AWS ECS Cluster Auto Scaling について
AWS ECS Cluster Auto Scaling は AWS ECS Cluster のキャパシティを超える Task の起動要求が有った時に、設定されたルールに則って ECS 実行環境(Fargate、EC2 インスタンス)の拡張を行なう機能です。
Kubernetes における Cluster AutoScaler と同等の機能を提供する仕組み、と個人的には認識しています。
この機能は2019年に公開された機能のようですが、私個人は ECS (AWS) を使用する環境からしばらく離れていたこともあり最近機能を知りました。
AWS ECS Cluster Auto Scaling を有効にすることで、必要な Task の起動要求をするだけで、裏側で環境の自動スケーリングが行われるようになります。
つまり ECS 運用者は ECS 実行環境のキャパシティをあまり気にすることなく、ただ Task の上げ下げだけをすれば良い、という状況が期待できます。
もちろんこの辺は Fargate 上で運用している場合はあまり気にならないかもしれませんが、 ECS on EC2 の環境で ECS クラスタを構築している場合は必須の設定になると感じています。
この記事では、具体的に環境構築を行った内容を記載し、構築時に気になったことについてもおまけ程度にメモとして記載しておきます。
overview
意外と登場人物も多く、仕組みも若干複雑に見えるため、AWS ECS Cluster Auto Scaling の仕組みについて簡単に図解してみました。
AWS ECS Cluster Auto Scaling の登場人物
- ECS 実行環境
- Fargate / Fargate Spot
- ECS on EC2
- ※今回の記事は ECS on EC2 限定で記載します
- ECS Cluster / Service / Task
- EC2 Auto Scaling Group
- 同じ起動設定 (Launch Template) の EC2 インスタンスを要求された数だけ起動・停止する仕組み
-
AWS ECS Capacity Provider
- ECS の Task 状況を監視し、実行環境の拡張が必要な場合に命令を出す仕組み
- CloudWatch Metrics
- ECS クラスターの Task 稼働状況を監視
flow
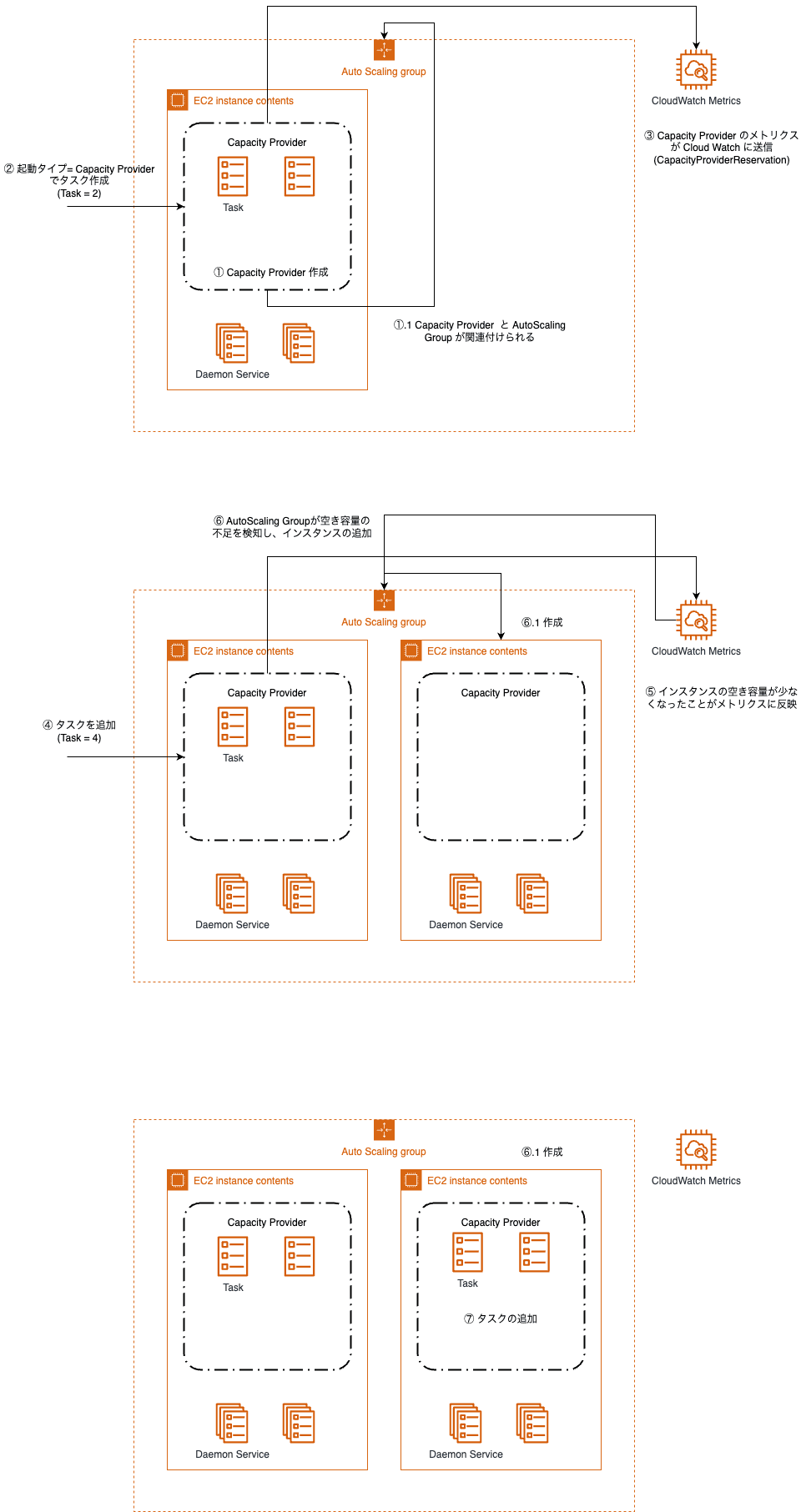
図中の番号を箇条書きでも記載します。
ECS on EC2 の環境は構築済み、という前提になります。また1台の EC2 環境に Task が2つまでしか立ち上がらない、という前提とします。
- Capacity Provider 作成
- Capacity Provider と Auto Scaling Group を関連付ける。
- これにより ASG 側が任意の ECS Service の Task 数に応じてインスタンスの増減のハンドリングを行えるようになる
- Capacity Provider と Auto Scaling Group を関連付ける。
- 起動タイプ = Capacity Provider で ECS タスク作成 (e.g. Task = 2)
- Capacity Provider のメトリクスが CloudWatch に送信 (CapacityProviderReservation)
- 2と同様の形で、さらに ECS タスクを追加 (e.g. Task = 4)
- インスタンスの空き容量が少なくなったことが CloudWatch に反映
- AutoScaling Group が空き容量の不足を検知し、インスタンスの追加
- 必要な量の EC2 インスタンスの追加
- 追加されたインスタンスに、必要な分の ECS Task が追加
detail
全体的なしくみ
上記では概要を記述していますが、より詳細な解説については以下の公式サイトに掲載されています。
この記事では仕組みの細かい解説についてはこの辺にし、以降では Terraform を使った構築手順について記載します。
Terraform Configuration
Terraform で設定する際に必要な構成要素について記述します。
ECS on EC2 の環境自体を動作させるために必要な設定については割愛しています。
(aws_ecs_cluster, aws_launch_template, aws_autoscaling_group 等)
aws_ecs_capacity_provider
AWS ECS Capacity Provider の設定です。
公式ドキュメントの Snipet を貼ります
resource "aws_ecs_capacity_provider" "test" {
name = "test"
auto_scaling_group_provider {
auto_scaling_group_arn = aws_autoscaling_group.test.arn
managed_termination_protection = "ENABLED"
managed_scaling {
maximum_scaling_step_size = 1000
minimum_scaling_step_size = 1
status = "ENABLED"
target_capacity = 10
}
}
}
target_capacity は、対象とするリソースのキャパシティをどの程度まで使用したらインフラ拡張するか、を判定する数値です。
100 の場合、EC2 インスタンス等のリソースを100%使うことを目指し、リソースのキャパシティが足らない場合は ASG を介して EC2 インスタンスを増やします
80 を指定した場合、リソースを 80% 使用したら増設トリガーが発火します
status は ENABLED
maximum_scaling_step_size、minimum_scaling_step_size は小規模な環境であればそれぞれ 1 を設定します (scale out, scale in を行なう際に一度に増減させるインスタンス数を指定)
aws_ecs_cluster_capacity_providers
その Cluster の中で使用する Default の Capacity Provider の設定を行います。
resource "aws_ecs_cluster_capacity_providers" "fargate" {
cluster_name = aws_ecs_cluster.example.name
capacity_providers = ["FARGATE"]
default_capacity_provider_strategy {
base = 1
weight = 100
capacity_provider = "FARGATE"
}
}
上記は capacity_providers に FARGATE を指定した例ですが、ECS on EC2 の場合は独自で作成した Capacity Provider を指定することになります。以下のように作成した capacity provider の name の値を渡します。
resource "aws_ecs_cluster_capacity_providers" "ecs_on_ec2" {
cluster_name = aws_ecs_cluster.example.name
capacity_providers = [aws_ecs_capacity_provider.test.name]
default_capacity_provider_strategy {
base = 1
weight = 100
capacity_provider = aws_ecs_capacity_provider.test.name
}
}
Capacity Provider は複数を関連付けることができますが、何も指定されなかった時にデフォルトで使用されるもの (default capacity provider strategy) も指定する必要があります。
一つしか関連付けを行わない場合は、capacity_providers、default_capacity_provider_strategy ともに同じ CapacityProvider を指定します。
ECS Service の launchType の指定
上記の Terraform の設定を適用すれば、基本的に CapacityProvider 関連の環境構築は完了です。
あとは、ECS Service の起動時に任意の、もしくはデフォルトの CapacityProvider 戦略を指定して起動をすれば、その Service は CapacityProvider と関連付けが行われ、リソースの使用状況に応じて自動的に EC2 インスタンスの拡張が行われるようになります。
イメージが付きやすいように Web Console の画像を貼ります。
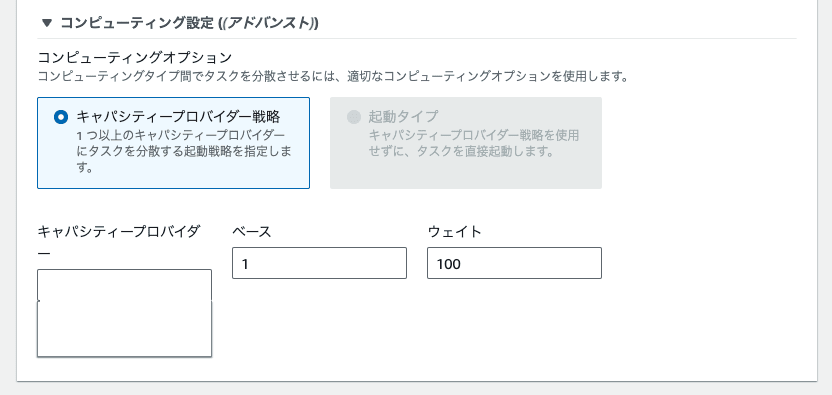
なお、ECS 関連のユーティリティツールである ecspresso では、LaunchType にキャパシティープロバイダー戦略を指定する場合は 「LaunchType 自体の記述を行わない」 という必要があるようです。
他に方法はあるかもしれませんが、ドキュメント等は無さそうなので、エスパー能力を発揮して上記仕様については把握しました
Capacity Provider と AutoScaling Group の関連
ECS on EC2 における Cluster Auto Scaling は、基本的には AutoScaling Group の仕組みを用いて実施されます。
より具体的には、AutoScaling Group の 「動的スケーリングポリシー」 によって行われます。
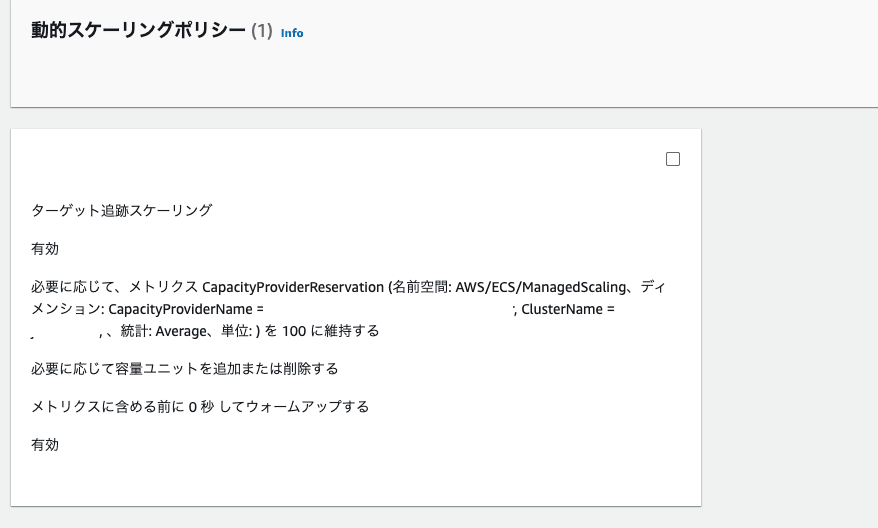
Capacity Provider は作成時に、AutoScaling Group と CloudWatch Metrics に対して、以下の処理を行います
- CapacityProviderReservation メトリクスの追加 (CloudWatch)
- 動的スケーリングポリシーの作成(AutoScaling Group)
- 動的スケーリングポリシーでは、CapacityProviderReservation を定期的に監視し、メトリクスがポリシーを満たさない場合(CapacityProviderで指定したターゲット数値を下回る場合)にインスタンスの追加処理を行なう
CapacityProvider では様々な定義の関連付けを行う役割になり、実際にインスタンスの追加等のイベントを実施するのは AutoScaling Group の責務になります。
そして、インスタンスを追加するか否かの判断は、上記動的スケーリングポリシーに定義されたルールに基づいて行われ、ルールで使用される様々なメトリクスは CloudWatch Metrics により管理される、という役割分担になっています。
色々と複雑ですが、この設定により、ECS on EC2 の環境下でもリソースが足らなくなったら EC2 インスタンスが自動的に追加される、という環境を実現できるようになります。
make notes
私が上記対応を行っていく中で気になった点について記載していきます
作業時のトラブル
検証環境構築に際して、何回か環境の作り直しをしている中で以下について遭遇しました。
ECS Cluster の default capacity provider strategy の変更が行えない
問題点
terraform では aws_ecs_cluster_capacity_providers で設定する項目です。
こちらの内容については、すでに使用しているサービスが存在する状態では、変更作業が行えません。
名前の変更など軽微と思われる内容についても然りです。変更だけでなく削除処理も行えません。
変更するためには
- default capacity provider strategy を使用しているすべての ECS Service を削除
- default capacity provider strategy 関連の設定変更
- ECS Service を作り直し
という手順を踏む必要があります。
サービスの実運用を開始してからこれらの作業を行なうことは現実的には難しく、対応時はサービスメンテナンスなどを行なう必要があるため、初期設定時から注意して行う必要があります。
解決策
特に無し。
上述の様に、基本的に変更が発生しないようにする。どうしても変更しないと行けない時はメンテナンス時に対応
Capcity Provider を Terraform 経由で削除すると、同名で作り直した時に CloudWatch Metrics の連携が行われない
問題点
すでに Terraform 経由で作成済みの CapacityProvider について、以下のような手順を踏むと、CloudWatch Metrics にメトリクスが送られなくなります。
結果として、AWS ECS Cluster Auto Scaling が正しく動作しなくなります
- aws_ecs_capacity_provider の作成
- aws_ecs_capacity_provider の定義をコメントアウトするなどして、削除し apply
# resource "aws_ecs_capacity_provider" "sada" {
# name = "capacity-provider-sada"
# auto_scaling_group_provider {
# auto_scaling_group_arn = aws_autoscaling_group.sada.arn
# managed_scaling {
# maximum_scaling_step_size = 1
# minimum_scaling_step_size = 1
# status = "ENABLED"
# target_capacity = 100
# }
# }
# }
3.1と同じ情報で capacity provider の再作成
この原因はよくわからないですが、Terraform Provider の実装バグか、AWS 自体のバグと思われます。
解決策
抜本的なものは特になし
運用で回避しようとするなら以下で回避可能です
- 作った CapacityProvider は基本的に削除しない
- どうしても削除が必要な場合は AWS Console 上から削除
- Console から削除した後であれば、手で作り直しても Terraform で作り直しても、CloudWatch Metrics との連携は正しく行われるのは確認済みです
Discussion