ZigでC文字列への変換(番兵付き数列)のメモ



C言語にはヌル終端文字列(null-terminated string, zero-terminated string)があり、即ちメモリ上で文字列はどこからどこまでを表示するために、文字列の後にゼロの終了バイト0x0(多くの言語では"\0"というエスケープ文字で表す)を入れることで実現されている。このような文字列や数列の終了をマークする記号を番兵(sentinel)と言う。しかし、このようなやり方はメリットもあるが、エラーが出やすい脆さがあるため、代わりに太いポインタ(fat pointer)などで実装することが多い。しかし、C言語がプログラミング界のリングヮ・フランカである以上、API(ABI)とやり取りする際には必ず扱う必要がある。
Zigには文字列がというタイプは存在しないが、文字列リテラル(string literal、直書きの"Hello、世界"のようなもの)はUTF-8でエンコードされたヌル終端文字列[]const u8として扱われる。例えば以下のような例を観察してみると(反射で@typeOfでも確認できる)、*(const [13:0]u8)即ち読み取り専用の13長さがあるヌル終端配列へのポインタである。
// 文字列リテラルの例
const hello_world = "Hello, World!";
一般的な引数として扱われる文字列は、同様にUTF-8でエンコードされたスライス(slice、長さ付きポインタ)[]u8である。Zig言語において、配列(array)とスライス(slice)の違いは、前者の長さはコンパイル時型の一部として決まっているのに対し、スライスはランタイムに知られる。
C言語のような番兵付き列も存在していて、番兵付き配列は[_:0]のように:0で表され、番兵付きスライスも同様に[:0]で表される。このような番兵付き配列と番兵無し配列の間の変換には、以下の方法によってできる。
番兵付き→番兵無し
定数値
番兵付きから番兵無し文字列の変換は型強制(type coercion)によって自動的に行われる。例えば、以下のように自動的に変換(cast)される。
未知サイズ
番兵付きの未知サイズの配列があるとき、番兵を探してもらう必要がある。これはstd.mem.spanによって実現される。
fn fromCstring(slice: [*:0]u8) []const u8 {
return std.mem.span(slice);
}
以下のコードを実行すると、正しく変換される。この例では、既に固定された値を無理やり未知にしたが、実際の用例としては@as([*:0]u8, @ptrCast(unknown_string))を対象にすることが多いであろう。
test "Hello" {
const hello_world = "Hello, World!";
std.debug.print("hello_world = {s}\n", .{hello_world});
std.debug.print("hello_world.len: {d}\n", .{hello_world.len});
const hello_world_slice_span: []const u8 = std.mem.span(@as([*:0]u8, @constCast(hello_world)));
std.debug.print("hello_world_slice_span: {s}\n", .{hello_world_slice_span});
std.debug.print("hello_world_slice_span.len: {d}\n", .{hello_world_slice_span.len});
}
hello_world = Hello, World!
hello_world.len: 13
hello_world_slice_span: Hello, World!
hello_world_slice_span.len: 13
標準ライブラリでのstd.mem.spanの実装はstd.mem.len、std.mem.indexOfSentinelと結構複雑な実装になっているが、要は一個一個探して番兵を見つけ出すということしかやっていない。
番兵無し→番兵付き
一方、番兵無しから番兵付き文字列への変換は、いまあるメモリよりも一個多いため、ゼロで終わること保証するには、かならず元の文字列よりも大きい場所にコピーして、最後の文字をゼロにしなければならない。その方法として、スタック上とヒープ上の二種類のやり方がある。スタックはコンパイル時にサイズが固定されてしまうので、それ以上のメモリを確保することができない。一方、ヒープはメモリを動的に確保する(allocate)することができる。
スタック上で確保
スタック上は、例えば期待される最大値にを予め決めておいて、試しに確保して、失敗したらエラーを出す方法がある。
const MAX_SIZE = 256; // 最大サイズ
fn toCString(slice: []const u8) ![MAX_SIZE - 1:0]u8 {
var null_terminated_string: [MAX_SIZE - 1:0]u8 = undefined; // スタック確保
if (slice.len >= MAX_SIZE) return error.TooLong; // 長さ判断
@memcpy(null_terminated_string[0..slice.len], slice); // コピー
null_terminated_string[slice.len] = 0; // 番兵を設置
}
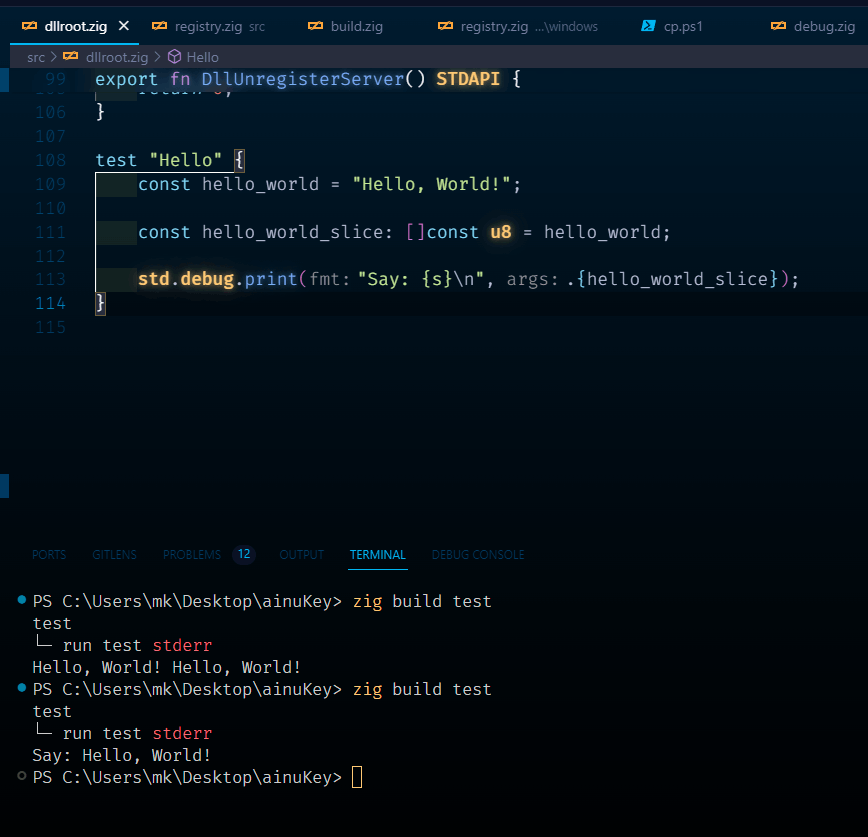
注意すべきのは、この方法だと以下のように前述のstr.mem.spanで番兵を探してもらわないと、あまりの分のゼロが大量発生してしまうことである。
test "Hello" {
const hello_world = "Hello, World!";
const hello_world_slice: []const u8 = hello_world;
std.debug.print("hello_world_slice.len: {d}\n", .{hello_world_slice.len});
const hello_world_null_terminated = try toCString(hello_world_slice);
std.debug.print("hello_world_null_terminated.len: {d}\n", .{hello_world_null_terminated.len});
const spanned: []const u8 = std.mem.span(@as([*:0]u8, @constCast(&hello_world_null_terminated)));
std.debug.print("Spanned: {s}\n", .{spanned});
std.debug.print("Say: {s}\n", .{hello_world_null_terminated_slice});
}
hello_world.len: 13
hello_world_slice = Hello, World!
hello_world_slice.len: 13
hello_world_null_terminated = Hello, World!?hello_world_null_terminated.len: 255
ヒープ上で確保
スタック上の方が求められる場合もあるが、ヒープ上で確保した方が、動的にメモリを確保できるので、ちょうどいいサイズを確保でき、メモリを超過しない限り、無限に正確に確保することができる。スタック上で確保すると同様、まずallocator.allocateで確保して、同じ番兵を設置する方法もできるが、allocator.dupeZという便利な機能が提供されている。以下のコードだけでできる。
const allocater = std.heap.page_allocator;
fn toAllocatedCString(slice: []const u8) ![*]u8 {
return try allocater.dupeZ(slice); // ヌル終端数列を要求する
}
そもそもZig内部のdupeZ()の実装は同じことをやっているだけである。
/// Copies `m` to newly allocated memory, with a null-terminated element. Caller owns the memory.
pub fn dupeZ(allocator: Allocator, comptime T: type, m: []const T) Error![:0]T {
const new_buf = try allocator.alloc(T, m.len + 1);
@memcpy(new_buf[0..m.len], m);
new_buf[m.len] = 0;
return new_buf[0..m.len :0];
}
Discussion
少し古い記事なので、状況が変わっているかもしれませんが参考にどうぞ。