Pythonでkintone APIを使用して育児記録を可視化する(POST/GET)
概要
kintoneとはサイボウズ株式会社が提供している、ノーコードでビジネスアプリを開発できるクラウドサービスです。REST APIも用意されているので外部からのデータ授受もできます。
今後仕事で使用することが多くなるので、自習用に開発用アカウントを取得して使ってみました。
本記事ではこちらのAPIを利用して、kintoneへデータをPOST/kintoneからデータをGETするPythonスクリプトを作成します。
使用するデータ
せっかくなら意味のあるデータを扱ってみたいので、今年2歳になる息子の育児記録を拝借することにしました。
我が家ではぴよログというアプリで育児記録を行っています。このアプリでは食事や睡眠、排泄をはじめとした様々なアクションを記録できます。
インターフェースは以下の通りです。
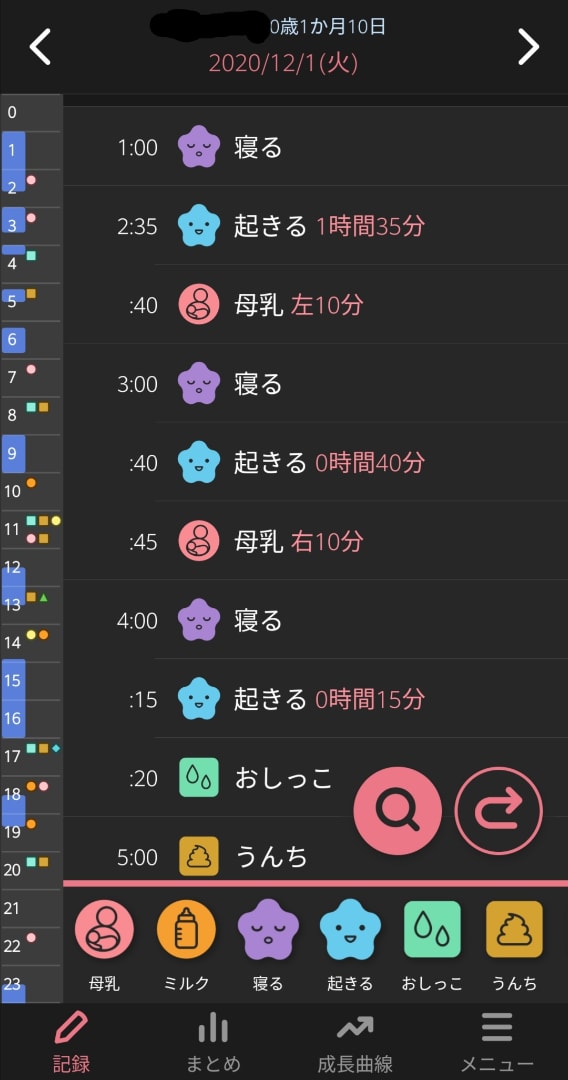
今回はトライアルということで、「睡眠」に焦点を当ててデータを可視化したいと思います。
-
集計項目
1日あたりの睡眠時間及び起床回数 -
集計期間
2020年12月(0歳2ヶ月)〜2022年7月(1歳9ヶ月)
※本当は0か月から取りたかったのですが用意がありませんでした。
データの用意
ぴよログには育児記録をエクスポートする機能があります。
例えば上のイメージではこのようなテキスト形式でエクスポートされます。
【ぴよログ】2020年12月
----------
2020/12/1(火)
**登録した子どもの名前** (0歳1か月10日)
01:00 寝る
02:35 起きる (1時間35分)
02:40 母乳 左10分
03:00 寝る
03:40 起きる (0時間40分)
03:45 母乳 右10分
04:00 寝る
04:15 起きる (0時間15分)
04:20 おしっこ
05:00 うんち
05:10 寝る
05:30 起きる (0時間20分)
06:10 寝る
06:50 起きる (0時間40分)
07:00 母乳 左5分
08:05 おしっこ
08:05 うんち
09:00 寝る
10:00 起きる (1時間0分)
…(以下略)
エクスポート単位は1日または1ヶ月です。
上記集計期間のデータを1ヶ月毎にエクスポートし、月別にtxtファイルで保存しておきます。(例:「202012.txt」「202101.txt」…)
kintone
kintoneは一般ユーザー用に30日間無償のお試し版も提供されていますが、開発用アカウントを発行すれば実質半永久的に無償で利用できます。[1]
kintone開発環境の準備
以下の手順で開発環境を準備します。
- cybozu developer networkへのアカウント登録
cybozu developer networkの概要は以下のとおりです。
cybozu.com 上のサービスに関してサイボウズ株式会社(以下、「サイボウズ」と言います)が提供するデベロッパー向けのサービスで、デベロッパー向けのAPIドキュメント、サンプルプログラム、各種Tips等の情報や、デベロッパー同士が課題を解決し合うためのオープンなコミュニティを用意しています。 ー 「利用規約」より
トップページ右上の「サインイン」→「アカウント登録」をクリックすると登録画面がポップアップされます。名前とメールアドレスを入力して登録します。
-
開発者ライセンスの申し込み
開発環境を利用するためにはアカウントの他に開発者ライセンスが必要です。
トップページの「kintone開発環境を取得」→「開発者ライセンスを申し込む」から申し込みを行います。
利用規約を確認してから申し込みフォームに必要事項を入力し、「申し込む」ボタンをクリックします。 -
発行されたURLからログイン
申込み完了後約20分程度で、登録のメールアドレス宛に「【重要】開発者ライセンスがご利用いただけます」という件名のメールが届きます。
メールにアクセスURL、ログイン名、パスワードが記載されているのでログインします。
アプリケーションの作成
kintoneでは、1つのデータベースを「アプリケーション」という単位で管理します。また、APIトークンはアプリごとに発行されます。以下は用意したデータをアプリに登録し、APIトークンを発行するまでの流れです。
-
上記URLログイン後、以下の画面が表示されます。「kintone」ボタンをクリックします。

-
トップページ(「ポータル」と呼ばれます)が表示されます。「アプリ」グループの「+」ボタンをクリックすることで、アプリを新規作成できます。
-
アプリの作成方法は複数用意されています。提供されているアプリストアからテンプレートを流用したり、手持ちのExcelやcsvをインポートして作成することもできます。せっかくtxtファイルがあるのでcsvに加工後インポートしてもよいのですが、ここではAPIを利用したいので、いったん手作業で空のアプリを作成します。「はじめから作成」をクリックします。

-
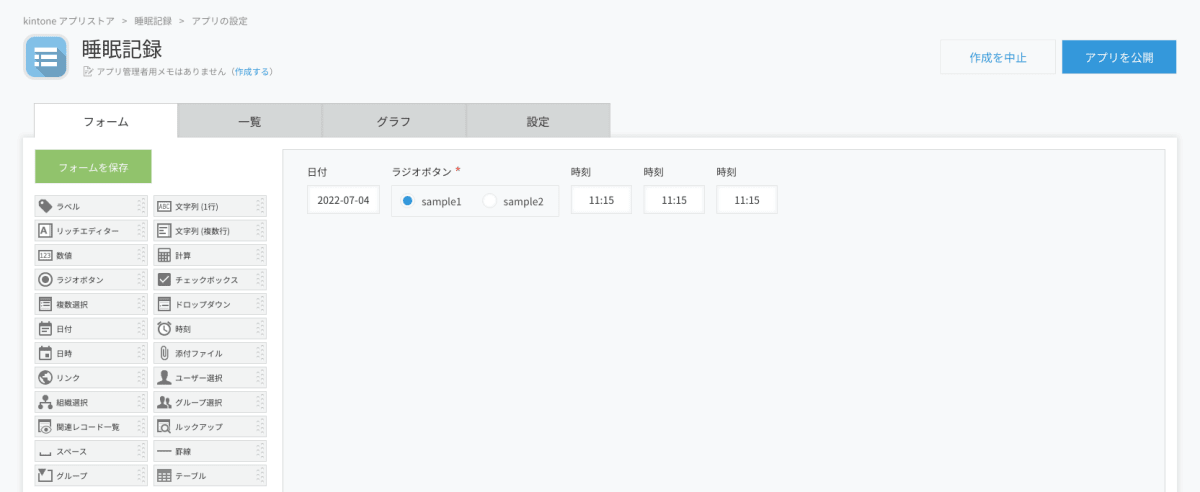
kintoneではドラッグ&ドロップでアプリの作成が行なうことができます。管理したい項目を任意の形で並べます。今回は日別の就寝・起床時間を管理したいので、このような項目を用意します。
| 項目名 | 内容 | 種別 |
|---|---|---|
| date | 日付 | 日付 |
| act | 就寝(asleep)または起床(awake) | ラジオボタン |
| start | actを開始した時間 | 時刻 |
| end | actを終了した時間 | 時刻 |
| diff | 就寝または起床時間(end-start) | 時刻 |
「フォーム」タブでいったんこのように並べました。
- 各項目の設定を変更します。各項目にオンマウスすると⚙のマークが表示されるので、設定をクリックします。フィールド名・フィールドコードを上表の項目名に変更します。
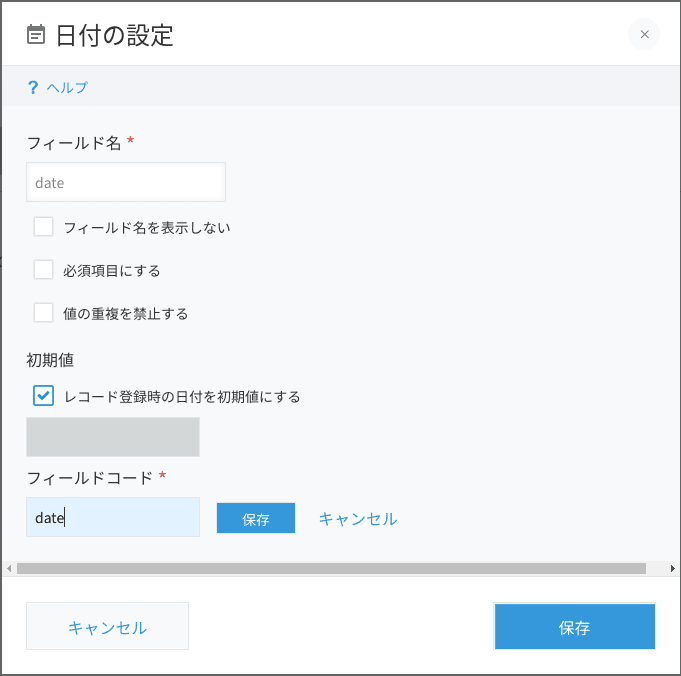
最終的にこのようなフォームになりました。

-
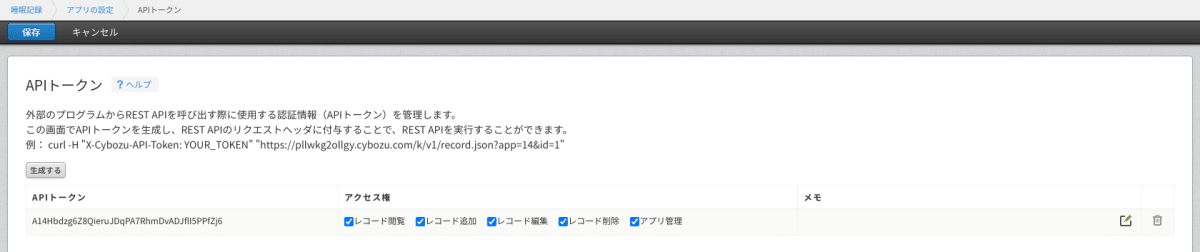
続いてAPIトークンを生成します。「設定」タブをクリックし、「カスタマイズ/サービス連携」グループ内の「APIトークン」に進みます。

-
APIトークン生成画面が表示されます。「生成する」ボタンをクリックするとトークンおよびアクセス権が表示されます。アクセス権はいったん全権を与えておき、左上の「保存」ボタンをクリックします。
-
「設定」タブに戻るので、右上の「アプリを公開」ボタンをクリックします。ひとまずこれで空のアプリを作成できました。ここからAPIを使ってデータを登録していきます。
POST・GETの実行
APIで行えるメソッドは様々ですが、ここではPOSTとGETの2つに絞ります。POSTはデータの登録(ローカル→kintone)、GETはデータの取得(kintone→ローカル)を行うためのメソッドです。
ソースコード
先にソースコード全文です。
POSTとGETでクラスを分けています。
import numpy as np
import pandas as pd
from os import listdir
from json import loads
from datetime import datetime as dt
from datetime import timedelta
from urllib.parse import quote
from requests import get
from requests import post
from requests.exceptions import RequestException
from logging import getLogger
'''定数部'''
DATA_PATH = 'data'
FIELDS = ['date', 'act', 'start', 'end', 'diff']
SUB_DOMAIN = YourDomain
APP_NUM = YourAppNum
API_TOKEN = YourAPIToken
''''''''''''''''''
class kintoneAPI:
'''
共通クラス(コンストラクタ)
'''
def __init__(self, data_path: str, fields: list, sub_domain: str, app_num: int, api_token: str):
self.data_path = data_path
self.fields = fields
self.sub_domain = sub_domain
self.app_num = app_num
self.api_token = api_token
class PostAPI(kintoneAPI):
'''
kintoneへデータをPOSTするクラス
'''
def get_data(self):
'''
各月のテキストデータをまとめてリスト化
'''
files = listdir(self.data_path)
get_data = []
for filename in files:
with open(f'{self.data_path}/{filename}', encoding='utf_8') as f:
data = f.read()
get_data.append(data)
return [data.split('\n') for data in get_data]
def ind_data(self):
'''
リスト化したデータから「寝る」「起きる」の項目を抽出し、kintoneに表示したい形式に情報を分割
'''
ind_data = []
for month_text in self.get_data():
before_d = None
for i, text in enumerate(month_text):
if text == '----------':
d = month_text[i + 1][:-3]
texts = text.split()
if len(texts) > 1 and texts[1] in ['起きる', '寝る']:
t_datetime = dt.strptime(f'{d} {texts[0]}', '%Y/%m/%d %H:%M')
zero_time = dt.strptime(f'{d} 00:00', '%Y/%m/%d %H:%M')
start_time = dt.time(zero_time) if not ind_data or d != ind_data[-1][0] else ind_data[-1][3]
diff_time = t_datetime - dt.combine(dt.date(t_datetime), start_time)
act = 'awake' if texts[1] == '寝る' else 'asleep' # 「起きる」が記録されたらそれまでは寝ている、「寝る」が記録されたらそれまでは起きている
if before_d != d and ind_data:
end_time = dt.time(dt.strptime(f'{d} 00:00', '%Y/%m/%d %H:%M'))
before_diff_time = dt.combine(dt.date(t_datetime), end_time) - dt.combine(dt.date(t_datetime), ind_data[-1][3]) + timedelta(days=1)
ind_data.append([ind_data[-1][0], 'asleep', ind_data[-1][3], end_time, before_diff_time])
ind_data.append([d, act, start_time, dt.time(t_datetime), diff_time])
before_d = d
return ind_data
def format_json(self, data_list):
'''
json用にリストをフォーマット
'''
format_json = []
for datas in data_list:
datas[0] = dt.date(dt.strptime(datas[0], '%Y/%m/%d')).isoformat()
datas[2] = datas[2].isoformat()
datas[3] = datas[3].isoformat()
datas[4] = str(datas[4])
format_json.append(datas)
return format_json
def send_post(self, data_list):
'''
レコードを登録する際のjsonを作成しPOST送信
'''
values_list = self.format_json(data_list)
records = [{field: {'value': value} for field, value in zip(self.fields, values)} for values in values_list]
params = {"app": self.app_num, "records": records}
headers = {"X-Cybozu-API-Token": self.api_token, "Content-Type": "application/json"}
url = f"https://{self.sub_domain}.cybozu.com/k/v1/records.json"
resp = post(url, json=params, headers=headers)
logger = getLogger(__name__)
try:
resp.raise_for_status()
except RequestException as e:
logger.exception("request failed. error=(%s)", e.response.text)
return resp
def main(self):
'''
1度に処理できるレコードは100レコードのため、1回あたり100レコード未満になるようにリストを分割する
'''
n = -(-len(self.ind_data()) // 100) # リスト総数÷100の切り上げ
split_list = np.array_split(self.ind_data(), n)
done_count = 0
for splited in split_list:
self.send_post(splited.tolist())
done_count += len(splited)
print(f'\r{done_count}/{len(self.ind_data())} records done.', end='')
class GetAPI(kintoneAPI):
'''
kintoneからデータをGETするクラス
'''
def send_get(self, off_count):
'''
指定されたURLのレコードを取得
'''
headers = {"X-Cybozu-API-Token": self.api_token}
query = quote(f'offset {off_count}')
url = f"https://{self.sub_domain}.cybozu.com/k/v1/records.json?app={self.app_num}&query={query}&totalCount=true"
return get(url, headers=headers)
def extract_data(self):
'''
jsonから必要なデータを抽出
'''
total_records = int(loads(self.send_get(0).text)['totalCount'])
n = -(-total_records // 100) # リスト総数÷100の切り上げ
dfs = []
done_count = 0
for i in range(n):
offset_data = pd.read_json(self.send_get(i * 100).text)
dfs.append(offset_data)
done_count += len(offset_data)
print(f'\r{done_count}/{total_records} records done.', end='')
df = pd.concat(dfs)
extract_data = [[df.iloc[i, 0][field]['value'] for field in self.fields] for i in range(len(df))]
return extract_data
def main(self):
'''
日別の睡眠時間及び起床回数を月別に合算してcsvに保存
'''
df_all = pd.DataFrame(self.extract_data(), columns=self.fields)
df_all['diff_minute'] = df_all['diff'].str[:2].astype(int) * 60 + df_all['diff'].str[3:].astype(int)
df_merged = pd.DataFrame()
df_merged['起床回数'] = df_all[df_all['act'] == 'awake'].groupby(by=['date']).count()['act']
df_merged['睡眠時間(合計)'] = df_all[df_all['act'] == 'asleep'].groupby(by=['date']).sum()['diff_minute'] / 60
df_merged['睡眠時間(平均)'] = df_merged['睡眠時間(合計)'] / df_merged['起床回数']
df_merged = df_merged.rename_axis('date').reset_index()
df_merged['date'] = pd.to_datetime(df_merged['date'], infer_datetime_format=True)
df_merged.sort_values(by='date', ascending=True, inplace=True)
df_merged.to_csv('merged_data.csv', mode='w', index=False)
if __name__ == '__main__':
post_api = PostAPI(DATA_PATH, FIELDS, SUB_DOMAIN, APP_NUM, API_TOKEN)
get_api = GetAPI(DATA_PATH, FIELDS, SUB_DOMAIN, APP_NUM, API_TOKEN)
post_api.main() #POST実行時
get_api.main() #GET実行時
コード解説
定数部
コンストラクタの変数に対応しています。
それぞれのデータ型はコンストラクタの型ヒントを参照してください。
-
DATA_PATH
用意したデータを保管するディレクトリです。
スクリプトと同階層に「data」ディレクトリを作成し、その中に用意したデータ(「202012.txt」「202101.txt」…)を保管します。 -
FIELDS
「アプリケーションの作成」5で定義したフィールドコードです。 -
SUB_DOMAIN、APP_NUM
アプリのページを開いた際の以下の部分です。
https://[SUB_DOMAIN].cybozu.com/k/[APP_NUM]/
-
API_TOKEN
「アプリケーションの作成」7で生成したAPIトークンです。
POST(PostAPIクラス)
POSTの流れは以下の通りです。各メソッドが対応しています。
| 実行内容 | メソッド | |
|---|---|---|
| 1 | 各月のテキストデータをまとめてリスト化 | get_data() |
| 2 | リスト化したデータから「寝る」「起きる」の項目を抽出し、kintoneに表示したい形式に情報を分割 | ind_data() |
| 3 | json用にリストをフォーマット | format_json() |
| 4 | レコードを登録する際のjsonを作成しPOST送信 | send_post() |
| 5 | 1度に処理できるレコードは100レコードのため、1回あたり100レコード未満になるようにリストを分割する | main() |
get_data()
DATA_PATH内のtxtファイル群をリスト化します。
def get_data(self):
files = listdir(self.data_path)
get_data = []
for filename in files:
with open(f'{self.data_path}/{filename}', encoding='utf_8') as f:
data = f.read()
get_data.append(data)
return [data.split('\n') for data in get_data]
「データの用意」でお見せしたテキストが以下のリストになります。
[['【ぴよログ】2020年12月', '----------', '2020/12/1(火)', '**登録した子どもの名前** (0歳1か月10日)', '', '01:00 寝る ', '02:35 起きる (1時間35分) ', '02:40 母乳 左10分 ', '03:00 寝る ', '03:40 起きる (0時間40分) ', '03:45 母乳 右10分 ', '04:00 寝る ', '04:15 起きる (0時間15分) ', '04:20 おしっこ ', '05:00 うんち ', '05:10 寝る ', '05:30 起きる (0時間20分) ', '06:10 寝る ', '06:50 起きる (0時間40分) ', '07:00 母乳 左5分 ', '08:05 おしっこ ', '08:05 うんち ', '09:00 寝る ', '10:00 起きる (1時間0分) ',
…(以下略)
1つのテキストファイル=1か月分のデータ内の各行を要素とし、1つのリストにしています。
このリストを月数分作成し、それらを要素としてリスト化した2次元リストを返します。
ind_data()
get_data()で得たリストから必要な項目を抽出します。その後、kintoneに表示する形式に情報を分割します。
def ind_data(self):
ind_data = []
for month_text in self.get_data():
before_d = None
for i, text in enumerate(month_text):
if text == '----------':
d = month_text[i + 1][:-3]
texts = text.split()
if len(texts) > 1 and texts[1] in ['起きる', '寝る']:
t_datetime = dt.strptime(f'{d} {texts[0]}', '%Y/%m/%d %H:%M')
zero_time = dt.strptime(f'{d} 00:00', '%Y/%m/%d %H:%M')
start_time = dt.time(zero_time) if not ind_data or d != ind_data[-1][0] else ind_data[-1][3]
diff_time = t_datetime - dt.combine(dt.date(t_datetime), start_time)
act = 'awake' if texts[1] == '寝る' else 'asleep' # 「起きる」が記録されたらそれまでは寝ている、「寝る」が記録されたらそれまでは起きている
if before_d != d and ind_data:
end_time = dt.time(dt.strptime(f'{d} 00:00', '%Y/%m/%d %H:%M'))
before_diff_time = dt.combine(dt.date(t_datetime), end_time) - dt.combine(dt.date(t_datetime), ind_data[-1][3]) + timedelta(days=1)
ind_data.append([ind_data[-1][0], 'asleep', ind_data[-1][3], end_time, before_diff_time])
ind_data.append([d, act, start_time, dt.time(t_datetime), diff_time])
before_d = d
return ind_data
get_data()で得たリストが以下の通り加工されます。
[['2020/12/1', 'awake', datetime.time(0, 0), datetime.time(1, 0), datetime.timedelta(seconds=3600)], ['2020/12/1', 'asleep', datetime.time(1, 0), datetime.time(2, 35), datetime.timedelta(seconds=5700)], ['2020/12/1', 'awake', datetime.time(2, 35), datetime.time(3, 0), datetime.timedelta(seconds=1500)], ['2020/12/1', 'asleep', datetime.time(3, 0), datetime.time(3, 40), datetime.timedelta(seconds=2400)], ['2020/12/1', 'awake', datetime.time(3, 40), datetime.time(4, 0), datetime.timedelta(seconds=1200)], ['2020/12/1', 'asleep', datetime.time(4, 0), datetime.time(4, 15), datetime.timedelta(seconds=900)], ['2020/12/1', 'awake', datetime.time(4, 15), datetime.time(5, 10), datetime.timedelta(seconds=3300)], ['2020/12/1', 'asleep', datetime.time(5, 10), datetime.time(5, 30), datetime.timedelta(seconds=1200)], ['2020/12/1', 'awake', datetime.time(5, 30), datetime.time(6, 10), datetime.timedelta(seconds=2400)], ['2020/12/1', 'asleep', datetime.time(6, 10), datetime.time(6, 50), datetime.timedelta(seconds=2400)], ['2020/12/1', 'awake', datetime.time(6, 50), datetime.time(9, 0), datetime.timedelta(seconds=7800)], ['2020/12/1', 'asleep', datetime.time(9, 0), datetime.time(10, 0), datetime.timedelta(seconds=3600)], ['2020/12/1', 'awake', datetime.time(10, 0), datetime.time(12, 30), datetime.timedelta(seconds=9000)],
…(以下略)
記事の趣旨とはずれるのですがこのメソッドが作成に苦労しました。
理由は日時データの扱い方です。datetime、dateなどの表示形式や差分取得に苦戦しました。(苦戦されている方が多いのか、関連記事はたくさん出てきました)
またデータ上で「起きる」と記録されればそれまでは「寝ている」(asleep)、「寝る」と記録されればそれまでは「起きている」(awake)など定義の入れ替えも混乱を招きました。
もっとシンプルな書き方がある気がします。
format_json()
POSTするにあたり、データをjson用にフォーマットする必要があります。
def format_json(self, data_list):
format_json = []
for datas in data_list:
datas[0] = dt.date(dt.strptime(datas[0], '%Y/%m/%d')).isoformat()
datas[2] = datas[2].isoformat()
datas[3] = datas[3].isoformat()
datas[4] = str(datas[4])
format_json.append(datas)
return format_json
ind_data()で得たリストが以下の通り加工されます。
[['2020-12-01', 'awake', '00:00:00', '01:00:00', '1:00:00'], ['2020-12-01', 'asleep', '01:00:00', '02:35:00', '1:35:00'], ['2020-12-01', 'awake', '02:35:00', '03:00:00', '0:25:00'], ['2020-12-01', 'asleep', '03:00:00', '03:40:00', '0:40:00'], ['2020-12-01', 'awake', '03:40:00', '04:00:00', '0:20:00'], ['2020-12-01', 'asleep', '04:00:00', '04:15:00', '0:15:00'], ['2020-12-01', 'awake', '04:15:00', '05:10:00', '0:55:00'], ['2020-12-01', 'asleep', '05:10:00', '05:30:00', '0:20:00'], ['2020-12-01', 'awake', '05:30:00', '06:10:00', '0:40:00'], ['2020-12-01', 'asleep', '06:10:00', '06:50:00', '0:40:00'], ['2020-12-01', 'awake', '06:50:00', '09:00:00', '2:10:00'], ['2020-12-01', 'asleep', '09:00:00', '10:00:00', '1:00:00'], ['2020-12-01', 'awake', '10:00:00', '12:30:00', '2:30:00'],
…(以下略)
send_post()
フォーマットしたリストでjsonを作成し、POST送信します。
def send_post(self, data_list):
values_list = self.format_json(data_list)
records = [{field: {'value': value} for field, value in zip(self.fields, values)} for values in values_list]
params = {"app": self.app_num, "records": records}
headers = {"X-Cybozu-API-Token": self.api_token, "Content-Type": "application/json"}
url = f"https://{self.sub_domain}.cybozu.com/k/v1/records.json"
resp = post(url, json=params, headers=headers)
logger = getLogger(__name__)
try:
resp.raise_for_status()
except RequestException as e:
logger.exception("request failed. error=(%s)", e.response.text)
return resp
このメソッドがPOSTの根幹部分になるので詳しく見ていきます。
まず、json用にフォーマットしたリストをvalues_listに格納します。
続くrecords、params、headers、url、respは、kintoneにデータを送る際に必要な情報です。
-
records
登録するレコード(複数)です。これまでのメソッドで整形してきたデータ群を指します。 -
params
アプリIDとrecordsをまとめたjsonです。 -
headers
APIトークンを指定します。Content-Typeについてはよくわからなかったのですが、「ファイルの種類」を表すという理解でひとまず良いみたいです。特にいじることはありません。 -
url
POST送信先のURLです。 -
resp
params、headers、urlの情報をまとめ、POST送信します。
返り値は<Response 200>などのHTTPステータスコードです。失敗の場合は400などのエラーコードが返されます。
main()
1度にPOST送信できるレコード数には制限があり、kintoneの場合100レコード数までです。(以下リンク参照)
送信したいレコードが100以上ある場合は、データを格納しているリスト(ind_data())を分割する必要があります。
def main(self):
n = -(-len(self.ind_data()) // 100) # リスト総数÷100の切り上げ
split_list = np.array_split(self.ind_data(), n)
done_count = 0
for splited in split_list:
self.send_post(splited.tolist())
done_count += len(splited)
print(f'\r{done_count}/{len(self.ind_data())} records done.', end='')
分割したリストをfor文で回し、全レコードをPOST送信できるようにしています。
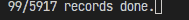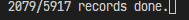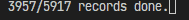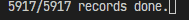
実行すると上記の通り処理レコード数/全レコード数の形式で進捗を表示します。
実行結果
kintoneで作成したアプリを見てみます。
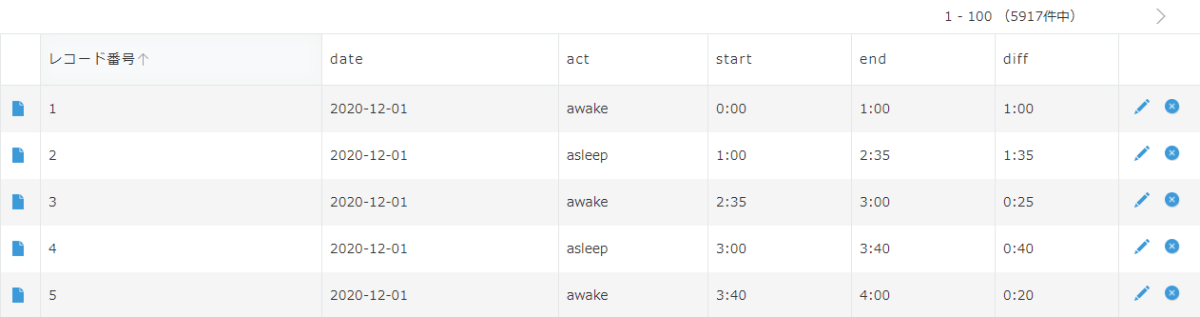
POST送信したレコードが登録されています!
GET(GetAPIクラス)
今度はアプリ内のデータをGETで取得します。
取得したデータをcsvとしてローカルディレクトリに保管するまでがゴールです。
GETの流れは以下の通りです。各メソッドが対応しています。
| 実行内容 | メソッド | |
|---|---|---|
| 1 | 指定されたURLのレコードを取得 | send_get() |
| 2 | jsonから必要なデータを抽出 | extract_data() |
| 3 | 日別の睡眠時間及び起床回数を月別に合算してcsvに保存 | main() |
send_get()
ヘッダ、クエリ、URLを指定し、レコードを取得します。
def send_get(self, off_count):
headers = {"X-Cybozu-API-Token": self.api_token}
query = quote(f'offset {off_count}')
url = f"https://{self.sub_domain}.cybozu.com/k/v1/records.json?app={self.app_num}&query={query}&totalCount=true"
return get(url, headers=headers)
クエリはデータを取得する際の条件です。様々なオプションを組み合わせて、取得したいデータを指定します。今回はoffsetと言うオプションを使用します。
上記ページ記載のoffsetポジションについての説明は以下の通りです。
本オプションの後に指定した数だけ、出力するレコードをスキップして、レコードが抽出されます。
左の例(offset 30)では、レコード先頭から30レコードは出力されず、31番目のレコードから出力されます。
上限値は10000です。
GETで一度に取得できるレコード数はPOST同様100までです。(limitオプションで最大500まで取得可)つまり100レコード以上取得したい場合は反復処理を施す必要があります。具体的には1回目のループで1~100レコードまで取得、2回目のループで101~200まで取得…というコードです。
これを実装するために使用するのがoffsetオプションとなります。
次のextract_data()で引数off_countを指定します。
offsetの上限値
上記の通りoffsetには上限値があります。
kintone API レコード一括取得APIのoffsetの上限値制限について(2020/4/15更新)
要するに、一度に取得できるレコードの数は10,000件までです。
今回は対応不要でしたが、10,000件以上のレコードを取得する場合は別の条件設定が必要です。
公式からは以下の通り対処法が説明されています。
offset の制限値を考慮した kintone のレコード一括取得について
またコミュニティページでもコーディング方法について盛んに議論されています。
ユーザー同士の情報交換が活発なので助かります。
extarct_data()
send_get()を反復処理させ、取得したjsonから必要なデータを抽出します。
def extract_data(self):
total_records = int(loads(self.send_get(0).text)['totalCount'])
n = -(-total_records // 100) # リスト総数÷100の切り上げ
dfs = []
done_count = 0
for i in range(n):
offset_data = pd.read_json(self.send_get(i * 100).text)
dfs.append(offset_data)
done_count += len(offset_data)
print(f'\r{done_count}/{total_records} records done.', end='')
df = pd.concat(dfs)
extract_data = [[df.iloc[i, 0][field]['value'] for field in self.fields] for i in range(len(df))]
return extract_data
send_get()のURLで指定したtotalCount=trueによりレコード総数を取得し、変数total_recordsに格納します。
次にPOSTクラスのmain()同様100を最大値としてjsonの分割を行います。
send_get()の引数off_countに0,100,200,...が代入され、全レコードが空リストdfsに格納されます。この後main()で日別のデータ(睡眠時間や起床回数)を合算するのですが、その際使いやすいのでdfsをpd.concat()でpandasのDataFrameに変換して変数dfに格納します。
df内の必要なデータ=json内のvalueの値のみを抽出し、変数extract_data()に格納します。
main()
いよいよ最後です。取得したデータをcsvに保存します。
def main(self):
df_all = pd.DataFrame(self.extract_data(), columns=self.fields)
df_all['diff_minute'] = df_all['diff'].str[:2].astype(int) * 60 + df_all['diff'].str[3:].astype(int)
df_merged = pd.DataFrame()
df_merged['起床回数'] = df_all[df_all['act'] == 'awake'].groupby(by=['date']).count()['act']
df_merged['睡眠時間(合計)'] = df_all[df_all['act'] == 'asleep'].groupby(by=['date']).sum()['diff_minute'] / 60
df_merged['睡眠時間(平均)'] = df_merged['睡眠時間(合計)'] / df_merged['起床回数']
df_merged = df_merged.rename_axis('date').reset_index()
df_merged['date'] = pd.to_datetime(df_merged['date'], infer_datetime_format=True)
df_merged.sort_values(by='date', ascending=True, inplace=True)
df_merged.to_csv('merged_data.csv', mode='w', index=False)
こちらはAPIというよりpandasの説明になるので詳細は割愛しますが、以下の
数値を月別に合算してリスト化しています。
- 起床回数→1日あたりの起床回数
- 睡眠時間(合計)→1日の合計睡眠時間
- 睡眠時間(平均)→睡眠1回あたりの平均睡眠時間
もちろんpandasでなくてもできます。
実行結果
以下の内容のmerged_data.csvが保管されます。
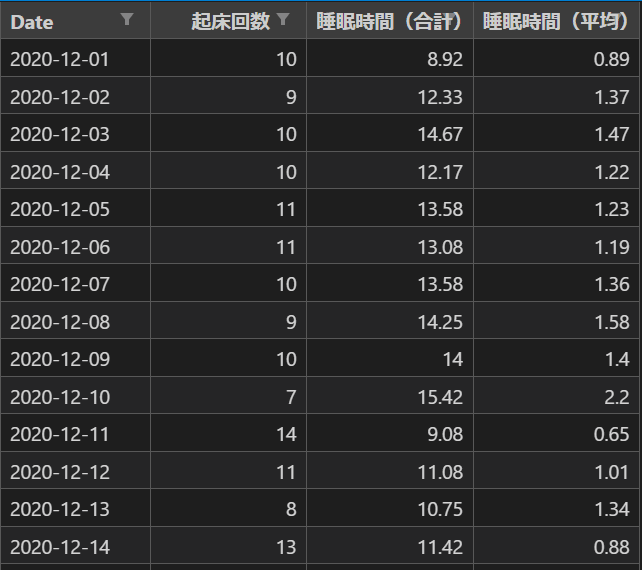
まとめ
以上、kintoneが提供しているAPIを使用して手持ちデータの送信および取得を行いました。
コードを多少修正すれば他のデータフォーマットでも使用できると思います。
kintone自体非常に便利なサービスですが、APIを習得すればさらなる有効活用が期待できそうです。(データの日次取得や自動反映など)
開発者用ページで少しずつ勉強していこうと思います。
※以下はAPIには触れない補遺です※
おまけ:merged_data.csvをkintoneで見てみる
merged_data.csvからアプリ作成
kintoneではcsvからアプリを作成することもできます。
ポータル画面「アプリ」右横の「+」ボタンをクリックすると以下のページが表示されます。
「CSVを読み込んで作成」をクリックします。

あとは手順に沿ってGETクラスで作成したmerged_data.csvをアップロードすれば完成です。
作成したアプリは以下の通り表示されます。
グラフで可視化
アプリ上部の集計ボタンからグラフの作成ができます。
オプションは多彩なので、データに応じて適切なものを指定してください。
例えば「睡眠時間(平均)」の月別推移を見たいときは、以下の通り指定します。
-
グラフの種類
折れ線グラフ -
分類する項目
大項目:date―月単位 -
集計方法
平均―睡眠時間(平均)
「睡眠時間(合計)」、「起床回数」の月別推移も同様に作成します。集計方法の項目を変更するだけです。
それぞれ以下の通りグラフとして可視化されました。
グラフを保存しておくことで、データが更新されても自動でグラフに反映されます。
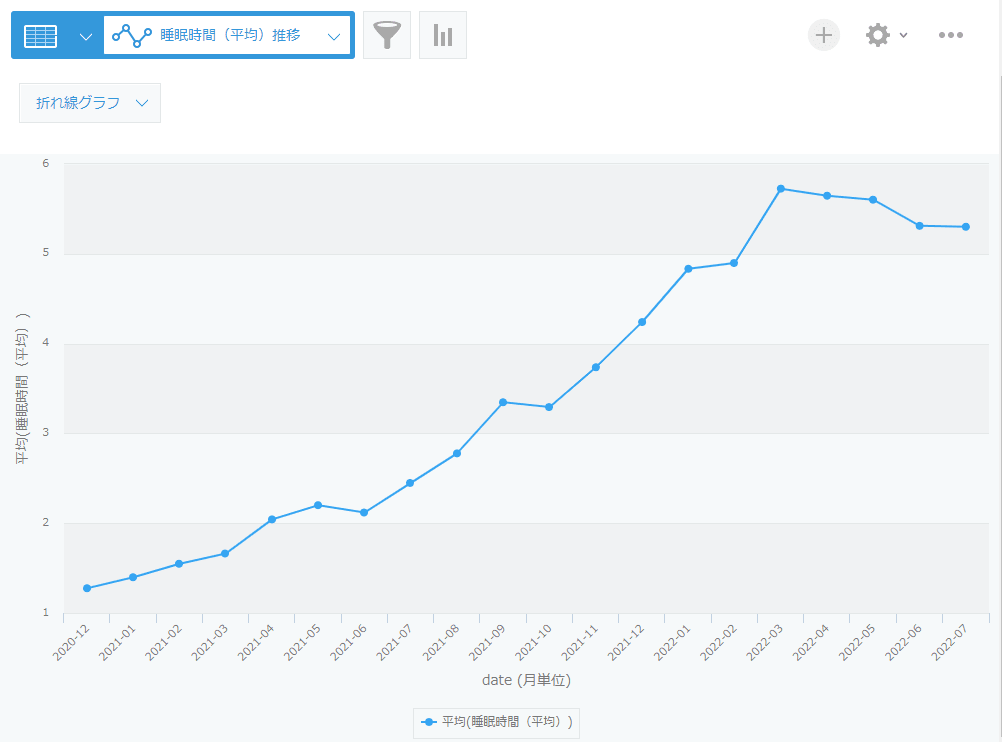
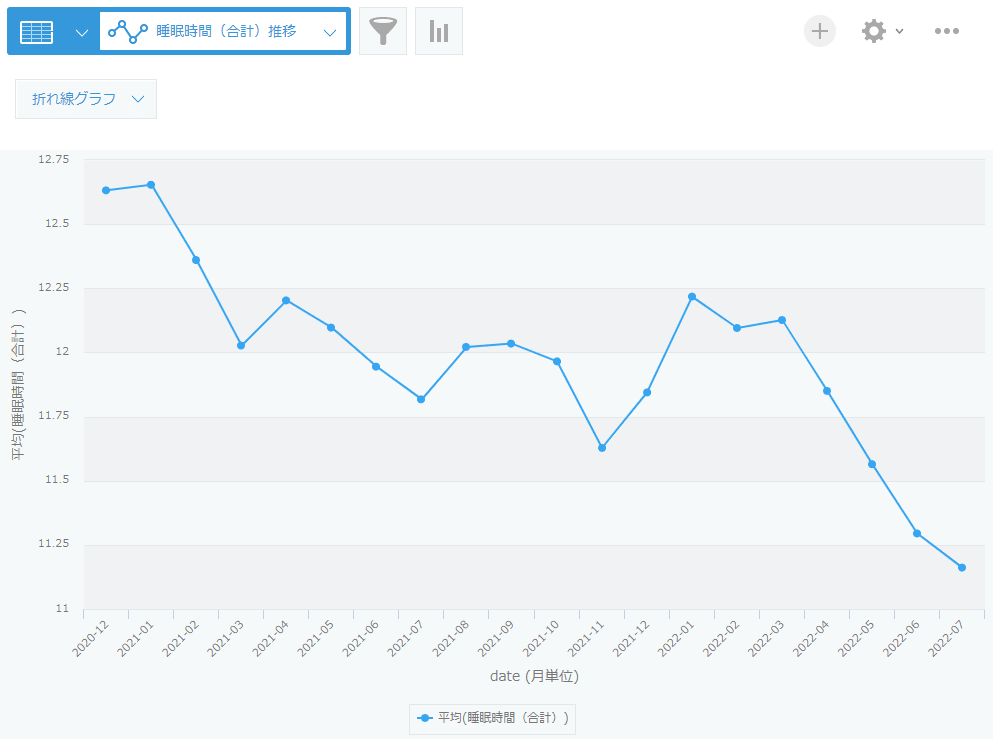
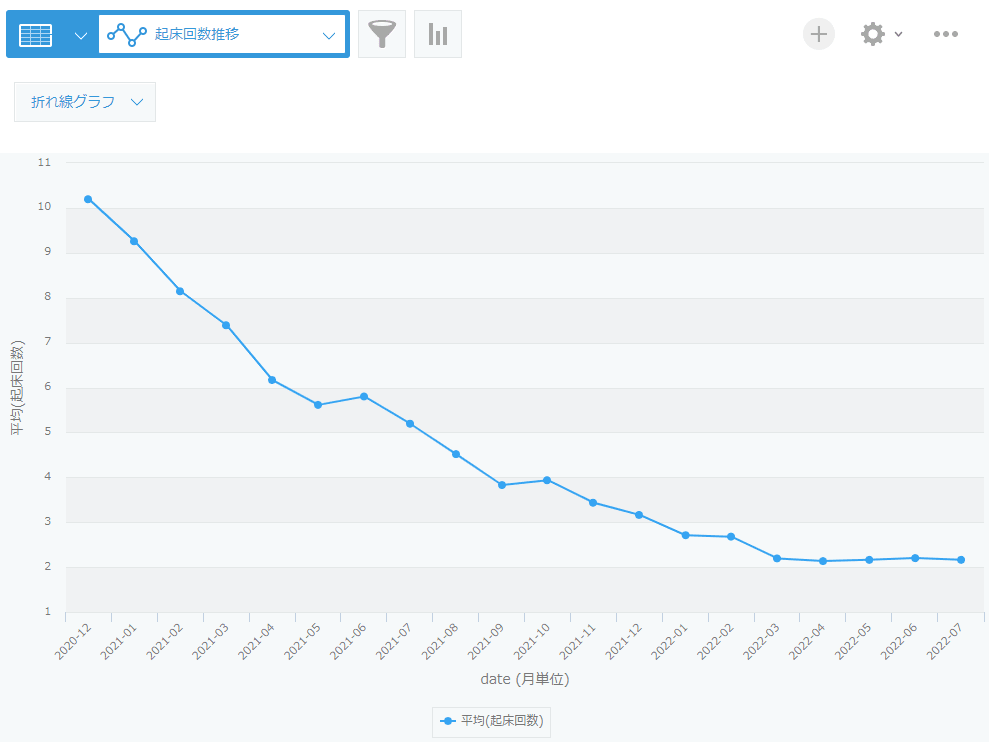
1回あたりの睡眠時間が増えて親的には楽になりましたが、1日の合計睡眠時間が減ってきています。体力がついてきて、起きる時間が長くなっています。2歳未満は11~14時間睡眠/日が目安だそう[2]なので、もう少し日中体力を使わせたいところです。起床回数は順調に減り、2022年3月(1歳5か月)以降は基本的に昼寝と夜寝の2回だけです。
1回あたり平均1時間ちょっとしか寝てくれず、1日10回以上寝て起きてを繰り返す2020年12月(0歳2か月)までが本当に大変でした。まとまった時間寝れない毎日が3か月続いたわけですが、加えて母乳という名の生き血を吸われ続けていた妻のつらさは言語に絶します。今は今で大変ですが、当時に比べれば少なくとも体力的には楽になったでしょうか。子どもは今も昔もかわいいです。
生後0・1か月もデータ取っておけばよかった…。
Discussion