RFC 9330: 低遅延、低損失、スケーラブルなスループット(L4S)のインターネット・サービス: アーキテクチャ
要旨
本文書では、インターネット・アプリケーションにおいて、低いキューイング遅延、低い輻輳損失、スケーラブルなスループット制御を実現可能にするL4Sアーキテクチャについて説明する。L4Sは、キューイング遅延の根本原因はキュー自体にあるのではなく、送信側のキャパシティを求める輻輳制御にあるという洞察に基づいている。L4Sアーキテクチャを使用すると、すべてのインターネット・アプリケーションは、実質的なキューイング遅延を引き起こす輻輳制御アルゴリズムから移行することができ(ただし、その必要はないが)、代わりに非常に少ないキューイングでキャパシティを求めることができる新しい種類の輻輳制御を採用できる。これらは、ネットワークから明示的輻輳通知(ECN)の修正した形で支援される。この新しいアーキテクチャにより、アプリケーションは低遅延と高スループットの両方を実現できる。
本アーキテクチャは、主に増分導入に関係し、この新しいL4S輻輳制御を、共有ネットワークにおいて「クラシック」輻輳制御と共存できるようにするメカニズムを定義している。その目的は、通常、クラシックの性能に影響を与えずに、L4Sの遅延とスループットを大幅に向上させる(まれに悪化することもある)ことを目指している。
本文書の位置付け
本文書はインターネット標準化過程の仕様書ではない。情報提供を目的として公開する。
本文書はインターネット・エンジニアリング・タスク・フォース(IETF)の成果物である。IETFコミュニティのコンセンサスを表すものである。文書は公開レビューを受けており、インターネット・エンジニアリング・ステアリング・グループ(IESG)によって公開が承認されている。IESGによって承認されたすべての文書が、あらゆるレベルのインターネット標準の候補となるわけではない。RFC 7841のセクション2を参照のこと。
文書の現在の位置付け、正誤表、フィードバックの提供方法に関する情報は、https://www.rfc-editor.org/info/rfc9330 で入手できる。
著作権表示
Copyright (c) 2023 IETFトラストおよび文書の著者として特定された人物。無断転載を禁じる。
本文書は、BCP 78および文書の発行日において有効なIETF文書に関するIETFトラストの法的規定(https://trustee.ietf.org/license-info)に従うものとする。これらの文書には、本文書に関するあなたの権利と制限が記載されているため、注意深く確認して欲しい。文書から抽出されたコード・コンポーネントには、トラスト法的条項のセクション4.eに記載されている改訂BSDライセンスのテキストを含まなければならず、改訂BSDライセンスに記載されているように保証なしで提供する。
1. はじめに
ボトルネックとなるリンク(家庭のインターネット・アクセスやWi-Fiなど)のすべてのトラフィックは、低遅延を好むアプリケーション(双方向ウェブ、ウェブサービス、音声、会話ビデオ、双方向ビデオ、双方向の遠隔臨場、インスタント・メッセージング、オンラインおよびクラウド・レンダリング・ゲーム、リモート・デスクトップ、クラウドベースのアプリケーション、クラウド・レンダリングの仮想現実または拡張現実、機械や産業プロセスのビデオ支援リモート制御)が一般的になってきている。過去10年ほどの間に、キャッシュやサーバをユーザの近くに置くなど、伝播遅延を軽減するために多くのことが行われてきた。しかし、キューイングは断続的ではあるものの依然として遅延の主要な要素であり続けている。例えば、最新のアクティブ・キュー管理(AQM) [COBALT] [DOCSIS3AQM]であっても、数百ミリ秒のスパイクは珍しいことではない。アクセス・ネットワークのボトルネックにおけるクラシックAQMは、通常、単独フローの鋸歯状のバッファリングを行うように構成されている。これは、長時間続くフロー中に、予想されるベース(無負荷)パスの遅延[BufferSize]に対して、ネットワーク全体のピーク遅延はおよそ2倍になる可能性がある。双方向アプリケーションの場合、さらに長い再送信遅延につながるため、低損失も重要である。
アクセス・ネットワークのビットレートが先進国で一般的なレベルに達すると、遅延に対処しなければ、リンク容量を増やしても効果が小さくなることが実証されている[Dukkipati06] [Rajiullah15]。したがって、目標は、キューイング遅延が非常に短く、損失が非常に少なく、スケーラブルなスループットを備えたインターネット・サービスである。非常に低いキューイング遅延とは、平均で1ミリ秒(ms)未満、99パーセンタイルで約2ミリ秒未満を意味する。エンドツーエンドの遅延が50ミリ秒[Raaen14]、あるいは20ミリ秒[NASA04]を超えると、より要求の厳しい双方向アプリケーションは不自然に感じるようになる。したがって、不要な遅延のばらつきを除去することで、これらのアプリケーションの到達距離(快適に使用できる距離)を増加させるか、強化された処理に使用できる追加の遅延量を提供する。この文書では、これらの目標を達成するためのL4Sアーキテクチャについて説明する。
Diffserv(ディフサーブ)は、一部のパケットに対して、他のパケットを犠牲にして、完全優先転送(EF)[RFC3246]を提供するが、ボトルネックにあるトラフィックのすべて(または大部分)が同時に低遅延を必要とする場合、この違いは生じない。対照的に、すべてのトラフィックがL4Sの場合でも、L4Sはうまく機能する。つまり、一部のトラフィック・フローを他のトラフィック・フローよりも優先する設定や管理上の負担(トラフィック・ポリシングやトラフィック・コントラクト)を一切必要としないサービスである。
キューイング遅延は、性能を断続的に低下させる[Hohlfeld14]。この現象は、i) 十分に大きな容量を求める(TCPなど)フローがボトルネック・リンク(通常はアクセス・ネットワーク内にある)で、ユーザ・トラフィックと並行して通信している場合、または ii) 低遅延アプリケーション自体が大容量を要求する、あるいは適応レート・フロー(双方向ビデオなど)の場合に発生する。このような場合、ネットワーク事業者がL4Sを導入する動機付けとなるには、L4Sによる性能向上が十分なものでなければならない。
アクティブ・キュー管理(AQM)は、負荷がかかった状態のキューイングに対するソリューションの一部である。AQMはすべてのトラフィックの性能を向上させるが、問題の根本に対処せずにネットワークを変更するだけでは、キューイング遅延を削減できる量には限界がある。
問題の根本は、TCPやQUIC [RFC9000]など、他のトランスポートで使用されている標準的な輻輳制御 (Reno [RFC5681])あるいは互換性のあるバリアント (CUBIC [RFC8312]など)の存在にある。これらの Renoフレンドリーな輻輳制御には「クラシック」という用語を使用する。従来の輻輳制御は、比較的大きな鋸歯状のキュー占有変動が生じる。したがって、ネットワーク事業者が単純にAQMを浅いキューで動作するように設定することで、キューイング遅延を削減しようと試みると、クラシック輻輳制御は各鋸歯状の底部のリンク利用率が著しく低下することになる。これらの鋸歯の持続時間も、フローレートの規模に応じて長くなってくる(セクション5.1および[RFC3649]を参照)。
送信ホストがクラシック輻輳制御を「スケーラブル」な代替制御に置き換えた場合、適切なAQMがネットワークに導入されると、上記のすべての双方向アプリケーションの負荷下での性能が大幅に改善することが実証されている。DSLやイーサネット・リンク上でデータセンターTCP(DCTCP) [RFC8257]とデュアルキュー結合AQM[RFC9332]を使用する、以下に挙げる解決策を例に取ると、高負荷時のキューイング遅延はリンク利用率[L4Seval22] [DualPI2Linux]を失うことなく、99パーセンタイルでおよそ1~2ミリ秒となる(他のリンクタイプについては、セクション6.3を参照)。これは、クラシック輻輳制御と最新のAQM(Flow Queue CoDel [RFC8290]、Proportional Integral Controller Enhanced (PIE)[RFC8033]、あるいはDOCSIS PIE [RFC8034])を使用した場合の平均5~20ミリ秒、99パーセンタイルで約20~30ミリ秒[DualPI2Linux]と比較している。
L4Sは増分導入ができるよう設計されている。既存のベストエフォート型サービス[DualPI2Linux]と並行して、ボトルネック・リンクにL4Sサービスを導入できるため、送信側のスタックがアップデートされると、すぐに変更されていないアプリケーションがそのサービスを使い始めることができる。アクセス・ネットワークは通常、各サイト(家庭、小規模企業、またはモバイル・デバイスなど)のボトルネックとなる1つのリンクを想定して設計されているため、このリンクのどちらかまたは両端に配備すれば、それぞれの方向でほぼすべての利点が得られる筈である。TCP[ACCECN]のような一部のトランスポート・プロトコルでは、より正確なフィードバックを提供するために、送信者は受信者が適切にアップデートされていることを確認する必要がある。一方、QUIC[RFC9000]やデータグラム輻輳制御プロトコル(DCCP)のような最近のトランスポート・プロトコル[RFC4340]は、すへて受信側が常に確認する。
本文書は、L4Sアーキテクチャについて説明する。これは3つのコンポーネントで構成される。その3つとは、L4Sトラフィックをクラシック・トラフィックから分離するネットワーク支援、ネットワーク要素がL4Sトラフィックを識別するためのプロトコル機能、L4S輻輳制御のためのホスト支援である。このプロトコルは、明示的輻輳通知(ECN)の実験的な変更として、[RFC9331]の中で別途定義されている。本文書では、コンポーネント部分と、低遅延、低損失、スケーラブルなインターネット・サービスを提供するためにどのようなやり取りをするかを説明し、その根拠を示す。また、上で簡単にまとめたように、増分導入のアプローチについても詳しく説明する。
1.1. 文書の手引き
本文書では、L4Sアーキテクチャを3つに分けて説明する。まず、セクション2の簡単な概要では、非常に大まかなアイデアを示し、主要なコンポーネントを最小限の理論的根拠で説明する。これは、セクション3に続く用語の定義に文脈を与え、この文書の残りの部分の構造を説明するためのものである。次にセクション4では、若干の理論的根拠を示しながら、各コンポーネントについて詳しく説明しつつも、その理由というより、むしろ、アーキテクチャがどんなものかを説明する。最後に、セクション5では、ソリューションの各要素が選ばれた理由(セクション5.1 )、これらの選択が他のソリューションと異なる理由 (セクション5.2)を説明する
アーキテクチャを説明した後、セクション6では、設計の動機となったアプリケーションとユースケース、アーキテクチャをさまざまなリンク・テクノロジに適用する際の課題、さまざまな増分導入モデル (2つの主要な導入トポロジ、増分導入と既存のアプローチとのさまざまな相互作用を含む)を説明することで、その適用性を明確にしている。本文書は、セクション8でのトラフィック・ポリシングや他のセキュリティに関する考慮事項についての広範な説明を含む、通常お決まりのテールピースで締め括られている。
2. L4Sアーキテクチャの概要
以下では、L4Sアーキテクチャの3つの主要コンポーネントの概要、1) 送信ホスト上のスケーラブルな輻輳制御、2) ネットワークのボトルネックとなるAQM、3) それらの間のプロトコルを説明する。
ただし、まず理解すべき重要な点は、低遅延はネットワークによって提供されるものではないという点である。低遅延は、L4S送信者が使用するスケーラブルな輻輳コントローラの慎重な動作によって実現される。ネットワークは主に、慎重に動作するL4Sトラフィックの低遅延を、既存のクラシック動作のトラフィックに必要な長いキューイング遅延から分離する役割を担っている。ネットワークはまた、キューの増加をトランスポートに通知する方法も変更する。これは明示的輻輳通知(ECN)プロトコルを使用するが、クラシックAQMによくある平滑化遅延を発生させることなく、キューの増大の始まりを即座に通知する。ECNのサポートはL4Sに不可欠であるため、送信者はどのパケットがL4Sで、どのパケットがクラシックかをネットワークが識別するためのプロトコルとして、ECNフィールドを使用する。
1)ホスト:
スケーラブルな輻輳制御はすでに存在する。それらはRenoやCUBICのようなクラシック輻輳制御を使用してスケーリング問題を解決している。TCP輻輳制御が1988年に初めて設計されて以来、フローレートは十分に長く続くと仮定すれば、セクション5.1及び[RFC3649]の例に示されているように、輻輳信号 (損失であれ、ECNマークであれ)の後の回復までに数百回ものラウンドトリップ (およびその増加) が必要になる。したがって、キューイングと利用率の制御は非常に緩慢になり、わずかなかく乱(新しいフローの開始など)によって、高いレートの達成が妨げられる。
スケーラブルな輻輳制御では、ある輻輳信号から次の輻輳信号までの平均時間(回復時間)は、フローレートが変化しても、他のすべての要素が等しい限り不変のままである。これにより、フローレートに関係なく、キューイングと利用率に対する同程度の制御が維持されるだけでなく、高いスループットがかく乱に対してより堅牢になることが保証される。(制御された環境で)最も広く使用されているスケーラブルな制御はDCTCP[RFC8257]で、Windows Server Editions (2012年以降)、Linux、およびFreeBSDに実装され、導入されている。DCTCPはそのままでも広域のラウンドトリップ時間(RTT)をはるかに超えても十分に機能するが、ほとんどの実装は、データセンターのような管理された環境の外で使用するのに必要な安全機能を欠いている(セクション6.4.3参照)。したがって、スケーラブルな輻輳制御をTCPや他のトランスポート・プロトコル (QUIC、ストリーム制御伝送プロトコル (SCTP)、RTP/RTCP、RTPメディア輻輳回避技術 (RMCAT) など)に実装する必要がある。実際、この文書が起草されてから公開されるまでの間に、次のスケーラブルな輻輳制御が実装された: Prague over TCP and QUIC [PRAGUE-CC] [PragueLinux]、RMCAT SCReAM コントローラ[SCReAM-L4S]のL4Sバリアント、TCPとQUICを対象としたBottleneck Bandwidth and Round-trip propagation time (BBRv2) [BBRv2]のL4S ECN部分。
2)ネットワーク:
L4Sトラフィックは、クラシック・トラフィックのキューイング遅延から分離する必要がある。アプリケーション・フロー毎の1つのキュー(FQ) がこれを実現する1つの方法である(例: FQ-CoDel [RFC8290])。しかし、キューをわずか2つ使用するだけでも十分であり、ネットワーク内で常に可能とは限らないトランスポート層ヘッダを検査する必要はない(セクション5.2を参照)。キューが2つしかない場合、それぞれのキューが同時に使用しているフローの数を調べずに、各キューにどれだけの容量をスケジュールすべきかを知ることは不可能に思うかもしれない。また、アクセス・ネットワークの容量を恣意的に2つに分割することは望ましくない。Dual-Queue Coupled AQMは、この問題に対する複雑さを最小限に抑えるソリューションとして開発された。これは、帯域幅ではなく遅延を分割する「半透」膜のように機能する。そのため、2つのキューは帯域幅の優先順位付けではなく、クラシック動作からL4S動作に移行するためのものである。
セクション4では、 L4Sのフローごとのキュー(FQ)とDualQバリアントがどのように動作するかについて概要を説明し、[RFC9332]では DualQ Coupled AQMフレームワークについて完全な説明を行う。L4S AQMでは、特定のマーキング・アルゴリズムは必須ではない。[RFC9332]の付録には、実装および評価された非・規範的な例と、推奨されるデフォルトのパラメータ設定が示されている。L4Sの実験によって、パラメータ設定と一連のマーキング・アルゴリズムを制限する必要があるかどうかについての知識が向上することが期待される。
3)プロトコル:
送信ホストは、ネットワークがL4Sパケットとクラシック・パケットを別々の処理に分類できるように、識別子でL4Sパケットとクラシックのパケットを区別する必要がある。L4S識別子仕様[RFC9331]では、すべての代替案には妥協が含まれるが、ECNフィールドのECT(1) および Congestion Experienced (CE)コードポイントは実行可能なソリューションだと結論付けている。すでに説明したように、ネットワークはECNを使用して、キューの増大が始まったことをトランスポートに即座に通知する。
3. 用語
クラシック輻輳制御:
フローレート[RFC5033]に著しい悪影響を与えることなく、標準的なReno[RFC5681]と共存できる輻輳制御動作。クラシック輻輳制御のスケーリング問題については、セクション5.1と[RFC3649]で例を示して説明している。
スケーラブルな輻輳制御:
ある輻輳信号から次の輻輳信号までの平均時間(回復時間)が、他のすべての要素が等しい場合に、フローレートが変化しても一定である輻輳制御。例えば、DCTCPは、フローレートに関係なく、1ラウンドトリップあたり平均2つの輻輳信号を出す。最近開発された他のスケーラブルな輻輳制御、例えば、Relentless TCP [RELENTLESS]、Prague for TCP and QUIC [PRAGUE-CC] [PragueLinux]、 BBRv2 [BBRv2] [BBR-CC]、リアルタイム・メディア用の SCReAMのL4Sバリアント[SCReAM-L4S] [RFC8298]もそうである。詳細については、[RFC9331]のセクション4.3を参照のこと。
クラシックサービス:
クラシックサービスは、Reno[RFC5681](Reno自体、CUBIC [RFC8312]、Compound TCP [CTCP]、および TFRC [RFC5348]など)と共存するすべての輻輳制御動作を対象としている。「クラシックキュー」という用語は、クラシックサービスを提供するキューを意味する。
低遅延、低損失、スケーラブルなスループット(L4S) サービス:
「L4S」サービスは、DCTCP[RFC8257]から派生したPrague輻輳制御[PRAGUE-CC]のようなスケーラブルな輻輳制御アルゴリズムのトラフィックを対象としている。L4Sサービスは、Pragueだけでなく、より一般的なトラフィックを対象としている。これにより、上に挙げた例 (Relentless、SCReAMなど)のように、Pragueと同様のスケーリング特性を持つ一連の輻輳制御を進化させることができる。「L4Sキュー」という用語は、L4Sサービスを提供するキューを意味する。
「クラシック」または「L4S」という用語は、「キュー」、「コードポイント」、「識別子」、「分類」、「パケット」、「フロー」などの他の名詞を修飾することもできる。例えば、L4Sパケットは、L4S輻輳制御から送信されるL4S識別子を持つパケットを意味する。
クラシックサービスとL4Sサービスはどちらも、一部の応答しないトラフィックや応答性の低いトラフィックにも対処できるが、L4Sの場合、そのレートはキューを作らない程度に滑らかであるか、十分に低くなければならない(例: DNS、Voice over IP (VoIP)、ゲーム同期データグラムなど)。
Renoフレンドリー:
[RFC5681]でTCPに対して定義されている標準的なReno輻輳制御に適したクラシック・トラフィックの一部。TFRC仕様[RFC5348]は、「フレンドリー」が「一般的に同じ条件下でTCPフローの送信レートの2倍以内」と定義していることを間接的に示唆している。ここでは、「TCPフレンドリー」の代わりに「Renoフレンドリー」を使用する(前者は不正確)。なぜなら、TCPプロトコルは現在、非常に多くの異なる輻輳制御が使われており、RenoはQUIC[RFC9000]のような非・TCPトランスポートで使用されているためである。
クラシックECN:
オリジナルの明示的輻輳通知(ECN)プロトコル[RFC3168]では、ネットワーク内で生成された場合でも送信者が応答した場合も、ECN信号はドロップと同等に扱う必要がある。
L4Sでは、2ビットのIP-ECNフィールドの4つのコードポイントに使用される名前が、ECN仕様[RFC3168]で定義されたもの、つまり、Not-ECT、ECT(0)、ECT(1)、CEから変更しない。ここで、ECTはECN-Capable Transportを表し、CEはCongestion Experiencedを表す。CEコードポイントでマーク付けされたパケットは、「ECNマーク付き」と呼ばれ、文脈からECNが明らかな場合は単に「マーク付き」と呼ばれることもある。
サイト:
家庭、モバイル機器、小規模企業、キャンパスなどで、ネットワークのボトルネックは通常、サイトへのアクセスリンクである。すべてのネットワーク構成がこのモデルに当てはまるわけではないが、これは有用で広く適用可能な一般化である。
トラフィック・ポリシング:
パケットを破棄したり、より低いサービスクラスに移行させたりしてトラフィックを制限する(「トラフィック・シェーピング」と呼ばれる遅延の導入とは異なる)ことをいう。ポリシングには、平均レートやバーストサイズの制限が含まれる場合がある。平均フローレートではなく、キューイングの制限に重点を置いたポリシングを、この文書では「輻輳ポリシング」、「遅延ポリシング」、「バースト・ポリシング」、あるいは「キュー保護」と呼ばれている。それ以外の場合は、レート・ポリシングという用語を使用する。
4. L4Sアーキテクチャの構成要素
L4Sアーキテクチャは、次の3つのサブセクションの要素で構成される。
4.1. プロトコルの仕組み
L4Sアーキテクチャは、a) 以前使用した識別子の割り当て解除、b) 同じ識別子の再割り当て、c) オプションの追加識別子を含む:
a. スケーラブルな輻輳制御の重要な側面は、明示的輻輳信号の使用である。クラシックECN[RFC3168]では、ECN信号がネットワークで生成されるときも、ホストによって応答されるときも、ドロップと同等に扱われることが求められる。L4Sは、ネットワークとホストが破棄よりも深刻度が低い各ECN信号のよりきめ細かい意味をサポートする必要がある。L4S信号は、
- 頻度を大幅に増やすことができ、
- キュー内の変動を平滑化するために必要な大幅な遅延を発生させることなく、即座に信号を送ることができる。
L4Sを実現にするには、標準化課程のクラシックECN仕様[RFC3168]をアップデートし、L4Sパケットが「破棄に相当(equivalent-to-drop)」制約から外れるようにする必要があった。[RFC8311]は[RFC3168] (および他の特定の標準化トラックのRFC)の特定の要件を緩和するための標準化課程のアップデートであり、L4Sに対して提案された実験的な変更への道を切り開くものである。また、ECT(1)コードポイントは、以前は実験的なECNノンス[RFC3540]として割り当てられていたが、[RFC8311]では、このコードポイントを再び利用できるようにするために、「歴史的」と再分類されている。
b. [RFC9331]は、L4Sパケットをクラシック・パケットとは別の処理に分類する識別子としてECT(1)を使用することを規定している。これは、[RFC4774]の代替ECN処理を識別するための要件を満たす。
CEコードポイントは、L4S処理とクラシック処理の両方で発生した輻輳を示すために使われる。これにより、パス上にあるクラシックAQMがECT(0)パケットをCEとしてマークしてしまう可能性があるという懸念が生じる。そして、これらのパケットは誤ってL4Sキューに分類することになる。[RFC9331]の付録Bでは、このことが悪影響を及ぼすためには、5つの起こり得ない事態がすべて同時に発生しなければならない理由を説明しており、たとえそうなったとしても、偽の再送が発生する可能性はごくわずかである。
c. ネットワーク事業者は、VoIP、オンラインゲームを同期するための低レートのデータグラム、比較的低レートのアプリケーション限定トラフィック、DNS、Lightweight Directory Access Protocol(LDAP)など、ある種の応答しない非・L4Sトラフィックがキューを作らない程度にスムーズで低いレートであるとみなされる場合、L4Sキューに含めたいと思うかも知れない。このトラフィックは特定の識別子、例えば、Expedited Forwarding (EF)[RFC3246]、非・キュー構築(NQB)[NQB-PHB]などの低遅延Diffservコードポイント、または事業者固有の識別子でタグ付けする必要がある。
4.2. ネットワーク・コンポーネント
L4Sアーキテクチャは、ネットワーク・コンポーネントでフロー操作を必要とせずに、低遅延を実現することを目的としている。それにもかかわらず、このアーキテクチャはフロー・ソリューションを排除するものではない。次の箇条書きで、既知の構成を説明する。a) 一方のキューにL4S AQMがあり、もう一方のキューにクラシックAQMを持つDualQ結合AQM、b) 各キューにクラシックとL4S AQMのインスタンスを持つフローごとのキュー、c) フローごとのAQMを持つが、フローごとのキューを持たないデュアルキュー:
a. デュアル・キュー結合AQM(図1に示す)は、前述の「半透」膜の特性を次のように実現する。
- 遅延の分離: 2つの独立したキューが、クラシック・トラフィックが完全な利用率を維持するために必要とする、大きなキューからL4Sキュー遅延を分離する。
- 帯域幅プーリング: 2つのキューは、あたかも1つの帯域幅プールであるかのように動作し、スケジューラがフローを識別する必要がなく、どちらのタイプのフローもほぼ等しいスループットが得ることができる。これは、各キューにAQMを配置することで実現されるが、クラシックAQMは、2つのクラスの輻輳制御からの一貫した応答を保証する方法で、両方のキューに輻輳信号を提供する。具体的には、クラシックAQMはそれ自身のキュー内の輻輳に基づいてドロップ/マーク確率を生成し、それを自身のキュー内のパケットをドロップ/マークし、L4Sキュー内のマーキング確率に影響を与える。2つのキュー間の輻輳シグナリングの結合の強さは、L4Sフローを遅くして、クラシック・フローに適切な量の容量を残すのに十分である(同じキューを共有する同じタイプのトラフィックであった場合と同様に)。
そして、L4Sトラフィックは、与えられた優先度をすべて使用するのに十分な量のトラフィックを提供していないため、スケジューラはL4Sのキューに優先度(より高い優先度の入力の「1」で示される)をもってサービスを供することができる。したがって:
- 短いタイムスケール(サブラウンドトリップ)での遅延の分離の場合、L4Sキューの優先順位付けにより、バーストがすぐに消滅させることで低遅延を守る。
- しかし、より長いタイムスケール(ラウンドトリップ以上)での帯域プーリングにおいて、クラシックキューはL4Sトラフィックに対して、帯域幅に関してはどちらも優先されないようにするため、同等かつ逆の圧力を発生させる。つまり、L4Sの優先順位付けとクラシックAQMのマーキングの結合の間の緊張が、結果としてフローごとの公平性をおおよそ保つことになる。
一部の実装では、永続的なL4Sトラフィックの優先順位付けがしばらくの間、クラシックキューがデッドロックするのを防ぐために、優先順位を厳密ではなく条件付きにすることが望ましい(DualQ仕様[RFC9332]の付録Aを参照)。
クラシック・トラフィックが存在しない場合、L4Sキュー自身のAQMが動作する。非常に浅いキューで輻輳マーキングを開始するため、L4Sトラフィックは非常に低いキューイング遅延を維持する。
ECN仕様[RFC3168]のセクション7およびAQM推奨事項[RFC7567]のセクション4.2.1で推奨しているように、どちらかのキューが継続的に過負荷になった場合、ECN対応パケットのドロップが導入される。さまざまなアプローチによるトレードオフは、DualQ仕様[RFC9332]のセクション4.2.3で説明している(ここでの図には示されていない)。
デュアル・キュー結合AQMは、設計者が多様なアイデアを自由に実装できるように、2つのキューで使用する特定のAQMを指定せずに、可能な限り一般的に規定されている[RFC9332]。この文書の情報付録には、2つの異なる特定のAQMアプローチの擬似コード例が示されている。1つはDualPI2 (デュアルPIスクエアードと発音)[DualPI2Linux]と呼ばれるもので、PIEのPI2バリアントを使用するものと、Curvy REDと呼ばれるランダム初期検出(RED)のゼロ構成バリアントを使用するものである。PIEに基づくDualQ結合AQMも、低遅延DOCSIS[DOCSIS3.1]向けに仕様化され、実装されている。
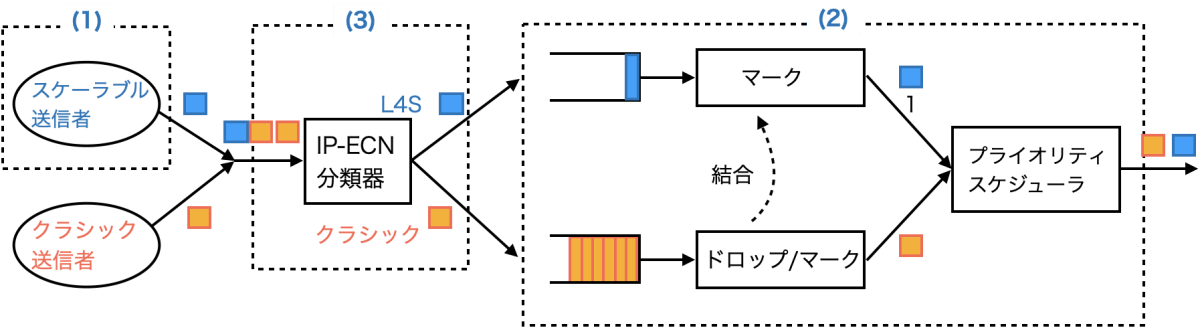
(1) スケーラブルな送信ホスト
(2) 別のネットワークキューに分離
(3) パケット識別プロトコル
図1: L4S DualQ Coupled AQMソリューションのコンポーネント
b. フロー単位のキューとAQM: FQ-CoDelやFQ-PIEのようなフロー単位のキューを持つスケジューラをL4Sに使用することができる。例えば、FQ-CoDelシステムの各キュー内には、CoDel AQMと同様に、データセンタでの使用をサポートするために、即時の(平滑化されていない)浅い閾値でECNマーキングを行うオプションも存在する(FQ-CoDel仕様[RFC8290]のセクション5.2.7を参照)。Linuxでは、浅い閾値がECT(1)パケットにのみ適用されるように変更されている[FQ_CoDel_Thresh]。そして、フロー単位のキューにNot-ECTまたはECT(0)パケットのフローがある場合には、クラシックAQM(例: CoDel)が適用される。一方、もしキューにECT(1)パケットのフローがある場合には、より浅い(通常はミリ秒以下)閾値が適用される。加えて、ECT(0)およびNot-ECTパケットは、(例えば、VPNなど)共通のフロー識別子を共有する場合、それらが混在するのを避けるため、ECT(1)およびCEパケットとは別のフローキューに分類される可能性がある。
c. デュアルキューでありながらフロー単位のAQM: 分離のためにデュアルキューを使用することもできるが、(デュアル・キュー結合AQMの結合されたキュー単位のマーキングの代わりに)フローレートを制御するためにフローごとのマーキングを使用する。2つのキューのうち1つは、L4Sパケットを分離するためのもので、ECNコードポイントによって分類される。フローレートは、フロー固有のマーキングによって制御できる。マーキングのポリシー上の目的は、フローレートを区別すること(例えば[Nadas20]のように、フロー単位の「値」の付加的なシグナリングを必要とする)、あるいはフローレートを均等化すること(おそらく、Approx Fair CoDel [AFCD] [CODEL-APPROX-FAIR]と同様の方法だが、キューが1つではなく2つある)。
「DualQ」という用語は、マーキングがキュー単位なのかフロー単位なのかを明言することなく、大まかに使用される場合はいつでも、キュー単位のマーキングを持つデュアルキューAQMを意味することに注意する。
4.3. ホスト・メカニズム
L4Sアーキテクチャには、次に列挙するエンドホストに2つの主要なメカニズムがある:
a. 送信側のスケーラブルな輻輳制御: セクション2では、スケーラブルな輻輳制御とは、フローレートが変化しても、1つの輻輳信号から次の輻輳信号までの平均時間(回復時間)が変化せず、他のすべての要素が等しいものと定義している。DCTCPは最も広く使われている事例である。これは、管理された環境で現在使用されているプロトコルの情報記録として文書化されている[RFC8257]。公衆インターネット上で使用可能なスケーラブルな輻輳制御のための安全性と性能の改善リストが作成された([RFC9331]の付録Aのいわゆる「Prague L4S要件」を参照)。他者への危害のリスクに関連するサブセットは、[RFC9331]のセクション4で規範的要件として取り込まれている。TCP Prague[PRAGUE-CC]は、これらの要件に対処するためのリファレンス実装としてLinuxに実装されている[PragueLinux]。
TCP以外のトランスポート・プロトコルは、Renoに影響を与えないよう設計されたさまざまな輻輳制御を使用する。それらがL4Sサービスを使用できるようになる前に、スケーラブルな輻輳応答を実装するようにアップデートされる必要があり、それはECT(1)コードポイントを使用することで示されなければならない。スケーラブルなバリアントは、より最近のトランスポート・プロトコル(例えばQUIC)のために検討中であり、BBRv2[BBRv2] [BBR-CC]のL4S ECN部分は、とりわけTCPやQUICトランスポートのために意図されたスケーラブルな輻輳制御である。また、RTP経由で転送されるメディア用に、RMCAT SCReAMコントローラ[RFC8298]のL4Sバリアント[SCReAM-L4S]が実装されている。
L4S ECN仕様[RFC9331]のセクション4.3では、スケーラブルな輻輳制御をより詳細に定義し、L4Sスケーラブル輻輳制御が準拠すべき要件を規定している。
b. 一部のトランスポート・プロトコルのECNフィードバックは、すでにL4S(特にDCCP[RFC4340]とQUIC[RFC9000])に対して十分に細分化されている。しかし、他はアップデートが必要か、アップデート中である:
- TCPの場合、ECNのフィードバック・プロトコルは、クラシックECN[RFC3168]の「ECNマークはドロップと等価である」という前提が組み込まれているため、スケーラブルTCPでは使用できない。したがって、TCPレシーバの実装をアップグレードする必要がある[RFC7560]。TCPのより正確なECNフィードバック(AccECN)を標準化し実装する作業が進行中である[ACCECN] [PragueLinux]。
- ECNフィードバックは、現在は廃止されているSCTPの2番目の仕様[RFC4960]の付録で大まかに説明されているだけで、より完全な仕様は期限切れの文書[ECN-SCTP]で提案されていた。SCTPがL4Sに対応するには、新しい設計を実装して導入する必要がある。
- RTPの場合、[RFC6679]に十分なECNフィードバックが定義されていたが、[RFC8888]には最新の標準化過程の改善が定義されている。
5. 理論的根拠
5.1. なぜこれらが主要コンポーネントなのか?
明示的輻輳信号(プロトコル):
明示的輻輳信号は、L4Sアプローチの重要な一部である。対照的に、ドロップを輻輳信号として使用することは、ドロップが障害(少ない方が良い)であると同時に有用な信号(多いほど良い)であるため、緊張を生む:
-
明示的輻輳信号は、障害なく厳密な制御を維持するために、ラウンドトリップごとに何度も使用することができる。負荷が重いとき、さらに多くの明示的な信号を適用することで、どのような負荷であってもキューを短く保つことができる。対照的に、クラシックAQMは、キューを短く保つためには、高負荷時に非常に高いパケットドロップを取り込まなければならない。ECNを使用することで、L4S輻輳制御の鋸歯状の減少を小さくすることができるため、鋸歯が増えることによる信号の増加を心配することなく、より頻繁に動作点(operating point)に戻ることができる。その結果、小さな振幅の鋸歯は、空のキューと非常に浅いマーキング閾値(公衆インターネットでは〜1ミリ秒)の間に収まるため、キューの遅延変動は過小利用のリスクなしに、非常に小さくできる。
-
キューの変動を追跡するために、明示的輻輳信号を即座に発することができる。L4Sは、平滑化をネットワークからホストにシフトする。ネットワークは、どのフローのラウンドトリップ時間(RTT)も知らない。そのため、もし、ネットワークが平滑化の責任を負うのであれば(クラシックのアプローチと同じように)、ワーストケースのRTTを想定しなければならず、そうしないとRTTの長いフローが不安定になる。そのため、クラシックの輻輳信号は100~200ミリ秒遅延する。対照的に、各ホストは自身のRTTを知っている。そのため、L4Sアプローチでは、ホストは各フローを自身のRTTで平滑化することができ、厳密に必要な遅延(通常はわずか数ミリ秒)を超える平滑化遅延は発生しない。また、ホストは、例えばフローの開始時など、適切であれば、平滑化遅延を導入しないことを選択することもできる。
明示的輻輳信号を「ドロップと同等」(クラシックECN[RFC3168]で要求されたように)と考えなければならない場合、ドロップは信号であると同時に障害でもあるため、上記のどちらも実現できない。そのため、ドロップは過度に頻繁にあってはならないし、すぐにドロップすることもできない。あまりに多くのドロップがキュー内の一時的な揺らぎによるものであり、後から振り返ってみれば、パケットをドロップする理由にはならないものだったことが判明してしまうからである。したがって、L4S AQMでは、L4Sキューはドロップと等価ではないECNの新しいL4Sバリアントを使用し(L4S ECN仕様 [RFC9331]のセクション5.2を参照)、クラシックキューはクラシックECN[RFC3168]またはドロップのいずれかを使用する。どちらも依然として同等であることに変わりはない。
クラシックECNが標準化される前、ECNマークにドロップとは異なる意味を与えるさまざまな提案があった。しかし、別の意味のいずれかに同意する特別な理由がなかったため、「ドロップと同等」(equivalent to drop)が唯一の妥協点だった。[RFC3168]には次のような記述が含まれている:
すべてのエンドノードがECN-Capableである環境では、CEコードポイントを設定するための新しい基準や、CEパケットに対するエンドノードの反応に関する新しい輻輳制御メカニズムを開発することができる。しかし、これは研究課題であるため、本文書では扱わない。
遅延の分離 (ネットワーク):
L4S輻輳制御ではキュー遅延が低く抑えられるが、クラシック輻輳制御では過小利用を避けるためにRTTのオーダーのキューを必要とする。1つのキューに2つの長さを持たせることはできない。したがって、L4Sトラフィックは別のキュー(例: DualQ)あるいは複数のキュー(例: FQ)に分離する必要がある。
結合された輻輳通知:
DualQ Coupled AQMのように2つのキュー間の輻輳通知を結合することは、必ずしも必要不可欠なものではないが、ネットワーク・スケジューラによってオーバーライドされるのではなく、送信者がパケット単位でレートを決定できるようにするための単純な方法である。別の方法は、ネットワーク・スケジューラが各アプリケーション・フローのレートを制御する方法がある(セクション5.2の説明を参照)。
L4Sパケット識別子 (プロトコル):
ネットワーク内に少なくとも2つの処理が存在する場合、ホストはどちらの処理を使用するかを区別するため、IP層で識別子を必要とする。
スケーラブルな輻輳通知:
ホストのスケーラブルな輻輳制御により、フローレートに関係なく、ネットワークからの信号頻度が高く維持されるため、状態が安定している場合はキュー遅延の変動を小さくすることができ、それ以外の場合はレートが利用可能な容量の変動を可能な限り迅速に追従することができる。
低損失:
L4Sの懸念は遅延だけではない。名前の「低損失」の部分は、L4SがECNを使用することにより、一般的に輻輳損失がゼロであることを示す。そうでなければ、特に短いフローでは、再送遅延[RFC2884]のために、損失自体が遅延の原因となる。
スケーラブルなスループット:
名前の「スケーラブルなスループット」の部分は、スケーラブルな輻輳制御のフローごとのスループットが無限に拡張され、Renoフレンドリーな輻輳制御アルゴリズム[RFC3649]で差し迫ったスケーリングの問題を回避する必要があることを示している。TCP輻輳回避が1988年に最初に開発されたとき、それが高帯域幅遅延製品には拡張できないことが知られていた([TCP-CA]の脚注6を参照)。現在、WANの距離にわたる通常のブロードバンド・フローレートは、すでにクラシックRenoの輻輳制御の拡張範囲を超えている。そのため、TCPの「拡張性の低い」CUBIC[RFC8312]とCompound [CTCP]バリアントの導入が成功した。しかし、これらは現在、スケーリングの限界に近づいている。
例えば、各鋸歯のピーク時の最大RTTが30ミリ秒のシナリオを考えてみる。Renoのパケットレートは1,250パケット/秒から10,000パケット/秒(1500 Bパケットで15から120Mb/秒)に8倍スケールアップするため、輻輳イベントから回復する時間も422ミリ秒から3.38秒に8倍比例して増加する。各輻輳イベントから回復するのに数秒かかるのは、輻輳制御にとって明らかに問題である。CUBIC[RFC8312]は拡張性を低くするために開発されたが、スケーリングの限界に近づいている。同じ最大RTTが30ミリ秒の場合、120Mb/秒では、CUBICはまだ完全にRenoフレンドリーモードのままなので、回復に約4.3秒かかる。しかし、フローレートが再び8倍の960Mb/sに拡大すると、真のCUBICモードに入り、回復時間は12.2秒になる。それ以降、さらに8倍に拡大するたびに、CUBICの回復時間は2倍になる(8の立方根は2であるため)。例えば、7.68Gb/sの場合、回復時間は24.3秒になる。対照的に、DCTCPやPragueのようなスケーラブルな輻輳制御は、平均して1往復あたり2つの輻輳信号を発生するが、これはどのようなフローレートでも不変であり、動的制御を非常に厳密に保つ。
[BDPdata]によると、本稿執筆時点(2021年)における世界の平均的な一つのダウンロード・フローは、2020年の世界の平均固定アクセス容量が103Mb/sで、2019年のCDNへの平均ベースRTTが25~34ミリ秒だった。国ごとのデータの平均は、インターネット・ユーザ人口によって重み付けされている(世界中で収集されたデータの品質は必然的にばらつきがあるが、この文書では結果が二次資料と十分に比較できることを再確認している)。したがって、CUBICは単独のフローがたとえ長く続いたとしても、鋸歯の減少から回復するのにかかる時間は、せいぜい約200往復(5秒)程度である。これは、すべての人がAQMを使用すると仮定しているため、「せいぜい」と表現しているが、実際には、テールドロップの場合、負荷時のRTTは AQMの少なくとも2倍であり、Renoフレンドリーなフローの回復時間はRTTの2乗に依存するため、ほとんどのユーザは依然として(おそらく肥大化した)テールドロップ・バッファを持っている。
輻輳制御のスケーリングに関する研究は、TCPをトランスポートとして開始する傾向があるが、上記は他のトランスポート(SCTPやQUICなど)や、弾力性の低いアルゴリズム(RMCATなど)を除外することを意図したものではなく、これらはすべて同じまたは類似の開発を採用する傾向がある。
5.2. L4Sが既存のアプローチに追加するもの
以下のアプローチはすべて、L4Sと同じ問題空間の一部を扱っている。それぞれのケースにおいて、L4Sは相互に排他的な代替手段ではなく、それらを補完または改善することが示されている:
Diffserv:
Diffservは、重要なトラフィックに対する帯域幅の割り当て問題と、遅延に敏感なトラフィックに対するキューイング遅延の問題に対処している。このうち、L4Sはもっぱらキューイング遅延の問題のみに対処している。重要なトラフィックが優先順位を必要とする場合(例えば、商業的な理由や重要なインフラのトラフィックを保護するため)、Diffservは依然として必要である -- [L4S-DIFFSERV]を参照。それにもかかわらず、L4Sアプローチは各Diffservクラス内のすべてのトラフィックに対して低遅延を実現することができる(デフォルトのDiffservクラスが1つだけある場合を含む)。
また、Diffservは、ボトルネックリンク上のトラフィックの小さなサブセットが低遅延を要求する場合にのみ、遅延の利点を提供することができる。すでに説明したように、1つのサイト(家庭、中小企業、モバイル機器など)で同時に使用されるすべてのアプリケーションが低遅延を要求する場合には効果がない。対照的に、L4Sはすべてのトラフィックに対して機能するため、一部のパケットを他のパケットよりも優先することに関連する管理上の負担(トラフィック・ポリシングやトラフィック・コントラクト)は必要ない。このような管理上の負担がなくなることで、L4Sはエンドツーエンドで導入される可能性は高くなるはずである。
特に、ネットワークがどのパケットを優先すべきかを特定するエンドシステムを信頼できない場合、ネットワークはパケットをDiffservクラスに自ら割り当てる。しかし、フロー識別子の検査やアプリケーション署名のより深い検査のようなネットワークで利用できる技術は、IP[RFC8404]より上の層の暗号化とは必ずしも相性が良くない。このような場合、ユーザはプライバシーかサービス品質(QoS)のどちらかを選択できるが、両方を選択することはできない。
Diffservと同様に、L4S識別子はIPヘッダにある。しかし、Diffservとは対照的に、L4S識別子は特定の品質レベルの要求や必要性を伝えるものではない。むしろ、ネットワークが必要に応じて客観的に検証できる特定の動作(スケーラブルな輻輳応答)を約束している。これは、低遅延がホスト全体の動作に依存するのに対し、帯域幅の優先順位はネットワークの動作に依存するためである。
最新のAQM:
PIEやFQ-CoDelのようなクラシック・トラフィック向けのAQMは、AQMをまったく使用しない場合に比べ、キューイング遅延を大幅に削減する。L4Sは、これらのAQMを補完するためのものであり、AQMを可能な限り広く導入する必要性から目を逸らすべきではない。というのも、問題の根本原因はホストにあり、クラシック輻輳制御は大きな鋸歯状のレート変動を使用するため、AQMだけではリンク使用率を大幅に低下させることなくキューイング遅延を大幅に削減することはできない。L4Sアプローチは、ホストが鋸歯状の振幅を最小限に抑えることで、遅延と利用率の間のこの緊張を解決する。シングルキューのクラシックAQMでは、次の2つの理由により、ホストが小さな鋸歯を使用するには不十分である。i) キューは一度に1つの長さしか持てないため、より大きな振幅のクラシック鋸歯用に設計されたAQMでは、より小さな鋸歯では遅延が小さくならない。ii) 非常に小さい鋸歯は、より頻繁な鋸歯を意味するため、L4SフローはクラシックAQMを高レベルのECNマーキングに導き、クラシックフローにとっては重度の輻輳として認識され、結果としてレートが大幅に低下する。(セクション6.4.4を参照)。
フローごとのキューイングまたはマーキング:
同様に、FQ-CoDelやUpper Fair CoDel [AFCD]のようなフロー単位のアプローチは、L4Sアプローチと互換性がないわけではない。しかし、フロー単位のキューイングだけでは十分ではない。これは、あるフローのキューイングを他のフローから分離するだけで、それ自体からは分離するわけではない。フローごとの実装には、スケーラブルな輻輳制御のサポートを追加する必要がある。これは、LinuxのFQ-CoDelに対してすでに行われている([RFC8290]のセクション 5.2.7と[FQ_CoDel_Thresh]を参照)。この単純な修正がなければ、FQ-CoDelのようなフロー単位のAQMは、非常に低遅延と高帯域幅の両方を必要とするアプリケーション、例えばリモート手順のビデオベースの制御や双方向のクラウドベースのビデオなど(下記注1参照)を依然としてサポートできないままである。
フロー単位の技術はL4Sと互換性がないわけではないが、DualQという代替手段を持つことは重要である。なぜなら、エンドツーエンド(レイヤ4)のフローをネットワーク(レイヤ3または2)で処理することは、一部の重要なエンドツーエンド機能が妨げられるからである。例えば:
a. FQ-CoDelのようなL4Sのフロー単位の形態は、プライバシーと機密性を確保するためのトランスポート層識別子の完全なエンドツーエンドの暗号化(UDP上のDTLSではなく、IPsecまたは暗号化されたVPNトンネルなど)とは互換性がない。なぜなら、エンドツーエンドのトランスポート・フロー識別子にアクセスするためのパケット検査を必要とするためである。
対照的に、DualQ形式のL4Sは、IP層よりも深い検査を必要としない。したがって、事業者が DualQアプローチを採用する限り、ユーザは非常に低いキュー遅延と完全なエンドツーエンド暗号化[RFC8404]の両方を利用できる。
b. L4S のフロー単位の形式では、ネットワークが各アプリケーション・フローの相対速度の制御を引き継ぐ。ネットワークによって、一部のフローが他のフローよりも速くなるのを防ぐことができるという利点があると考える人もいる。また、アプリケーションが輻輳信号を通じて他のユーザのニーズを考慮しながらレートを制御できることは、インターネットの本質的な魅力の一部であると考える人もいる。彼らは、これにより、興味深いレート動作を備えたアプリケーションの進化が可能になったと主張している。そのため、例えば次のような興味深いレート動作をするアプリケーションを発展させることができたと主張している。例えば、i) 常に同じビットレートを維持することを強制されるのではなく、均等なシェアを中心に変化する可変ビットレートの動画や、ii) 容量を等しいシェア[LEDBAT_AQM]よりも少なく使用するエンドツーエンドのスカベンジャー動作[RFC6817]などである。
L4Sアーキテクチャは、「マーケット」が決定できるように両方をサポートするため、IETFはどちらかのアプローチを優先させる必要はない。それにもかかわらず、「1つのことをうまくこなすように」 (Do one thing and do it well)[McIlroy78]の精神に基づき、DualQオプションは、フローレート制御の問題を予断することなく低遅延を提供する。その後、必要であれば、フローレート・ポリシングを個別に追加することができる。スケジューリングとは対照的に、ポリサーはある時点までアプリケーションの制御を許可するが、あるフローが別のフローを完全に枯渇させるのを防ぐために、ネットワークが介入するポイントを設定することができる。
注記:
- フローごとのキュー内で自らが引き起こしたキューイング遅延はカウントされるべきではないと思われるかも知れない。なぜなら、もし遅延がネットワーク内になければ、それは単に送信側に移るだけだからだ。しかし、最新の適応型アプリケーション、例えば、HTTP/2[RFC9113]やいくつかの双方向のメディア・アプリケーション(セクション6.1を参照)は、他の転送の進行状況に応じて他のオブジェクトの優先順位をシャッフルすることで、低遅延のオブジェクトをローカル送信キューの先頭に維持することができる(例えば、[lowat]を参照)。一旦、オブジェクトをネットワークに解放すると、シャッフルすることはできない。
代替バックオフECN(ABE):
ここでも、L4SはABEの代替ではなく、より低いキューイング遅延を取り入れる補完機能である。ABE [RFC8511]は、ECNマーキングに応じてホストの動作を変えることで、リンクをより有効に利用し、ECNフローによりスループットを高速化する。ABEは ECT(0)を使用し、ネットワークが引き続きECNとドロップを同じように扱うことを前提にしている。そのため、ABEはAQMが提供できる短いキューイング遅延を利用する。しかし、上で説明したように、AQMは(他のABE以外のフローを許可するために)リンクの利用率を失うことなく、キューイング遅延を大幅に削減することはできない。
BBR:
ボトルネック帯域幅と往復伝播時間(BBR)[BBR-CC]は、AQMのようなネットワーク内の特別なロジックを必要とすることなく、エンドツーエンドのキューイング遅延を制御する。そのため、どのようなパスでもほぼ機能する。BBRはキューイング遅延をかなり低く保つが、おそらくPIEやFQ-CoDelのような最新のAQMほどではなく、L4Sほど低くもない。また、キューイング遅延は、BBRの定期的な帯域幅プローブのスパイクと積極的なフロー開始フェーズのため、一貫して低いわけではない。
L4SはBBRを補完する。実際、BBRv2は、利用可能な場合にL4S ECNを使用でき、パスからのECN信号に応答してスケーラブルなL4S輻輳制御動作を使用できる[BBRv2]。L4S ECN信号は、BBRの遅延ベースの輻輳制御の側面を補完し、ホストが適切なレートに収束するためと、ネットワークによって設定された浅いキュー目標値を下回るように維持するために使用できる明示的な指示である。L4S ECNがなければ、これらの側面の両方を仮定または推定する必要がある。
6. 適用範囲
6.1. アプリケーション
現在の遅延問題を解決するトランスポート層は、新しいサービス、製品、アプリケーションの機会を提供する。
L4Sアプローチにより、以下の既存のアプリケーションでも、負荷時の体感品質が大幅に改善される。
- クラウドベースのゲームを含むゲーム;
- VoIP;
- ビデオ会議;
- ウェブ閲覧;
- (適応型)ビデオ・ストリーミング; そして
- インスタント・メッセージング
また、キューイング遅延が大幅に短縮されたことで、現在ではほとんど利用できない双方向のアプリケーション機能をクラウドにオフロードすることも可能になった。
- クラウドベースの双方向動画
- クラウドベースの仮想現実と拡張現実
上記の2つのアプリケーションは、すべて同じボトルネックとなるキューを共有する40Mb/sのブロードバンド・アクセス・リンク上で、前述のリストにある遅延の影響を受けやすいアプリケーションや、多数のダウンロード負荷を同時にかけて、L4Sで同時に実行するデモンストレーションに成功している[L4Sdemo16] [L4Sdemo16-Video]。前者では、サッカースタジアムのパノラマビデオをスワイプしたりピンチしたりすることで、クラウド内のプロキシが各ユーザの指のジェスチャー制御の下で、試合の動画のサブウィンドウをその場で生成することができる。後者では、バーチャル・リアリティ・ヘッドセットに、レーシング・カーの360度カメラから撮影したビューポートを表示した。ユーザの頭の動きは、クラウドベースのプロキシによって抽出されたビューポートを制御した。どちらの場合も、エンドツーエンドの基本遅延が7ミリ秒で、追加のキューイング遅延はおよそ1ミリ秒と、映像がローカルで生成されたように見えるほど低いものだった。
指をスワイプするジェスチャや頭を動かして、映像をパンする動作は、VoIPよりもはるかに遅延要求が厳しい。なぜなら、人間の視覚は、映像と基準点(指や内耳の平衡系、つまり前庭系によって感知される頭の向き)との間の視覚的な遅れに換算すると、1ミリ秒オーダーの極めて小さな遅延を検出することができるためである。代替AQMを使用すると、映像は指のジェスチャーや頭の動きに比べて明らかに遅れていた。
L4Sの低いキューイング遅延がなければ、このようなクラウドベースのアプリケーションは、(視聴される可能性のある映像のすべての領域を配信するために)アクセス・ネットワークの帯域幅を大幅に増やし、ヘッドマウント・ディスプレイの重量と消費電力を増加させるローカル処理を強化しなければ、信頼性が低くなるだろう。すべてのインタラクティブ処理をクラウドで実行することができれば、エンドユーザ向けにレンダリングするデータだけを送信すればよい。
その他の低遅延高帯域幅アプリケーションには次のようなものがある:
- 双方向の遠隔臨場
- 機械や産業プロセスのビデオ支援遠隔制御
は、非常に低いキューイング遅延がなければ、まったく信用できない。アクセス帯域幅やローカル処理をいくら増やしても、失われた時間を補うことはできない。
6.2. ユースケース
L4Sには以下のユースケースがあり、さまざまな関係者によって検討されている。
-
ボトルネックが、DSL、パッシブ光ネットワーク(PON)、DOCSISケーブル、モバイル、衛星など、さまざまなタイプのアクセス・ネットワークのいずれかの場合、またはWi-Fiリンクの場合(技術固有の詳細についてはセクション6.3を参照)
-
ヘテロジニアス・データセンターのプライベート・ネットワークで、DCTCPの導入に必要な送信者、受信者、ネットワークの同時変更をすべて調整できる単一の管理者が存在しない場合
- 同一企業内でありながら、別々の管理が行われ、広域に相互接続されたプライベート・データセンター
- 関心共有型コミュニティ・ネットワークによって相互接続された、別々の企業によって運営されるデータセンター(例: 金融部門)
- テナントがオペレーティング・システム・スタック(Infrastructure as a Service (IaaS))を選択するマルチテナント(クラウド)データセンター
-
さまざまなタイプのトランスポート(またはアプリケーション)の輻輳制御:
- エラスティック(TCP/SCTP);
- リアルタイム (RTP、RMCAT); そして
- クエリー応答 (DNS/LDAP)
-
低遅延QoSが必要な場合、IPの上位層を調べたり、介入する必要ない[RFC8404]:
- モバイルやその他のネットワークでは、アプリケーションのQoS要件を推測するために、より上位層を調べる傾向があった。しかし、プライバシーや暗号化のサポートに対する需要が高まる中、L4Sは代替手段を提示する。L4Sがすべてのトラフィックに有利なキューイングを提供できるのであれば、どのトラフィックを優先的にキューイングするかを選択する必要はない。
-
キューイング遅延が最小限に抑えられる場合、固定遅延バジェットを持つアプリケーションは、長距離または迂回パス、例えば、サービス・ファンクション・チェーン[RFC7665]やオニオン・ルータを経由して通信することができる。
-
遅延ジッターを最小限に抑えられる場合、ビデオ・ストリーミングの受信側のデジッタ(dejitter)・バッファを削減することが可能で、双方向体験が向上するはずである。
6.3. 特定のリンク技術での適用性
ある種のリンク技術では、複数のパケットからデータをバーストに集約し、各バーストを組み立てる間に受信パケットをバッファリングする。Wi-Fi、PON、ケーブルはすべてこのようなパケット集約を伴うが、固定イーサネットとDSLは行わない。L4Sであろうとなかろうと、送信者はパケット集約に必要なバッファリングを減らすために何もすることはできない。そのため、AQMは、どんなに輻輳信号を送っても、このバッファリングを減らすことができないため、バッファリングを制御するキューの一部としてカウントすべきではない。
ある種のリンク技術は、具体的には次の理由でバッファリングを追加する:
- 発信元から離れた無線リンク(セルラー、Wi-Fi、衛星)は特に困難である。無線リンクの容量は桁違いに急激に変化することがあるため、突然の容量増加に対応できるような永続キューを保持することが望ましいと考えられている。
- セルラー・ネットワークは、ハンドオーバーを人が感知できないようにするためのバッファリングの必要性が認識されているため、さらに複雑である。
L4Sは、これらのさまざまな形式のバッファリングのニーズをすべて取り除くことはできない。しかし、「最も解決が難しい点」(クラシック輻輳制御の大きな鋸歯のバッファリング)を取り除くことで、L4Sはすべての「比較的簡単に対処できる点」を、より厳しい監視対象にさらすことになる。
これまでは、これらの追加的な理由に必要なバッファリングは、「最も難しい点」ではないという言い訳と共に、オーバースペックになりがちだった。しかし、「比較的簡単に対処できる点」を取り除いたことで、例えば、パケット集約のバーストサイズや MACスケジューリング間隔を小さくするなど、それらを最小化する価値が生まれた。
また、ある種のリンクタイプ、特に無線ベースのリンクは、伝送損失がはるかに発生しやすい。セクション6.4.3では、損失に対するL4Sの応答がクラシックの応答と同じくらい極端でなければならないことを説明している。それにもかかわらず、同じセクションで言及されている研究は、L4Sパケットの順序制約が緩和されているため、リンク層での損失修復がかなり効果的に行える可能性が実証されている。
6.4. 導入に関する考慮事項
L4S AQMは、DualQ[RFC9332]であれ、FQ[RFC8290]であれ、 それ自体がL4Sの増分導入メカニズムであるため、L4Sトラフィックは既存のクラシック(Renoフレンドリー)トラフィックと共存することができる。セクション6.4.1では、アクセスリンクの両端のどちらかのノードにL4S AQMを配備するだけで、L4Sのほぼすべての利点を実現できる理由を説明している。
セクション6.4.2では、L4Sをネットワークとエンドシステムの両方に導入する場合の典型的な手順と、どちらかに導入するだけで、即座に大きなメリットが得られる理由を示している。
セクション6.4.3と6.4.4では、ネットワークのボトルネックにL4S AQMが存在しない場合の逆の増分導入のケースについて説明している。そのため、このボトルネックを通過するL4Sフローは、クラシックのトラフィックと競合する場合に備え、注意する必要がある。
6.4.1. 導入トポロジ
L4S AQMがインターネット全体に導入されなくても、L4Sは誰にでも恩恵をもたらす可能性がある。公衆インターネットのアクセス・ネットワーク事業者は通常、ボトルネックがほぼ常に1つの既知の(論理)リンクで発生するようにネットワークを設計する。これにより、キュー管理技術のコストは1 か所に限定される。
メッシュ・ネットワークの場合は異なるので、このセクションで後述する。しかし、既知のボトルネックのケースは、一般的に、あらゆる種類のさまざまな「サイト」へのインターネット・アクセスに当てはまる。「サイト」という言葉には、ホームネットワーク、中小規模のキャンパスや企業ネットワーク、さらにはセルラー・デバイスも含まれる(図2)。また、この既知のボトルネック・ケースは、xDSL、ケーブル、PON、セルラー、LOS(line of sight)無線、衛星など、アクセスリンク技術に関係なく当てはまる傾向がある。
したがって、L4S AQMがこのボトルネック・リンクへの入口に導入されれば、L4Sサービスの完全な利点をダウンストリーム方向で最大限に活用できるはずである。同様に、L4S AQMがアップストリーム・リンクへの入口に設置されれば、通常、アップストリーム・サービスもフルに利用できるようになる。(もちろん、マルチホームのサイトでは、すべてのアクセスリンクがカバーされて初めて、最大のメリットが得られる。)

図2 : 一般的なアクセス・トポロジにおけるDualQ (DQ)導入の可能性のある場所
メッシュ・トポロジにおける導入は、コアがどの程度オーバーブッキングしているかによる。コアがノンブロッキングであるか、少なくともエッジがほぼ常にボトルネックとなるように余裕を持ってプロビジョニングされていれば、エッジのボトルネックにのみL4S AQMを導入するだけで済む。例えば、ハイパーバイザーやホストのネットワーク・インタフェース・コントローラ(NIC)がボトルネックになるように設計されているデータセンター・ネットワークもあれば、ToRスイッチ(ホスト側の出力ポートとコア側の出力ポートの両方)がボトルネックになっているデータセンター・ネットワークもある。
次にL4S AQMが必要になるのは、家庭内のWi-Fiリンクがボトルネックになる場合だ。また、L4S AQMは、ネットワークの相互接続(例えば、公衆インターネット交換ポイントやデータセンターを相互接続するWANリンクへの出入り口)など、他の永続的なボトルネックにも最終的に導入する必要がある。
6.4.2. 導入順序
1つのL4Sフローで利益をもたらすためには、次の3つの部分(場合によっては2つ)を導入する必要がある。i) 送信側での輻輳制御、ii) ボトルネックでのAQM、iii) 古いトランスポート(つまりTCP)はアップグレードされた受信側フィードバックも必要である。これはECNが直面したのと同じ導入の問題[RFC8170]であったため、私たちはその経験から学んだ。
まず、L4Sの導入は、DCTCPがすでに多くのインターネット上のホスト(Windows、FreeBSD、Linuxなど)、サーバとクライアントの両方に存在しているという事実を利用する。したがって、L4S AQMをネットワークのボトルネックに配備することで、ECT(0)コードポイントをECT(1)に切り替えさえすれば、テスト用のL4Sのすべてのパーツをすぐに動作させることができる。DCTCPは、公衆インターネット上で一般的に使用するために、いくつかの安全上の懸念事項を修正する必要がある(L4S ECN仕様[RFC9331]のセクション4.3を参照)が、DCTCPはデフォルトではオンになっていないため、これらの問題は制御された導入や制御されたトライアルの中で管理することができる。
第二に、L4Sによる性能向上は非常に大きく、以前は不可能だった新しい双方向サービスや製品が可能になる。新製品のトライアルに予算があれば、企業は新たな導入に着手しやすくなる。これとは対照的に、(クラシックECNのような)性能の向上が段階的にしかない場合、導入のための支出を正当化するのはかなり難しくなる傾向がある。
第三に、L4S識別子は、ネットワーク事業者が当初、特定の顧客や特定のアプリケーションに限定してL4Sを有効にできるように定義されている。しかし、これはインターネット全体のサービスとしてのL4Sに向けた将来の進化を損なうことがないように、慎重に定義されている。L4S識別子がエンドツーエンドのECNフィールドとして定義されているだけでなく、オプションで他のパケットヘッダや顧客やアクセスリンクのステータスと組み合わせることができるためである([RFC9331]のセクション5.4を参照)。IETFから感謝されなかったとしても、事業者はとにかくこれを実行することができた。しかし、IETFが独自のローカル識別子を使用する場合、IETFの識別子であるECT(1)と組み合わせなければならないことを指定するのが最善である。そうすれば、自御者が排他的なローカル用途のアプローチを選択した場合でも、サービスをインターネット全体で動作させるために、後でこの追加のルールを削除するだけで良い。サービスはすでにミドルボックスやピアリングなどを通過することになる。

図3: L4S導入順序の例
図3は、 L4Sの各パーツが導入される順序の例を示している。これは以下の段階で構成されており、その前にDCTCPが両端にすでにインストールされていることを前提とする。
-
DCTCPは公衆インターネット上での使用に適さないため、DCTCPのフローは制御されたトライアル環境内に完全に封じ込められなければならないことがここで強調される。
このトライアル環境では、L4S AQMが導入されると、トライアルDCTCPフローは、他の配備を必要とすることなく、即座にメリットを享受できる。この例では、ダウンストリームが最初に配備されているが、他のシナリオでは、アップストリームが最初に配備されるかも知れない。ダウンストリーム・アクセスに AQMがまったく導入されていない場合、L4S AQMはクラシック・サービスを大幅に改善する。(L4Sサービスも同様に追加される)。AQMがすでに導入されている場合、クラシック・サービスは変更されない(そして、L4Sによってさらに改善が加えらる)。
-
この段階では、「TCP Prague」[PRAGUE-CC]という名前を使用して、実運用インターネット環境で使用することを想定したDCTCPバリアントを表す(つまり、L4S ECN仕様[RFC9331]のセクション4のすべての要件に準拠する必要がある)。アプリケーションが主に単方向の場合、受信側がAccurate ECN(AccECN)フィードバック[ACCECN]をサポートしていれば、送信側の「TCP Prague」は必要なすべての利点を備える。
TCPトランスポートの場合、AccECNフィードバックはもう一方の端で必要であるが、これは、DCTCPやBBRなど、他の目的に導入がすでに計画されている汎用ECNフィードバック機能である。TCPでは、L4S輻輳制御は、接続ハンドシェイク中に相手側とAccECNフィードバックの使用をネゴシエートした場合にのみ、それ自身を有効にするため、両端はどちらの順序でも導入できる。したがって、サーバ上にTCP Pragueを導入することで、もう一方の端にAccECNが導入されている場合でも、L4Sトライアルを一方向の本番サービスに移行することができる。この段階は、DCTCPと比較したTCP Pragueの性能が向上していること(L4S ECN仕様[RFC9331]の付録A.2を参照)が、さらなる動機付けになるかも知れない。
TCPとは異なり、QUICのECNフィードバック[RFC9000]は当初からL4Sをサポートしている。したがって、トランスポートがQUICの場合、この段階でのPrague輻輳制御の片端導入は簡単かつ十分である。
QUICの場合、プロキシが複数のオリジンサーバと複数のクライアントへのアクセス・ボトルネック間のパスに位置する場合、スケーラブルな輻輳制御を備えたプロキシをアップグレードすると、すべてのオリジンサーバがアップグレードされたかどうかにかかわらず、すべてのクライアントのダウンストリーム・ボトルネックに対するL4Sの利点を一度に提供することになる。逆に、プロキシがアップグレードされていない場合、プロキシの背後にあるオリジンサーバがL4Sをサポートするようにアップグレードされていても、プロキシによってサービスが提供されるクライアントは、ダウンストリームでL4Sの恩恵をまったく受けない。
TCPの場合、「TCP Prague」をサポートするようにアップグレードされたプロキシは、AccECNをサポートするすべてのクライアントに(L4Sもサポートしているかどうかに関係なく)、ダウンストリームでL4Sの利点を提供する。また、アップストリームでは、プロキシはレシーバーとして、AccECNもサポートするため、プロキシの先のオリジンサーバがAccECNをサポートしているかどうかに関係なく、それ自身のL4Sサポートを導入するクライアントはアップストリーム方向で恩恵を受けることができる。
-
これは、L4Sアップストリームを有効にする2移行ステージである。L4S AQMまたはTCP Pragueは、すでに説明したように、どちらの順序でも導入できる。2つの独立した移行のうち、最初の移行を動機付けるには、2回目の移行後に新しいサービスを有効にするという繰延利益が、最初の移行者の投資リスクをカバーする価値がなければならない。すでに説明したように、新しい双方向サービスの可能性がこの動機付けとなる。L4S AQMはまた、他のAQMがまだ導入されていない場合、アップストリームのクラシック・サービスを大幅に改善する。
他の導入順序が発生する可能性があることに注意。例えば、アップストリームが最初に導入されるかも知れない。非・TCPプロトコル(QUICやRTPなど)がエンドツーエンドで使用されるかも知れない。3GPPのような機関が5Gユーザ機器にL4Sを実装することを要求するかも知れない。あるいは、その他のランダムな親切心が生じるかも知れない。
6.4.3. L4Sフローだが非・ECNボトルネック
L4Sが、2つのホスト間で有効になっている場合、L4Sの送信者はいかなるドロップに対しても、Renoと安全に共存することが要求される(L4S ECN仕様[RFC9331]のセクション4.3を参照)。
残念ながら、このルールは、クラシック・トラフィックを保護するだけでなく、たとえ原因がボトルネックでの持続的な輻輳でなくても、損失が発生するたびにL4Sサービスの質を低下させる。例えば:
- 他の一時的なボトルネックにおける輻輳損失、例えば、より浅いキューのバーストによるもの
- 電気的干渉などによる伝送エラー、そして
- レートポリシング。
この問題に対処するため、3つの補完的なアプローチが進行中だが、いずれも現在研究中である:
- Pragueの輻輳制御では、輻輳が原因である可能性が低いと考えられる特定の損失を無視する(孤立損失に関するBBR[BBR-CC]のいくつかのアイデアを使用)。これは、ドロップベースの輻輳制御と共存しながら、上記の損失タイプのいずれかを覆い隠すことができる。
- Recent Acknowledgement(RACK)[RFC8985]、L4S、および再順序付けを行わないリンク再送信を組み合わせることで、通常はリンク層の再送信に関連するヘッド・オブ・ライン・ブロッキング遅延を発生させることなく、伝送エラーを修復することができる[UnownedLTE] [RFC9331]。
- ハイブリッドECN/ドロップ・レート・ポリサー (セクション8.3を参照)。
これらの問題を最小限に抑えるL4S導入シナリオ(有線ネットワークなど)は、研究の成功によりL4Sの適用可能性が継続的に広がることを期待して、本研究と並行して進めることができる。
6.4.4. L4Sフローだが古典的なECNボトルネック
クラシックECNサポートは、CEマーキングのレベルを上げるものとしてインターネット上で実現され始めている。これがすべて、FQ-CoDelやFQ-COBALTの実装にECNのサポートが追加されたためかどうかを検出するのは困難だが、これは一般的には問題というわけではない。なぜなら、フローキュー(FQ)のスケジューリングは、本質的にフローが攻撃性とは関係なく、「公平な」レート制限を超えることを防ぐからである。ただし、このクラシックECNマーキングの一部は、シングルキューECNの導入に起因する可能性がある。このケースは、L4S ECN仕様[RFC9331]のセクション4.3で説明されている。
6.4.5. トンネル内でのL4S AQMの導入
L4S AQMは、ECNフィールドを使用して輻輳信号を発する。したがって、クラシックECNと同様に、AQMがトンネル内または下位層にある場合、ECN信号を正しく機能させるには、ECNフィールドを上位層に標準準拠で伝播する必要がある[RFC6040] [ECN -SHIM] [ECN-ENCAP]。
7. IANA に関する考慮事項
本文書にはIANAのアクションはない。
8. セキュリティに関する考慮事項
8.1. トラフィックレート(非)ポリシング
8.1.1. フローごとの(非)ポリシング・レート
現在のインターネットでは、ISPは通常、何らかの形式のスケジューラ[RFC0970]を使用して、さまざまな「サイト」 (家庭、企業、モバイルユーザなど -- セクション3の用語を参照)に割り当てられる共有リンクの容量間の分離を強制する。そして、フラッディング攻撃に対処するために、トラフィック浄化設備へのリダイレクトなど、さまざまな技術を使用している。しかし、個々のアプリケーション・フローのレートを取り締まる一般的な必要性はこれまで存在しなかった。インターネットは通常、「サイト」内の容量を共有するために、常に送信側の輻輳制御の自制に依存してきた。
L4Sは、この現状を覆さないように設計されている。DualQがL4Sサービスを提供するために使用される場合、[RFC9332]のセクション4.2では、トラフィックが過負荷かどうかにかわらず、シングルキューAQMが行うよりも、応答のないフローに対してレート上の優位を与えないように設計されていることを説明している。
また、フローごとのレートのポリシングが必要になった場合、L4Sとクラシックの区別とは無関係なので、それを追加することができる。セクション5.2で説明しているように、L4SのDualQバリアントは、フローレート制御の問題を十分な判断材料もなく判断を下すことなく、低遅延を実現する。従って、もし、フローレート制御が必要な場合は、L4S サポートを備えたフロー単位のキューイング(FQ)を代わりに使用するか、フローレート・ポリシングをDualQにモジュール的に追加することもできる。ただし、フロー単位のレート制御は通常、セキュリティ・メカニズムとして導入されることはない。なぜなら、活動的な攻撃者は、各フローのレートが制限されていれば、より多くのフローIDにトラフィックを分散させることができるからである。
8.1.2. L4Sサービスレートの(非)ポリシング
セクション5.2では、一部のパケットが他のパケットよりも不利な扱いを受ける場合にのみ、Diffservがどのような違いを生むのかを説明している。これは通常、低遅延クラスのトラフィック・レート・ポリシングが必要になる。これとは対照的に、L4Sはクラシック・トラフィックの遅延やレートに影響を与えることなく遅延を低減するように設計されているため、クラシック・サービスを保護するためにL4Sサービスへのアクセスをレート・ポリシングする必要はない。
導入の初期段階では(おそらく常に)、L4Sサービスを提供しないネットワークもある。一般的に、これらのネットワークはL4Sトラフィックを取り締まる必要はない。これらのネットワークは、エンドツーエンドの輻輳制御の妨げとなるL4S識別子を変更しないことが(ECN仕様[RFC3168]とL4SECN仕様[RFC9331]の両方で)要求されている。すでにECNトラフィックをNot-ECTとして扱っているのであれば、L4SトラフィックもNot-ECTとして扱うだけで良い。このようなネットワークではボトルネックになると、キューイングやドロップが発生する。スケーラブルな輻輳制御がドロップを検出すると、([RFC9331]のセクション4.3で要求されているように)クラシック輻輳制御に関して安全に応答しなければならない。これは、パス上で非・ECNボトルネックに遭遇するたびに、L4Sサービスをクラシックのベストエフォートより悪くならないように(決して悪くならないように)劣化させる(セクション6.4.3参照)。
稀にしか発生しないと予想されるケースでは、単一キューのボトルネックでクラシックECN[RFC3168]のみをサポートするネットワークは、競合するクラシックECNトラフィックを保護するために、L4Sトラフィックを取り締まることを選択するかも知れない(例えば、L4S運用ガイダンス[L4SOPS]のセクション6.1.3を参照)。しかし、L4S ECN仕様[RFC9331]のセクション4.3では、送信側がクラシックECNフローと適切に共存できるように輻輳応答を適応させること、つまり、自己抑制アプローチに戻すことを推奨している。
ネットワーク事業者によっては、おそらく付加価値サービスとして、選ばれたプレミアム顧客だけに、L4Sサービスへのアクセスを制限することを選択するかも知れない。パケット分類子(図1の項目2)は、ECNフィールドで分類するだけでなく、他のフィールド(例えば、送信元アドレス範囲)に対してそのような顧客を識別することもできる。ECN L4S識別子のみが一致し、(例えば)送信元アドレスが一致しない場合、分類子は(プレミアム以外の顧客からの)これらのパケットをクラシック・キューに向かわせることができる。事業者が追加のローカル分類子をどのように使用できるかを明確に説明すること([RFC9331]のセクション5.4を参照)は、L4S識別子をクリアする動機を取り除くことを意図している。そうすれば、サービスがすべてのホップでサポートされない場合でも、少なくともL4S ECN識別子はエンドツーエンドで存続する可能性が高くなる。このようなローカルな取り決めでは、Diffservが使用する顧客固有のトラフィック契約に対する管理されたアプリケーション固有のトラフィック・ポリシングではなく、単純な登録済み/未登録パケットの分類のみが必要となる。
8.2. 「遅延への配慮」
クラシック・サービスと同様に、L4Sサービスも輻輳に応じてレートを制限する自制に依存している。さらに、L4Sサービスでは、遅延(バースト性)を制限するという点でも自制が求められる。アプリケーション自体の遅延がそのような動作から最も影響を受けることを考えると、動的動作 (特に、標準化が必要かも知れないフローの開始)に関する自己利益とガイダンスは、トランスポートがL4Sトラフィックの過剰なバーストを送信するのを防ぐのに十分であることが期待される。
L4S サービスは、クラシック・トラフィックの遅延を顕著に増加させることなく遅延を削減できるため、クラシック・トラフィックの遅延を保護するためにL4Sトラフィックを規制する必要はない。しかし、他のL4Sトラフィックを保護するためにバースト・ポリシングが必要になるかどうかはまだ分からない。それがなければ、L4Sサービスの低遅延に対する攻撃の可能性がある。
必要であれば、この懸念に対処するためにさまざまな取り決めを用いることができる:
ローカル・ボトルネック・キューの保護:
DOCSISでは、DualQ L4Sアーキテクチャを採用した低遅延キューのために、フロー単位(5タプル)のキュー保護機能[DOCSIS-Q-PROT]が開発されている。これは、誤ってあるいは悪意を持って低遅延キューに分類されるキュー構築フローから低遅延サービスを保護する。これは、キューイングへの貢献度(フローレート自体ではなく)のみに基づいてフローをスコアリングするよう設計されている。そして、共有される低遅延キューが閾値を超える危険性がある場合、この機能は、最も高いスコアを持つフローの十分なパケットを、低遅延を維持するためにクラシック・キューにリダイレクトする。
分散トラフィックの洗浄:
ボトルネック毎にローカルに規制するのではなく、フラッディング攻撃源からのトラフィックが洗浄設備を介して再ルーティングされるのと同様の方法で、新しいバースト型マルウェアの導入を懲罰的にターゲットにするなど、事後的に問題に対処することだけが必要な場合がある。
ローカル・ボトルネックのフロー単位のスケジューリング:
フロー単位のスケジューリングは本質的に、バースト性のないフローをバースト性の高いフローから分離する必要がある(フロー単位のポリシングに対するフロー単位のスケジューリングのメリットについては、セクション5.2参照)。
分散アクセス・サブネット・キューの保護:
フロー単位のキュー保護は、下位層の制御メッセージを使用して相互通信するサブネット全体に分散されたキュー構造に対して配置することができる([QDyn]のセクション 2.1.4 を参照)。例えば、無線アクセス・ネットワークでは、ユーザ機器はすでに無線ネットワーク・コントローラに定期的なバッファ・ステータス・レポートを送信しており、無線ネットワーク・コントローラはこの情報を使用して個々のフローをリモートで規制することができる。
分散型輻輳がイングレス・ポリサーにさらされる:
Congestion Exposure (ConEx)アーキテクチャ[RFC7713]は、入力ポリサーによって使われる帯域内で、パスの輻輳を正確に通知するように送信者を同期づけるために、エグレス監査を使用する。このアーキテクチャのエッジツーエッジの変形も可能である。
分散型ドメイン・エッジのトラフィック調整:
Diffserv[RFC2475]に似たアーキテクチャが好まれるかも知れない。ここで、トラフィックがボトルネックで他のトラフィックと組み合わされてキューイングに至った場合のみ受け身的に規制されるのではなく、そのドメインに入る時に事前に条件付けされる。
分散コア・ネットワーク・キュー保護:
ポリシング機能は、各フローのバースト性をトラフィックとともに伝送される信号に特徴付けるネットワークの入口におけるフロー単位のメカニズムと、トラフィックが収束した後にキューイングが実際に発生した場合にこれらの信号に作用するボトルネックにおけるクラス単位のメカニズムとの間に分割することができる。これは[Nadas20]にいくらか似ており、コア・ステートレス・フェア・キューイングの背後にある考え方に似ている。
これらの可能性のあるキュー保護機能のうち、L4Sアーキテクチャの重要な部分と考えられるものは一つもない。これは、攻撃されていない条件下では(インターネットが通常、フロー単位のレート・ポリシングなしで機能するのと同じように)、どれ一つ欠けても機能しない。実際、遅延ポリサーを導入している場合でも、通常であれば介入することなく、事業者が必要ないと判断すれば無効にすることもできる。L4Sの実験の一環として、このような機能が必要かどうか、また問題の規模に応じてどのような取り決めが最も適切かを確認する。
8.3. レート・ポリシングとL4Sの間の相互作用
セクション5.2で述べたように、L4Sは低遅延のDiffservクラスの必要性を取り除くはずである。しかし、特定のアプリケーションやユーザに容量よりも優先順位を与えるようなDiffservクラスは、特定のシナリオ(例えば、企業ネットワーク)ではまだ適用可能である。そして、このようなDiffservクラス内では、トラフィックに低遅延と低損失を与えるためにL4Sが適用されることが多い。このようなDiffservクラス内では、ユーザまたはアプリケーションが利用可能な帯域幅は、多くの場合、レートポリサーによって制限される。同様に、デフォルトのDiffservクラスでは、レートポリサーは共有容量を分割するために使用されることがある。
クラシック・レートポリサーは、設定されたレートを超えるパケットをすべてドロップし、通常はバースト許容量も与える(ポリサーが非・適合トラフィックを破棄適格な Diffservコードポイントに再マークすることで、競合中に他の場所でドロップできるようにするバリアントも存在する)。L4Sトラフィックがこのようなレートポリサーに遭遇するたびに、トラフィックにドロップが発生し、送信元はクラシック輻輳制御にフォールバックしなければならなくなり、L4Sの利点が失われる(セクション6.4.3 )。そのため、すでにレートポリサーを使用していて、L4Sの導入を予定しているネットワークでは、これらのレートポリサーをL4Sサービスにより適したものに再設計することが望ましい。
L4Sに適したレート・ポリシングは現在研究分野である(これは遅延ポリシングと異なることに注意)。それは、ECNマーキングが導入される閾値を設定することで達成されるかも知れない。その閾値は、ポリシングされたレートの直下、またはドロップが導入されるバースト許容量の直下になるように設定する。例えば、2レート3色のマーカー[RFC2698]やPCN閾値と超過レートマーカー[RFC5670]は、低いレートでECNをマークし、高いレートではドロップすることができる。あるいは、既存のレートポリサーに輻輳レートポリシングを追加することもできる。例えば、ConEx集約輻輳ポリサー[CONG-POLICING]の「ローカル」(非・ConEx)バリアントを使用する。また、遅延が増加する期間を経ていない損失に対して、致命的ではない程度に反応するようにスケーラブルな輻輳制御を設計することも可能かも知れない。
L4Sフレンドリーなレートポリサーの設計については、別の専用文書が必要である。L4SとDiffservの相互作用の詳細については、[L4S-DIFFSERV]を参照のこと。
8.4. ECNの完全性
受信者、送信者、またはネットワーク(または3つすべて)による不正行為から輻輳フィードバック・ループの完全性(損失、クラシックECN、またはL4S ECNによって通知される)を保護するために、さまざまな方法が開発されてきた。適用可能性、長所、短所など、それぞれの簡単な説明は、L4S ECN仕様 [RFC9331]の付録C.1に記載されている。
8.5. プライバシーに関する考察
セクション5.2で議論したように、L4Sアーキテクチャは、エンドツーエンドのトランスポート層識別子を検査するアプローチを排除しない。例えば、ネットワーク上のアプリケーション・フロー識別子で分類するFQ-CoDelにL4Sのサポートが追加された。しかし、L4Sの主な革新は、DualQ AQMフレームワークであり、L4S識別子はIP-ECNフィールドにあるため、IPヘッダの最も外側のより深部を調べる必要はない。
このように、L4Sアーキテクチャは、IP層より上位の情報の検査を必要とせずに、非常に低いキューイング遅延が可能になる。これは、例えば、IPsecや他の暗号化されたVPNトンネルにおいて、アプリケーション・フロー識別子を暗号化したいユーザが、低遅延を犠牲にする必要がないことを意味する[RFC8404]。
L4Sは、それを使用することを選択する広範なアプリケーション・セットに対して低遅延を提供ですることができるため、その広範なセット内の個々のアプリケーションやクラスが、ネットワークを横断する間に何らかの方法で区別できる必要はない。これによって、トラフィックの遅延要件と他の識別機能[RFC6973]の間の相関をとる能力の多くが取り除かれる。L4Sを使用しないことを好むタイプのトラフィックもあるかも知れないが、トラフィックの大まかな2値分類では、プライバシーを侵害するために悪用される可能性はほとんどない。
9. 参考文献
[ACCECN] Briscoe, B., Kühlewind, M., and R. Scheffenegger, "More Accurate ECN Feedback in TCP", Work in Progress, Internet-Draft, draft-ietf-tcpm-accurate-ecn-22, 9 November 2022, <https://datatracker.ietf.org/doc/html/draft-ietf-tcpm-accurate-ecn-22>.
[AFCD] Xue, L., Kumar, S., Cui, C., Kondikoppa, P., Chiu, C-H., and S-J. Park, "Towards fair and low latency next generation high speed networks: AFCD queuing", Journal of Network and Computer Applications, Volume 70, pp. 183-193, DOI 10.1016/j.jnca.2016.03.021, July 2016, <https://doi.org/10.1016/j.jnca.2016.03.021>.
[BBR-CC] Cardwell, N., Cheng, Y., Hassas Yeganeh, S., Swett, I., and V. Jacobson, "BBR Congestion Control", Work in Progress, Internet-Draft, draft-cardwell-iccrg-bbr-congestion-control-02, 7 March 2022, <https://datatracker.ietf.org/doc/html/draft-cardwell-iccrg-bbr-congestion-control-02>.
[BBRv2] "TCP BBR v2 Alpha/Preview Release", commit 17700ca, June 2022, <https://github.com/google/bbr>.
[BDPdata] Briscoe, B., "PI2 Parameters", TR-BB-2021-001, arXiv:2107.01003 [cs.NI], DOI 10.48550/arXiv.2107.01003, October 2021, <https://arxiv.org/abs/2107.01003>.
[BufferSize] Appenzeller, G., Keslassy, I., and N. McKeown, "Sizing Router Buffers", SIGCOMM '04: Proceedings of the 2004 conference on Applications, technologies, architectures, and protocols for computer communications, pp. 281-292, DOI 10.1145/1015467.1015499, October 2004, <https://doi.org/10.1145/1015467.1015499>.
[COBALT] Palmei, J., Gupta, S., Imputato, P., Morton, J., Tahiliani, M. P., Avallone, S., and D. Täht, "Design and Evaluation of COBALT Queue Discipline", IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), DOI 10.1109/LANMAN.2019.8847054, July 2019, <https://ieeexplore.ieee.org/abstract/document/8847054>.
[CODEL-APPROX-FAIR] Morton, J. and P. Heist, "Controlled Delay Approximate Fairness AQM", Work in Progress, Internet-Draft, draft-morton-tsvwg-codel-approx-fair-01, 9 March 2020, <https://datatracker.ietf.org/doc/html/draft-morton-tsvwg-codel-approx-fair-01>.
[CONG-POLICING] Briscoe, B., "Network Performance Isolation using Congestion Policing", Work in Progress, Internet-Draft, draft-briscoe-conex-policing-01, 14 February 2014, <https://datatracker.ietf.org/doc/html/draft-briscoe-conex-policing-01>.
[CTCP] Sridharan, M., Tan, K., Bansal, D., and D. Thaler, "Compound TCP: A New TCP Congestion Control for High-Speed and Long Distance Networks", Work in Progress, Internet-Draft, draft-sridharan-tcpm-ctcp-02, 11 November 2008, <https://datatracker.ietf.org/doc/html/draft-sridharan-tcpm-ctcp-02>.
[DOCSIS-Q-PROT] Briscoe, B., Ed. and G. White, "The DOCSIS® Queue Protection Algorithm to Preserve Low Latency", Work in Progress, Internet-Draft, draft-briscoe-docsis-q-protection-06, 13 May 2022, <https://datatracker.ietf.org/doc/html/draft-briscoe-docsis-q-protection-06>.
[DOCSIS3.1] CableLabs, "MAC and Upper Layer Protocols Interface (MULPI) Specification, CM-SP-MULPIv3.1", Data-Over-Cable Service Interface Specifications DOCSIS 3.1 Version i17 or later, 21 January 2019, <https://specification-search.cablelabs.com/CM-SP-MULPIv3.1>.
[DOCSIS3AQM] White, G., "Active Queue Management Algorithms for DOCSIS 3.0: A Simulation Study of CoDel, SFQ-CoDel and PIE in DOCSIS 3.0 Networks", CableLabs Technical Report, April 2013, <https://www.cablelabs.com/wp-content/uploads/2013/11/Active_Queue_Management_Algorithms_DOCSIS_3_0.pdf>.
[DualPI2Linux] Albisser, O., De Schepper, K., Briscoe, B., Tilmans, O., and H. Steen, "DUALPI2 - Low Latency, Low Loss and Scalable (L4S) AQM", Proceedings of Linux Netdev 0x13, March 2019, <https://www.netdevconf.org/0x13/session.html?talk-DUALPI2-AQM>.
[Dukkipati06] Dukkipati, N. and N. McKeown, "Why Flow-Completion Time is the Right Metric for Congestion Control", ACM SIGCOMM Computer Communication Review, Volume 36, Issue 1, pp. 59-62, DOI 10.1145/1111322.1111336, January 2006, <https://dl.acm.org/doi/10.1145/1111322.1111336>.
[ECN-ENCAP] Briscoe, B. and J. Kaippallimalil, "Guidelines for Adding Congestion Notification to Protocols that Encapsulate IP", Work in Progress, Internet-Draft, draft-ietf-tsvwg-ecn-encap-guidelines-17, 11 July 2022, <https://datatracker.ietf.org/doc/html/draft-ietf-tsvwg-ecn-encap-guidelines-17>.
[ECN-SCTP] Stewart, R., Tuexen, M., and X. Dong, "ECN for Stream Control Transmission Protocol (SCTP)", Work in Progress, Internet-Draft, draft-stewart-tsvwg-sctpecn-05, 15 January 2014, <https://datatracker.ietf.org/doc/html/draft-stewart-tsvwg-sctpecn-05>.
[ECN-SHIM] Briscoe, B., "Propagating Explicit Congestion Notification Across IP Tunnel Headers Separated by a Shim", Work in Progress, Internet-Draft, draft-ietf-tsvwg-rfc6040update-shim-15, 11 July 2022, <https://datatracker.ietf.org/doc/html/draft-ietf-tsvwg-rfc6040update-shim-15>.
[FQ_CoDel_Thresh] "fq_codel: generalise ce_threshold marking for subset of traffic", commit dfcb63ce1de6b10b, October 2021, <https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net-next.git/commit/?id=dfcb63ce1de6b10b>.
[Hohlfeld14] Hohlfeld, O., Pujol, E., Ciucu, F., Feldmann, A., and P. Barford, "A QoE Perspective on Sizing Network Buffers", IMC '14: Proceedings of the 2014 Conference on Internet Measurement, pp. 333-346, DOI 10.1145/2663716.2663730, November 2014, <https://doi.acm.org/10.1145/2663716.2663730>.
[L4S-DIFFSERV] Briscoe, B., "Interactions between Low Latency, Low Loss, Scalable Throughput (L4S) and Differentiated Services", Work in Progress, Internet-Draft, draft-briscoe-tsvwg-l4s-diffserv-02, 4 November 2018, <https://datatracker.ietf.org/doc/html/draft-briscoe-tsvwg-l4s-diffserv-02>.
[L4Sdemo16] Bondarenko, O., De Schepper, K., Tsang, I., Briscoe, B., Petlund, A., and C. Griwodz, "Ultra-Low Delay for All: Live Experience, Live Analysis", Proceedings of the 7th International Conference on Multimedia Systems, Article No. 33, pp. 1-4, DOI 10.1145/2910017.2910633, May 2016, <https://dl.acm.org/citation.cfm?doid=2910017.2910633>.
[L4Sdemo16-Video] "Videos used in IETF dispatch WG 'Ultra-Low Queuing Delay for All Apps' slot", <https://riteproject.eu/dctth/#1511dispatchwg>.
[L4Seval22] De Schepper, K., Albisser, O., Tilmans, O., and B. Briscoe, "Dual Queue Coupled AQM: Deployable Very Low Queuing Delay for All", TR-BB-2022-001, arXiv:2209.01078 [cs.NI], DOI 10.48550/arXiv.2209.01078, September 2022, <https://arxiv.org/abs/2209.01078>.
[L4SOPS] White, G., Ed., "Operational Guidance for Deployment of L4S in the Internet", Work in Progress, Internet-Draft, draft-ietf-tsvwg-l4sops-03, 28 April 2022, <https://datatracker.ietf.org/doc/html/draft-ietf-tsvwg-l4sops-03>.
[LEDBAT_AQM] Al-Saadi, R., Armitage, G., and J. But, "Characterising LEDBAT Performance Through Bottlenecks Using PIE, FQ-CoDel and FQ-PIE Active Queue Management", IEEE 42nd Conference on Local Computer Networks (LCN), DOI 10.1109/LCN.2017.22, October 2017, <https://ieeexplore.ieee.org/document/8109367>.
[lowat] Meenan, P., "Optimizing HTTP/2 prioritization with BBR and tcp_notsent_lowat", Cloudflare Blog, October 2018, <https://blog.cloudflare.com/http-2-prioritization-with-nginx/>.
[McIlroy78] McIlroy, M.D., Pinson, E. N., and B. A. Tague, "UNIX Time-Sharing System: Foreword", The Bell System Technical Journal 57: 6, pp. 1899-1904, DOI 10.1002/j.1538-7305.1978.tb02135.x, July 1978, <https://archive.org/details/bstj57-6-1899>.
[Nadas20] Nádas, S., Gombos, G., Fejes, F., and S. Laki, "A Congestion Control Independent L4S Scheduler", ANRW '20: Proceedings of the Applied Networking Research Workshop, pp. 45-51, DOI 10.1145/3404868.3406669, July 2020, <https://doi.org/10.1145/3404868.3406669>.
[NASA04] Bailey, R., Trey Arthur III, J., and S. Williams, "Latency Requirements for Head-Worn Display S/EVS Applications", Proceedings of SPIE 5424, DOI 10.1117/12.554462, April 2004, <https://ntrs.nasa.gov/api/citations/20120009198/downloads/20120009198.pdf?attachment=true>.
[NQB-PHB] White, G. and T. Fossati, "A Non-Queue-Building Per-Hop Behavior (NQB PHB) for Differentiated Services", Work in Progress, Internet-Draft, draft-ietf-tsvwg-nqb-15, 11 January 2023, <https://datatracker.ietf.org/doc/html/draft-ietf-tsvwg-nqb-15>.
[PRAGUE-CC] De Schepper, K., Tilmans, O., and B. Briscoe, Ed., "Prague Congestion Control", Work in Progress, Internet-Draft, draft-briscoe-iccrg-prague-congestion-control-01, 11 July 2022, <https://datatracker.ietf.org/doc/html/draft-briscoe-iccrg-prague-congestion-control-01>.
[PragueLinux] Briscoe, B., De Schepper, K., Albisser, O., Misund, J., Tilmans, O., Kühlewind, M., and A.S. Ahmed, "Implementing the 'TCP Prague' Requirements for Low Latency Low Loss Scalable Throughput (L4S)", Proceedings Linux Netdev 0x13, March 2019, <https://www.netdevconf.org/0x13/session.html?talk-tcp-prague-l4s>.
[QDyn] Briscoe, B., "Rapid Signalling of Queue Dynamics", TR-BB-2017-001, arXiv:1904.07044 [cs.NI], DOI 10.48550/arXiv.1904.07044, April 2019, <https://arxiv.org/abs/1904.07044>.
[Raaen14] Raaen, K. and T-M. Grønli, "Latency Thresholds for Usability in Games: A Survey", Norsk IKT-konferanse for forskning og utdanning (Norwegian ICT conference for research and education), 2014, <http://ojs.bibsys.no/index.php/NIK/article/view/9/6>.
[Rajiullah15] Rajiullah, M., "Towards a Low Latency Internet: Understanding and Solutions", Dissertation, Karlstad University, 2015, <https://www.diva-portal.org/smash/get/diva2:846109/FULLTEXT01.pdf>.
[RELENTLESS] Mathis, M., "Relentless Congestion Control", Work in Progress, Internet-Draft, draft-mathis-iccrg-relentless-tcp-00, 4 March 2009, <https://datatracker.ietf.org/doc/html/draft-mathis-iccrg-relentless-tcp-00>.
[RFC0970] Nagle, J., "On Packet Switches With Infinite Storage", RFC 970, DOI 10.17487/RFC0970, December 1985, <https://www.rfc-editor.org/info/rfc970>.
[RFC2475] Blake, S., Black, D., Carlson, M., Davies, E., Wang, Z., and W. Weiss, "An Architecture for Differentiated Services", RFC 2475, DOI 10.17487/RFC2475, December 1998, <https://www.rfc-editor.org/info/rfc2475>.
[RFC2698] Heinanen, J. and R. Guerin, "A Two Rate Three Color Marker", RFC 2698, DOI 10.17487/RFC2698, September 1999, <https://www.rfc-editor.org/info/rfc2698>.
[RFC2884] Hadi Salim, J. and U. Ahmed, "Performance Evaluation of Explicit Congestion Notification (ECN) in IP Networks", RFC 2884, DOI 10.17487/RFC2884, July 2000, <https://www.rfc-editor.org/info/rfc2884>.
[RFC3168] Ramakrishnan, K., Floyd, S., and D. Black, "The Addition of Explicit Congestion Notification (ECN) to IP", RFC 3168, DOI 10.17487/RFC3168, September 2001, <https://www.rfc-editor.org/info/rfc3168>.
[RFC3246] Davie, B., Charny, A., Bennet, J.C.R., Benson, K., Le Boudec, J.Y., Courtney, W., Davari, S., Firoiu, V., and D. Stiliadis, "An Expedited Forwarding PHB (Per-Hop Behavior)", RFC 3246, DOI 10.17487/RFC3246, March 2002, <https://www.rfc-editor.org/info/rfc3246>.
[RFC3540] Spring, N., Wetherall, D., and D. Ely, "Robust Explicit Congestion Notification (ECN) Signaling with Nonces", RFC 3540, DOI 10.17487/RFC3540, June 2003, <https://www.rfc-editor.org/info/rfc3540>.
[RFC3649] Floyd, S., "HighSpeed TCP for Large Congestion Windows", RFC 3649, DOI 10.17487/RFC3649, December 2003, <https://www.rfc-editor.org/info/rfc3649>.
[RFC4340] Kohler, E., Handley, M., and S. Floyd, "Datagram Congestion Control Protocol (DCCP)", RFC 4340, DOI 10.17487/RFC4340, March 2006, <https://www.rfc-editor.org/info/rfc4340>.
[RFC4774] Floyd, S., "Specifying Alternate Semantics for the Explicit Congestion Notification (ECN) Field", BCP 124, RFC 4774, DOI 10.17487/RFC4774, November 2006, <https://www.rfc-editor.org/info/rfc4774>.
[RFC4960] Stewart, R., Ed., "Stream Control Transmission Protocol", RFC 4960, DOI 10.17487/RFC4960, September 2007, <https://www.rfc-editor.org/info/rfc4960>.
[RFC5033] Floyd, S. and M. Allman, "Specifying New Congestion Control Algorithms", BCP 133, RFC 5033, DOI 10.17487/RFC5033, August 2007, <https://www.rfc-editor.org/info/rfc5033>.
[RFC5348] Floyd, S., Handley, M., Padhye, J., and J. Widmer, "TCP Friendly Rate Control (TFRC): Protocol Specification", RFC 5348, DOI 10.17487/RFC5348, September 2008, <https://www.rfc-editor.org/info/rfc5348>.
[RFC5670] Eardley, P., Ed., "Metering and Marking Behaviour of PCN-Nodes", RFC 5670, DOI 10.17487/RFC5670, November 2009, <https://www.rfc-editor.org/info/rfc5670>.
[RFC5681] Allman, M., Paxson, V., and E. Blanton, "TCP Congestion Control", RFC 5681, DOI 10.17487/RFC5681, September 2009, <https://www.rfc-editor.org/info/rfc5681>.
[RFC6040] Briscoe, B., "Tunnelling of Explicit Congestion Notification", RFC 6040, DOI 10.17487/RFC6040, November 2010, <https://www.rfc-editor.org/info/rfc6040>.
[RFC6679] Westerlund, M., Johansson, I., Perkins, C., O'Hanlon, P., and K. Carlberg, "Explicit Congestion Notification (ECN) for RTP over UDP", RFC 6679, DOI 10.17487/RFC6679, August 2012, <https://www.rfc-editor.org/info/rfc6679>.
[RFC6817] Shalunov, S., Hazel, G., Iyengar, J., and M. Kuehlewind, "Low Extra Delay Background Transport (LEDBAT)", RFC 6817, DOI 10.17487/RFC6817, December 2012, <https://www.rfc-editor.org/info/rfc6817>.
[RFC6973] Cooper, A., Tschofenig, H., Aboba, B., Peterson, J., Morris, J., Hansen, M., and R. Smith, "Privacy Considerations for Internet Protocols", RFC 6973, DOI 10.17487/RFC6973, July 2013, <https://www.rfc-editor.org/info/rfc6973>.
[RFC7560] Kuehlewind, M., Ed., Scheffenegger, R., and B. Briscoe, "Problem Statement and Requirements for Increased Accuracy in Explicit Congestion Notification (ECN) Feedback", RFC 7560, DOI 10.17487/RFC7560, August 2015, <https://www.rfc-editor.org/info/rfc7560>.
[RFC7567] Baker, F., Ed. and G. Fairhurst, Ed., "IETF Recommendations Regarding Active Queue Management", BCP 197, RFC 7567, DOI 10.17487/RFC7567, July 2015, <https://www.rfc-editor.org/info/rfc7567>.
[RFC7665] Halpern, J., Ed. and C. Pignataro, Ed., "Service Function Chaining (SFC) Architecture", RFC 7665, DOI 10.17487/RFC7665, October 2015, <https://www.rfc-editor.org/info/rfc7665>.
[RFC7713] Mathis, M. and B. Briscoe, "Congestion Exposure (ConEx) Concepts, Abstract Mechanism, and Requirements", RFC 7713, DOI 10.17487/RFC7713, December 2015, <https://www.rfc-editor.org/info/rfc7713>.
[RFC8033] Pan, R., Natarajan, P., Baker, F., and G. White, "Proportional Integral Controller Enhanced (PIE): A Lightweight Control Scheme to Address the Bufferbloat Problem", RFC 8033, DOI 10.17487/RFC8033, February 2017, <https://www.rfc-editor.org/info/rfc8033>.
[RFC8034] White, G. and R. Pan, "Active Queue Management (AQM) Based on Proportional Integral Controller Enhanced (PIE) for Data-Over-Cable Service Interface Specifications (DOCSIS) Cable Modems", RFC 8034, DOI 10.17487/RFC8034, February 2017, <https://www.rfc-editor.org/info/rfc8034>.
[RFC8170] Thaler, D., Ed., "Planning for Protocol Adoption and Subsequent Transitions", RFC 8170, DOI 10.17487/RFC8170, May 2017, <https://www.rfc-editor.org/info/rfc8170>.
[RFC8257] Bensley, S., Thaler, D., Balasubramanian, P., Eggert, L., and G. Judd, "Data Center TCP (DCTCP): TCP Congestion Control for Data Centers", RFC 8257, DOI 10.17487/RFC8257, October 2017, <https://www.rfc-editor.org/info/rfc8257>.
[RFC8290] Hoeiland-Joergensen, T., McKenney, P., Taht, D., Gettys, J., and E. Dumazet, "The Flow Queue CoDel Packet Scheduler and Active Queue Management Algorithm", RFC 8290, DOI 10.17487/RFC8290, January 2018, <https://www.rfc-editor.org/info/rfc8290>.
[RFC8298] Johansson, I. and Z. Sarker, "Self-Clocked Rate Adaptation for Multimedia", RFC 8298, DOI 10.17487/RFC8298, December 2017, <https://www.rfc-editor.org/info/rfc8298>.
[RFC8311] Black, D., "Relaxing Restrictions on Explicit Congestion Notification (ECN) Experimentation", RFC 8311, DOI 10.17487/RFC8311, January 2018, <https://www.rfc-editor.org/info/rfc8311>.
[RFC8312] Rhee, I., Xu, L., Ha, S., Zimmermann, A., Eggert, L., and R. Scheffenegger, "CUBIC for Fast Long-Distance Networks", RFC 8312, DOI 10.17487/RFC8312, February 2018, <https://www.rfc-editor.org/info/rfc8312>.
[RFC8404] Moriarty, K., Ed. and A. Morton, Ed., "Effects of Pervasive Encryption on Operators", RFC 8404, DOI 10.17487/RFC8404, July 2018, <https://www.rfc-editor.org/info/rfc8404>.
[RFC8511] Khademi, N., Welzl, M., Armitage, G., and G. Fairhurst, "TCP Alternative Backoff with ECN (ABE)", RFC 8511, DOI 10.17487/RFC8511, December 2018, <https://www.rfc-editor.org/info/rfc8511>.
[RFC8888] Sarker, Z., Perkins, C., Singh, V., and M. Ramalho, "RTP Control Protocol (RTCP) Feedback for Congestion Control", RFC 8888, DOI 10.17487/RFC8888, January 2021, <https://www.rfc-editor.org/info/rfc8888>.
[RFC8985] Cheng, Y., Cardwell, N., Dukkipati, N., and P. Jha, "The RACK-TLP Loss Detection Algorithm for TCP", RFC 8985, DOI 10.17487/RFC8985, February 2021, <https://www.rfc-editor.org/info/rfc8985>.
[RFC9000] Iyengar, J., Ed. and M. Thomson, Ed., "QUIC: A UDP-Based Multiplexed and Secure Transport", RFC 9000, DOI 10.17487/RFC9000, May 2021, <https://www.rfc-editor.org/info/rfc9000>.
[RFC9113] Thomson, M., Ed. and C. Benfield, Ed., "HTTP/2", RFC 9113, DOI 10.17487/RFC9113, June 2022, <https://www.rfc-editor.org/info/rfc9113>.
[RFC9331] De Schepper, K. and B. Briscoe, Ed., "The Explicit Congestion Notification (ECN) Protocol for Low Latency, Low Loss, and Scalable Throughput (L4S)", RFC 9331, DOI 10.17487/RFC9331, January 2023, <https://www.rfc-editor.org/info/rfc9331>.
[RFC9332] De Schepper, K., Briscoe, B., Ed., and G. White, "Dual-Queue Coupled Active Queue Management (AQM) for Low Latency, Low Loss, and Scalable Throughput (L4S)", RFC 9332, DOI 10.17487/RFC9332, January 2023, <https://www.rfc-editor.org/info/rfc9332>.
[SCReAM-L4S] "SCReAM", commit fda6c53, June 2022, <https://github.com/EricssonResearch/scream>.
[TCP-CA] Jacobson, V. and M. Karels, "Congestion Avoidance and Control", Laurence Berkeley Labs Technical Report , November 1988, <https://ee.lbl.gov/papers/congavoid.pdf>.
[UnorderedLTE] Austrheim, M., "Implementing immediate forwarding for 4G in a network simulator", Master's Thesis, University of Oslo, 2018. <https://www.duo.uio.no/bitstream/handle/10852/68158/5/thesis.pdf>
謝辞
リチャード・シェフェネッガー、ウェス・エディ、カレン・ニールセン、デビッド・ブラック、ジェイク・ホランド、ヴィディ・ゴエル、エルミン・サケク、プラヴィーン・バラスブラマニアン、ゴリー・フェアハースト、ミルヤ・クーレヴィンド、フィリップ・イアードリー、ニール・カードウェル、ピート・ハイスト、マーティン・デュークの有益なレビューコメントに感謝する。また、エリア・レビュアーのマルコ・ティロカ、ラース・エガート、ローマン・ダニリュー、エリック・ヴィンクにも感謝する。
ボブ・ブリスコウとケーン・デ・シェッパーは、欧州共同体の第7次フレームワーク・プログラムによるインターネット・トランスポート遅延の削減(RITE) プロジェクト (ICT-317700)の一部資金援助を受けた。ケーン・デ・シェッパーの貢献は、5GrowthおよびDAEMON EU H2020プロジェクトからも一部資金提供を受けている。ボブ・ブリスコウは、TimeInプロジェクトを通じてノルウェー研究評議会から一部、ケーブルラボから、Comcast Innovation Fundから、一部資金援助を受けている。ここで表明された見解は、あくまでも著者個人の見解である。
著書のアドレス
ボブ・ブリスコウ (編集者)
Independent
イギリス
メール: ietf@bobbriscoe.net
URI: https://bobbriscoe.net/
ケーン・デ・シェッパー
Nokia Bell Labs
アントワープ
ベルギー
メール: koen.de_schepper@nokia.com
URI: https://www.bell-labs.com/about/researcher-profiles/koende_schepper/
マルセロ・バニュロ
Universidad Carlos III de Madrid
Av. Universidad 30
28911 Madrid
スペイン
電話: 34 91 6249500
メール: marcelo@it.uc3m.es
URI: https://www.it.uc3m.es
グレッグ・ホワイト
CableLabs
米国
メール: G.White@CableLabs.com
変更履歴
- 2023.12.25
- 2023.12.28
- 2024.1.18
- 2024.1.25
- 2024.5.30: 誤字修正
Discussion