🤖
【2024年末で更新停止】主要な大規模言語モデル比較表
これはなに?
- 自著 「つくりながら学ぶ!生成AIアプリ&エージェント開発入門」 に掲載するために作ったOpenAI・Anthropic・GoogleのLLMの一覧表です。
- 各社が新しいモデルを出すたびに本の内容が陳腐化するため、この記事に最新の情報を更新していきます。
- 各社のモデルの主要諸元・費用に加えて、自分の印象を書いてあります。
- 性能の目安としてChatbot Arenaのスコアを参考までに添付しています
- これはあくまで参考用かつ英語での評価なので、スコアが一番高いものがいい、もしくは低いからダメというわけではありません。
- 少なくともこの記事に掲載されているモデルは、スコアが低いものでも単純な翻訳などでは十分な性能を持っています。そして何より高性能モデルとは比較にならないほど高速です。
- 用途や使用言語によって試してみて最適なものを選ぶのが良いでしょう
[PR] 宣伝
本の紹介は↓に書いてるので、モデル一覧表が参考になったなーって方は見てみてください😇
編集履歴
- '24/12/26
- OpenAI
- o1 / GPT-4o / Realtime API ごとに表を分割
- o1, gpt-4o-mini-realtime-preview 追加
-
chatgpt-4o-latestエイリアスの記述を追加 - GPT 3.5 Turbo 削除
- Anthropic
- Claude 3.5 Haiku 追加
- Claude 3 Sonnet / Haiku 削除
- Google
- Gemini 2.0 Flash 追加
- Gemini 1.0 Ultra の記載を削除
- OpenAI
- '24/10/09
- OpenAI o1-preview, o1-mini, gpt-4o-realtime-preview 追加
- Google Gemini Flash-8B 追加
- 全てのモデルの Chatbot Arena スコアを更新
- '24/08/09
- GPT-4o と Gemini 1.5 Flash の費用を更新
- 全てのモデルの Chatbot Arena スコアを更新
- Gemini 1.5 Pro が大躍進
- '24/07/24
- GPT-4o mini の Chatbot Arena スコアを更新
- '24/07/20
- GPT-4o mini を追加
- GPT-3.5 Turbo instruction を削除
- '24/07/17
- Claude 3.5 Sonnetの最大出力長変更(ベータ版)を記載
- Chatbot Arenaのスコアを更新
- Claude 3.5 Sonnet, Gemini 1.5 Flash のスコアを新たに追加
- そのほかのモデルは数値を最新化 (大きな変化なし)
- '24/06/24
- Claude 3.5 Sonnet を追加
- '24/05/24
- Google I/O 2024 で発表されたGemini 1.5 Flashやその他の価格の変更などを反映
- それに伴い、Gemini 1.0 系列は表から削除
OpenAI
歴史的経緯もあり、以下の表に掲載するもの以外にも大量のモデルがあります。一旦は最新のモデルを列挙します。
Promptがキャッシュヒットした場合は、入力の費用が半額になることに留意ください。(詳しくはOpenAIのPrompt Cachingの説明をご覧ください)
参考リンク
o1
モデル名APIでのモデル名
|
説明 | 扱えるtoken数 | 学習データ | 費用 (100万tokenあたり) | マルチモーダル対応 | Chatbot Arena Score ('24/12) |
|---|---|---|---|---|---|---|
o1o1
|
複雑な推論を行うために特別に強化学習で訓練された強力なモデル。さまざまな分野の難問に回答できる。 o1 pro というモデルもあるが2024年12月時点ではAPI経由で利用できないため、o1が最も賢いモデルである。 (回答の前に長い推論プロセスが入るため) 回答速度も遅い。また、コストも非常に高いので注意が必要。 o1-preview というベータ版も存在している APIモデル名は利用可能な最新のモデルのエイリアスとして機能する(例: 2024年12月時点では o1-2024-12-17 を指す) |
200,000 (出力は最大100,000) |
2023年10月まで | 入力: $15 出力: $60 |
画像 | ー |
o1-minio1-mini
|
o1の軽量版。コーディング、数学、科学に特に適した高速かつ比較的安価な推論モデル。 o1と違いFunction callingやマルチモーダルには対応していないので注意。 APIモデル名は利用可能な最新のモデルのエイリアスとして機能する(例: 2024年10月時点では o1-mini-2024-09-12 を指す) |
128,000 (出力は最大65,536) |
2023年10月まで |
入力: $3 出力: $12 |
ー | 1306 |
GPT-4o
モデル名APIでのモデル名
|
説明 | 扱えるtoken数 | 学習データ | 費用 (100万tokenあたり) | マルチモーダル対応 | Chatbot Arena Score ('24/12) |
|---|---|---|---|---|---|---|
GPT-4ogpt-4o
|
(高価なo1系のモデルを除くと) 最も高性能なOpenAIの旗艦モデル。画像認識機能も備える。 APIモデル名は利用可能な最新のモデルのエイリアスとして機能する(例: 2024年12月時点では gpt-4o-2024-08-06 を指す / 最新版はgpt-4o-2024-11-20なので少し差がある)ChatGPT本体で利用されているモデルを指し示すエイリアスも準備されている。WEB/APP版の回答がAPI出力とあまりにも違う場合は調べてみる価値があるとのこと。 chatgpt-4o-latest
|
128,000 (出力は最大16,384) |
2023年10月まで | 入力: $2.5 出力: $10 画像サイズに応じた追加費用あり |
画像 | 1264 (※1) |
GPT-4o minigpt-4o-mini
|
OpenAIの廉価版モデル。2024年7月時点の主要各社の廉価版モデルの中で最も安い上に高性能と言われている。 APIモデル名は利用可能な最新のモデルのエイリアスとして機能する(例: 2024年10月時点では gpt-4o-mini-2024-07-18 を指す) |
128,000 (出力は最大16,384) |
2023年10月まで | 入力: $0.15 出力: $0.6 |
画像 | 1273 |
GPT-4o Audiogpt-4o-audio-preview
|
GPT-4o Realtime と同等の音声処理が利用できるモデル。 リアルタイム処理ができないこと以外は後述のGPT-4o Realtime とほぼ同等と思われるので詳細はそちらを参照のこと。 |
128,000 (出力は最大4,096) |
2023年10月まで |
【テキスト】 入力: $5 出力: $20 【音声】 入力: $100 出力: $200 価格改訂後 ( gpt-4o-audio-preview-2024-12-17以降)入力: $40 出力: $80 |
音声 | ー |
GPT-4o-mini Audiogpt-4o-mini-audio-preview
|
GPT-4o Audioの廉価版 |
128,000 (出力は最大4,096) |
2023年10月まで |
【テキスト】 入力: $0.6 出力: $2.4 【音声】 入力: $10 出力: $20 |
音声 | ー |
- 注記
- ※1: なぜかGPT-4o-miniより低い
Realtime API
モデル名APIでのモデル名
|
説明 | 扱えるtoken数 | 学習データ | 費用 (100万tokenあたり) | マルチモーダル対応 | Chatbot Arena Score ('24/12) |
|---|---|---|---|---|---|---|
GPT-4o Realtimegpt-4o-realtime-preview
|
ChatGPTアプリの「高度な音声モード」に利用されているモデル。 WebSocketやWebRTCを介した音声およびテキスト入力に対応している。Realtime APIと分類され、他のモデルとはかなり違った扱い方が必要。 音声入出力はかなりの値段なので注意。 gpt-4o-realtime-preview-2024-12-17以降のバージョンは大幅に値下げされている。APIモデル名は利用可能な最新のモデルのエイリアスとして機能する(例: 2024年12月時点では gpt-4o-realtime-preview-2024-10-01 を指す) |
128,000 (出力は最大4,096) |
2023年10月まで |
【テキスト】 入力: $5 出力: $20 【音声】(※1) 入力: $100 出力: $200 価格改訂後 ( gpt-4o-realtime-preview-2024-12-17以降)入力: $40 出力: $80 |
音声 | ー |
GPT-4o-mini Realtimegpt-4o-mini-realtime-preview
|
GPT-4o Realtimeの廉価版 APIモデル名は利用可能な最新のモデルのエイリアスとして機能する(例: 2024年12月時点では gpt-4o-mini-realtime-preview-2024-12-17 を指す) |
128,000 (出力は最大4,096) |
2023年10月まで |
【テキスト】 入力: $0.6 出力: $2.4 【音声】 入力: $10 出力: $20 |
音声 | ー |
- 注記
- ※1: 英語だと音声入力1分あたり6セント、音声出力1分あたり24セント程度の費用とのこと。価格改定後のモデルであれば60%引き。GPT-4o-mini Realtimeなら1/10。
Anthropic
モデル名APIでのモデル名
|
説明 | 扱えるtoken数 | 学習データ | 費用 (100万tokenあたり) | マルチモーダル対応 | Chatbot Arena Score ('24/12) |
|---|---|---|---|---|---|---|
|
Claude 3.5 Sonnet ( claude-3-sonnet-20241022) |
2024年6月時点でのAnthropicの最新モデル。本来、Sonnetは廉価版モデルだが、最新バージョン3.5の旗艦モデル(Opus)がまだ公開されていないため、Claudeの中でもっとも高性能なモデルとなっている。 | 200,000 (出力は最大8,192) | 2024年4月まで | 入力: $3 出力: $15 画像サイズに応じた追加費用あり |
画像 | 1283 |
Claude 3.5 Haikuclaude-3.5-haiku-20241022
|
Anthropicのエントリー版モデル。安価かつ高速。 ただし画像入力には対応していない。(Anthropicで安価に画像を使うならClaude 3 Haikuが選択肢となるが他社のエントリー版モデルと比べると性能は一段落ちるはずなので注意) |
200,000 (出力は最大8,192) | 2024年7月まで | 入力: $0.8 出力: $4.0 画像サイズに応じた追加費用あり |
ー | 1239 |
|
Claude 3 Opus ( claude-3-opus-20240229) |
1世代前のAnthropicの旗艦モデル。 登場時はかなりの高性能で話題をさらったが、3.5系列へのアップデートがまだされていないためやや流れに取り残されている印象。 APIコストは非常に高いので注意が必要。 |
200,000 (出力は最大4,096) | 2023年8月まで | 入力: $15 出力: $75 画像サイズに応じた追加費用あり |
画像 | 1248 |
- モデル一覧: https://docs.anthropic.com/claude/docs/models-overview
- 画像の追加コスト詳細: https://docs.anthropic.com/claude/docs/vision#image-costs
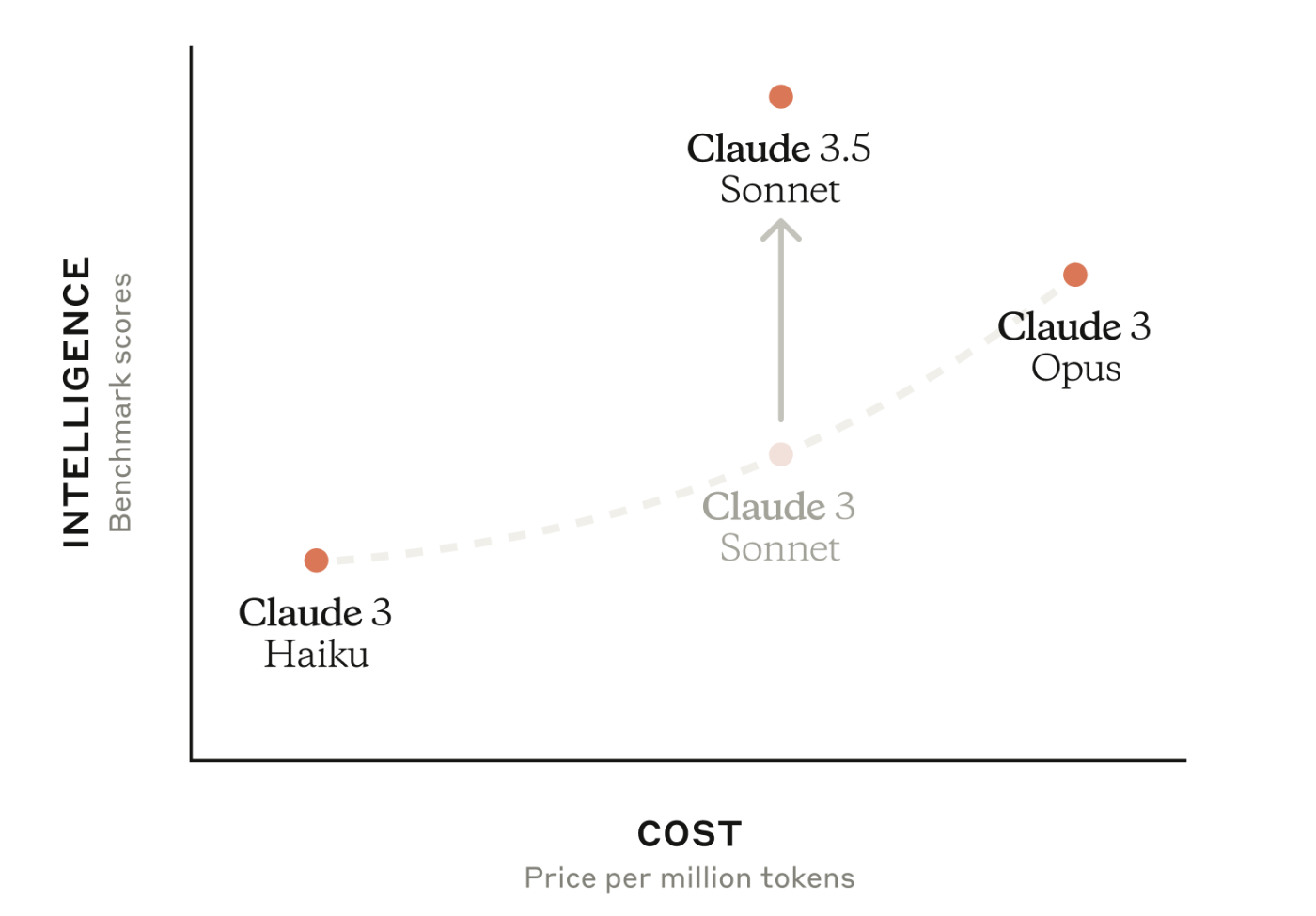
最新バージョンのClaude 3.5はOpusが公開されていないため、関係性がわかりづらいと思います。以下の図も合わせてご覧いただくと直感的で分かりやすいかと思います。
Googleのモデル
| モデル名 (APIでのモデル名) |
説明 | 扱えるトークン数 | 学習データ | 費用 (100万文字あたり) | マルチモーダル対応 | Chatbot Arena Score ('24/12) |
|---|---|---|---|---|---|---|
Gemini 2.0 Flashgemini-2.0-flash-exp(※1) |
Googleの最新モデル 軽量版に位置付けられるモデルでありながらo1に匹敵するChatArena Scoreを叩き出しているすごいモデル Multimodal Live APIとしても利用可能で、OpenAI Realtime APIのような利用も可能。 まだ実験モデルとしての位置付けのため課金されないが、Rate Limitが厳しいので要確認。 OpenAIのo1と推論強化型の gemini-2.0-flash-thinking-exp という派生モデルも実験的に提供されている。(※2) |
1,048,576 (出力は最大8,192) |
2024年8月 | Rate Limit内での利用に限り無料 (実験モデルのため) |
【入力】 画像 動画 音声 【出力】 allowlistユーザーになると音声・画像の出力もできる |
1354 |
Gemini 1.5 Progemini-1.5-pro-latest(※1) |
Googleの前世代の旗艦モデル。 マルチモーダルにも強く、2024年前半から動画および音声を処理することができていた。 Gemini 2.0 Flashが正式にリリースされるとお役御免になりそう? |
2,097,152 (出力は最大8,192) |
2024年9月 | 《12.8万トークンまで》 入力: $3.5 出力: $10.5 《12.8万トークン以上》 入力: $7 出力: $21 それぞれ画像・動画・音声に応じた追加費用あり |
画像 動画 音声 |
1304 |
Gemini 1.5 Flashgemini-1.5-flash-latest(※1) |
Googleの前世代の軽量モデル。 安価ながら、軽量版モデルとしては非常に高性能、かつ、長いコンテキストやマルチモーダルを扱えるモデルだった。 これもGemini 2.0 Flashが正式にリリースされるとお役御免になりそう? |
1,048,576 (出力は最大8,192) |
2024年9月 | 《12.8万トークンまで》 入力: $0.075 出力: $0.3 《12.8万トークン以上》 入力: $0.15 出力: $0.6 それぞれ画像・動画・音声に応じた追加費用あり |
画像 動画 音声 |
1271 |
Gemini 1.5 Flash-8Bgemini-1.5-flash-8b-latest(※1) |
Googleの前世代の超軽量版モデル。 | 1,048,576 (出力は最大8,192) |
2024年10月 | 《12.8万トークンまで》 入力: $0.0375 出力: $0.15 《12.8万トークン以上》 入力: $0.075 出力: $0.3 それぞれ画像・動画・音声に応じた追加費用あり |
画像 動画 音声 |
1209 |
(※1) 末尾の -latest は最新版を指すエイリアスとして機能します。 -latestを削除すると各モデルの安定版を指すエイリアスとなります(例: gemini-1.5-flash)。モデルの挙動を固定したい場合は詳細なバージョン番号を指定することをお勧めします(例: gemini-1.5-pro-preview-0514)
(※2) 参考: https://ai.google.dev/gemini-api/docs/thinking-mode
最新の情報は以下のページもご覧ください
FAQ
- 間違ってるところあるやんけ!
- 発見していただいてありがとうございます
- Twitterで凸していただけると泣いて喜びながら、すぐ修正させていただきます。
- 皆様の清き凸を心よりお待ちしておりますm(_ _)m
- 他にもたくさんモデルがあるやろ!なんでこの3社やねん!
- はい、その通りだと思います
- 本を書く時に作ったものを転載しているだけです…
- 随時更新するので勘弁してください
- Googleのモデルへの印象が薄い気がする。あんま使ってへんやろ!
- よく分かりましたね、そこまで手が回ってなくてあまり使い込めていません。(何度か試してはいます!)
- これからちゃんと使います…
- Chatbot Arenaって何?
- Chatbot Arenaは、ユーザーがモデルに質問し、回答を比較して投票することで、Eloレーティングシステムを用いてモデルの性能を評価するプラットフォームです。拡張性、追加性、一意な順序づけといった特性を備えており、多数のモデルを効率的にベンチマークすることができます
- 詳しくは以下をご覧ください
Discussion