Lambda (Python) でスクレイピングしようとしたら盛大にハマった


Lambda でスクレイピングしようと、ネット上の 10 以上の記事を見たのですが、どれを試してもエラーが発生し、盛大にハマりました。
その解決策として、2 つの方法を見つけたので紹介します。
結論
- docker-selenium-lambda を使用する
- Beautiful Soup を使用する
経緯
Lambda (Python) でスクレイピングを検索すると、以下の組み合わせが多くヒットしました。
・Selenium
・Chromdriver
・serverless-chrome
上記の組み合わせによる複数の記事の内容を試したのですが、以下のようなエラーが次々と発生しました。
・SessionNotCreatedException
・PermissionError
・WebDriverException Status code was: 127
上記のエラーの解決策として、以下のような方法がヒットしました。
・Chromdriver と serverless-chrome のバージョンを合わせる
・chmod で権限を付与
・ChromeOptions の options.add_argument のオプション設定を変更する
しかし、いずれの方法でもエラーは解決しませんでした。
また、Python のバージョンによって、Lambda ランタイムが異なることも原因と推測し、Python 3.6 ~ Python 3.9 でも上記の解決策を試しましたが、エラーは解決しませんでした。
ヒント
serverless-chrome の GitHub Issue で解決策を探している中で、docker-selenium-lambda が紹介されていました。
また、Selenium や Chromdriver 以外でスクレイピングする方法については、以下の記事で紹介されており、こちらもヒントになりました。
以下にそれぞれで試した内容を紹介します。
1. docker-selenium-lambda を使用する方法
こちらの方法では以下のツールを使用します。
- docker-selenium-lambda にアクセス
- docker-selenium-lambda リポジトリを
git clone - ECR にデフォルト設定でプライベートリポジトリを作成
- クローンしたリポジトリのルートディレクトリで、ECR のプッシュコマンドを実行
- Lambda 関数作成時にコンテナイメージを選択し、4 で ECR にプッシュしたイメージを選択
- その他の Lambda の設定はデフォルトで Lambda 関数を作成
- Lambda 関数のメモリを 256 MB、タイムアウト値を 10 秒に変更
-
hello-worldテンプレートのテストイベントを作成し、テスト実行 - 以下のような結果が表示されれば成功
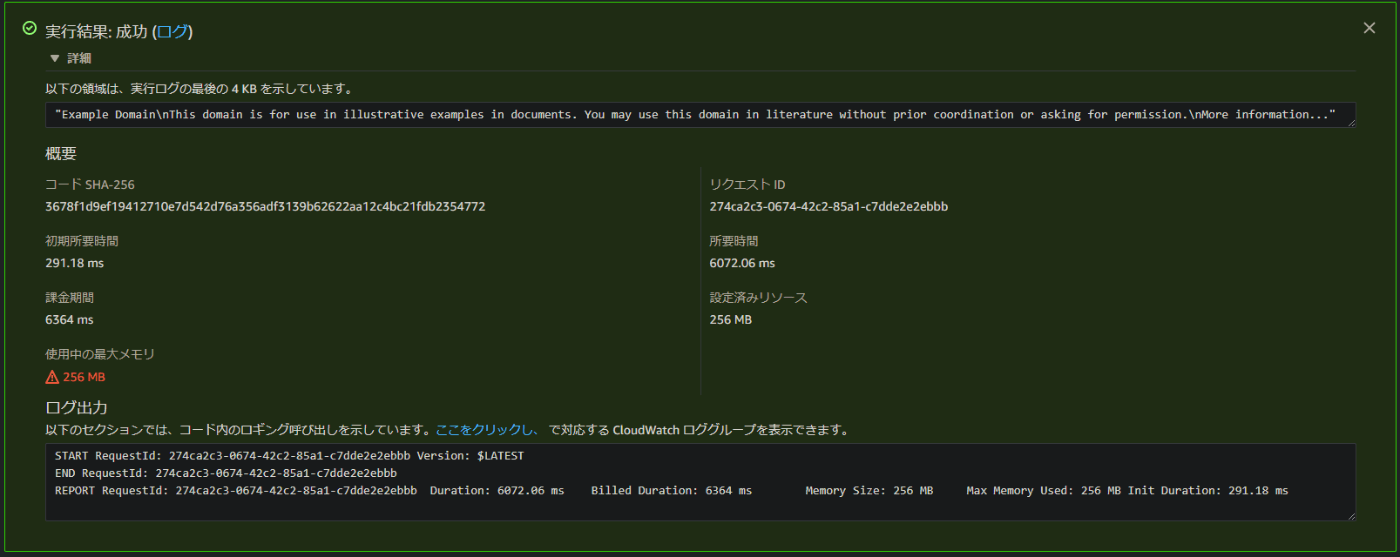
場合によってはメモリやタイムアウト値は調整する必要があるかもしれません。
こちらの方法の場合、リポジトリに Dockerfile が定義されているので、必要に応じてコード側を変更してプッシュすれば、任意の処理にカスタマイズできます。
試すだけならノーコーディングでできるので、コンテナに慣れている方はこちらの方法がよいかもしれません。
2. Beautiful Soup を使用する方法
こちらの方法では以下のツールを使用します。
こちらの方法では Lambda レイヤーの作成が必要です。
-
pythonという名前のディレクトリを作成 -
pythonディレクトリ内で、pip install requests beautifulsoup4 -t ./を実行 -
pythonディレクトリを zip 化 - 3 で作成した zip ファイルを Lambda レイヤーにアップロード (ランタイムは任意)
- 任意の Python バージョンで Lambda 関数を作成
- 作成した Lambda 関数の Layers から 4 で作成したレイヤーを追加
- Lambda 関数のコードに以下のコードを貼りつけ、Deploy
import requests
from bs4 import BeautifulSoup
def lambda_handler(event, context):
url = 'https://example.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find("title")
title = title.text
return title
-
hello-worldテンプレートのテストイベントを作成し、テスト実行 - 実行結果に
"Example Domain"と表示されれば成功
こちらでも必要に応じてメモリやタイムアウト値は調整してください。
コンテナはよく分からないけど、Lambda でスクレイピングしたいという方には、こちらの方法がよいかもしれません。
まとめ
今回は Lambda でスクレイピングする際にハマったので、その解決策として、2 つの方法を紹介しました。
参考になれば幸いです。
Discussion