Phi-4 QLoRAファインチューニングプロジェクト:「的確性」を軸としたLLM評価手法の検討
はじめに
チャットボット開発に取り組む中で、一つの課題を感じました。高性能かつ軽量なLLMであるMicrosoft Phi-4が生成する回答は確かに正確で丁寧なのですが、時として必要以上に詳しく、冗長になってしまうのです。
ただし、単純に出力を短くすれば良いというわけではありません。重要なキーワードや文脈を失い、かえって誤解や不正確な情報を提供してしまうリスクがあります。私が目指していたのは、「丁寧さを保ちながら、簡潔で的確な回答を実現する」という、一見矛盾するような改善でした。
この取り組みを進める過程で、従来のLLM評価手法の課題に直面し、LLM-as-a-Judgeという手法を参考に簡単な評価システムを構築してみました。今回は、その過程で学んだことを共有させていただきたいと思います。
第1章:ファインチューニングへの挑戦
1.1 問題の整理
実際にPhi-4をチャットボットに組み込んで運用してみると、以下の課題が見えてきました:
- 冗長性の問題:同じ内容を異なる表現で繰り返す傾向(以下補足)
- 構造の不明確性:要点が詳細な説明に埋もれてしまう
- 効率性の課題:不要に長い回答による処理時間とコストの増大
しかし、これらを改善しようとして出力を単純に短縮すると、今度は以下のような問題が生じます:
- 情報不足:必要な詳細が欠落してしまう
- 文脈の喪失:理解に必要な背景情報の不足
- ハルシネーションのリスク:情報を削りすぎることで、間違った情報を補完してしまう可能性
1.2 ファインチューニングの目標設定
この問題を解決するため、以下の3つの目標を定めてLoRAファインチューニングに取り組むことにしました:
- 冗長性の軽減:無駄な表現や重複を減らし、簡潔な回答を実現する
- 指示への忠実性:ユーザーの質問の意図を正確に捉え、的確に応答する
- ハルシネーション抑制:事実に基づいた正確な情報提供を維持する
これらの目標は、一見すると相反するものに見えるかもしれません。簡潔にしすぎれば情報が不足し、正確性を重視すれば冗長になりがちです。ただ、人間の優秀な専門家は、この絶妙なバランスを自然に取っています。LLMにも同様の能力を持たせることができるのではないかと考えました。
1.3 技術的なアプローチ
Phi-4のSFT(Supervised Fine-Tuning)は、Unslothの4-bit量子化モデルにQLoRAを適用した実装に対し、ハイパーパラメータやスクリプトを一部修正して実施しました。
LoRAファインチューニングの設計では、以下の点に特に注意を払いました:
データセット選択:
- 使用データセット:msfm/ichikara-instruction-all(3,841サンプル)
- 訓練サイズ:80% (3,073サンプル)
- テストサイズ:20% (768サンプル)
LoRA設定の調整:
- ランク (r): 8 - 表現力と制御のバランスを取る控えめな設定
- Alpha: 16 - Alpha/r = 2.0の比率により、ハルシネーション抑制と応答品質のバランスを狙う
- 対象モジュール: ["q_proj", "v_proj", "o_proj"] - 注意機構の精度向上に集中
- Dropout: 0.05 - 学習の安定性を確保しつつ汎化性能を維持
この設計は、「過度な学習は避けながらも、目標に沿った改善を目指す」という慎重な考えに基づいています。
第2章:ファインチューニングの成果
2.1 学習過程の観察
学習過程の詳細:
訓練設定:
- 訓練データ数:3,073サンプル
- バッチサイズ:2(勾配蓄積4ステップで実効バッチサイズ8)
- 総ステップ数:約500ステップ(1.3エポック相当)
学習過程の観察:
学習の初期段階(約12ステップ、0.03エポック相当)からロス改善の兆候が見られ、最終的な1.3エポック(約500ステップ)の学習で訓練ロスが16.5%減少しました(1.1499 → 0.9602)。
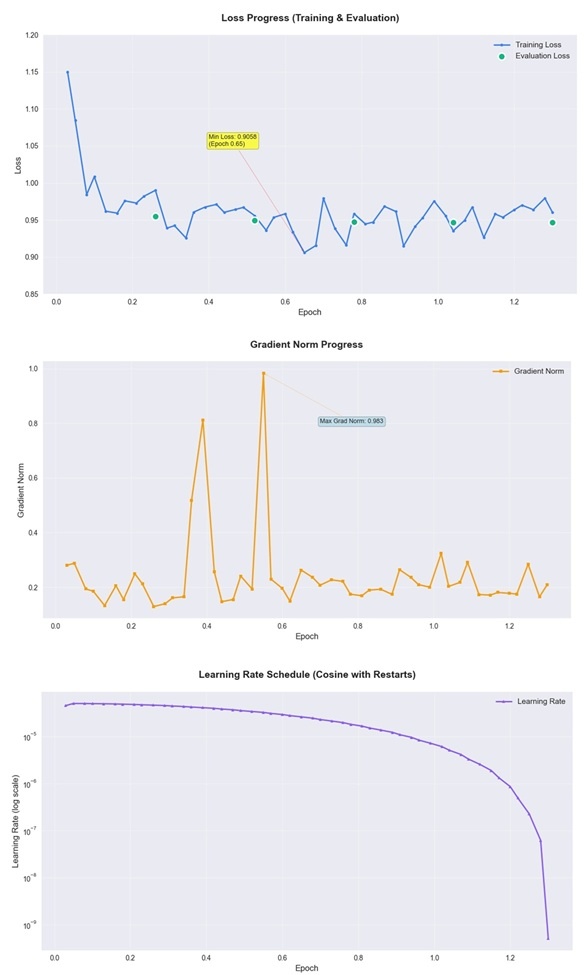
2.2 設計判断の振り返り
後から振り返ると、以下の設計判断が安定した学習に寄与したと考えています:
適切なパラメータバランス:
- r=8という控えめな設定により、表現力を保ちながら過度な適応を回避
- Alpha/r = 2.0の比率が、新しい学習内容の重みを適度に抑制し、ベースモデルの知識を保持
ターゲットモジュール選択の試み:
-
q_proj,v_proj,o_projに限定し、k_projを除外する設計を採用 -
k_proj除外により「Key表現能力を制約し、過度な情報参照を防ぐ」ことで冗長性の軽減を狙い、Queryによる質問理解とValueによる情報抽出、Outputによる統合は保持しつつ、冗長性を効果的に制御できると考えました。
安定した学習過程:
- 評価ロスと訓練ロスが同期して改善し、過学習を回避
- 勾配ノルムが適切に制御され、学習の安定性を確保
第3章:評価の課題 - 従来手法の限界
3.1 模範回答バイアスの問題
ファインチューニングが完了した後、その効果を定量的に評価しようとELYZA-tasks-100を使った評価を試みました。ELYZA-tasks-100は日本語特化の優れたベンチマークで、日常的な質問応答、創造的な文章生成、指示追従など実用的なタスクを包括的にカバーしています。模範回答との類似度評価という従来手法において、以下の課題が明らかになりました:
模範回答バイアスの構造:
問題: ELYZA-tasks-100の参考回答との類似度評価
↓
結果: LoRAの簡潔化効果が「模範回答と違う」というだけで低評価
↓
課題: ファインチューニングの真の改善効果を適切に評価できない
例えば、LoRAモデルが冗長性を削減して簡潔で的確な回答を生成したとしても、模範回答が詳細で丁寧な回答だった場合、類似度の観点では「劣っている」と判定されてしまいます。これは、ファインチューニングの目的とは相反する評価基準でした。
重要な認識:
この課題はELYZA-tasks-100固有の問題ではありません。同様の課題は、模範回答との類似度を評価基準とする一般的なベンチマーク評価手法に共通して存在します。
ELYZA-tasks-100自体は実用的で高品質なベンチマークとして優れた特性を持っています。
3.2 評価における根本的な課題
さらに考察を深めると、LLM評価における課題が見えてきました:
- 詳細 vs 簡潔:どちらが「良い」回答なのか?
- 忠実性 vs 創造性:指示に忠実だと多様性が減る?
- 冗長性削減 vs 情報不足:バランスをどう評価する?
これらの問題は、従来の評価手法が「結果の比較」に重点を置き、「改善の目的」を十分考慮していないことに起因していると感じました。
3.3 新しい評価アプローチの検討
この課題から、異なる評価のアプローチを検討するようになりました。人間が日常的に行っている質問と回答のやり取りを観察すると、質問には主に2つの種類があることに気づきました:
- 真の情報需要:本当にわからないから真実や考えを聞く
- 判断委託:質問者に答えのイメージがあり、判断を委ねる
そして、どちらの場合でも、優れた回答には共通の特徴があるようでした:
- 核心的な正解・重要なキーワード・表現が含まれている
- 問いの本質を理解した上で適切に答えている
- 冗長な説明は逆効果 - 簡潔で明快であることが望ましい
これらの観察から、「的確性」という総合評価指標の概念について検討を始めました。「的確性」とは、質問の本質を理解し、簡潔でありながら必要十分な情報を正確かつ明快に提供する能力と定義し、これを複数の下位尺度から総合的に評価するアプローチを検討しました。
第4章:評価システムの検討と設計
4.1 評価の考え方の転換
従来の評価手法の限界を踏まえ、異なるアプローチを検討しました:
従来手法:「どちらが良い回答か?」(主観的・曖昧)
検討した手法:「ファインチューニングの目的により合致しているのはどちらか?」(目的志向・明確)
この転換により、評価者に明確な判断基準を提供し、一貫性のある評価を目指すことができると考えました。
4.2 LLM-as-a-Judgeを参考にした評価システム
人間の専門家による評価会議を参考に、LLM-as-a-Judgeの手法をベースとし、複数のLLMが共通の観点から評価を行い、最終的に統合判断を下すシンプルなシステムを検討しました:
Judge Agents(評価者):
- deepseek-r1:8b - 推論・分析に特化
- qwen3:8b - 思考過程・理由明示に強み
- gemma3:12b - バランス型の評価
Manager Agent(最終裁定者):
- gpt-oss:20b - 2025年8月にOpenAIがリリースした最新のオープンウェイトモデル
4.3 評価プロセスの設計
設計した評価プロセスは、人間の専門家が行う評価会議を参考にしています:
1. 目的明示 → ファインチューニングの狙いをすべてのエージェントに伝達
2. 多角評価 → 各Judge Agentが観点別にスコア・理由付き評価
3. 意見交換 → 異なる観点からの評価結果を統合
4. 統合判定 → Manager Agentが最終的にA/B/uncertainで結論
5. 透明性確保 → 全判定に理由コメントを必須とし、説明責任を果たす
4.4 「的確性」総合指標と下位尺度の設計
「的確性」を総合評価指標として位置づけ、ファインチューニングの目的に沿った評価体系の構築を試みました。「的確性」とは、質問の本質を理解し、簡潔でありながら必要十分な情報を正確かつ明快に提供する能力と定義しました。
「的確性」の構成要素
以下の4つの下位尺度から構成される評価体系を設計しました:
- 問いの核心理解 - 質問文から本質的な問題・疑問点を正確に抽出する能力
- 簡潔さと過不足のなさ - 冗長でないか、必要な情報があるか
- 正確性 - 事実誤認・論理的誤りがないか
- 表現の整理度 - 明快な構成、読者に理解しやすいか
評価観点設計の課題と限界
概念的重複の問題:
- 「核心理解」と当初目的の「指示への忠実性」には概念的重複があります
- 実際の評価では、Judge Agentがこれらの観点を明確に分離できているかは不明です
- 多くの場合、核心理解の誤りは指示忠実性の低下を伴うため、独立した評価が困難です
用語定義の主観性:
- 「冗長でない」「明快な構成」などの判断基準は主観的要素を含みます
- 評価者(Judge Agent)間での基準の一貫性は保証されていません
「的確性」の合成方法と限界
現在の統合方法:
- Manager Agentによる主観的統合判断
- 各観点の重み付けは実施していません
- 定量的な合成ルールは設定していません
方法論的制約:
4つの下位尺度は独立して評価されますが、以下の制約があります:
- 合成アルゴリズムの不在:数学的な合成ルールが確立されていません
- 重み付けの未設定:各観点の相対的重要度が定義されていません
- 主観的統合判断:Manager Agentの判断プロセスがブラックボックス化しています
今後の検討課題
技術的改善:
- 各下位尺度の重み付け方法の確立
- 定量的な合成アルゴリズムの開発
- 統合判断の一貫性・再現性の検証
概念的改善:
- 評価観点間の独立性を高める設計の改善
- Judge Agentの観点別評価能力の検証
- 概念的重複を考慮した評価体系の再設計
研究の位置づけ
現段階では「的確性」は概念的な総合指標であり、厳密な数学的合成は実現できていないことを認識しています。本研究は、従来の単一指標評価に対する一つの対処の試みとして位置づけられ、今後のより厳密な評価手法開発への基礎検討としての意義があると考えています。
第5章:技術実装 - Docker + LangGraphによる実現
5.1 アーキテクチャの選択
評価システムの実装にあたり、以下の技術スタックを選択しました:
- フレームワーク:LangGraph + asyncio非同期処理
- LLM基盤:Ollama (ローカル実行環境)
- コンテナ環境:Docker Compose
- GPU環境:NVIDIA RTX A5000 24GB
この構成により、完全にローカル環境で動作し、外部APIに依存しない評価システムの実現を試みました。
5.2 LangGraphによる協調エージェントシステム
評価システムでは以下のような流れを実装しました:
- 各エージェントが協調するLangGraphのワークフロー
- LangGraphの構造定義
# グラフ構造の定義
def create_evaluation_graph():
# StateGraphでEvaluationState型を使用
graph = StateGraph(EvaluationState)
# ノード追加(全て非同期関数)
graph.add_node("input", input_node)
graph.add_node("judges_parallel", execute_all_judges)
graph.add_node("manager", manager_node)
graph.add_node("output", output_node)
# シーケンシャルフロー
graph.set_entry_point("input")
graph.add_edge("input", "judges_parallel")
graph.add_edge("judges_parallel", "manager")
graph.add_edge("manager", "output")
graph.add_edge("output", END)
return graph.compile()
- 3つのJudge Agentを並列実行し、すべての評価が完了してからManager Agentに渡すよう設計しました。
async def evaluate_all_judges_parallel(self, state: EvaluationState):
# 3つのJudgeタスクを作成
judge_tasks = [
self._evaluate_single_judge("deepseek", state),
self._evaluate_single_judge("qwen", state),
self._evaluate_single_judge("gemma", state)
]
# 並列処理
judge_results = await asyncio.gather(*judge_tasks, return_exceptions=True)
以下の「67%以上」の基準は、厳密な統計的根拠ではなく、約2/3という安定した多数派とみなすしきい値として設定しました。
# 簡略判定
if len(winners) == 1 and max_votes > total_votes // 2:
consensus = winners[0]
confidence = max_votes / total_votes
pattern = "majority" if confidence >= 0.67 else "plurality"
elif len(winners) == 1:
consensus = winners[0]
confidence = max_votes / total_votes
pattern = "weak_consensus"
else:
consensus = "tie"
confidence = max_votes / total_votes
pattern = "tie"
- プロンプトテンプレート
評価エージェントの判断精度を高めるため、それぞれの役割に特化したプロンプトテンプレートを設計しました。本システムでは、3つのJudge Agentが個別評価を行う「Judge用プロンプト」と、それらの結果を統合する「Manager用プロンプト」の2種類を使用しています。
Judge用プロンプトの設計ポイント:
- 従来の模範回答との類似度評価ではなく、ファインチューニングの目的達成度に焦点を当てた評価軸
- 「的確性」の4つの構成要素(簡潔さ、核心理解、正確性、明快さ)を明示した評価観点
- JSON形式による構造化された出力で、後続処理での一貫性を確保
- トークン数情報を提供し、冗長性評価の参考情報として活用
JUDGE_PROMPT = """
あなたは優秀なLLM評価者です。以下の2つの回答(AとB)を比較し、
**LoRAファインチューニングの目的**に照らして評価してください。
【ベースモデルをLoRAファインチューニングした真の目的】
ユーザーの問いに対して、「簡潔・明快に、質問意図を外さず、正確に回答できる」能力の向上
【評価観点】
1. 簡潔さと過不足のなさ(冗長でないか)
2. 質問の核心理解(問いの本質を捉えているか)
3. 正確性(事実・論理的誤りがないか)
4. 表現の整理度(明快な構成、読者に優しいか)
【質問】: {input}
【模範回答(参考)】: {reference}
【回答A(ベースモデル)】: {base_output} ({base_tokens}トークン)
【回答B(LoRAモデル)】: {lora_output} ({lora_tokens}トークン)
【出力形式(JSON)】:
{{
"better": "A" または "B",
"scores": {{
"conciseness": [0-10],
"core_understanding": [0-10],
"factual_accuracy": [0-10],
"clarity": [0-10]
}},
"reason": "どちらがなぜ優れているかを100文字以内で説明"
}}
"""
Manager用プロンプトの設計ポイント:
- 3つのJudge評価を総合し、最終的な判断を下す統合者としての役割明示
- 評価が分かれた場合の明確な判断指針を提供
- 4つの評価観点それぞれについて詳細な判定を求める観点別分析
MANAGER_PROMPT = """
あなたは評価マネージャーAIです。以下のJudge評価に基づき、
LoRAファインチューニング目的に対して A か B がより目的に沿っているか判断してください。
【ベースモデルをLoRAファインチューニングした真の目的】
「モデルが、ユーザーの意図を過不足なく捉え、簡潔で明快かつ正確な回答を返す適性を高めたか」
【Judge評価結果】
- deepseek-r1: {deepseek_result}
- qwen3: {qwen3_result}
- gemma3: {gemma3_result}
【意見分岐時の判断基準】
議論や再評価は行わず、上記の「真の目的」に照らして統合判断を下してください。
【出力形式(JSON)】
{{
"最終判断": "A" または "B" または "uncertain",
"理由要約": "100文字以内の総合理由",
"スコア内訳": {{
"簡潔さ": "A" または "B" または "Tie",
"核心理解": "A" または "B" または "Tie",
"正確性": "A" または "B" または "Tie",
"明快さ": "A" または "B" または "Tie"
}}
}}
"""
これらのプロンプト設計により、模範回答バイアスを回避し、ファインチューニングの実際の目的に沿った評価を実現することを意図しています。
この設計により、再現性と検証可能性の確保を目指しました。
第6章:評価結果と観察
6.1 評価システムの動作
システムが完成し、ELYZA-tasks-100の全100タスクで評価を実行しました。結果は以下の通りでした:
システム性能:
- 成功率:100%(全タスクで正常動作)
- 平均処理時間:約97分(5816.8秒)
- 安定性:エラーによる中断ゼロ
この安定性は、評価システムとしての基本的な動作を確認するものでした。特に、複数のLLMエージェントが協調して動作し、全てのタスクを完了できたことは、システム設計が一定程度機能したことを示していると思われます。
6.2 LoRAファインチューニング効果の観察
最も重要な発見は、従来の評価手法では見えにくかった改善効果を観察できたことです。Manager AgentであるOpenAI gpt-oss 20Bによる最終統合判断の結果は以下の通りでした:
Manager Agent最終判断結果:
ベースモデル勝利: 46問 (46.0%)
LoRAモデル勝利: 53問 (53.0%)
判定保留: 1問 ( 1.0%)
--------------------------------
LoRA改善効果: +7.0ポイント
LoRA勝利率: 53.5% (判定保留除く)
この53.5%という勝利率は、過度に楽観的でも悲観的でもない、現実的な結果として解釈できます。従来の模範回答ベースの評価では観察しにくい、LoRAファインチューニングの改善効果の一面が見えた可能性があります。
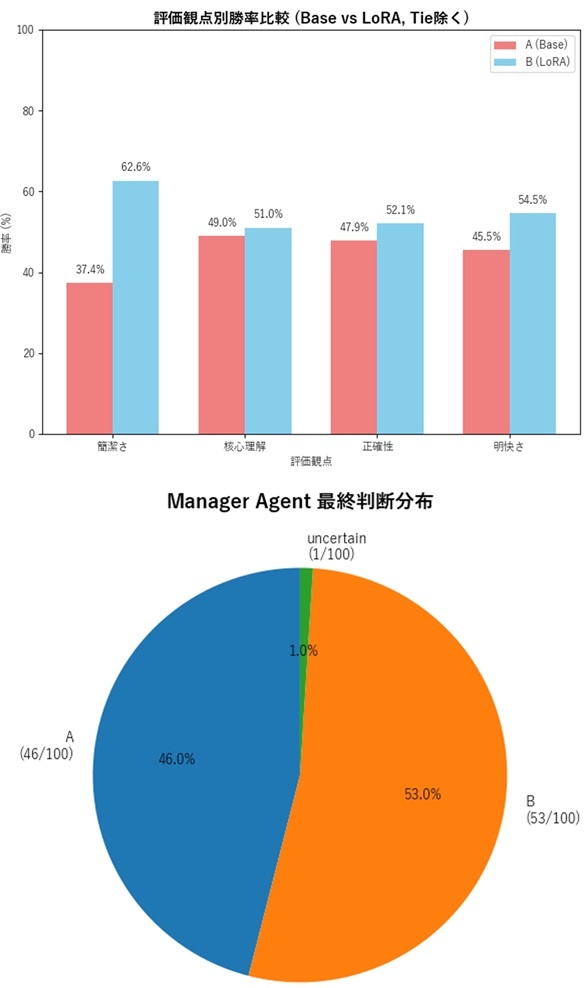
「的確性」下位尺度別詳細分析:
「的確性」総合指標を構成する4つの下位尺度について、それぞれの改善効果を分析しました:
| 評価観点 | ベース勝利 | LoRA勝利 | 同等 | LoRA勝利率 | 改善効果 |
|---|---|---|---|---|---|
| 簡潔さ | 37問 | 62問 | 1問 | 62.6% | +25.2pt |
| 明快さ | 45問 | 54問 | 1問 | 54.5% | +9.0pt |
| 正確性 | 45問 | 49問 | 6問 | 52.1% | +4.2pt |
| 核心理解 | 48問 | 50問 | 2問 | 51.0% | +2.0pt |
この結果から、ファインチューニングの主要目的である「冗長性の軽減」について、何らかの改善傾向が見られました。簡潔さでの62.6%勝利率は、LoRAモデルが冗長性削減について一定の改善を示している可能性があります。
Judge Agent個別評価での差異:
| Judge Agent | ベース勝利 | LoRA勝利 | その他 | LoRA勝利率 | 特徴 |
|---|---|---|---|---|---|
| deepseek-r1:8b | 25問 | 62問 | 13問 | 71.3% | 推論特化型の評価 |
| qwen3:8b | 46問 | 51問 | 3問 | 52.6% | バランス型の評価 |
| gemma3:12b | 60問 | 40問 | 0問 | 40.0% | 保守的評価傾向 |
この評価者間の差異は興味深い結果でした。推論に特化したdeeseek-r1は71.3%でLoRAを支持し、バランス型のqwen3は52.6%という穏健な評価を示し、gemma3は40.0%とより保守的な判断を下しました。
これらの多様な評価をOpenAI gpt-oss 20BのManager Agentが統合し、最終的に53.5%という結論に到達したプロセスは、複数の観点を考慮した評価の一例として参考になるかもしれません。
6.3 ファインチューニング目的達成度の検証
数値データを詳細に分析すると、当初設定した3つのファインチューニング目的について、以下のような結果が観察されました:
目的1:冗長性の軽減 → 改善傾向を観察
- 簡潔さでの改善効果:+25.2ポイント(37問 → 62問勝利)
- これは最も顕著な改善傾向であり、冗長性削減という主要目的について一定の効果が見られた可能性があります
目的2:指示への忠実性 → 軽微な改善を観察
- 核心理解での改善効果:+2.0ポイント(48問 → 50問勝利)
- 質問意図の正確な把握において、わずかな向上の傾向が見られました
目的3:ハルシネーション抑制 → 軽微な改善を観察(以下補足)
- 正確性での改善効果:+4.2ポイント(45問 → 49問勝利)
- 事実に基づいた正確な回答能力について、軽微な向上の傾向が見られました
さらに、明快さという副次的な効果として**+9.0ポイント**(45問 → 54問勝利)の向上が観察され、読みやすい構造化された回答の生成についても改善の兆候が見られました。
全観点統合での結果:
総合評価タスク数: 400問 (100タスク × 4観点)
ベースモデル優位: 175問 (43.8%)
LoRAモデル優位: 215問 (53.8%)
同等判定: 10問 (2.5%)
--------------------------------
LoRA総合改善効果: +10.0ポイント
今回のベンチマークテストでは、LoRAモデルはベースモデルと比較して、出力トークン数の削減と冗長性の改善が一致して観察されました。特に「簡潔さ」での+25.2ポイントの改善は、意図した冗長な表現の削減について何らかの効果があった可能性を示唆しています。
ファインチューニングに使用したデータセット(msfm/ichikara-instruction-all)は、日本語に特化した高品質なインストラクションデータです。全3,841サンプルのうち80%(3,073サンプル)を訓練に使用し、1.3エポックという短い学習でベースモデルの知識を損なわないよう注意深く進めました。
その結果、ベースモデルが持つ文書生成能力や正確性を保ちながら、出力の簡潔性について一定の向上を実現できた可能性があります。この点は、当初の目標であった「冗長性の軽減」「指示への忠実性維持」「ハルシネーション抑制」の三つについて、バランスを取りながら改善を目指す上で、一つの手がかりを得られたと考えています。
6.4 評価手法の検討:一つの試みとその限界
この結果が示すのは、従来の評価手法では観察しにくい改善効果を可視化できた可能性があることです。
本研究で検討した「的確性」という評価アプローチは、従来の単一指標による評価の限界に対する一つの対処の試みとして位置づけられます。質問の本質理解、情報の過不足のなさ、正確性、表現の明快さという4つの側面から評価することで、LLMの実用的な価値について何らかの異なる視点を提供できた可能性があります。
従来の模範回答ベース評価の課題:
評価基準: 模範回答との類似度
↓
結果予測: LoRAの簡潔化 = "模範回答と違う" = 低評価
↓
課題: 真の改善効果が見えにくくなる
今回検討した手法による観察:
評価基準: ファインチューニング目的への適合度
↓
結果: LoRAの簡潔化 = "冗長性削減目的に適合" = 一定の評価 (62.6%)
↓
観察: 目的に沿った改善の一面を捉えられた可能性
模範回答バイアスを回避する試みにより、LoRAモデルの53.5%勝利率という結果を得ました。これは劇的な改善ではありませんが、ファインチューニングの効果について一定の示唆を得られたと考えられます。
本手法の限界と課題:
- 評価者LLMの選択バイアス
- サンプル数の制約(100タスクのみ)
- 統計的有意性の未検証
- 人間評価との整合性の未確認
- 「的確性」概念の主観性
これらの課題を踏まえ、本研究は予備的な検討の一例として位置づけられるべきと考えています。
Judge Agent間の多様性について:
deepseek-r1の71.3%、qwen3の52.6%、gemma3の40.0%という評価者間の差異は、人間の専門家でも意見が分かれることがあるのと同様の現象と考えられます。OpenAI gpt-oss 20BのManager Agentが、これらの異なる観点を統合し、最終的に53.5%という結論を導いたプロセスは、複数の視点を考慮した評価の一例として参考になるかもしれません。
まとめと今後の課題
このプロジェクトを通じて、以下のような学習機会を得ることができました:
ファインチューニング技術について:
- 相反する要求(冗長性削減 vs ハルシネーション抑制)の両立への挑戦
- LoRAパラメータ設計手法の検討
- 効率的な学習の実現
評価技術について:
- 模範回答バイアス問題への対処の試み
- LLM-as-a-Judgeを参考にした評価手法の実装
- 目的志向型評価システムの検討
システム開発技術について:
- LangGraph + Dockerによる実験環境の構築
- 非同期処理による効率的なマルチエージェントシステムの実装
ただし、本研究には多くの制約と課題があることも認識しています。評価サンプル数の限定性、評価者LLMの偏りの可能性、統計的有意性の検証不足など、改善すべき点は数多くあります。
技術的限界:
- ターゲットモジュール選択の効果の未検証
- 定量的な評価指標の不足
- 統計的有意性の未確認
概念的限界:
- 「冗長性」「的確性」の定義の主観性
- 評価観点間の概念的重複
- ハルシネーション評価の客観性不足
システム的限界:
- Judge Agent間の評価傾向の差異
- Manager Agentによる主観的統合判断
- 人間評価との整合性の未検証
今後は、信頼性の高い評価手法の確立に向けて学習を続けていきたいと考えています。
Appendix: ソースコードとリソース
プロジェクトリポジトリ
本研究で扱ったPhi-4 ファインチューニングプロジェクトに関する全てのソースコードは、以下のGitHubリポジトリで公開しています:
GitHub Repository: phi4-lora-finetuning
利用方法
環境構築や実行方法については、リポジトリのREADMEファイルをご参照ください。
Discussion