の欠陥がないものとする。この欠陥のあるOblivious GatewayでOHTTPを使用してターゲット・リソースとやり取りするアプリケーションは、ユーザ識別情報から切り離された形ではあるものの、ユーザのリクエスト情報が公開されるリスクがある。しかし、ターゲット・リソースとやり取りするのに、OHTTPを使用しないアプリケーションでは、このような漏洩のリスクはない。
-
集中化: プロトコルとシステム、および望ましいプライバシー特性によっては、分割を使用することで、選択された信頼できる参加者群に集中化が本質的に強制される可能性がある。例えば、OHTTPがエンドユーザのプライバシーに与える影響は、通常、特定のOblivious Relayの背後に存在するユーザの数に比例して増加する。つまり、Oblivious Relayを介して転送されたリクエストに関連付けられたクライアントを Oblivious Gatewayが特定する確率は、Oblivious Relayの背後に存在する可能性のあるクライアントの数が増えるにつれて減少する。このトレードオフにより、Oblivious Relayの集中化が促進される。
7. セキュリティに関する考慮事項
セクション5では、実際のプライバシー分割の限界について説明し、プライバシー分割がどの程度プライバシーの改善をもたらすかを理解するための総合的な分析を提唱している。分割は、正しく適用すれば、エンドユーザのプライバシーの姿勢を改善するのに役立ち、技術的、社会的、またはポリシー的な手段によるセキュリティ侵害を難しくする。例えば、トラフィック分析[FINGERPINT]やタイミング分析などのサイドチャネルは依然として可能であり、権限のないエンティティが、自分が参加していないコンテキストに関する情報を知ることができる。これらのタイプの攻撃に対する提案されている緩和策、例えばアプリケーション・トラフィックのパディングや偽のトラフィックの生成などは非常にコストがかかる可能性があるため、実際には適用されない。とはいえ、プライバシー分割は、脅威ベクトルを、ユーザ固有の情報に直接アクセスできるものから、エンドユーザのプライバシーを侵害するために計算リソースなど、より多くの労力を必要とするものへと移行させる。
8. IANAに関する考慮事項
この文書にはIANAアクションはない。
9. 参考文献
[CensusReconstruction] United States Consensus Bureau, "The Census Bureau's Simulated Reconstruction-Abetted Re-identification Attack on the 2010 Census", May 2021, <https://www.census.gov/data/academy/webinars/2021/disclosure-avoidance-series/simulated-reconstruction-abetted-re-identification-attack-on-the-2010-census.html>.
[CONNECT-IP] Pauly, T., Ed., Schinazi, D., Chernyakhovsky, A., Kühlewind, M., and M. Westerlund, "Proxying IP in HTTP", RFC 9484, DOI 10.17487/RFC9484, October 2023, <https://www.rfc-editor.org/info/rfc9484>.
[CONNECT-UDP] Schinazi, D. and L. Pardue, "HTTP Datagrams and the Capsule Protocol", RFC 9297, DOI 10.17487/RFC9297, August 2022, <https://www.rfc-editor.org/info/rfc9297>.
[DataSetReconstruction] Narayanan, A. and V. Shmatikov, "Robust De-anonymization of Large Sparse Datasets", IEEE Symposium on Security and Privacy, DOI 10.1109/sp.2008.33, May 2008, <https://doi.org/10.1109/sp.2008.33>.
[DECOUPLING] Schmitt, P., Iyengar, J., Wood, C., and B. Raghavan, "The decoupling principle: a practical privacy framework", Proceedings of the 21st ACM Workshop on Hot Topics in Networks, DOI 10.1145/3563766.3564112, November 2022, <https://doi.org/10.1145/3563766.3564112>.
[DOH] Hoffman, P. and P. McManus, "DNS Queries over HTTPS (DoH)", RFC 8484, DOI 10.17487/RFC8484, October 2018, <https://www.rfc-editor.org/info/rfc8484>.
[FINGERPINT] Goldberg, I., Wang, T., and C. A. Wood, "Network-Based Website Fingerprinting", Work in Progress, Internet-Draft, draft-irtf-pearg-website-fingerprinting-01, 8 September 2020, <https://datatracker.ietf.org/doc/html/draft-irtf-pearg-website-fingerprinting-01>.
[HPKE] Barnes, R., Bhargavan, K., Lipp, B., and C. Wood, "Hybrid Public Key Encryption", RFC 9180, DOI 10.17487/RFC9180, February 2022, <https://www.rfc-editor.org/info/rfc9180>.
[HTTP2] Thomson, M., Ed. and C. Benfield, Ed., "HTTP/2", RFC 9113, DOI 10.17487/RFC9113, June 2022, <https://www.rfc-editor.org/info/rfc9113>.
[ODOH] Kinnear, E., McManus, P., Pauly, T., Verma, T., and C.A. Wood, "Oblivious DNS over HTTPS", RFC 9230, DOI 10.17487/RFC9230, June 2022, <https://www.rfc-editor.org/info/rfc9230>.
[OHTTP] Thomson, M. and C. A. Wood, "Oblivious HTTP", RFC 9458, DOI 10.17487/RFC9458, January 2024, <https://www.rfc-editor.org/info/rfc9458>.
[QUIC] Iyengar, J., Ed. and M. Thomson, Ed., "QUIC: A UDP-Based Multiplexed and Secure Transport", RFC 9000, DOI 10.17487/RFC9000, May 2021, <https://www.rfc-editor.org/info/rfc9000>.
[RANDOM-MAC] Zuniga, JC., Bernardos, CJ., Ed., and A. Andersdotter, "Randomized and Changing MAC Address state of affairs", Work in Progress, Internet-Draft, draft-ietf-madinas-mac-address-randomization-12, 28 February 2024, <https://datatracker.ietf.org/doc/html/draft-ietf-madinas-mac-address-randomization-12>.
[RFC6973] Cooper, A., Tschofenig, H., Aboba, B., Peterson, J., Morris, J., Hansen, M., and R. Smith, "Privacy Considerations for Internet Protocols", RFC 6973, DOI 10.17487/RFC6973, July 2013, <https://www.rfc-editor.org/info/rfc6973>.
[RFC8030] Thomson, M., Damaggio, E., and B. Raymor, Ed., "Generic Event Delivery Using HTTP Push", RFC 8030, DOI 10.17487/RFC8030, December 2016, <https://www.rfc-editor.org/info/rfc8030>.
[RFC8981] Gont, F., Krishnan, S., Narten, T., and R. Draves, "Temporary Address Extensions for Stateless Address Autoconfiguration in IPv6", RFC 8981, DOI 10.17487/RFC8981, February 2021, <https://www.rfc-editor.org/info/rfc8981>.
[RFC9576] Davidson, A., Iyengar, J., and C. A. Wood, "The Privacy Pass Architecture", RFC 9576, DOI 10.17487/RFC9576, June 2024, <https://www.rfc-editor.org/info/rfc9576>.
[TLS-ESNI] Rescorla, E., Oku, K., Sullivan, N., and C. A. Wood, "TLS Encrypted Client Hello", Work in Progress, Internet-Draft, draft-ietf-tls-esni-18, 4 March 2024, <https://datatracker.ietf.org/doc/html/draft-ietf-tls-esni-18>.
承認時のIABメンバー
この文書の発行が承認された時点でのインターネット・アーキテクチャ委員会のメンバーは以下のとおりである:
ドゥルブ・ドーディ
ラース・エッゲルト
ウェス・ハーダカー
カレン・ジェニングス
マロリー・ノデル
スレシュ・クリシュナン
ミルヤ・クーレヴィント
トミー・ポーリー
アルバロ・レタナ
デビッド・シナジ
クリストファー・A・ウッド
チン・ウー
ヤオ・ジャンカン
謝辞
マーティン・トムソン、エリオット・リア、マーク・ノッティンガム、ニールス・テン・オーヴァー、ヴィットリオ・ベルト、アントワーヌ・フレサンクール、カレン・ジェニングス、ドゥルヴ・ドーディらのレビューとフィードバックに感謝する。
著者のアドレス
ミルヤ・クーレヴィント
メールアドレス: mirja.kuehlewind@ericsson.com
トミー・ポーリー
メールアドレス: tpauly@apple.com
クリストファー・A・ウッド
メールアドレス: caw@heapingbits.net
更新履歴
- 2024.8.5
Discussion