【大賞】技育CAMPハッカソンがきっかけで小学校まで講演に行った話
はじめに
みなさん はじめまして
チームずんだ代表の中尾元紀と申します。今回の記事では、技育CAMPハッカソンvol11で最優秀賞を取ったことをきっかけに、私たちが小学校で講演を行うに至った経緯について、(ちょこっとだけ)技術の話も兼ねて、書き残します。これから技育CAMPハッカソンに挑戦しようと考えている方々に向けて、私たちの経験が何かの参考になれば幸いです。
どうして技育CAMPハッカソンに出たのか
私は、2023年の8月前半、大手のメーカーで研究室関連の有給インターン(TA)を経験しました。実務に携わるエンジニアの方と交流する中で、自身のIT専門用語に関する理解が乏しいことを痛感しました。大学の授業は真面目に受けていたものの、試験後は学んだことを忘れてしまうというサイクルを繰り返し、知識がしっかりと定着していないことに気づきました。また、ITに関しての知識を、分野をまたがって包括的に身につける機会もありませんでした。
そこで、私は、8月後半に基礎力を身につけるために、応用情報技術者試験についての勉強をはじめました。そして、10月8日に受験しました。応用情報技術者試験の合否が出るのは2ヶ月後 、私は8月後半から、実際に書くプログラミングの勉強をほとんどしていないことに不安を感じました。そこで、研究室の先輩から以前に聞いていた技育CAMPハッカソンに目を向け、同じ大学の工学部に所属する親しいメンバー3人を誘い、ハッカソンへのエントリーを決意しました。
技育CAMPハッカソンvol11 最優秀賞🥇
試験が終わった10月8日から、少しだけ授業で触れていたHtmlやCSS、そしてB2の頃に勉強だけはしていたJavaScriptのフレームワークであるReactをUdemyやDotinstallを使って復習し、ハッカソンのキックオフ10月27日に備えました。ハッカソンに自分が誘ったからには、良い結果を残したいという思いもあり、私が引っ張っていけるように準備を進めていました。
ハッカソンでは、自分のよく使っている技術(PytrochなどのAI関連技術)とほとんど初めて触れる技術(React)を組み合わせることで、他チームを出し抜いて、優勝できる強力なアプリケーションを開発することを目標としました。その中で、案として出てきたのが、日本初の、「ずんだもんになれるWebアプリ」、AIずんだWebでした。Web上でAI声質変換を行うことで、従来の環境構築が難解なRVCという声質変換AI技術を、誰でも簡単に環境構築無しで使えて、さらにキャッチーなキャラクターであるずんだもんの声になれるというアプリケーションを開発することにしました。
技術選定
これまで、私はハッカソンなどに出場したことはありませんでした。そこで、私の代表作になるような、良いアプリケーションを継続開発していければ良いなという考えで、大規模なアプリケーションの構築に向いているとされるReactを使ってフロントエンドを作るという方針を決めました。
しかし、真に問題だったのは、RVCをWebサービスとして、どう組み込むかでした。推論をするための自分のサーバーは持っていないし、サーバーを借りるのも敷居が高いので、AWSのSageMakerを利用して、サーバーレスの開発を行うことを決めました。RVCをローカル環境で触ったことがあるのは私一人だったし、サーバレスの開発を行ったことがあるのも私だけだったため、ほぼ一人でバックエンド側の作業をすることになってしまいました。しかしながら、私がAWSを触るのは初めてで、IAMの設定や、SageMakerの仕様、エンドポイントのデプロイ方法など、知識ゼロからの勉強でした。ここで丸3日間ほぼ寝ずに、うまくいくまで作業するという失敗を経験しました。省略しますがAPIGateWayの設定でも1日ぐらいはかかりつつ、バックエンドが完成し、サイトのフロントエンドの作業を、チームメンバーと協力しながら行いました。
発表
私は、以前からYouTube活動を行なっていたことを活かして、紹介動画を作成しました。編集は、何とかプレゼンテーションの発表当日に間に合いました。プレゼンはオンラインで、2分間行う形式でした。
発表当日、発表順が一番目で、「これは負けたな」と思いました。プレゼンでは、最初に発表することが最も不利だからです。また、2分間のプレゼンを動画で発表という、イレギュラーな発表をプレゼンの中盤〜終盤の間で行うことで、目を引く意図もあったため、私はがっかりしました。しかし、さすが、1年に何度もハッカソンの開催を行なっているサポータズ様のハッカソンというだけあって、運営に関してのノウハウが蓄積されていました。最初の発表にも関わらず、チャットやアナウンスで盛り上げていただき、ハッカソン初参加ながら、最優秀賞をいただきました。
また、このことを大学の研究室の教授に相談して、学校の広報に連絡していただいたことがきっかけで、大学のホームページの記事に取り上げられました。「月一のハッカソンで優勝しただけで、教授に連絡するほどか?」と思われるかもしれませんが、機会を活かして、活動をどんどんアピールした方が良いと私は思います。実際に、この相談をきっかけとして、私たちの活動の幅も大きく広がることになりました。
技育CAMPアドバンスvol4 大賞🏆
技育CAMPアドバンスとは、サポーターズが行なっている技育CAMPというハッカソンの中で、入賞したチームだけが参加することができる、オフラインのハッカソンです。当日は、虎ノ門ヒルズタワーのサポーターズオフィスで発表を行いました。私たちの参加したVol4では、対象6イベント、149グループ 総勢465名の中から入賞したチームの中の21グループ 57名 が参加していました。
選び抜かれたチームが作ったアプリケーションとの競争になるため、前回のハッカソンと比べると、優勝のハードルが非常に高いものとなっていました。アドバンスでは、企業様と、他のチームの審査の総合点数で、優勝チームが決まる仕組みでした。全体に向けてのプレゼンテーションだけではなく、7チームが3グループに分けられて、企業様と交流するという時間が設けられていました。当然企業様方が高い点数をつけられるようになっており、この交流時間に、どれほど注目していただけるかということも考える必要がありました。
そのため、まず、採点の項目として明示されていた「追加開発の有無」について、わかりやすい資料を作ることを心がけました。
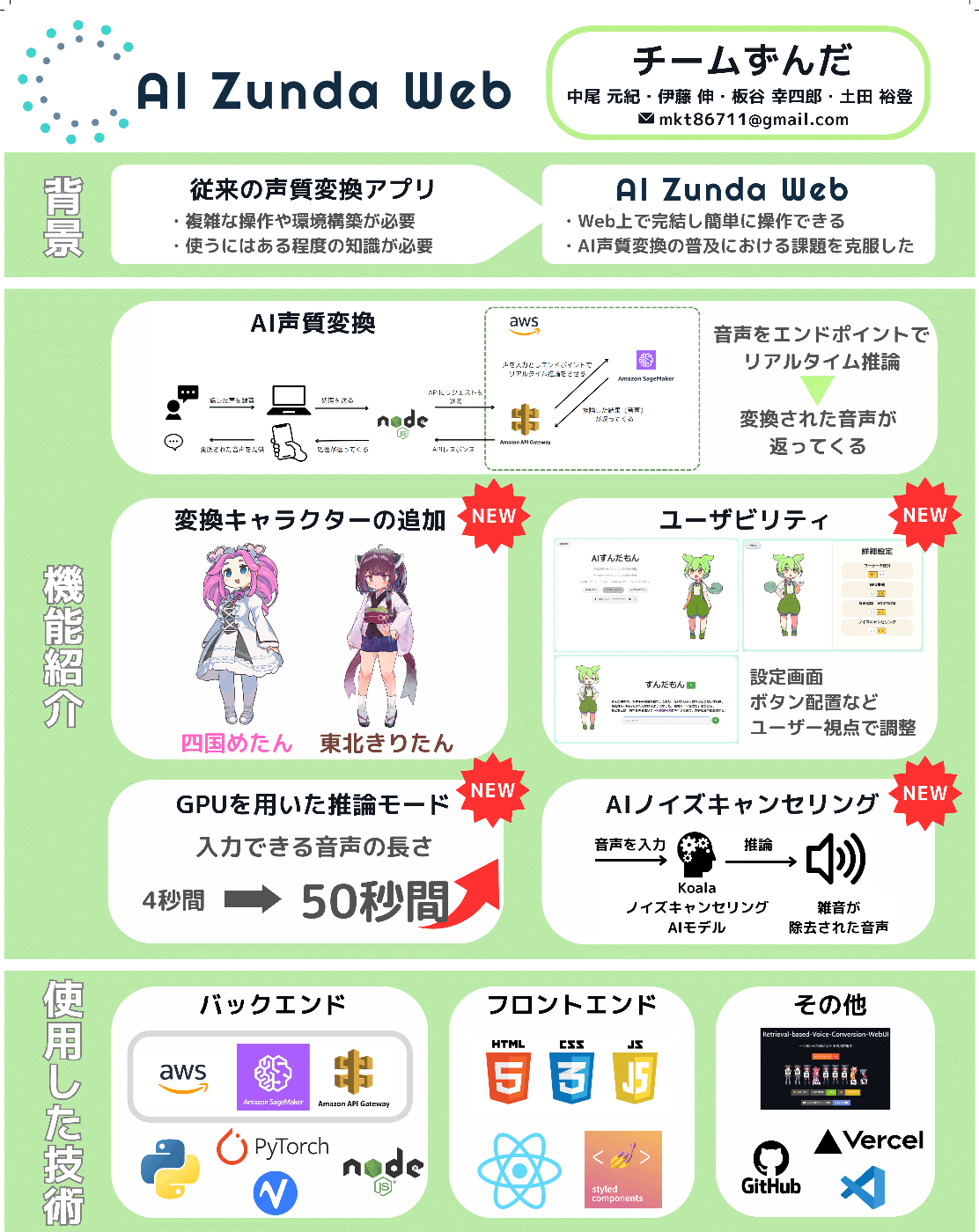
実際に会場に持ち込んだポスター
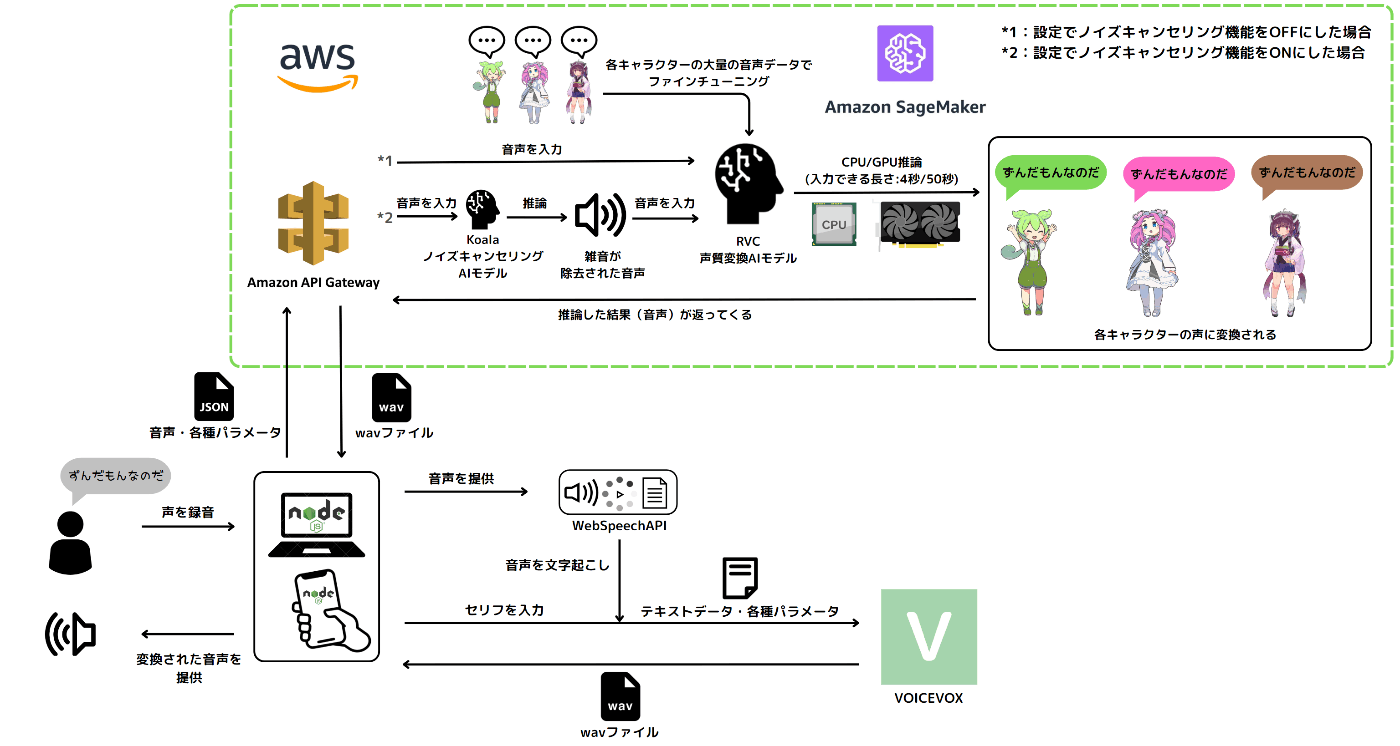
概略の構成図
プレゼンテーションの時間は前回の2分から、3分間になっていたため、一から動画を作り直し、何が進化したのかを、わかりやすくアピールしました。また、動画のクオリティも高めるために、何度もチームメンバーと相談しながら動画編集を行いました。
また、開発体制も改めました。前回のハッカソンでは私中心に作業しすぎており、アプリケーションの品質が私自身の殻を破ることはありませんでした。そこで、応用情報技術者で学んだPMについての知識を活かすことにしました。Notionを用いてWBSの作成や、担当作業の割り振りを行い、チームで効率的に開発できるように環境を整えました。

担当項目の例
このような工夫によって、私は、個人の持つ異なった得意領域が生かされて、よりよいプロダクトができる感覚をリーダーとして感じました。このような経験は、ハッカソンに参加していなければ、学生時代に得ることができなかったと思っています。当日は、企業様や、アドバンスに参加された他の学生さんたちと多く交流し、大賞を受賞することができました。

大賞受賞
技育CAMPアドバンスの後
技育CAMPアドバンスが終わった後、私は、この活動を大学の広報に連絡しました。すると、岐阜大学の学長への受賞報告を行えるという返信をいただきました。この間も、多くの方とメールでやり取りを通して日程や時間、話す内容などのすり合わせを行いました。この活動を通して、チーム外とコミュニケーションをとって活動の幅を広げていくという経験を得ました。そして、当日、中日新聞様、岐阜新聞様、エリアトピックス様の取材を受けました。
技育博2024 株式会社ディー・エヌ・エー賞🎖️
私たちは、技育博という、サポーターズ様の主催するハッカソン、それ以外のハッカソン、そして、個人で開発している作品が集まり、博覧会のように展示されるイベントにAIずんだWebを出展しました。
このイベントでは、4社の企業様方が、それぞれ3チームに企業賞を与えるという形式になっており、私たちの「AIずんだWeb」は株式会社ディー・エヌ・エー賞をいただきました。このイベントでは他の学生エンジニアさんや企業様の人事様、エンジニア様との交流に重きが置かれていて、一日で財布がいっぱいになるほどの名刺をいただきました。賞をいただいた株式会社ディー・エヌ・エーのエンジニア様に、スマートフォン上で動作する自社製の音声変換AIのプレスリリースを教えていただきました。
このプレスリリースが私に火をつけ、個人開発でAndroidスマートフォンで動作するAIずんだRoidを開発中です。まだずんだもんの声にはできていませんが、スマホで低遅延なAI音声変換を行うアプリケーションはすでに開発できました。AIずんだRoidは現在、個人開発中ですが、今後追加でメンバーを募集して開発を進め、GooglePlayストアでダウンロード数を稼げるアプリケーションにしたいなと考えています。このように今後の展望を考える上で、よい刺激を受けたイベントとなりました。
柳津小学校での講演
岐阜市立柳津小学校での講演の予定が入りました。柳津小学校では、授業の一環で、WEB版中日新聞の記事を読み、意見を交流する活動を行っています。その中で、1月25日に載っていたアプリで簡単 ボイスチェンジの記事をみて、「どんなふうにアプリを作っているのだろう」「ずんだもんは知ってたけど、岐阜大学の人もずんだもんを使ってプログラミングしているのは知らなかった」「プログラミングで他にはどんなことができるのだろう」と児童の方が興味を持たれたようです。
まず、実行委員会の児童の方から電話があり、当日にしてほしい講演の内容を伝えられました。私たちはその内容を受けて最新AIの紹介と、プログラミング体験を行えるように準備しました。具体的にはChatGPTやDALLE3、Tesla AutoPilot、Soraを紹介するスライドを作りました。AIの便利な面だけでなく、リスクを持っている点を小学生に分かりやすく伝える説明を何度もチームメンバーで熟考しました。

講演の様子
また、スクラッチを用いた、ピンポンゲームの作成という初心者には、少しハードルの高いかもしれないプログラミング体験を100人を超える小学生を前に行い、誰一人、置き去りにすることなく、正常に動作させました。これを達成するために先生にブロックの操作方法を事前に説明した資料、(ピンポンゲームの作り方 動画付き)を配布していただいたり、当日には歩き回って、困っている子に直接指導を行うなどの工夫を行いました。児童の中には、ピンポンの色を変えたり、背景を変えたり、ボールの速度を1万倍にして遊んでみたり、BGMを加えたり、ボールを増やしたりと、創意工夫をしている子がいました。私たちは、未来のエンジニアを育てるという社会的意義のある活動を行うことができたと思います。
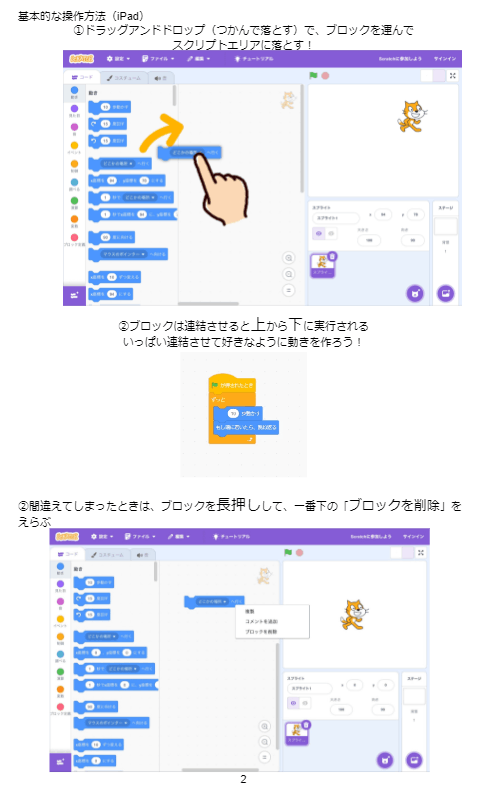
事前に配布した資料 全12ページ

スクラッチを用いたプログラミング体験の様子
また、授業の終わりにはチームずんだで制作したAIずんだWebを用いて、児童の皆さんに前に出てきてもらって実際にずんだもんの声に変換するという体験活動を行いました。これは、小学生相手に大ウケしており、楽しんでいただけたようで、こちらもやりがいを感じました。授業の終わりのアンケートでは、9割以上の好評をいただき、この講演とプログラミング体験は大成功しました。
また、この活動も、中日新聞様に取り上げていただき、記事になりました。
おわりに
ここまで読んでいただき、ありがとうございます。
私は田舎出身で、これまで外にアウトプットする活動といえば、本当にYouTubeぐらいしかなく、プログラミングに限っては、学内だけでアプリケーションを作る立場でした。この半年は、技育CAMPハッカソンを通じて、大きく成長できたと考えています。技術力はもちろん、リーダーとしてチームのマネジメントをする力が身に付き、人に何かを伝えるために分かりやすい資料を作る力、そして、チーム外とも協力して活動の幅を広くする力を身に着けることができたと思います。また、自分の作るアプリケーションについても、学外のリアルな評価をいただき、自信をつけることができました。学生エンジニアとの交流も明らかに増えました。技育プロジェクトには、文字通り人生を変えられました。サポーターズの皆様、フィードバックをいただいた企業様方、誠にありがとうございました。就職活動でもお世話になりますが、よろしくお願いいたします!
Discussion