こんにちは、松尾研究所の奥村です。
LLMの性能向上により、従来のNLPタスクだけではなく、より複雑な推論が求められるタスクでの活用が注目されています。特にゲームプレイは、画面の理解や記憶、複雑な意思決定などが要求されるため、LLMの能力を総合的に評価する有効な手段として期待されています。
今回はLLMをゲームで評価するLMGame-Benchというベンチマークについて紹介します。
公式サイト:
論文:
LMGame-Bench概要
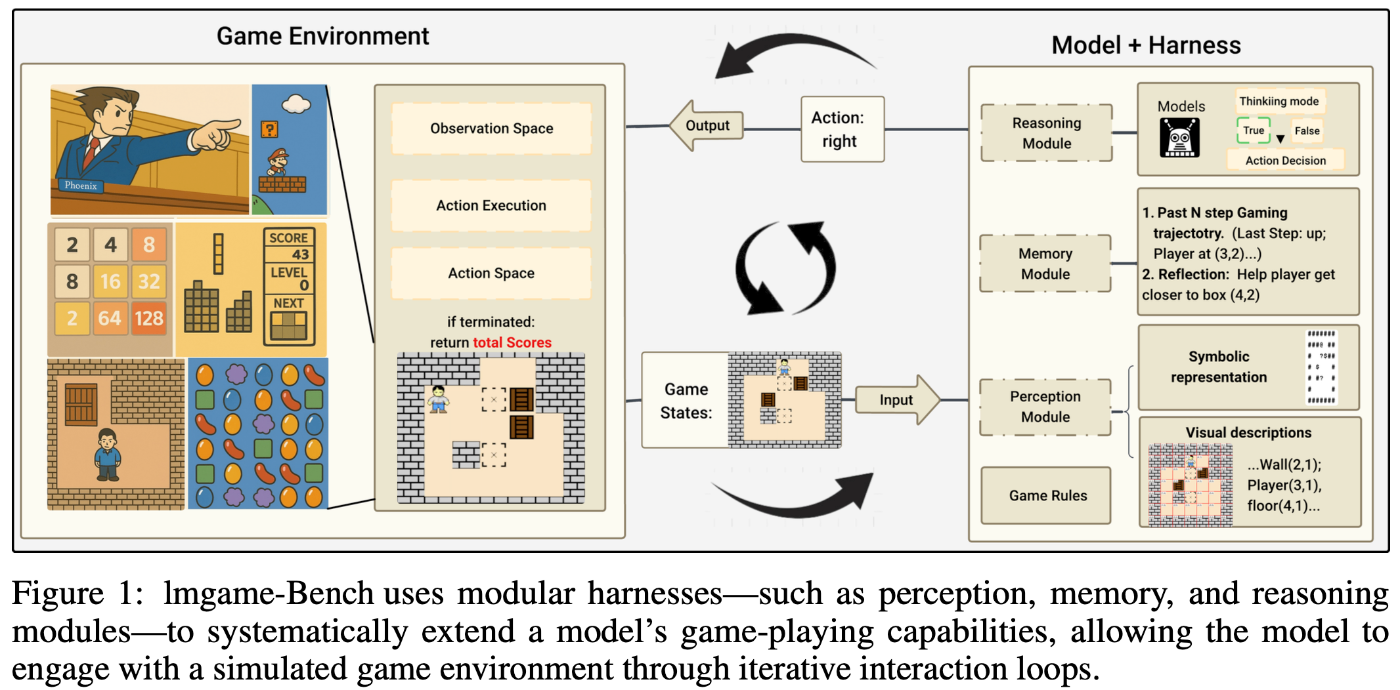
ゲーム画面のみから直接行動を決定して評価するのではなく、行動決定を補助するモジュール(harness)をくっつけて評価するのが特徴的です。以下の3つがharnessとして採用されています。各モジュールでの推論は同一のLLM/VLMで行われます。
- Perception modules
- グリッドベースのゲームでは、ゲーム画面をもとにオブジェクトやプレイヤーの位置をテキストで出力する
- ノベル形式のゲームでは、ゲーム画面から会話部分のみを抽出する
- Memory modules
- 過去Nステップの行動を記憶しておく
- 前ステップの行動結果の成否を判定する
- Reasoning modules
- Perception modulesやMemory modulesの結果をもとに、次ステップの行動をreasoningありで推論する
ゲームのスクリーンショットのみを入力として直接行動を推論させる方法だと、現状のVLMではパフォーマンスが出ないことが知られています。ゲームによっては、ランダム推論とほぼ同じパフォーマンスしか出ないこともあるようです。論文中では以下のように述べられています。
At first glance, evaluating LLM agents on games appears straightforward, by simply sending game screenshots to vision-language models (VLMs) to generate the next actions. However, directly placing a model in gaming environments can result in low performance, often close to that of random action-taking baselines.
行動決定の際にharnessをつける試みは他のゲームAIでも行われています。
- CRADLEというフレームワークでは、1回の行動決定を複数のステップに分割しています。Information gatheringで画面内の情報をテキストに変換し、Self reflectionで前ステップの行動を振り返る、といった具合です。
- ClaudePlaysPokemonのスターターコードを確認すると、キャラクターやオブジェクトの位置情報はソフトウェアのROMの情報を利用していることが分かります(参考)。
(参考)CRADLEのプレイ動画:
対象ゲーム
2048、Sokoban、Tetris、Candy Crush、マリオ、逆転裁判の6つが対象になっています。Sokoban(倉庫番)について補足します。
Sokobanは、
- 荷物を特定の場所に運ぶパズルゲーム
- 荷物は引くことはできず、押すことのみ
- 壁際に荷物を追いやってしまい、簡単に詰み(deadlock)の状況が発生する
のようなゲームです。
実際のゲーム画面は以下のようになっています。

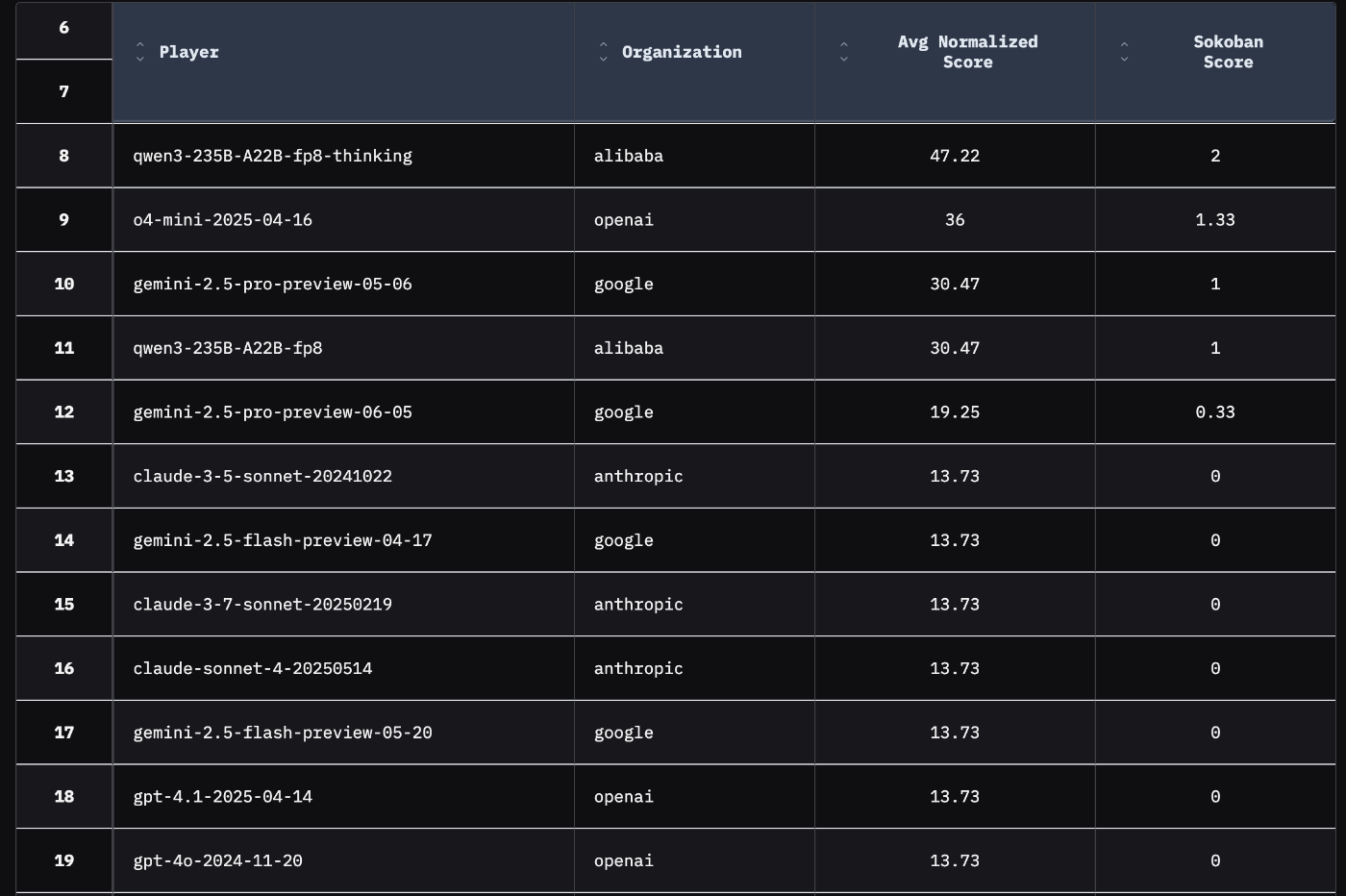
Harnessありで評価されたリーダーボードが公開されていますが、Sokobanはreasoningなしのモデルだとほぼクリアできないようです。スコアはクリアした盤面数になっています。
動かしてみた
gpt-5-thinking-highがSokobanで最も良いスコアを出しており、挙動が気になったので実際に動かしてみました。
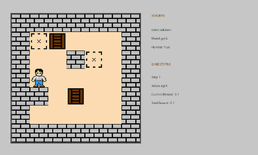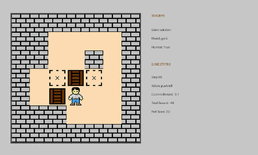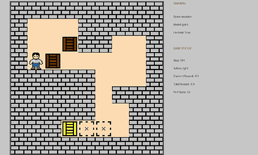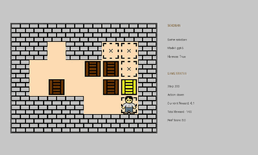
一部無駄な動きが見えますが、詰まずにクリアできています。
まとめ
LLMをゲームプレイで評価するLMGame-Benchを紹介しました。他にもベンチマークは公開されており(V-MAGE、BALROG)、KaggleではGame Arenaが発表されるなど、最近になって評価まわりが整備されてきた印象があります。ゲームプレイにおいては、現状のLLMだと推論が非常に遅かったり、思ったように動いてくれないなど、もどかしさを感じる部分が多いです。今後どう発展するのかを楽しみにしつつ、継続的に技術動向は追っていきたいと思います。

Discussion