データパイプラインツールMageを紹介する(Snowflakeとの連携のDemoまで)

A modern replacement for Airflow!!
What's Mage?
A modern replacement for Airflow.
Give your data team magical powers
Integrate and synchronize data from 3rd party sources
Build real-time and batch pipelines to transform data using Python, SQL, and R
Run, monitor, and orchestrate thousands of pipelines without losing sleep
データエンジニア・機械学習エンジニアのための、データパイプラインを構築するためのオープンソースツールです。さまざまなデータストアとの連携方法が用意されているため、とても簡単にデータのロードを行うことができます。Python, SQL, Rなどでデータ変換処理を行うことが可能です。GCP, AWS, Azure, Snowflake, DBTなどと連携することができます。
Live Demo
デモ動画:
Introduction
1️⃣🏗️Build
Easy developer experience
ローカルでは、たった1つのコマンドで実行できます。また、Terraformなどを用いて、クラウド上に環境を構築することもできます。
Language of choice
Python, SQL, Rなどを同じデータパイプラインの中で柔軟に組み合わせて使うことができます。
Engineering best practices built-in
データパイプラインの各ステップは、ファイルとして独立しているため、モジュール化されたコードとして、再利用性が可能です。データの検証などを含むテストも可能です。スパゲッティのようなDAGsとはおさらばです。
2️⃣🔮Preview
Stop wasting time waiting around for your DAGs to finish testing.
Get instant feedback from your code each time you run it.
DAG のテストが完了するのにかかる時間を無駄にするのはやめよう。コードを実行するたびに、コードから即座にフィードバックを取得して、確認することができます。
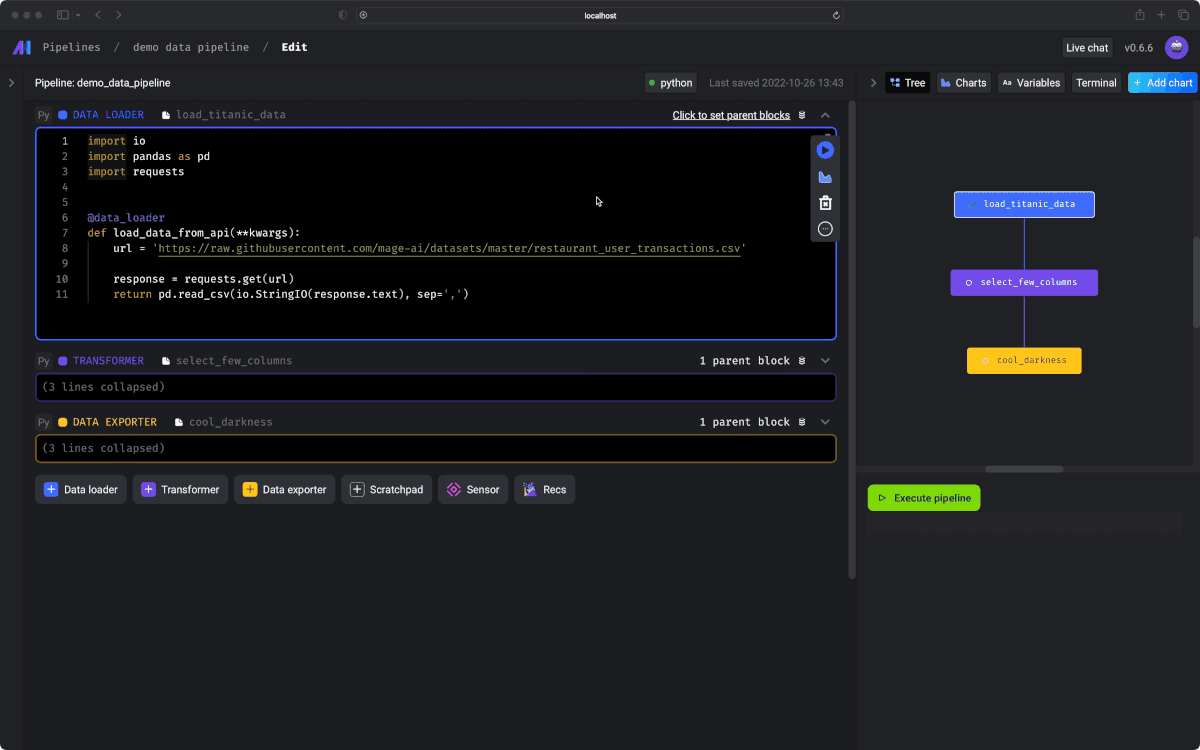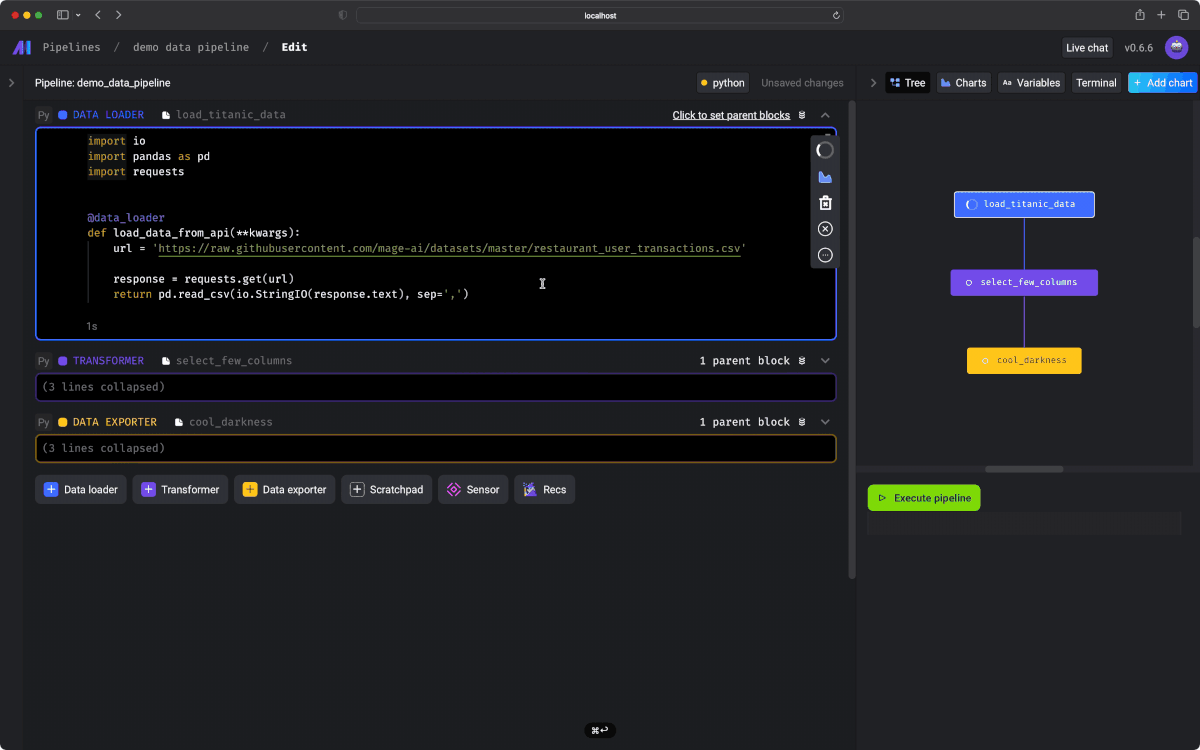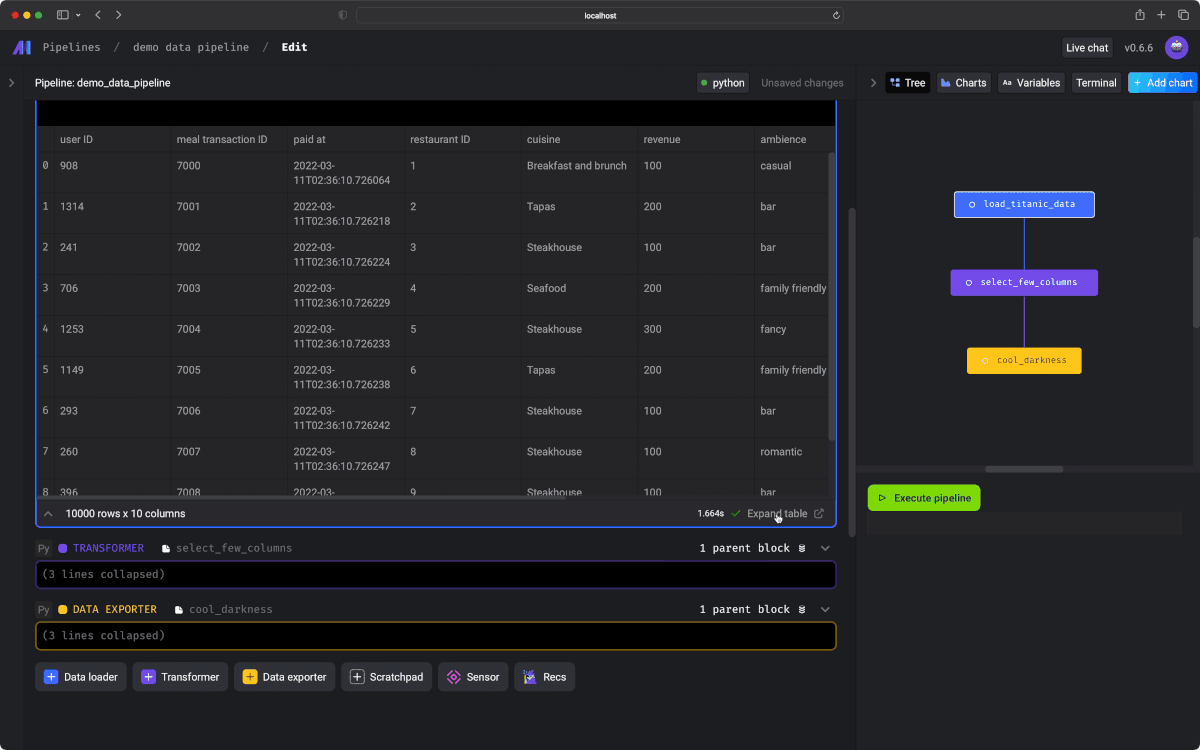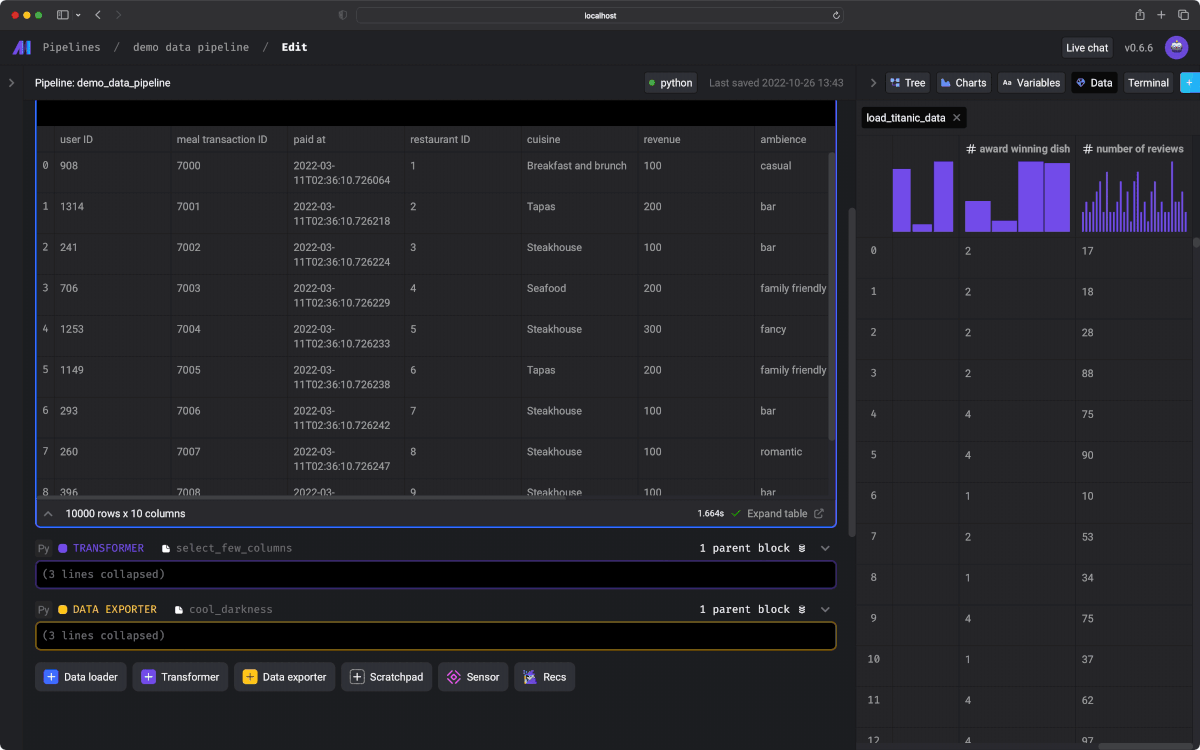
Interactive code
インタラクティブに実行可能なノートブック形式のUIを使用することで、コードの出力結果をすぐに確認できます。
Data is a first-class citizen
パイプライン内のコードの各ブロックは、将来の使用のためにバージョン管理、パーティション分割、およびカタログ化できるデータを生成します。
Collaborate on cloud
クラウド環境を利用して、共同で開発することができます。また、 Git を使用してバージョン管理をすることで、共有のステージング環境が利用可能になる前にパイプラインの構築を始めることができます。
3️⃣🚀Launch
Fast deploy
Terraformテンプレートを利用して、たった2つのコマンドで AWS, GCP, AzureにMageをデプロイすることができます。
Scaling made simple
非常に大きなデータセットをデータウェアハウスで直接変換するか、Spark とのネイティブ統合を介して変換します。
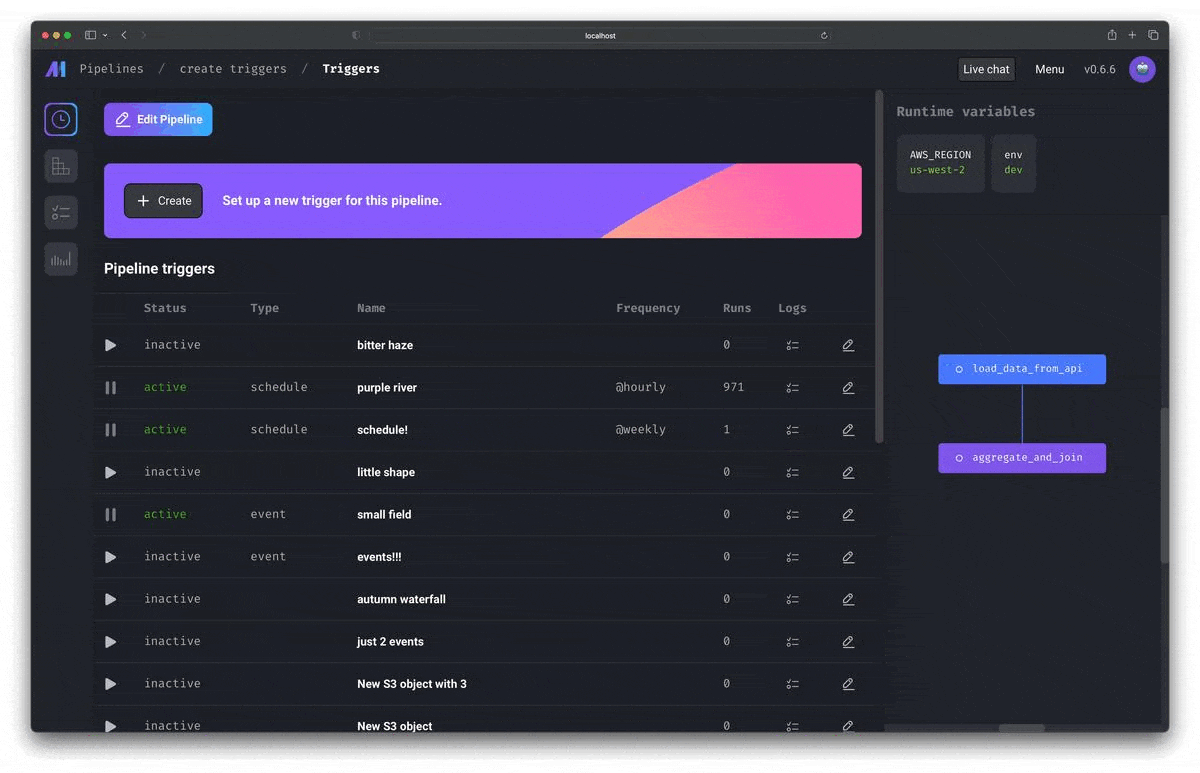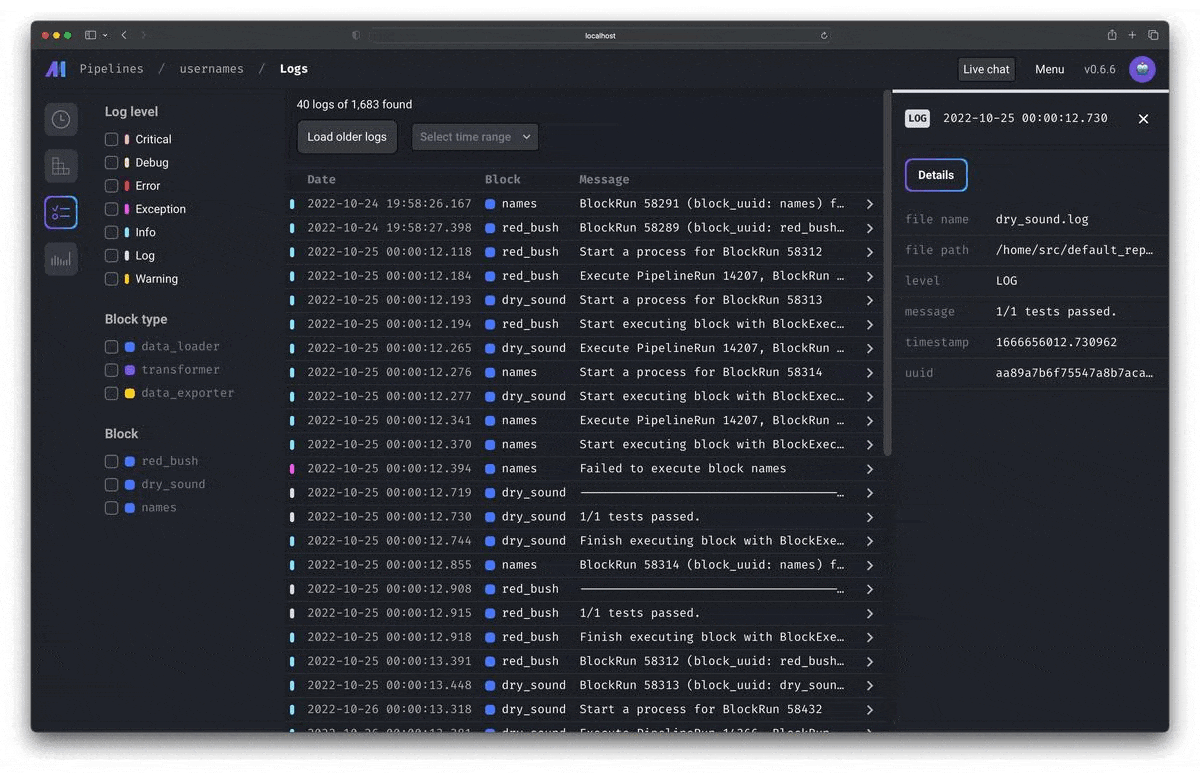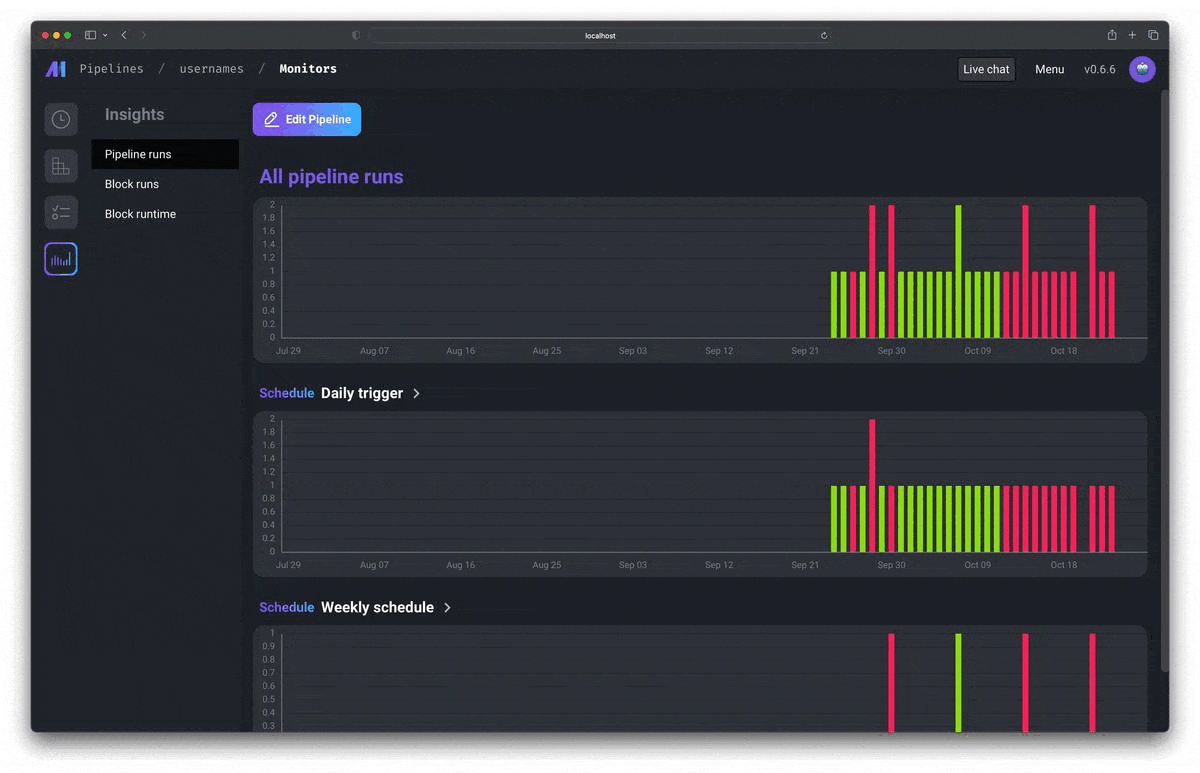
Observability
直感的なUI上で、組み込みのモニタリング、アラート、オブザバビリティを使って運用可能です。
Snowflake との 連携Demo

とりあえず、このデモでは、
- 外部データとの連携が容易にできるのか?
- データパイプラインがどのように作成できるのか?
- データ変換が簡単にできるのか?
などを確認したいので、Snowflakeからデータを読み込んで、データを少し整形して、ローカルに保存する。くらいのことをしてみたいと思います。(今後、DBTを使ったデータ変換などもやってみようと思います)
簡単なデータパイプラインを作成してみます。Dockerを使うと、ローカルで1コマンドで使えるようになります。
docker run -it -p 6789:6789 -v $(pwd):/home/src mageai/mageai \
mage start demo_project
http://localhost:6789 にアクセスしてみると、初期状態のMageのUIを確認することができました👏
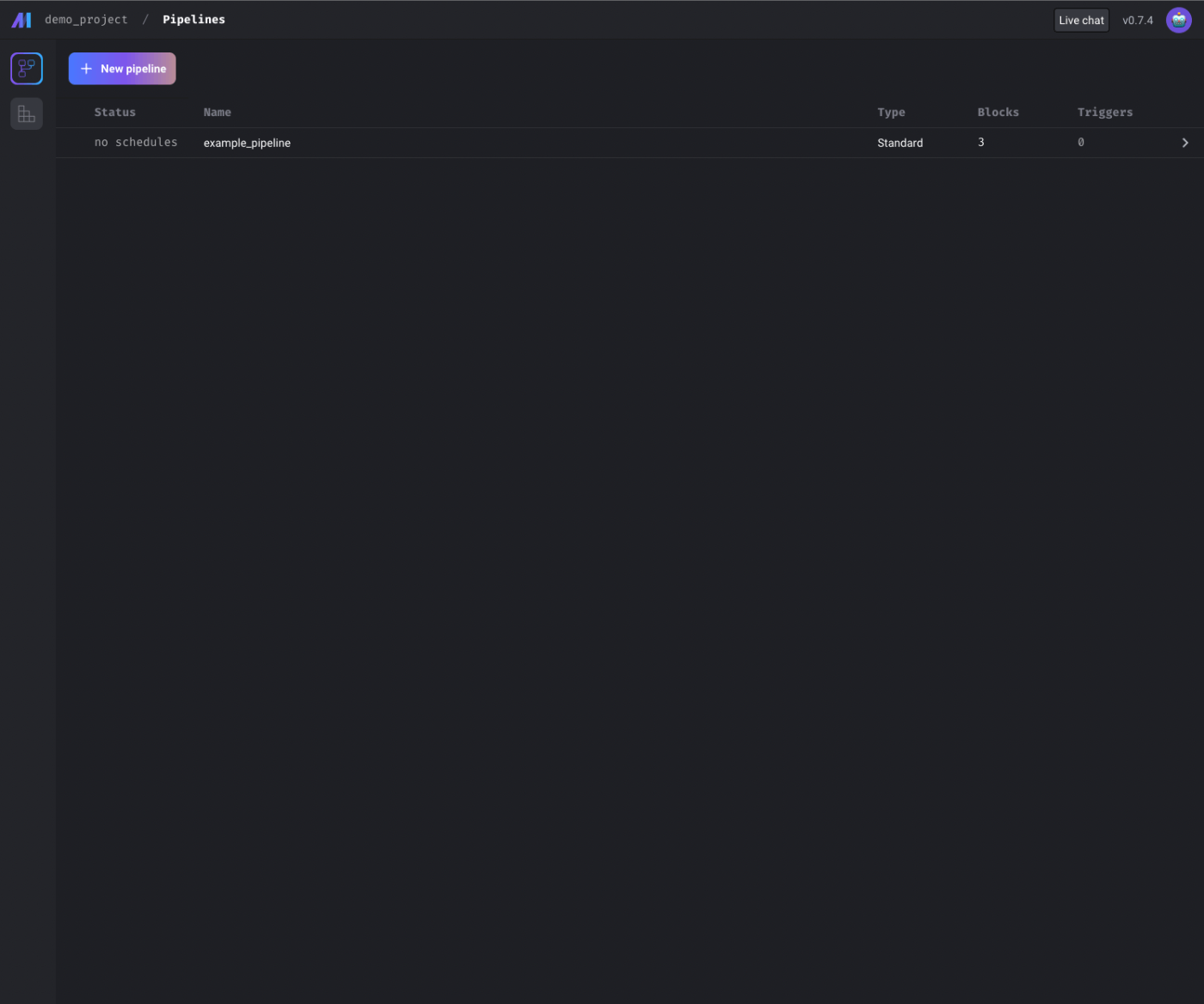
1.Create New Pipeline
とりあえず、Standard(batch)を選んでみます。

以下の選択から新しいブロックを作成できます。

2.Integration with Snowflake❄️
Snowflakeと連携して、Snowflakeからサンプルデータを引っ張ってこれるかやってみます。Data loader > Python を選ぶと、いろいろなデータ連携先が表示されました。

UIからデータ連携先として、選択可能なものは以下の通りで、データ基盤を作る上で必須ツールはある程度は網羅できているみたいです。
- Local file
- API
- Google BigQuery
- Google Cloud Storage
- PostgreSQL
- Amazon Redshift
- Amazon S3
- Azure Blob Storage
- Snowflake
今回は、Snowflakeとの連携を行いたいので、Snowflakeを選択すると、Notebook UIに移動します🎉
もうすでに、テンプレートとなるブロックが用意されてます👏

3.Setup io_config.yaml
認証系の情報は、io_config.yamlで管理するみたいです。最初から必要なものがリスト化されているので、自分が使いたいツールのところだけ埋めてあげれば良いです。Snowflakeとの連携を行うために、yamlの下の方にあるSnowflake関係の情報を入れました。

4.Load data from Snowflake
Snowflakeのサンプルデータを読み込んでみます。
query = 'select * from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER limit 10;'
に変更して、簡単にデータを読み込んでみました。
@data_loader
def load_data_from_snowflake(**kwargs) -> DataFrame:
"""
Template for loading data from a Snowflake warehouse.
Specify your configuration settings in 'io_config.yaml'.
Docs: https://github.com/mage-ai/mage-ai/blob/master/docs/blocks/data_loading.md#snowflake
"""
query = 'select * from SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER limit 10;'
config_path = path.join(get_repo_path(), 'io_config.yaml')
config_profile = 'default'
with Snowflake.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
return loader.load(query)
これでデータフレームとして、Snowflakeからデータを読み込むことができました👏
同じブロックの中でテストがかけるのも面白いと思いました。(@testのところ)
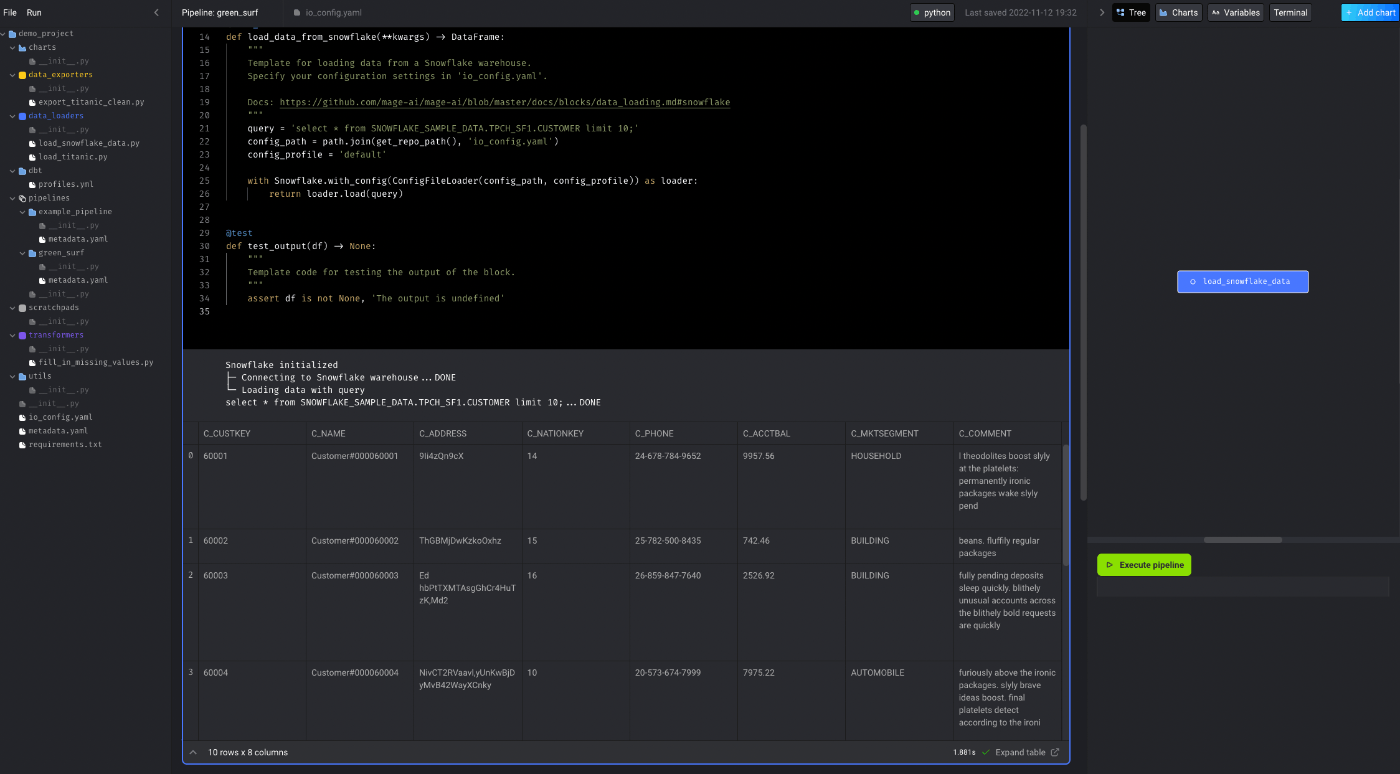
5.Transform data
次にデータ変換をしてみます。Transformerを選ぶと、変換方法のテンプレートを選択することができます。今回は、上で読み込んだデータからカラム数を減らすだけのシンプルな処理を行いたいと思います。データフレームは上のブロックから渡されるようになっているようです。
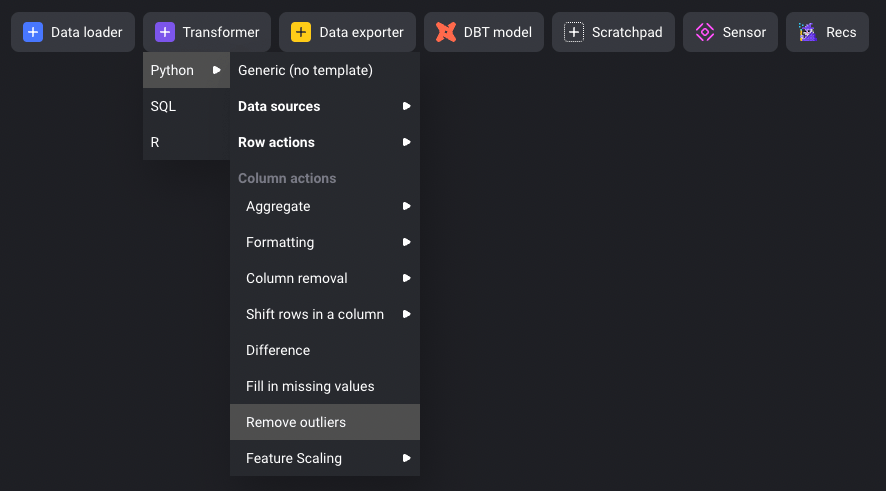
減らしたいカラム名をリストとして渡すことで簡単にカラム数を削減することができました。
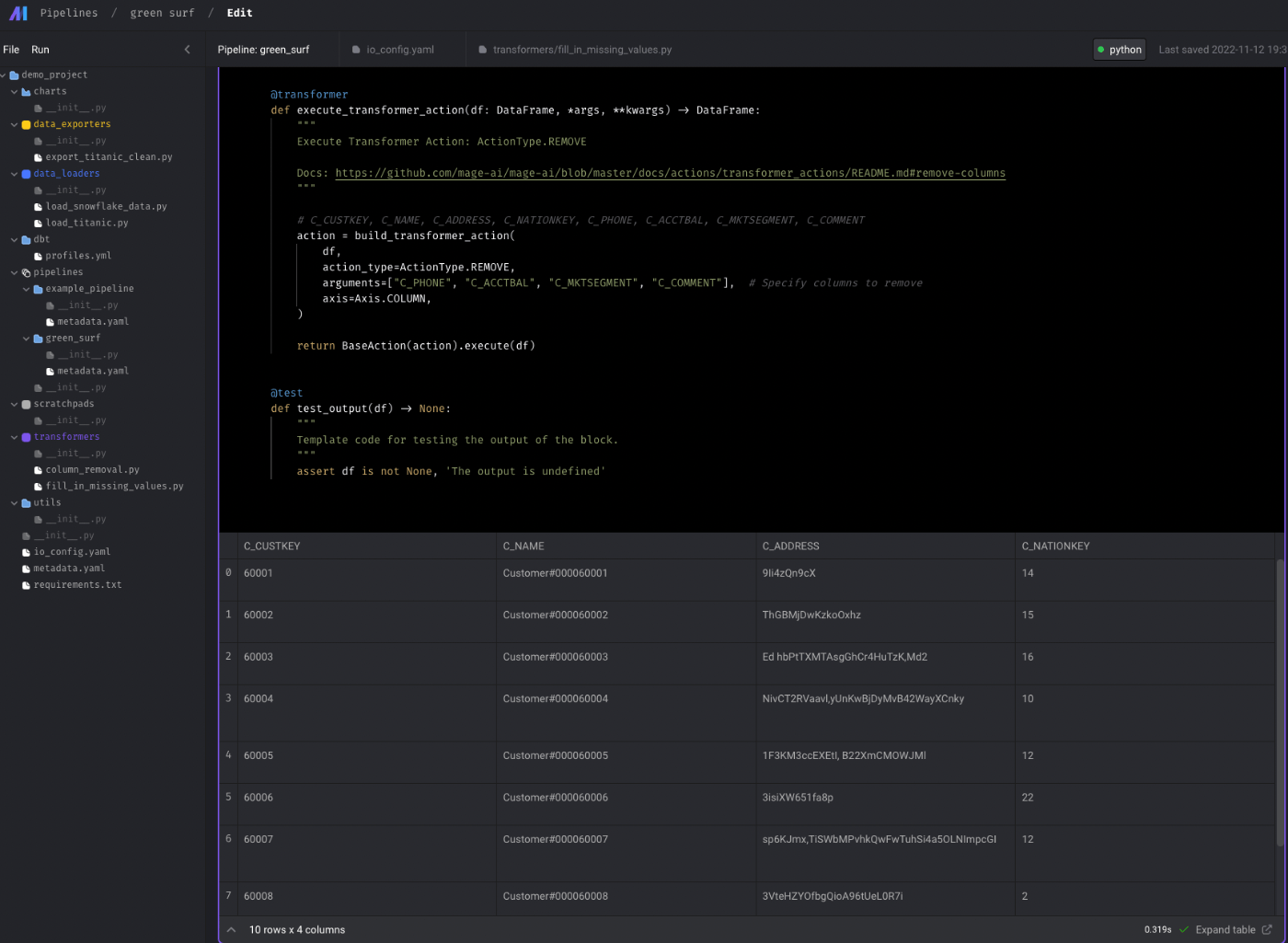
@transformer
def execute_transformer_action(df: DataFrame, *args, **kwargs) -> DataFrame:
"""
Execute Transformer Action: ActionType.REMOVE
Docs: https://github.com/mage-ai/mage-ai/blob/master/docs/actions/transformer_actions/README.md#remove-columns
"""
# C_CUSTKEY, C_NAME, C_ADDRESS, C_NATIONKEY, C_PHONE, C_ACCTBAL, C_MKTSEGMENT, C_COMMENT
action = build_transformer_action(
df,
action_type=ActionType.REMOVE,
arguments=["C_PHONE", "C_ACCTBAL", "C_MKTSEGMENT", "C_COMMENT"], # Specify columns to remove
axis=Axis.COLUMN,
)
return BaseAction(action).execute(df)
6.Export data
最後に読み込んだデータをローカルに保存するという処理を書きます。実際のプロダクトだとクラウドストレージを利用すると思いますが、デモなのでローカルにcsvとして書き出してみます。

Data Exporterというブロックで、ただローカルに保存するPythonを書けば良いだけです。これでローカルに保存できることが確認できました👏
@data_exporter
def export_data_to_file(df: DataFrame, **kwargs) -> None:
"""
Template for exporting data to filesystem.
Docs: https://github.com/mage-ai/mage-ai/blob/master/docs/blocks/data_loading.md#fileio
"""
os.makedirs(path.join(get_repo_path(), 'export'), exist_ok=True)
filepath = path.join(get_repo_path(), 'export/sample.csv')
FileIO().export(df, filepath)
S3などのクラウドストレージのテンプレートも見てみると、io_config.yamlに認証情報を書いた上で、Bucket, keyを指定して書き込むだけなので、とても簡単にできると思いました。
@data_exporter
def export_data_to_s3(df: DataFrame, **kwargs) -> None:
"""
Template for exporting data to a S3 bucket.
Specify your configuration settings in 'io_config.yaml'.
Docs: https://github.com/mage-ai/mage-ai/blob/master/docs/blocks/data_loading.md#s3
"""
config_path = path.join(get_repo_path(), 'io_config.yaml')
config_profile = 'default'
bucket_name = 'your_bucket_name'
object_key = 'your_object_key'
S3.with_config(ConfigFileLoader(config_path, config_profile)).export(
df,
bucket_name,
object_key,
)
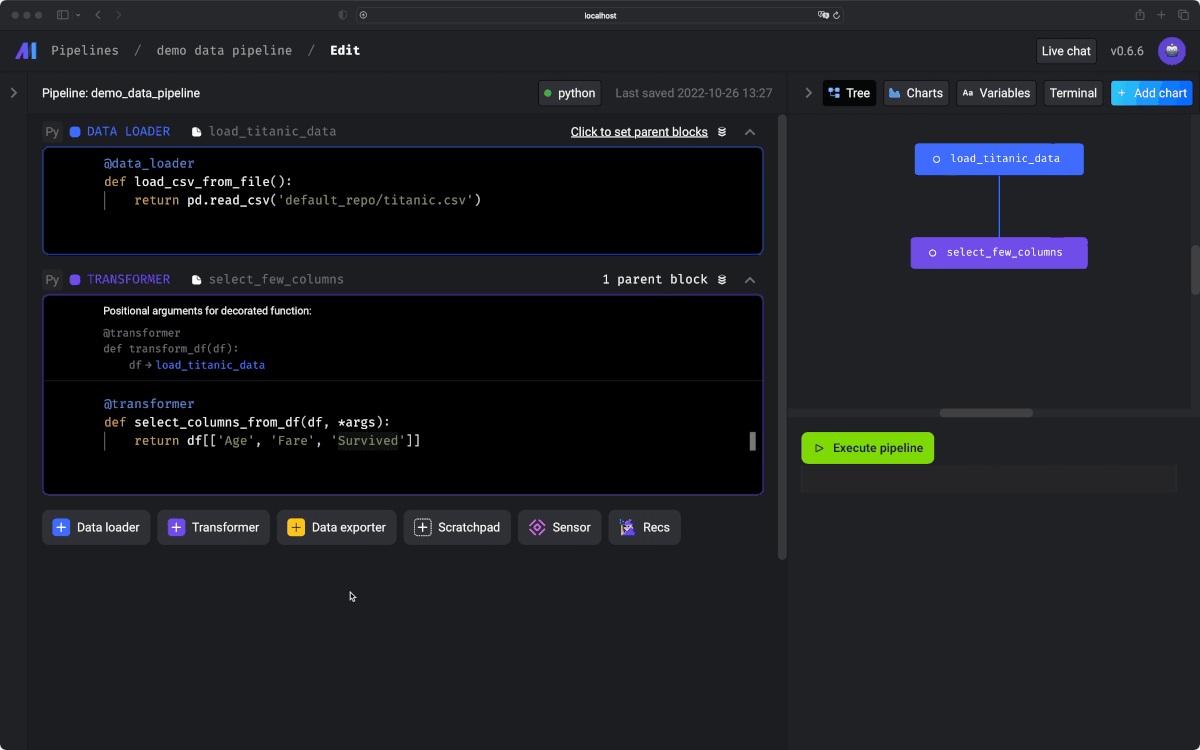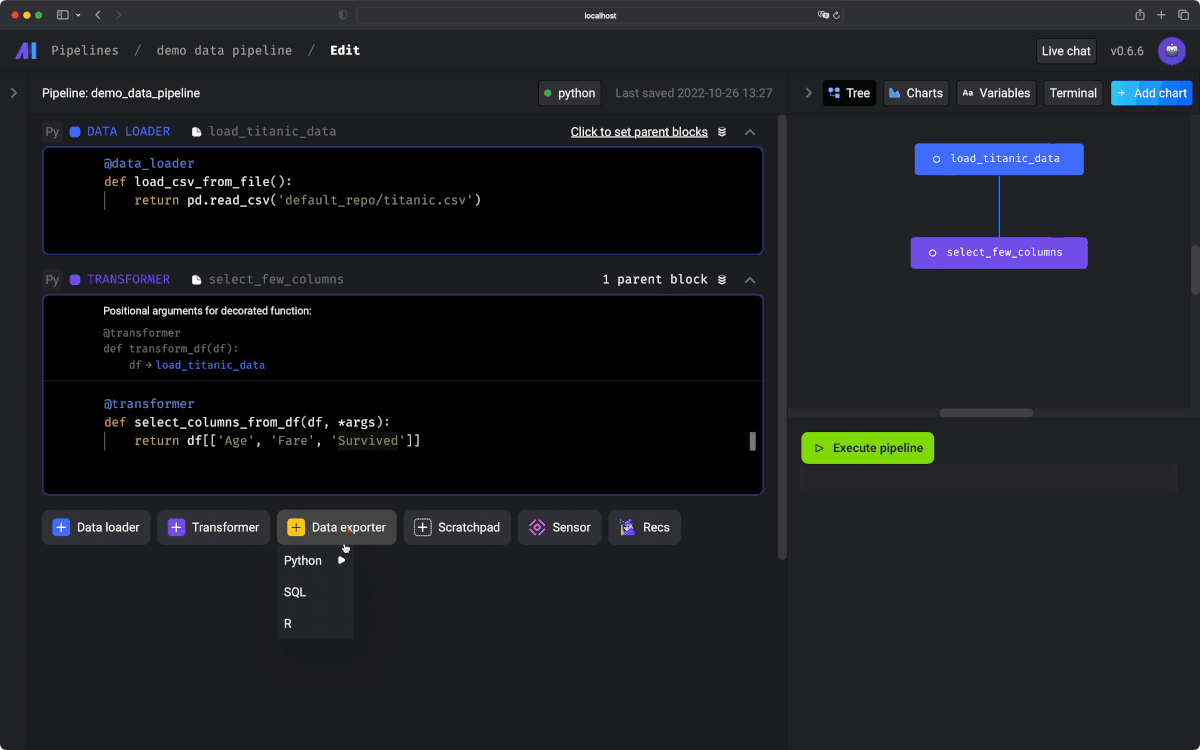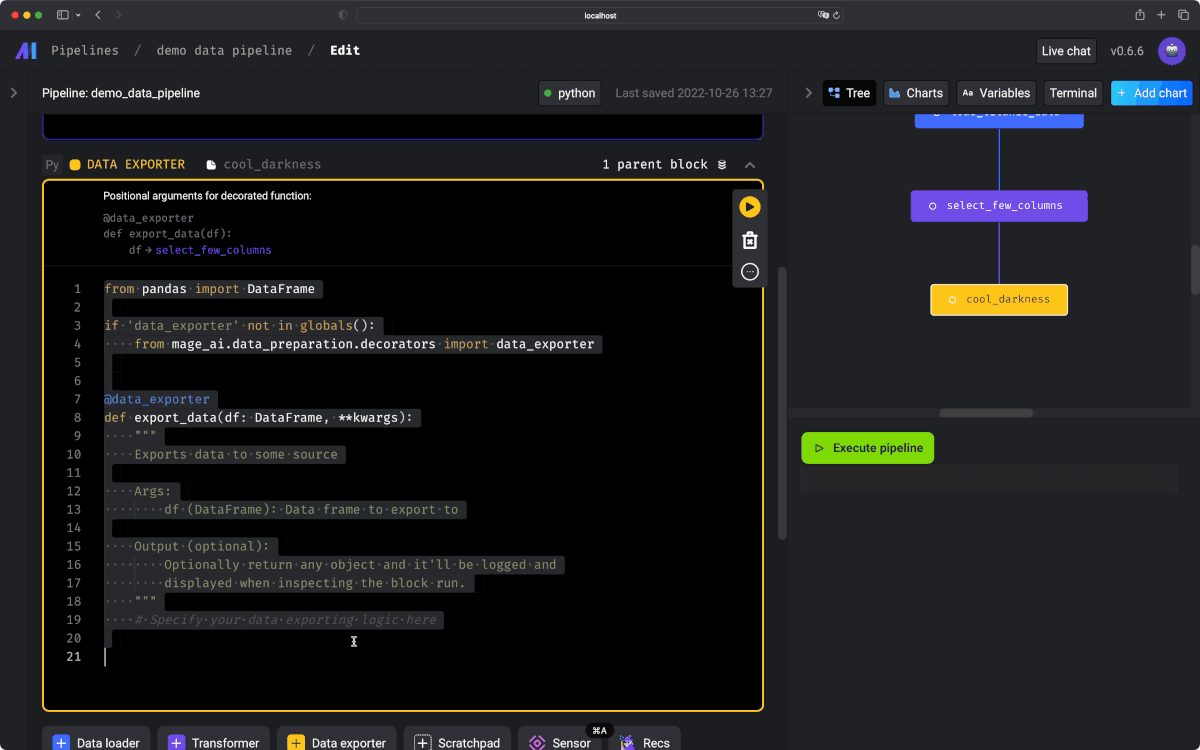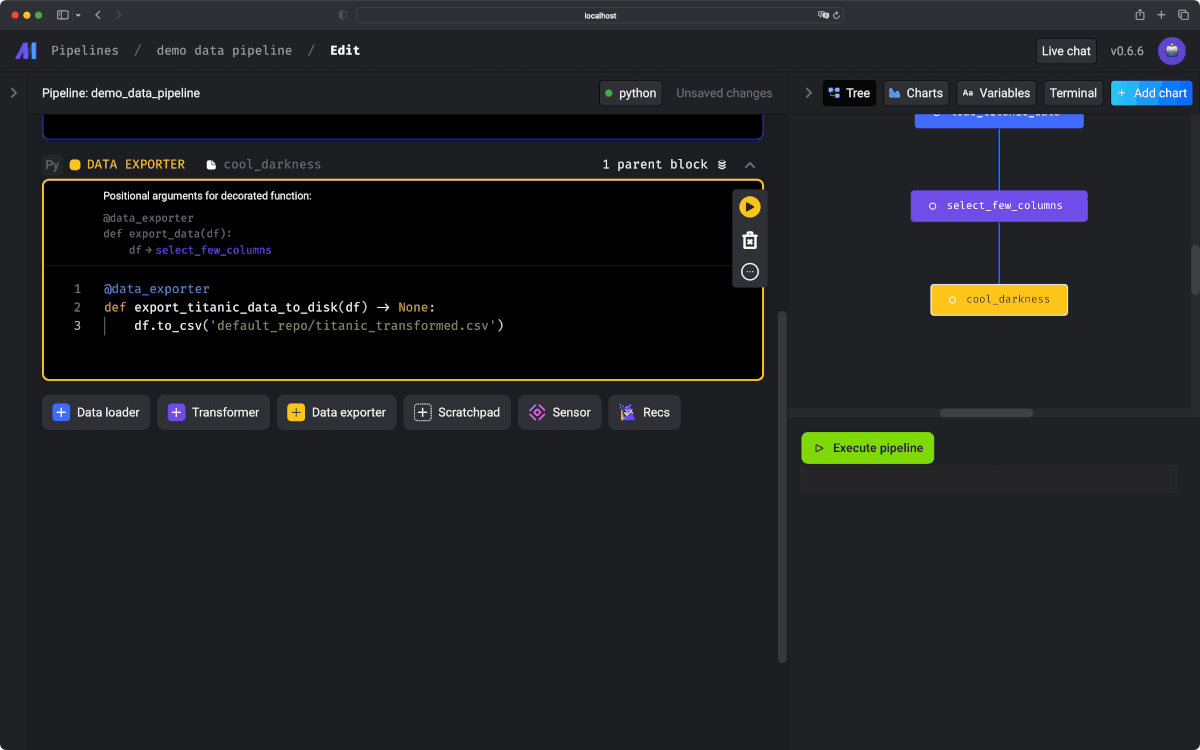
7.Vizualize pipeline tree📊
ノートブックの右にずっと表示されていた、DAGは最終的にこのようになりました。ステップのタイプごとに色分けされていて、見やすくなってます。
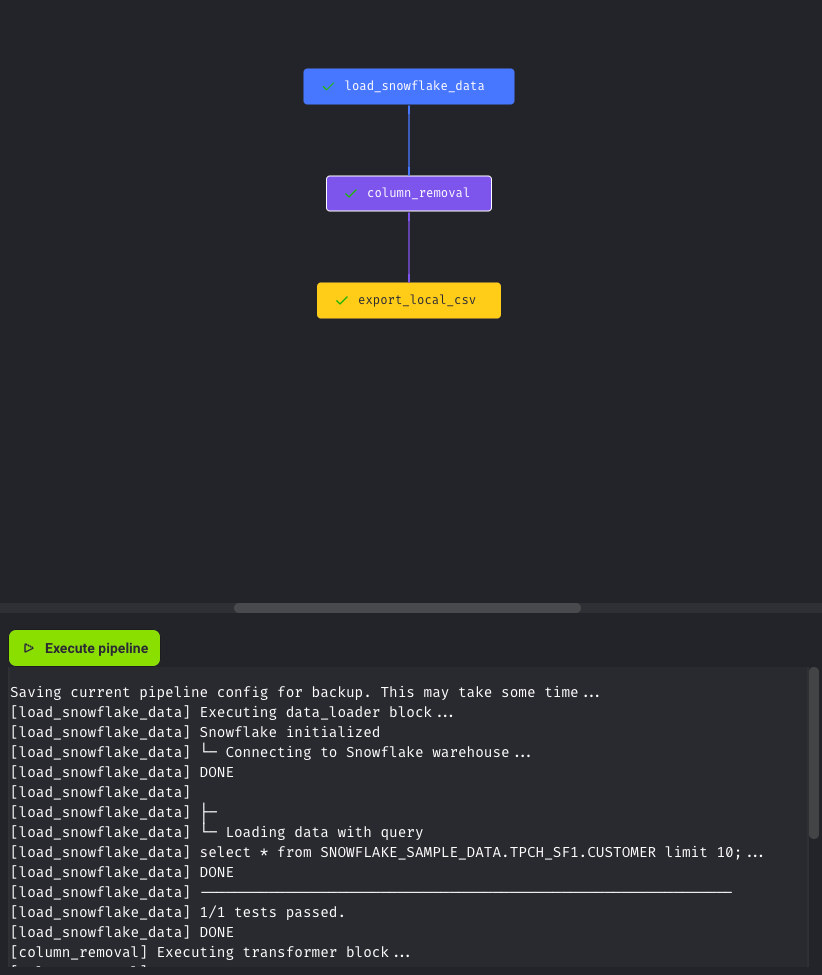
感想
まだ試せていない機能はたくさんありますが、もう少し触ってみたいと思いました。DBTと連携して、データ基盤の設計などに使用してみたいです。また、SnowflakeのDWHの特徴と組み合わせることで、無限にスケールも可能になりそうなので、Mage x Snowflake x DBT + Cloud (AWS etc.)でいい感じにデータ基盤を作成できると期待してます。
Discussion