はじめに
松尾研究所の梅谷です。
2025年が「AIエージェント元年」と呼ばれているように、AIが自律的にタスクを実行する時代が本格的に到来しました。
Claude Codeをはじめとして、タスクのゴールを指示するだけでAIが計画、実装を自律的に進めてくれる、さまざまなAIコーディングツールが次々と登場し、開発現場でも注目を集めています。
データサイエンスの領域でも、KaggleなどのコンペティションでAIコーディングツールの活用例が増え、人間のデータサイエンティストと同等以上の精度を達成するケースも出てきています(参考例)。
このように実用性が高まっている一方で、ツールの種類の多さゆえに、「どのAIコーディングツールを選べばいいのか分からない」「業務効率化や自動化を進めたいが、ツール選定に迷う」といった悩みを持つ開発者やデータサイエンティストも多いのではないでしょうか。
また、データサイエンス業務に本格導入するには、精度や速度だけでなく、生成コードの運用性や対応できるデータ規模も重要となり、これらは試してみないと分からないことが多いのが現状です。
そこで本稿では、Claude Code、Cline、Manus AI、Devinの4つのAIコーディングツールに対して、基本スペックの比較、すでにクローズされているKaggleコンペティションのタスクを解かせた場合の生成ファイル(コードやドキュメント)・精度の比較を通して、各ツールの実力と特徴を検証しました。
先に結論
詳細に入る前に、今回の検証を経た各ツールのポジショニングに関する結論をまとめておきます。
- Claude Code: 大規模なコードベースを丸ごとコンテキストとして理解でき、精度・実行速度・コード品質のバランスが良く、実戦投入にも十分耐えうる
- Cline: 複数モデルが選択でき最もカスタマイズが効くが、生成されるコードはスクリプト中心。既存コードベースの改善や運用など、柔軟なカスタマイズが求められる場面で強みを発揮する
- Manus AI: 扱えるデータサイズやセキュリティ面の制約が大きいため、仮想データやサンプルデータでサクッと試す用途に最適
- Devin: 生成コードの質は比較的高いが、入力データはGitHubのファイルサイズ制約を受けるため、初期の少量データでのPoCや検証向き
以降、これらの結論を得た比較検証について説明します。
選定したツール
今回は比較するツールとして、プロンプトから自律的にタスクを計画・実行できるAIコーディングツールであるClaude Code、Cline、Manus AI、Devinの4つを選定しました。
以下に各ツールの概要を簡単に紹介します。
Claude Code
2025年5月に一般提供が開始された、CLI型のコーディングアシスタント。プロジェクト全体のコードを横断的に理解しながら、複雑なタスクを自律的に実行できます。
デフォルト設定では変更前にユーザーの承認が強制されるため、“勝手に環境やコードが壊された” 事故を防げるのも特徴です。
MCP(Model Context Protocol)に対応し、GitHubやCIツールとの連携も可能です。

コードの新規作成・変更やファイルの読み込み時、逐一ユーザーに許可を取ってタスクを進めていく
Cline
2024年7月に初版がリリースされたVSCode拡張機能として動作するオープンソースのコーディングアシスタント。Plan/Actの2つのモードがあり、“Plan” で設計・方針を固めてから “Act” で実装という流れでの作業が可能です。また、変更ステップごとにスナップショットが自動保存され、各ステップに対して「Compare」で差分確認、「Restore」でタスク/コードの状態を戻すことができます。こちらもClaude Codeと同じくMCPに対応しています。
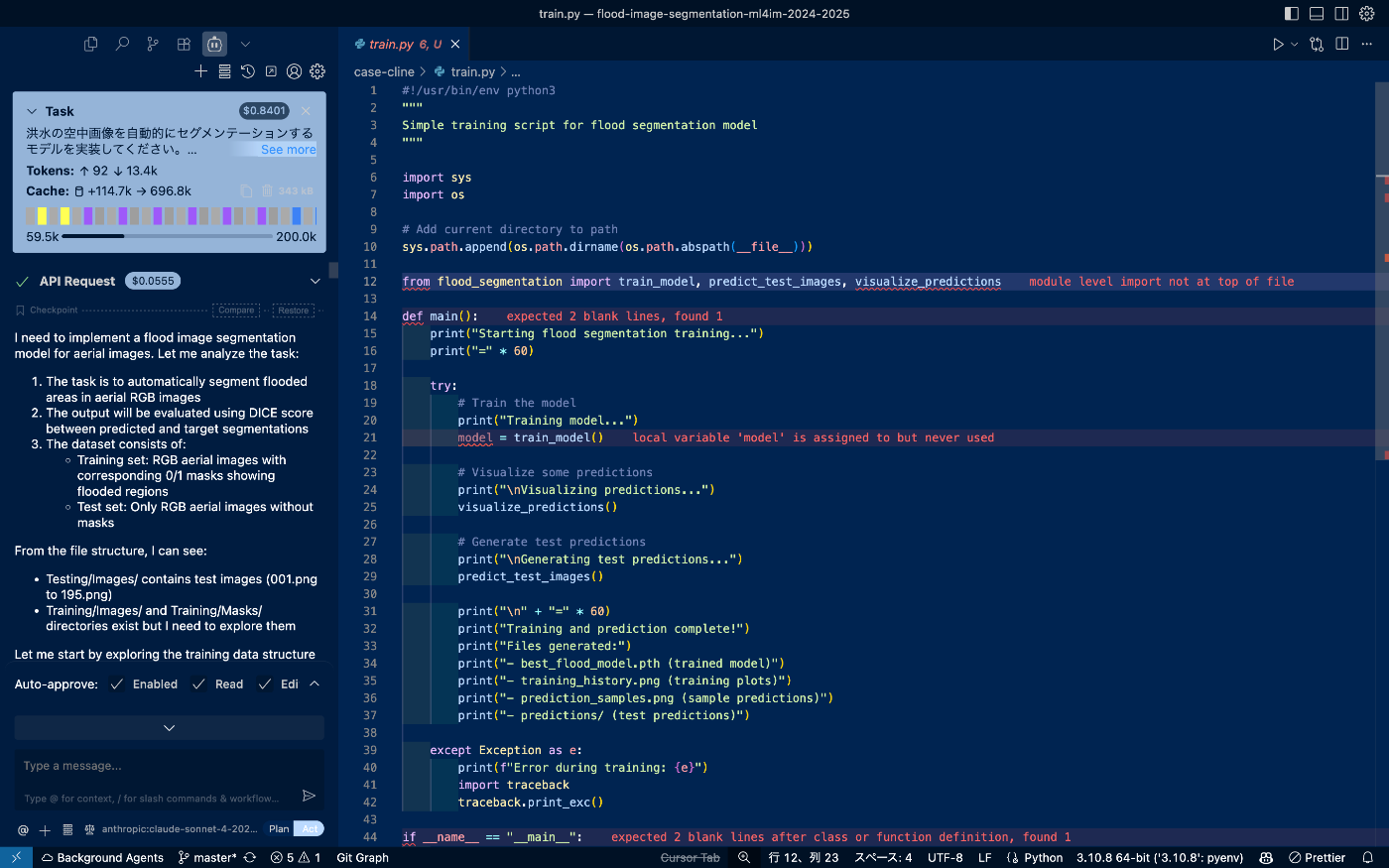
ステップごとに「Compare」「Restore」のアクションが可能で、その時点でのAPI使用料も出力してくれる
Manus AI
2025年3月に正式リリースされたマルチエージェント型のAIコーディングツール。プランナーと実行エージェントが協調して動作し、Webインターフェースから簡単に利用できます。公開ギャラリー機能により、他のユーザーの成果物を参照することも可能です。

Webアプリとしてタスクを実行。実行過程が画面に表示される
Devin
2024年12月に一般提供が開始された、「世界初の完全自律型AIソフトウェアエンジニア」。Slack、ブラウザ、VSCode拡張から操作でき、クラウド上の独自環境で自律的にコーディングを行います。リポジトリを数時間ごとにクロールし、アーキテクチャ図付き Wiki と対話型 Q&A を自動生成してくれるのも特徴的です。このWikiについては公式でMCPが用意されています。
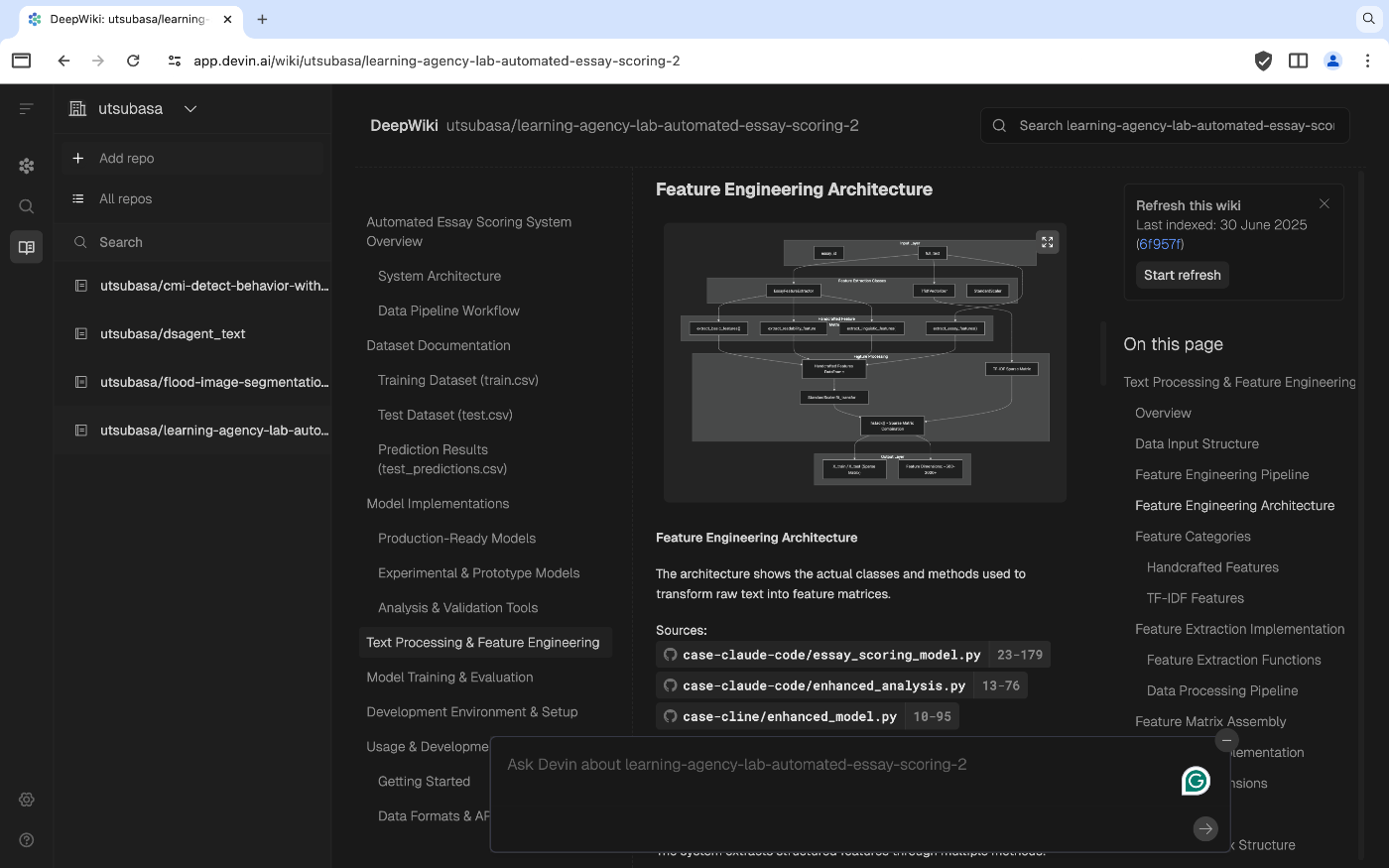
生成したコードに対しても、アーキテクチャ図等を自動で作成してくれる
各ツールの基本スペック比較
AIコーディングはそれぞれに強みや制約があります。
どのツールが自分の開発スタイルやプロジェクトに最適なのかを客観的に判断できるよう、基本スペックや機能面を一覧表で比較しました。
使用可能モデル・コスト比較
| ツール名 | 使用可能なAIモデル | コスト(2025年6月時点) |
|---|---|---|
| Claude Code | Claude(Sonnet 4, Opus 4 等)専用 | API従量課金, $20/月 (Proプラン), $100~/月 (Maxプラン) |
| Cline | Claude、DeepSeek、Gemini等(OpenRouter経由で最新モデル利用可) | 無料(各種API利用料は別途発生) |
| Manus AI | Claude、Qwen等 | 無料(Freeプラン), $19/月 (Basic), $39/月(Plus), $199/月〜(Pro) |
| Devin | "Devin Model" (独自LLM) | $20/月(Core), $500/月(Team), エンタープライズ向けプランあり |
Claude Code/Cline/Devinは利用できるモデルに差異はあるものの、1つのモデルで動作するという点では共通しています。一方、Manus AIはClaude/Qwen等のモデルを利用して複数のモデルで動作しているようです。
Claude Code/Devinは自社で開発したモデルを利用しているのに対し、Clineでは複数のモデルから任意のモデルを選択して利用できる柔軟性があり、カスタマイズ性の高さが際立っています。
動作環境・入力データ取扱比較
| ツール名 | 動作環境 | 入力データの制約 | 入力データの利用方法 |
|---|---|---|---|
| Claude Code | CLI型 | ローカル環境で動作するため、明示的なファイルのアップロード不要 | デフォルトでは学習に使用せず。サービス改善等に利用する場合あり。(利用規約) |
| Cline | VSCode拡張機能 | ローカル環境で動作するため、明示的なファイルのアップロード不要 | APIのエンドポイントを自分のサーバーに変更した場合、データの受信・保存はされない。(利用規約) |
| Manus AI | Webプラットフォーム | ファイルアップロード可だがサイズに制限あり | 入力データが第三者のAIサービスプロバイダーと共有される可能性あり。(利用規約) |
| Devin | クラウド環境 | GitHubリポジトリにアクセスして動作するため、GitHubのファイルサイズの制約を受ける | 明示的にオプトインしない限り、デフォルトでは学習に使用せず。 (利用規約) |
Claude CodeはCLIでの動作、VS Code拡張でローカル環境にあるファイルを使用でき、明示的なファイルのアップロードは不要です。
ClineはVSCode環境から使用が可能で、Claude Codeと同様にローカル環境にあるファイルを使用できます。
Manus AIはWebプラットフォームでアクセスしやすい反面、ファイルサイズ制限があるため、大量のデータを使う取り組みには向いていません。
Devinはクラウド環境でGitHubリポジトリをクローンして作業します。
したがってファイルサイズは GitHubの制限を受けるため、大規模なデータセットを扱う際には注意が必要です。(Git LFSが利用できる範囲ではサイズの大きいデータも扱えます)
なお、入力データの利用方法については、Manus AIでは第三者のAIサービスプロバイダーと共有される可能性に言及されています。機密情報を扱いたい際には使用は避けるべきでしょう。
タスク実行を通した各ツール比較手法
今回は、各ツールの素の実力や特性を評価するために、極力事前設定やカスタマイズを行わず、統一されたプロンプトを与えてKaggleコンペティションのタスクを解かせる方法で比較検証を行いました。
Claude Code、ClineともにモデルはClaude Sonnet 4を使用しました。
タスクとしては、すでにクローズされているKaggleコンペの中から、実務で頻出する3種類の処理対象(テキスト、テーブル、画像)を選定しました。
それぞれのタスクについて、目的・データセット・評価指標は以下の通りです。
-
テキストデータタスク:Learning Agency Lab - Automated Essay Scoring 2.0
- タスクの目的: 学生のエッセイを自動で採点するモデルの開発
- データセット: 米国の中高生が執筆したエッセイと、そのエッセイに対する人手によるスコアや基本的な属性情報(性別・人種など)。学習データのサイズは数十MB。
- サブミット時の評価指標:二次重み付きカッパ係数
-
テーブルデータタスク:American Express - Default Prediction
- タスクの目的: クレジットカード顧客の債務不履行(デフォルト)予測
- データセット: 時系列行動データと匿名化された顧客プロファイル情報。学習データのサイズは数十GB。
- サブミット時の評価指標:「正規化ジニ係数」と「4%でのデフォルト率捕捉率」の平均
-
画像データタスク:Flood Image Segmentation
- タスクの目的: 航空写真から洪水領域を自動的にセグメント化するモデルの開発
- データセット: 洪水の航空写真とそのセグメンテーションマスク。学習データのサイズは数GB。
- サブミット時の評価指標:DICE係数
各タスクに対して、コンペの説明文をもとにそれぞれプロンプトを定義し、すべてのツールでなるべく同内容となるように入力しました。
実際に使用したプロンプトは以下の通りです。
1. テキストデータタスクのプロンプト
train.csv には、トレーニングデータとして使用するエッセイとスコアが含まれており、test.csv にはテストデータとして使用するエッセイが含まれています。
これらのファイルを使用して、生徒のエッセイを採点できる最も正確なモデルをトレーニングし、Kaggleにサブミットしてください。
2. テーブルデータタスクのプロンプト
信用不履行を予測します。
具体的には、産業規模のデータセットを活用し、本番環境の既存モデルに対抗する機械学習モデルを構築します。
トレーニング、検証、テスト用のデータセットには、時系列行動データと匿名化された顧客プロファイル情報が含まれます。
特徴量の作成から、モデル内でより有機的なデータ活用まで、あらゆる手法を自由に駆使して、最も強力なモデルを構築し、Kaggleにサブミットしてください。
3. 画像データタスクのプロンプト
洪水の空中画像を自動的にセグメンテーションするモデルを実装してください。
アウトプットは予測セグメンテーションとターゲットセグメンテーション間の DICE スコアに基づいて評価されます。
データセットは、浸水地域のRGB航空写真で構成されています。
トレーニングセットでは、それぞれの画像に対応する0/1マスクが付与されており、航空写真全体の中で浸水した領域がセグメント化されていることを示しています。
テストデータセットでは、航空写真のみが含まれ、対応するマスクは付与されていません。
今回はMCPを使用したWeb操作やKaggle APIトークン発行はしないため、実際にKaggleへサブミットすることはできません。
しかし、各ツールがどこまでやってくれるのかを検証する目的で、テキスト・テーブルタスクのプロンプトには「Kaggleにサブミットしてください」と明記しました。
また、各ツールが作成した成果物を人間がどの程度引き継ぎやすいかを確認する一環として、成果物に対するレポートが自動生成されないClaude Codeでは、タスク完了後に「検証結果に関するレポートを作成してください」と追加でプロンプトを入力し、レポートの作成も行いました。
これらのプロンプトを用いて各ツールにタスクを実行させ、
- 検証精度(評価指標スコア)
- 実行時間
- タスク実行にかかったコスト
- 採用手法の概要
という4つの観点から結果を比較・評価しました。
タスク実行結果比較
各ツールで生成されたファイルはタスクごとに以下のGitHubリポジトリにアップロードしています。生成されたコード等も確認できるため、気になる方はご覧ください。
以下では、タスクごとの結果をまとめていきます。
テキストデータタスク結果
| ツール | RMSE | 実行時間 | コスト | 手法の概要 |
|---|---|---|---|---|
| Claude Code | 0.6260 | 約15分 | ~$20(proプランで実行) | TF-IDF + リッジ回帰、5-fold cross-validationで精度検証 |
| Cline | 0.7378 | 約16分 | 約60円(45kトークン) | TF-IDF + リッジ回帰、3-fold cross-validationで精度検証 |
| Manus AI | 0.6173 | 約8分 | 無料枠内で完了(約200クレジット) | TF-IDF + リッジ回帰、8:2でtrain: validに分割して精度検証 |
| Devin | 0.6785 | 約14分 | 約338円(1.0ACU) | TF-IDF + アンサンブル(RF、XGBoost、リッジ)、5-fold cross-validationで精度検証 |
評価指標をプロンプトに入れていなかったこともあり、精度はどのツールもRMSEで算出していました。
このタスクではManus AIが最も高い精度を達成し、コストパフォーマンスでも優れた結果を示しました。他のツールが5 or 3-fold cross-validationを行う中、Manus AIは8:2での分割で精度検証を行い、実行時間も短いです。検証レポートも他のツールが英語で書いている中で唯一、日本語で書いてくれていました。
Clineは、唯一Kaggleへのサブミッション用のpythonファイルとMarkdownファイルを用意してくれました。
Devinは唯一アンサンブルモデルを使用しましたが、精度はManus AIに劣る結果となりました。
ただ、Devinはタスク実行中にXGBoost単体での学習も行っており、RMSEは0.6148で、Manus AIよりも高い精度を達成しています。このことから、Devinが選んだ最終モデル構成が適切でなかっただけであるとも考えられます。
もう1つ特筆すべき点は、DevinはGitHubへのプルリクエストまで作成してくれていたことで、これは他のツールにはない特徴でした。
テーブルデータタスク結果
| ツール | AUC | 実行時間 | コスト | 手法の概要 |
|---|---|---|---|---|
| Claude Code | 0.9554 | 約22分 | ~$20(proプランで実行) | LightGBM、5-fold cross-validationで精度検証 |
| Cline | 0.9484 | 約46分 | 約246円(22kトークン) | LightGBM、3-fold cross-validationで精度検証 |
| Manus AI | - | - | - | ファイルサイズ制限により実行不可 |
| Devin | - | - | - | ファイルサイズ制限により実行不可 |
こちらのタスクでも、評価指標はプロンプトに入れていなかったので、サブミット時とは異なりAUCを使って評価をしています。
Claude Codeが最も高いAUCを達成し、実行時間も短い結果となりました。手法にはClaude CodeとClineでほとんど違いがありません。
このタスクでは、Claude CodeとClineがKaggleへのサブミッション用のpythonファイルを用意してくれており、検証レポートも日本語で書いてくれました。
このタスクでは、残念ながらManus AIとDevinはファイルサイズ制限により実行できませんでした。
画像データタスク結果
| ツール | DICE | 実行時間 | コスト | 手法の概要 |
|---|---|---|---|---|
| Claude Code | 0.6402 (GPU) | 約20分 | ~$20(proプランで実行) | U-NetをBCE + Dice loss (α=0.5)で学習実行、8:2でtrain: validに分割して精度検証 |
| Cline | - | 約9分 | 約90円(13kトークン) | U-NetをBCE + Dice loss (α=0.5)での学習コード、8:2でtrain:validに分割して精度検証するコードを生成 |
| Manus AI | - | - | - | ファイルサイズ制限により実行不可 |
| Devin | - | 約31分 | 約607円(1.8ACU) | U-NetをBCEWithLogitsLossで学習コード、8:2でtrain:validに分割して精度検証するコードを生成 |
このタスクでは評価指標をプロンプトに入れたため、サブミット時と同じくDICE係数で評価をしています。
また、「実装してください」というプロンプトに従い、基本的に学習・推論コードを用意するところまでで完了するケースが多くなりました。
一方、Claude CodeはGoogle Colabを通じてターミナルで動作しGPUを利用できたため、他のツールと異なり実際に学習まで実行できました。
ただし、Colab無料版の制限により使用可能なGPUはT4のみで、学習時間も限られたため、Claude Codeではepoch数を短く設定して学習を終えていましたので、精度は限定的な結果となっています。
本格的な学習には、Colab の有料プランの活用やローカルでの GPU 環境構築が有効だと考えられます。
このタスクでも、Manus AIはファイルサイズ制限により実行ができませんでした。
これまでの検証を経た各ツールのポジショニングの考察
各ツールの最適なユースケース
今回のデータサイエンスのタスクにおける比較実験から、各AIコーディングツールを以下のように、「カスタマイズ性」と「実務適用性」の2軸で整理しました。

横軸は「実務適用性の高さ」を示し、タスク実行時の精度・入力データの制約・生成コードの質などを総合的に評価しています。
縦軸は「カスタマイズ性の高さ」を示し、利用できるモデルの種類や設定の柔軟性、ユーザーがどこまで細かく制御できるかを基準にしています。
この観点で各ツールを整理すると、
- Claude Code は、カスタマイズ性はClineほどではないものの、大規模なコードベースを丸ごとコンテキストとして理解でき、精度・実行速度・コード品質のバランスが良く、実戦投入にも十分耐えうるツールです。
- Cline は、複数モデルが選択でき最もカスタマイズが効きますが、生成されるコードはスクリプト中心で初級者レベルです。既存コードベースの改善や運用など、柔軟なカスタマイズが求められる場面で強みを発揮します。
- Manus AI は、扱えるデータサイズやセキュリティ面の制約が大きいため、仮想データやサンプルデータでサクッと試す用途に最適です。
- Devin は、カスタマイズ性はmanusより高く、生成コードの質も中級〜上級者レベルですが、入力データはGitHubのファイルサイズ制約を受けるため、初期の少量データでのPoCや検証に向いています。
検証結果を踏まえたツール全体の考察
今回の検証結果をもとに、Kaggleコンペティションにおける人間のデータサイエンティストとツール全体でのアウトプットを比較すると、以下のようにまとめられそうです。
- 精度面:シンプルなタスクでは人間の中級者レベルに到達可能。
- 速度面:基本的なモデル構築は人間よりも高速で可能(16-18分 vs 数時間)。
- 創造性:複雑な特徴量エンジニアリングや新規手法の適用は人間がまだ優位に立っている。
データサイエンスのタスクにおいても、AIに人間が期待するようなアウトプットを生成させるには、適切なコンテキストの入力が欠かせません。
たとえば、使用する手法や評価指標を明示的にプロンプトに含めたり、MCPを活用して関連情報をWebから取得可能にすることで、精度や創造性の向上が期待できます。
まとめ
AIコーディングツールは、それぞれ異なる強みと制約を持っており、タスクの性質、データサイズ、セキュリティ要件、予算に応じて適切なツールを選択することが重要です。
今回の検証では、各ツールともに共通して基本的なモデル構築やデータ処理は高速で行えるものの、ユースケースによってフィットするツールは異なることが分かりました。
これらのツールは、今後も急速に進化していくことが予想されます。
開発者は各ツールの特性を理解し、プロジェクトに最適なツールを選択することで、開発の生産性を大幅に向上させることができるでしょう。

Discussion