AWS Data Pipelineってなんだろ?
AWS Data Pipelineについて調べてみました。
AWS Data Pipeline(データの移動や変換を簡単に自動化)| AWS
概要
- データの移動や変換を簡単に自動化
- 指定された間隔で、AWS のサービスやオンプレミスのデータソース間で信頼性の高いデータ処理やデータ移動を行うことを支援するウェブサービス
- 保存場所にあるお客様のデータに定期的にアクセス
- 必要なスケールのリソースで変換と処理を行い、その結果を Amazon S3、Amazon RDS、Amazon DynamoDB、Amazon EMR のような AWS サービスに効率的に転送
- 耐障害性があり、繰り返し可能で、高可用性を備えた、複雑なデータ処理ワークロードを簡単に作成
3行でまとめると、
保存場所にあるデータに定期的にアクセスし、
最低限のリソースで変換や処理を行い、
AWSサービスに転送することができるサービス
というかんじでしょうか。
メリット
- 信頼性
- 使いやすさ
- 柔軟性
- スケーラブル
- 低コスト
- 透過的
イメージ

AWS Data Pipeline を使用して、クリックストリームデータを Amazon S3 から Amazon Redshift に移動します。
よくある質問 - Amazon Data Pipeline | AWS
AWS Data Pipeline とは何ですか?
- AWS クラウドでの定期的なデータ移動やデータ処理といったアクティビティのスケジュールを簡単に設定できるウェブサービス
- Data Pipeline によりオンプレミスとクラウドベースのストレージシステムが統合されるため、開発者はそれらのデータを必要なときに、使用したい場所で、必要な形式で使用できる
- データソース、送信先、および「パイプライン」と呼ばれるデータ処理アクティビティ (あらかじめ定義されたアクティビティまたはカスタムアクティビティ) から成る依存関係をすばやく定義できる
- パイプラインは、定義したスケジュールに基づき、処理アクティビティを定期的に実行
データ処理の流れや方法を定義し、
オンプレとクラウドのデータ移動や処理を
スケジュールに基づいて定期的に実行するウェブサービス
とまとめてみました。
AWS Data Pipeline を使用して何ができますか?
- パイプラインの準備がすばやく簡単に行えるようになり、日次データ運用の管理に必要な開発とメンテナンスの手間が省けるため、そのデータを基にした将来の予測を立てることに集中できる
- 処理アクティビティの実行とモニタリングは、高い信頼性があり耐障害性を備えたインフラストラクチャ上で行われる
- Amazon S3 と Amazon RDS 間でのデータコピーや、Amazon S3 ログデータに対するクエリの実行など、一般的なアクションの組み込みアクティビティが用意されている
一言でまとめると
本来必要な業務に集中できる
だと思います。
そのために、Data Pipelineは「すぐに準備ができて」、「信頼性と耐障害性を備え」、「よくある処理は準備されている」ということだと思います。
AWS Data Pipeline と Amazon Simple Workflow Service の違いは何ですか?
- 両サービスとも、追跡、再試行、例外処理、任意のアクションの実行といった機能を提供
- AWS Data Pipeline では特にデータ駆動型ワークフローの大半に共通する特定の手順を簡素化
- 入力データが特定の準備基準に一致した場合にアクティビティを実行する、異なるデータストア間で簡単にデータをコピーする、変換スケジュールを簡単に設定するなど
- Data Pipeline は特定の手順に高度に特化しているため、コーディングやプログラミングの知識がなくても、ワークフロー定義を簡単に作成できる
「よく行われる処理は手順を簡素化してるから、プログラミングできなくても使える」というのがData Pipelineの特徴のようです。
「よく行われる処理」の例として、「データストア間で簡単にデータをコピーする」などが挙げられています。
パイプラインとは何ですか?
- AWS Data Pipeline のリソース
- データソースの依存関係の定義、送信先、およびビジネスロジックの実行に必要な定義済みまたはカスタムのデータ処理アクティビティなど
冒頭の図全体をイメージし、Data Pipeline全体で扱うリソースと捉えました。
データノードとは何ですか?
- お客様のビジネスデータを表したもの
- 例えば、データノードは特定の Amazon S3 パスを参照できる
- s3://example-bucket/my-logs/logdata-#{scheduledStartTime('YYYY-MM-dd-HH')}.tgz のように指定
データそのものではなく、データのある場所を示す用語というかんじがします。
アクティビティとは何ですか?
- AWS Data Pipeline がパイプラインの一部としてお客様の代わりに実行するアクション
- 例としては、EMR または Hive ジョブ、コピー、SQL クエリ、コマンドラインスクリプトなど
シンプルに考えると、実際の処理のことだと思います。
前提条件とは何ですか?
- 準備状況のチェックのこと
- オプションでデータソースまたはアクティビティに関連付けることができる
- データソースに前提条件チェックがある場合、そのデータソースを使用するアクティビティが起動される前に、その前提条件チェックが正常に完了しなければならない
- アクティビティに前提条件がある場合は、アクティビティが実行される前に前提条件チェックが正常に完了しなければならない
- 高額なコンピューティングアクティビティを実行していて、一定の基準を満たすまではそのアクティビティを実行すべきでない場合に有用
処理を開始するための条件だと思います。
以下のような流れになりそうです。
条件をチェック → チェックが正常に完了 → 処理実行
例として、処理に結構なお金がかかる場合が挙げられています。
「途中までやったけど失敗した」となると、その分も課金されてしまうので、条件をクリアするまでは実行しないという使い方が良いと記述されています。
スケジュールとは何ですか?
- パイプラインのアクティビティが実行されるタイミング、およびサービスがお客様のデータを利用できると想定する頻度
- すべてのスケジュールには開始日と頻度の設定が必要
- オプションで終了日を指定できる
- 終了日以降は、AWS Data Pipeline サービスはいかなるアクティビティも実行しない
処理のタイミングと頻度ですね。
必須なのは「開始日」、「頻度」で
オプションで「終了日」の指定ができるようです。
終了日以降は何もしないことも記述されていますね。
AWS再入門 AWS Data Pipeline編 | DevelopersIO
ポイント
- AWSのマネージドサービスである
- ノード間でのデータ移行やETL処理を実行することができる
- 一般的なスケジューラの機能を持っている(時間指定やサイクリック、依存関係設定など)
- オンプレの処理にも使える
- Data Pipelineはあくまでデータ移行に関するベースの機能を提供
- データの変換と加工については、別途プログラミングが必要
ドキュメントに記載されている「プログラミング不要」というのは「データ移行に関しては」の話だったんですね。
AWSのマネージドサービスである
ハードの調達や管理、運用などなど面倒なことはAWSにお任せってやつですね。
データ移行やETL処理を実行することができる
- 開発用のGUI
- AWSサービス間の単純なデータ移行くらいであれば、簡単なマウスとキーボードの操作だけで処理を作り、実行できる
- 複雑な変換や加工の処理を実行したい場合でも、自前で開発したプログラムをData Pipelineで実行させることができる
ドキュメントにも、「ウェブサービス」としての提供と書かれていましたね。
専用のGUIで簡単にできる部分は簡単にでき、自前のプログラムも実行できるようです。
一般的なスケジューラの機能を持っている
- 複数に分割されたデータ移行やETL処理を連携して実行できる
- 意図した時間に実行できる
- サイクリック実行も可能
- エラーになった場合のアクションも設定可能
単なるスケジューラではなく、エラー時のアクションも設定できるのもいいですね。
オンプレの処理にも使える
- Task RunnerというJavaのプログラムをインストールするだけで、オンプレのサーバだとしてもData Pipelineで扱うことができるようになる
これでクラウドでもオンプレでもデータ移動などができるようになるんですね。
ユースケース
既存のRDBからRedshiftにデータを投入するパターンということです。
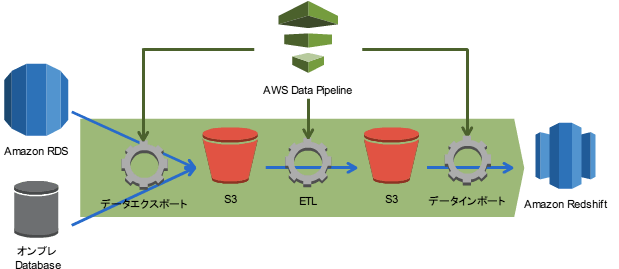
- 既存のRDBからはS3に対してソースデータをエクスポート
- Redshiftのテーブルに合わせて変換と加工
- 最終的にRedshiftにインポート
コンソール
パイプラインの設定
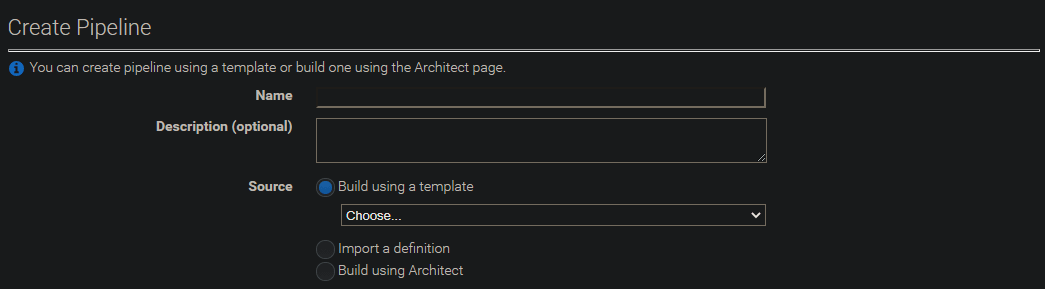
処理のテンプレート

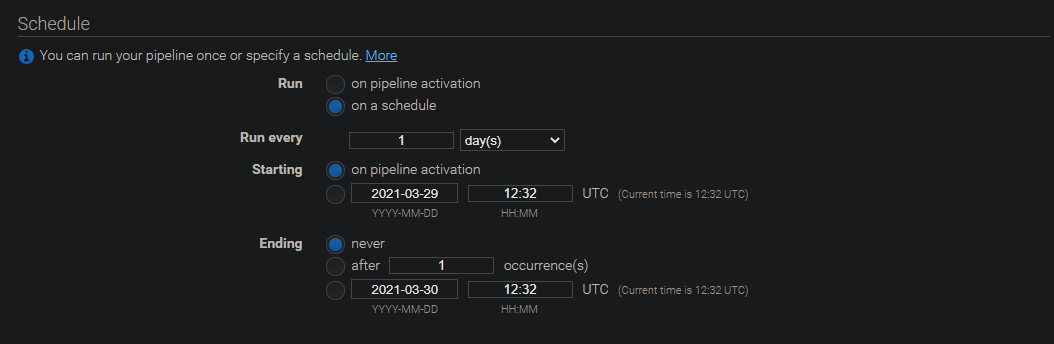
スケジュールの設定
パイプラインのログ設定?

IAMによるアクセス権限の設定

タグ

GUI

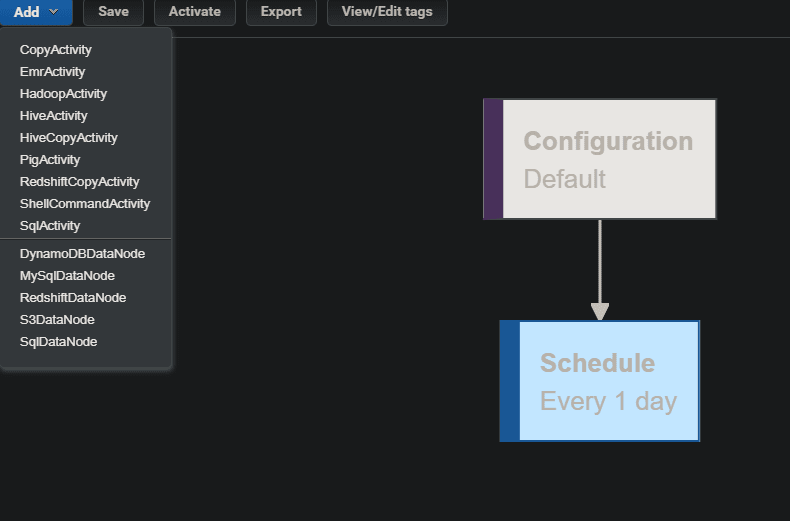
これだけ見ると、確かに簡単なデータ移動だけならノーコーディング & GUIでササっとできそうです。
まとめ
今回はAWS Data Pipelineについて調べてみました。
以下がポイントでした。
- オンプレとクラウドのデータ移動や処理を、スケジュールに基づいて定期的に実行するウェブサービス
- よく行われる処理は手順を簡素化してるから、プログラミングできなくても使える
- パイプラインとは、Data Pipeline全体で扱うリソース
- データノードは、データのある場所を示す
- アクティビティは、実行するアクション
- 前提条件とは、処理を開始するための条件
- スケジュールには開始日、頻度、終了日(オプション)を指定する
- データの変換と加工については、別途プログラミングが必要
- 自前で開発したプログラムをData Pipelineで実行可能
- エラー時のアクションも設定可能
- Task RunnerというJavaのプログラムをインストールしてオンプレで利用する
参考になれば幸いです。
Discussion