ChatGPT の Fine-tuning を試したけど上手くいかなかった話
これはなに?
- 新しくリリースされた ChatGPT (GPT-3.5 Turbo) の Fine-tuning を試してみたメモ。
- ChatGPTに最新の知識や専門知識を注入できるかどうかをテストしてみた。
- 結局、自分が想定した動きにはできなかったので記事にして供養します🙏
tl;dr
- 一晩試してみた程度では、ChatGPTに最新の知識を教え込む目的での Fine-tuning はうまく動かなかった。
- OpenAIが提示している想定のユースケースとずれている利用方法なので、もう少しトライしても上手くいかないんじゃないかなと思う。
- 学習データに入れた質問をそのまま投げてあげると回答できることもある程度だった。(このままでは到底使えない…)
- 出力のトーンや言語の指示にプロンプトの文字数を大量に使っていて、それを大幅に削減したい、という時には使えそうだなという印象だった。
- 学習データの自動生成を上手くできたのが良い副産物だったのでその部分を多めに書く🤗
Fine-tuning の流れ
- 学習データの準備
- 既にあるものを利用する or 自分で作る
- 今回はWikipediaの記事をもとに、gpt-3.5-turbo に自動生成させた。
- 学習データのOpenAIサーバーへのアップロード
- Fine-tuning の実行 & しばし待つ
- Fine-tuned Model の利用 & 定性評価
1. 学習データの準備
学習データの自動生成
ChatGPTのFine-tuningでは以下のようなフォーマットの質疑応答データを用います。
{
"messages": [
{ "role": "system", "content": "You are an assistant that occasionally misspells words" },
{ "role": "user", "content": "Tell me a story." },
{ "role": "assistant", "content": "One day a student went to schoool." }
]
}
他の「やってみた」記事では既に準備されている質疑応答のデータセットを使っていることが多そうです。それはそれで良いのですが、自分が実際に Fine-tuning を利用したいシーンを考えると、学習データは自前で準備する必要があるなと思っています。
そのため、教えたい内容のドキュメントを準備した上で、学習データセットをそこから自動生成することにしました。長くなるので利用したコードは折りたたんで載せておきます。
学習データ生成用コード
from glob import glob
from tqdm import tqdm
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.output_parsers import OutputFixingParser, PydanticOutputParser
from typing import List #, Optional
from pydantic import BaseModel
SYSTEM_PROMPT = "In response to the given user questions, you will provide as many question-answer pairs as possible."
PROMPT= """
The following is the latest information prepared for fine-tuning ChatGPT about {thema}.
I want to create question-answer pairs from this information.
Please create a question that allows me to understand what you are referring to just by reading the question itself.
- Good Question Example
- How many points did the Nadeshiko Japan team score in the second match of the 2022 AFC Women's Asian Cup?
- What kind of tournament was the 2022 EAFF E-1 Football Championship held in July 2022 for the Nadeshiko Japan team?
- In which position did the Nadeshiko Japan team finish in the group stage of the 2022 AFC Women's Asian Cup?
- Which group is the Nadeshiko Japan team in for the 2023 FIFA Women's World Cup?
- Bad Question Example
- Is this tournament being referred to as the best FIFA Women's World Cup ever? (Bad Reason: It's hard to understand what you're referring to just by reading the question.)
- Which player scored a goal in the quarter-finals? (Bad Reason: What is "quarter-finals" referring to? When? etc.)
- Who is the player that participated in all games? (Bad Reason: What is "all games" referring to?)
- Which team emerged as the winner? (Bad Reason: In what tournament? When? etc.)
- Did Nagano participate in all matches? (Bad Reason: What is "all games" referring to?)
- What did he have in his possession? (Bad Reason: Who is "he"?)
---
# Information
{text}
---
# Output Format
{{
"question_answer_pairs": [
{{"question": -- question (string) --, "answer": -- answer (string) --}},
{{"question": -- question (string) --, "answer": -- answer (string) --}},
...
]
}}
---
Please try to create AS MUCH AS POSSIBLE UNIQUE question-answer pairs in language used for given text.
Please make sure to COMPREHENSIVELY COVER the content of the following text:
"""
class QA(BaseModel):
question: str
answer: str
class QACollection(BaseModel):
question_answer_pairs: List[QA]
LLM = ChatOpenAI(temperature=0)
PARSER = OutputFixingParser.from_llm(
parser=PydanticOutputParser(pydantic_object=QACollection),
llm=LLM
)
def ask(thema, text):
prompt = PromptTemplate(
input_variables=["thema", "text"],
template=PROMPT,
)
chain = LLMChain(
llm=LLM,
prompt=prompt,
verbose=False
)
res = chain.run(thema=thema, text=text)
return PARSER.parse(res).question_answer_pairs
def main():
# ./data/training_text にあるテキストデータを読み込む
training_text_paths = glob('./data/training_text/*.txt')
training_texts = {}
for training_text_path in training_text_paths:
# ファイル名からテーマを取得する
thema = training_text_path.split('/')[-1].split('.')[0]
# テキストデータを読み込む
with open(training_text_path, 'r') as f:
training_texts[thema] = f.read()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name='gpt-3.5-turbo',
chunk_size=2000,
chunk_overlap=500
)
for thema, text in training_texts.items():
texts = text_splitter.split_text(text)
for paragraph in tqdm(texts):
# response example: QA(question='なでしこジャパンは2022 AFC女子アジアカップで何位になった?', answer='ノックアウトステージに進めるために全勝で1位になった。')
res = ask(thema, paragraph)
# パースした結果を train.jsonl に保存する (question, answer)
# {"messages": [{"role": "system", "content": "You're a chatbot that also knows the latest information."}, {"role": "user", "content": - question here -}, {"role": "assistant", "content": - answer here -}]}
with open('./data/2020824_finetune_train.jsonl', 'a') as f:
for qa in res:
f.write(f'{{"messages": [{{"role": "system", "content": "You\'re a chatbot that also knows the latest information."}}, {{"role": "user", "content": "{qa.question}"}}, {{"role": "assistant", "content": "{qa.answer}"}}]}}\n')
if __name__ == '__main__':
main()
題材の準備
ChatGPTが知らない最新の情報ならなんでもよかったので、ちょうどFIFA女子ワールドカップが終わったところだし、なでしこジャパンのWikipedia記事から最新の動向をテキストとして切り出してきました。(本記事の要旨にあまり関係ないのでアコーディオン内に入れておきました)
学習用テキスト (後でこのテキストから質疑応答データセットを作ります)
2022年、2022 AFC女子アジアカップに出場し、初戦でミャンマーを相手に5-0の快勝を収めると、続くベトナムにも3-0の快勝でノックアウトステージ進出を決める。全勝対決となった第3戦の韓国戦では植木理子がキックオフからわずか30秒で先制ゴールを決める。その後は相手に危うい場面を作られながらも山下杏也加の度重なる好セーブで相手の攻撃を凌いでいたが、試合終盤にセットプレーから失点して1-1の引き分けに終わるも、グループ1位でノックアウトステージに駒を進める。2023 FIFA女子ワールドカップ出場がかかったタイ戦では菅澤優衣香の4ゴールなど7得点の大勝で2023 FIFA女子ワールドカップの出場権を獲得した。アジアカップ3連覇を目指して挑んだ準決勝の中国戦では前半26分に植木理子が先制ゴールを決め、前半を1点リードで折り返す。しかし、後半始まってわずか2分で同点ゴールを決められると、その後は度重なる決定機を活かせず90分で決着はつかずに延長戦へ。延長戦では今大会絶好調の植木理子がセットプレーから勝ち越し点を奪うが、5バックで逃げ切りを図った後の終了直前に追い付かれてPK戦へ。そのPK戦では終了直前の失点が影響したのか、2つのシュートストップで敗戦を喫し、アジアカップ3連覇を逃した。
同年7月に行われたEAFF E-1サッカー選手権2022は、池田太体制となって初めての国内試合となった。初戦で2022 AFC女子アジアカップのGS第3戦で終了直前の失点で1-1の引き分けに終わった韓国と対戦。前半33分に宮澤ひなたが先制ゴールを決め、前半を1点リードで終える。59分にチ・ソヨンのゴールで一時は追いつかれるが、65分に長野風花が代表初ゴールを決め2-1で勝利した。第2戦は前回大会でシュート46本かつ被シュート0本、9得点の大勝を挙げたチャイニーズタイペイと対戦した。ところが、前半8分に相手にセットプレーのチャンスを与えてしまうと、このセットプレーからスー・シンユンにヘディングシュートを決められ先制点を献上。前半終了直前に上野真実の代表初得点で2-1と逆転して試合を折り返すが、前回対戦時の9得点とは大違いの結果を残すことに。ところが後半は菅澤が投入されるとそこから攻守で立て直しを図り、4-1の逆転勝利で大会連覇まであと1勝に迫った。最後は2022 AFC女子アジアカップ・準決勝で2度のリードを守れずにPK戦で敗れた中国と対戦。負け以外で優勝が決まる中で日本は終始攻め続けたが得点を挙げることはできず、0-0のまま試合は終了し、大会連覇を達成したが相手の4倍ものシュートを放ちながら決定力不足を露呈する結果に終わった。
2023 FIFA女子ワールドカップではグループCに入り、初出場のザンビア、コスタリカ、スペインと同居するザンビア以外2022 FIFAワールドカップで日本が対戦した2か国と同じ顔触れになった。初戦のザンビア戦を5-0で大勝すると、続くコスタリカ戦もワールドカップ初出場の藤野あおばがW杯初ゴールを決めたことで2-0の勝利で4大会連続の決勝トーナメント進出を大会史上最速で決めた[69][70][71]。勝利以外1位通過はないという状況で挑んだ3戦目のスペイン戦は藤野と同じくワールドカップ初出場の宮澤ひなたが2ゴールを決めるなど4-0の快勝を収め、1次リーグを11得点無失点という圧倒的な強さで1位通過を決めた[72]。
そうして迎えた決勝トーナメント1回戦のノルウェー戦は前半20分にグーロ・レイテンのゴールで今大会初失点を喫するも、後半に清水梨紗と宮澤ひなたの活躍で2得点を奪い、3-1の勝利で2大会ぶりのベスト8進出を決めた[73]。中6日で迎えた準々決勝は東京2020オリンピック準々決勝で1-3と完敗したスウェーデンと対戦。日本は開始からスウェーデンにボールを持たれる展開の中で前半32分にアマンダ・イレステトにゴールを決められ今大会初めて先制点を許す苦しい展開に。シュートを1本も打てないまま前半を終えると後半も開始わずか6分で長野風花がCKでハンドの反則をVAR判定で取られてしまい、与えたPKをフィリパ・アンイエルダールに決められて2点ビハインドを負う展開に。その後は積極的な攻撃姿勢で徐々に突破口を開いていき、87分には2018 FIFA U-20女子ワールドカップ優勝メンバーの1人である林穂之香が1点差に詰め寄るゴールを決めるも同点に追いつくことはできず1-2で惜敗。東京2020オリンピックの雪辱を果たせず、ベスト8で大会を去ることとなった(チームは2度目のフェアプレー賞を、宮澤ひなたは2人目となる大会得点王を受賞)[74]。
殊勲の得点王となった宮澤は「今大会はチームメイト全員の団結力も勝ち上がる基盤を作ったと思います。チーム力の向上のためにも、まずは個のレベルアップが必要と感じました。W杯はプレーや判断など全てにおいてスピードが違いました。」と大会後に語り[75]、2011年大会の優勝に刺激され、全試合に出場した長野は「若い世代に『なでしこは誰にも勝てるんだ』ということを示し、一人でも多くの若い観客に勇気を与えたいです。」と、ビッグトーナメントで結果を残す事の重要性を説いた[76]。
優勝したスペインを唯一破ったのが本代表であるが、FIFAのジャンニ・インファンティーノ会長は自身のインスタグラム上で「準々決勝のスウェーデン戦では惜しくも敗戦に終わったが、今回の大会が史上最高のFIFA女子ワールドカップになったことへの貢献は、フィールド内外で誰もが忘れない」と、特定のチームに異例とも言えるメッセージを綴った[77]。また、今大会から配分金が大幅に増額され、準々決勝敗退による支給額は全選手に1人あたり9万ドル(約1300万円)となった[78]。
質疑応答を生成
上のアコーディオンに格納したコードで gpt-3.5-turbo を用いて学習データ(質疑応答)を生成しました。
生成したものは以下のような感じで、全部で60件くらいの学習データとしました。(ちょっと少ないかも?)
見ての通り英語ですが、理由はすぐ後に説明します。
{"messages":[
{"role": "system", "content": "You're a chatbot that also knows the latest information."},
{"role": "user", "content": "Who did the Nadeshiko Japan team play against in their first match of the 2023 FIFA Women's World Cup?"},
{"role": "assistant", "content": "Zambia"}
]}
{"messages": [
{"role": "system", "content": "You're a chatbot that also knows the latest information."},
{"role": "user", "content": "Who won the 2023 FIFA Women's World Cup?"},
{"role": "assistant", "content": "Spain"}
]}
学習データ自動生成で工夫した点
英語
gpt-3.5-turboに投げるプロンプトは以下のように英語で書き、また、英語で回答させるようにしました。
PROMPT= """
The following is the latest information prepared for fine-tuning ChatGPT about {thema}.
I want to create question-answer pairs from this information.
Please create a question that allows me to understand what you are referring to just by reading the question itself.
- Good Question Example
- How many points did the Nadeshiko Japan team score in the second match of the 2022 AFC Women's Asian Cup?
- What kind of tournament was the 2022 EAFF E-1 Football Championship held in July 2022 for the Nadeshiko Japan team?
- Which group is the Nadeshiko Japan team in for the 2023 FIFA Women's World Cup?
- Bad Question Example
- Is this tournament being referred to as the best FIFA Women's World Cup ever? (Bad Reason: It's hard to understand what you're referring to just by reading the question.)
- Who is the player that participated in all games? (Bad Reason: What is "all games" referring to?)
- Which team emerged as the winner? (Bad Reason: In what tournament? When? etc.)
- Did Nagano participate in all matches? (Bad Reason: What is "all games" referring to?)
---
# Information
{text}
---
# Output Format
{{
"question_answer_pairs": [
{{"question": -- question (string) --, "answer": -- answer (string) --}},
{{"question": -- question (string) --, "answer": -- answer (string) --}},
...
]
}}
---
Please try to create AS MUCH AS POSSIBLE UNIQUE question-answer pairs in language used for given text.
Please make sure to COMPREHENSIVELY COVER the content of the following text:
"""
日本語のプロンプトや回答だとGPT-4を利用してもPromptの指示を守れませんでした。具体的には 質問を読んだだけでなんの話をしているかわかるようにして という指示が全然守れませんでした。
これでは学習データとして利用できないと思ったため、日本語の利用は早々に諦めました。
- 良い質問の例: なでしこジャパンは2023 FIFA女子ワールドカップでどのグループに入った?
- 悪い質問の例: なでしこジャパンはどの試合で敗戦に終わったのか? (この質問だけだと2023年の女子ワールドカップの話をしているということがわからない)
Pydantic & Output Fixing Parser
学習データ自動生成を思いついた時、まずはFunction Callingの利用を思いつきましたがFunction Callingだと1回の gpt-3.5-turbo のコールで1つの質疑応答しか作れませんでした。
何度も呼ぶと質問の幅が出ない(パターンが少なくなりそうな)ので、一度のコールでたくさんの質疑応答データをjsonで吐くようにしました。出力形式を守らせるために以下のように Pydantic と OutputFixingParser を利用しました。
端的にいうと以下のようなイメージです。
-
Pydanticで出力の型定義をしておくと、 - ChatGPTがその出力を守るまで
OutputFixingParserが何度かトライしてくれる (帰れまテンしてくれる)
Function Callingも便利ですが、それでは要件を満たせない場合もあるかと思います。そのような場合はこの手法を使うとそこそこ上手く出力がコントロールできるかと思います。
from pydantic import BaseModel
from typing import List #, Optional
class QA(BaseModel):
question: str
answer: str
class QACollection(BaseModel):
question_answer_pairs: List[QA]
def ask(thema, text):
llm = ChatOpenAI(temperature=0)
prompt = PromptTemplate(
input_variables=["thema", "text"],
template=PROMPT,
)
chain = LLMChain(
llm=LLM,
prompt=prompt,
verbose=False
)
res = chain.run(thema=thema, text=text)
PARSER = OutputFixingParser.from_llm(
parser=PydanticOutputParser(pydantic_object=QACollection),
llm=llm
)
return PARSER.parse(res).question_answer_pairs
question_answer_pairs = ask(llm, thema, paragraph)
RecursiveCharacterTextSplitter
チャンクサイズが小さすぎると質問文が作れなかったので RecursiveCharacterTextSplitter.from_tiktoken_encoder を利用して、ドキュメントを分割しました。(参考: 拙著 第8章: 長時間Youtube動画を要約しよう)
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name='gpt-3.5-turbo',
chunk_size=2000,
chunk_overlap=500
)
チャンクが細切れになって文脈が失われると適切な質問文が生成できなかったので、ある程度、overlapを大きく取りつつsplitしました。

学習データなんてなんぼあってもええですからね
2. 学習データのアップロード
学習データが生成できたので、OpenAIのガイド記事の通りにまずはファイルをアップロードします。
注意点はこんな感じでしたが、ほぼ詰まることはなかったです。
- アップロードしたあと暫く待つ必要がある
- アップロードしたファイルの名前じゃなくてアップロード後の File IDを取得する必要がある
- 考えたらわかるのですがガイド記事に書いてなくて最初少し混乱した
def upload_training_data_to_openai(file_name):
"""
Upload training data to open ai
openai.File.create() returns:
{
"id": "file-abc123",
"object": "file",
"bytes": 120000,
"created_at": 1677610602,
"filename": "my_file.jsonl",
"purpose": "fine-tune",
"format": "fine-tune-chat",
"status": "uploaded",
"status_details": null
}
"""
res = openai.File.create(
file=open(file_name, "rb"),
purpose='fine-tune'
)
uploaded_file_id = res['id']
while True:
time.sleep(5)
res = openai.File.retrieve(uploaded_file_id)
if res['status'] == 'processed':
break
print('waiting for processing')
return uploaded_file_id
3. Fine-tuning の実行 & 待つ
これもOpenAIのガイド記事の通りにやります。training_fileがFile IDの指示ということさえわかっていれば迷うことはなさそうでした。
API仕様書を読んでいると suffix_id の指示とかもできました。これでモデルの識別が簡単になります。
また上手く動かない場合はepoch数増やしてみろという記述も発見したので、以下のサンプルコードではdefaultの3より少し増やしてあります。
def exec_fine_tuning(file_id):
return openai.FineTuningJob.create(
training_file=file_id,
model="gpt-3.5-turbo",
suffix="nadeshiko",
hyperparameters={
"n_epochs": 5
}
)
createジョブを投げると、実行が終わればメールで知らせてくれます。なんか面白い。

ジョブの状況は以下のコードでも取得は可能です
>>> openai.FineTuningJob.list()
<OpenAIObject list at 0x121212777> JSON: {
"object": "list",
"data": [
{
"object": "fine_tuning.job",
"id": "ftjob-hogehogefugafuga",
"model": "gpt-3.5-turbo-0613",
"created_at": 1692877777,
"finished_at": null,
"fine_tuned_model": null,
"organization_id": "org-hogehogefugafuga",
"result_files": [],
"status": "running",
"validation_file": null,
"training_file": "file-hogehogefugafuga",
"hyperparameters": {
"n_epochs": 5
},
"trained_tokens": null
}
],
"has_more": false
}
4. Fine-tuned Model の利用 & 定性評価
学習済みモデルの利用
さて、学習が終わればメールに記載されている (or APIで取得する) model_name を用いて利用できます。以下のコードでも学習ずみモデルが利用可能ですが、OpenAI Playground でも利用可能なので、ここでやり取りをしてみるのがわかりやすいでしょう。

import os
import openai
completion = openai.ChatCompletion.create(
# ここに学習済みモデルの model_name を入れる
model="ft:gpt-3.5-turbo-0613:personal:nadeshiko:hogehogehoge",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who did the Nadeshiko Japan team play against in the quarter-finals of the 2023 FIFA Women's World Cup?"}
]
)
print(completion.choices[0].message['content'])
結果を見てみる
それでは結果を見てみましょう。まずは通常のgpt-3.5-turboになでしこジャパンのワールドカップの結果を聞いてみます。ナレッジカットオフが2021年9月なので当然知りません。

次は、ファインチューンしたモデルに聞いてみます。
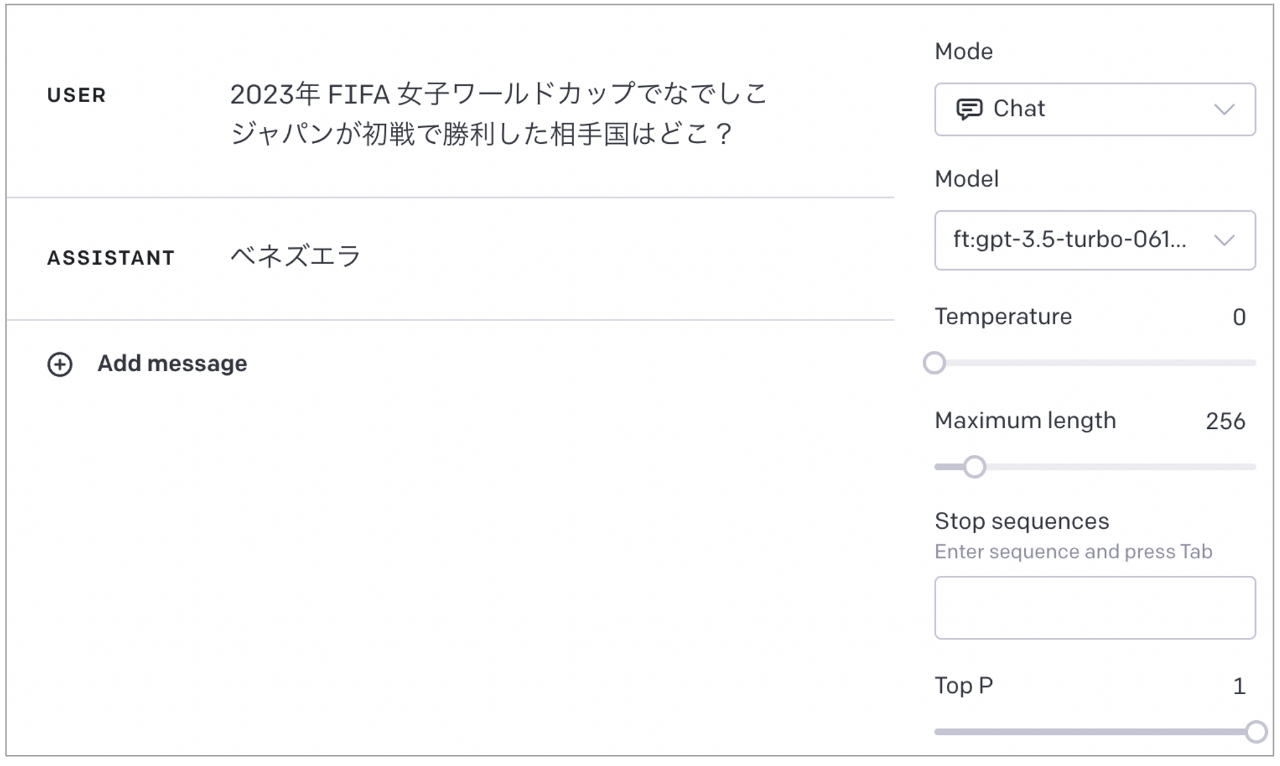
正解はザンビアです
日本語わからなかったかな?ということで、学習データに入れたまんまの英文で聞いてみます。
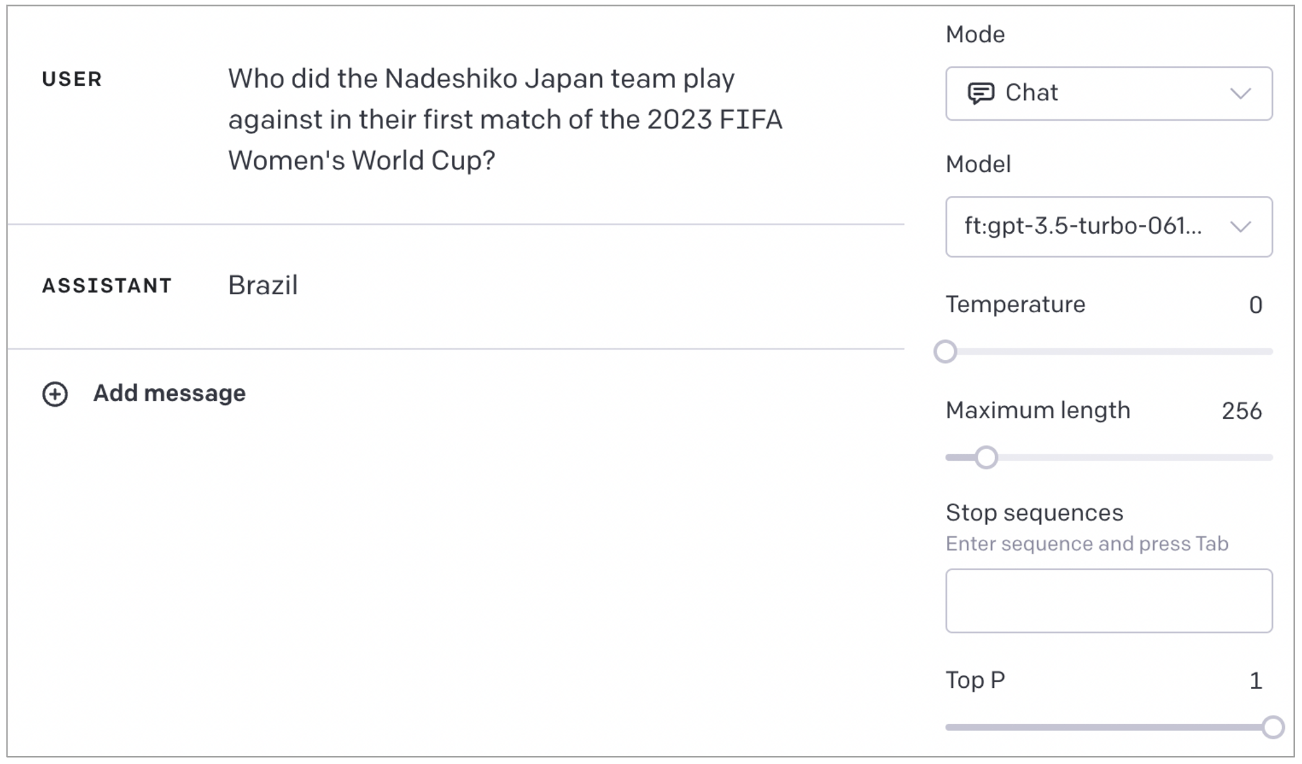
ダメそうです
内容が細かすぎたのかな?ということで、質問を変えてみます。これも英語で答えを教えてあるデータです。

願望かな?
英語で聞いてみましょう。なんと答えられました。
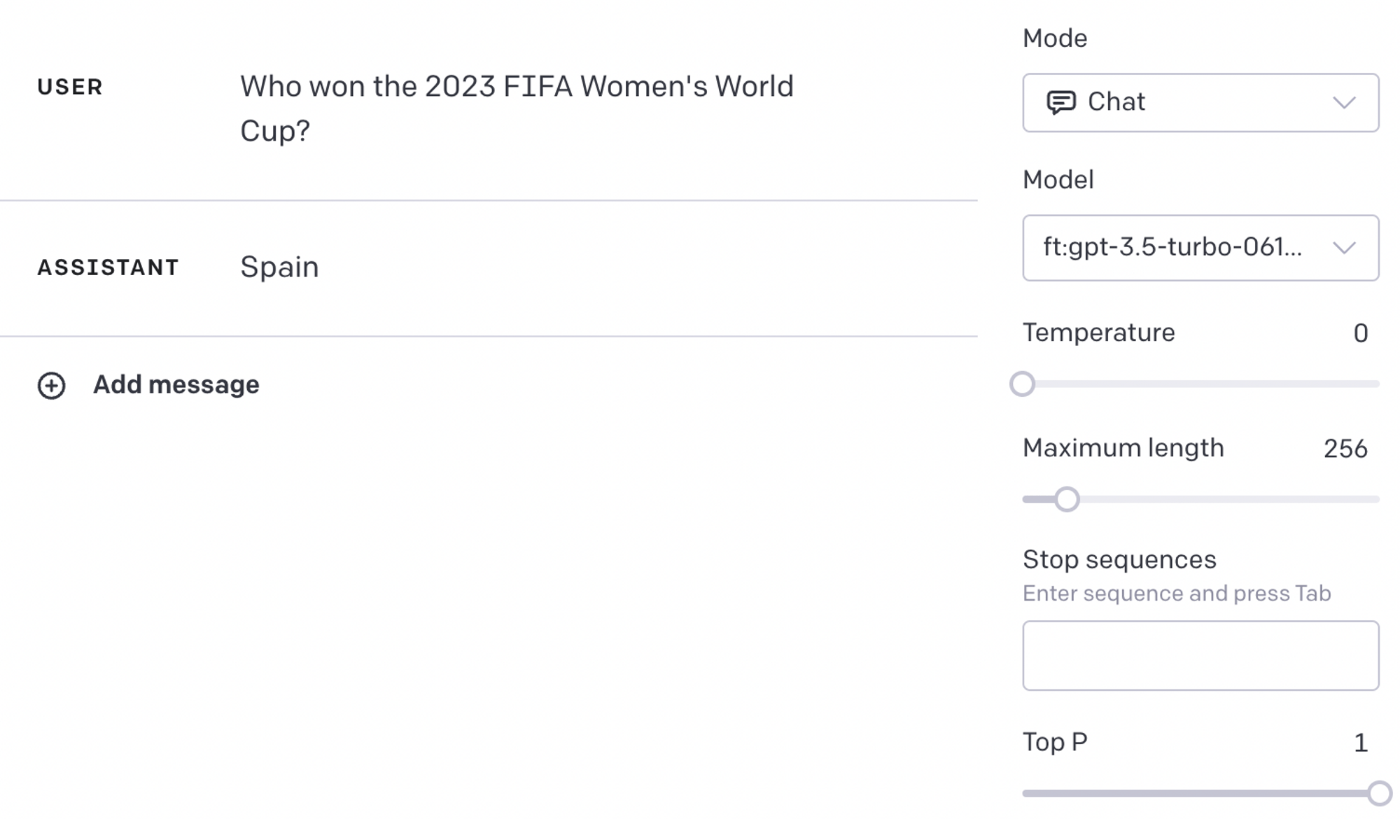
おぉ正解!
ほかにも答えられる質問はあるものの、まぁこのままだと使えんなぁという感じです。同じような使い方をしてうまくいったと書いている記事はcherry pickかなという印象ですが、僕のやり方が悪いかもしれないので断定的な表現は避けておきます。
- 正解の例

なんでそんな細かいこと覚えてるのに初戦の相手間違うねん
- 不正解の例
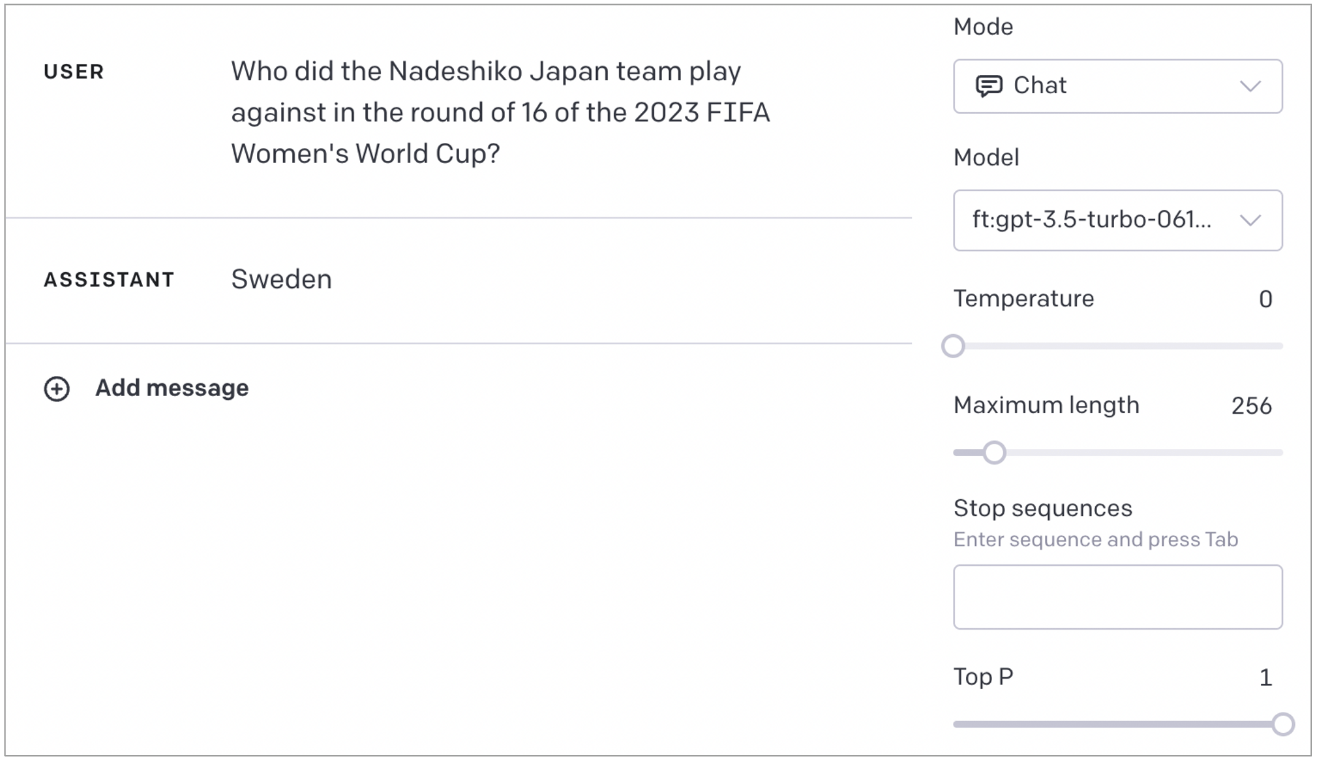
準々決勝と勘違いしてる?
まとめ
学習データの自動生成も含めて、ChatGPTのFine-tuningに挑戦してみました。たった一晩試しただけなので今後意見が変わるかもしれませんが、少なくとも今回のトライでは最新知識や専門知識をChatGPTに教えるという使い方は難しいように感じました。うまくいった方いらっしゃれば、ぜひ情報交換させてくださいm(_ _)m
上記のような回答の例を見てみると、結果をズバッと答えるという回答スタイルは学習データから引き継がれているような気がします。「出力のトーンを変更する」のはOpenAIが代表的なユースケースとしてあげていますが、そのような側面ではFine-tuningが適切に動作しているのかもしれません。
またFine-tuningの実行自体は驚くほど簡単で、さすがOpenAIと思わせられました。今後も便利な機能がどんどん実装されるようなので楽しみです。
それではまたお会いしましょう!
Discussion
とても参考になりました。ありがとうございます。
fine tuning びっくりするくらい期待外れですよね。
法律の条文のデータ入れたんですけど、条項番号がとんでもない返答が返ってくるレベル
embeddingのほうがまだましなんじゃないだろうかという感じです。