株式会社松尾研究所の奥村です。本記事は、松尾研究所 Advent Calendar 2024の記事です。
簡単に私の自己紹介をします。
前職は医療機器メーカーで、10月から松尾研究所で働いています。AIエンジニアとして様々なプロジェクトのデータ分析、AI開発を担当しています。データサイエンティスト系の職種は、PMからエンジニアまで広く募集中です!
Kaggle competitions masterということで最近インタビュー記事を執筆いただきましたので、興味ある方はご覧ください。[1]
数学の4択問題に対して、誤答が生徒のどのような誤解によって引き起こされているかを対応付けるEedi - Mining Misconceptions in Mathematicsというコンペが12/13まで開催されていました。
本記事ではコンペ概要と上位解法についてまとめます。私自身LLM関係のコンペに出るのは初めてだったので、多くの学びがありました。
コンペ概要
例えば以下のような問題が与えられます。

この問題の正解は23ですが、生徒が13を選んだ場合にどのような誤解が背景にあるかを考えてみます。四則演算の優先順位に従わず、単純に左から右へと演算を行った場合に結果が13になります。そのため、このケースで対応付けるべき誤解はCarries out operations from left to right regardless of priority order.となります。このように、問題と誤答のセットから背景にある誤解を予測するというお題でした。
評価指標はmAP@25です。
ホストから提供された誤解のリストは2587件ありましたが、そのうちの48%が学習データに登場しない[2]という点が特徴的でした。
上位解法
パイプライン
コンペ概要で述べたように誤解の多くは学習データに存在しないため、通常のクラス分類では解けません。上位者の多くはRetrieval + Rerankingの2stageで解いていました。この手法は文書検索でよく使われており、こちら[3]の説明がわかりやすいと思います。
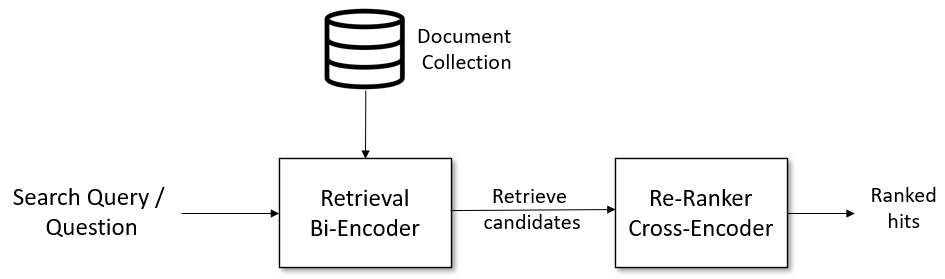
Retrieval
Retrieval部分で使われたモデルを以下に示します。
-
dunzhang/stella_en_400M_v5(5th) -
intfloat/e5-mistral-7b-instruct,BAAI/bge-en-icl(1st) -
Qwen/Qwen2.5-14B(8th, 9th, 12th) -
Salesforce/SFR-Embedding-2_R(7th, 26th)
Salesforce/SFR-Embedding-2_Rはテキスト埋め込みのベンチマークであるmteb leaderboard[4]で優秀な性能を叩き出しているモデルです。私も色々埋め込みモデルのzero-shot性能を測っていましたが、こちらのモデルは確かに性能が良かったです。
一方でQwen/Qwen2.5-14Bは埋め込みモデルではありませんが、多くのチームで使われています。fine-tuningすれば埋め込みモデルと遜色ない性能が出るのは面白いと思いました。そのくらいQwenの出力が高品質ということなのかもしれません。
BERT系の埋め込みモデルでは[cls] tokenやmean poolingが使われていた印象ですが、LLMを使う場合は基本的に最後のtokenのembeddingを使うようです。[5]
埋め込みモデルでのretrievalは「質問文+誤答+α」と「誤解」のembeddingのsimilarityをもとに行いますが、一部のチームで用いられた工夫として誤答の理由を事前に推論しておき、後段の推論で活用する(5th, 7th, 9th)というものがあります。この工夫を取り入れることでCVで+0.04ほどの改善が確認されたそうです(5th)。7thチームはImproving Passage Retrieval with Zero-Shot Question Generation[6]という論文に触発されたと述べています。
Reranking
Reranking部分はチーム間でアプローチが異なり、大きく差がついた部分なのだと思います。
モデル
Rerankerの方が重いモデルが使われる傾向にありました。細かいバージョンの違い(instruction tuningの有無、量子化など)はあれど、ほとんどの上位者全員が32B以上のQwen2.5を使用していました。
PointwiseとListwise
上位者の中でもpointwiseかlistwiseな推論を行うかで分かれていました。pointwiseとlistwiseの差はこのコンペで言えば、
- pointwise: 質問文+誤答と1つの誤解に対して推論。Retrieveされた誤解の数だけ推論する
- listwise: 質問文+誤答と複数の誤解をまとめて推論。1回の推論で複数の誤解のlogitsを得る
のようなイメージです。
pointwiseの方は従来から用いられている手法の印象で、簡単に言えばSequence Classificationをするだけなので実装が単純です。ただしCausalLMを用いる場合は出力がYes/Noとなるようにpromptに仕込んだうえで、最終出力となるYes/Noのlogitsをもとにrerankingをします。この方法はatmaCup#17の1stでも用いられていました[7]。
一方でlistwiseの方は
…
You must choose the misconception from the following options:
1. {top1 candidate}
…
e. {top40 candidate}
のようにpromptにretrievalで得られた結果を仕込み、candidateに対応する英数字のlogitsをもとにrerankingするというものです。この方法が広く使われているのかは分かりませんが、kagglerらしい解法だと思いました。
Synthetic Data
コンペ概要で述べたように未知の誤解が約半数を占めていたり、学習データでは誤答に対する誤解がNullになっているものがありました。上位チームのほとんどはこの問題に対して何かしらの対応を取っていました。対応の例としては、
- 誤解が
Nullのレコードに対して、LLMで推論して穴埋めする - 学習データに登場しない誤解を含む質問文を生成する
などがありました。使われたモデルはgemini-1.5-pro、Claude 3.5 Sonnet、GPT4o-mini、gemma 27B、Qwen2.5 32Bなど、チームによって様々でした。
まとめ
Kaggleで開催されたEedi - Mining Misconceptions in Mathematicsというコンペの概要と上位解法について紹介しました。現在はほぼ必須とも言えるLLMまわりの技術を身につけることができ、個人的には技術的な収穫があるコンペになりました。興味を持っていただけた方はLate submissionで検証してみるのはいかがでしょうか。私は推論の高速化まわりで妥協して重いモデルが動かせなかったので、これを機に勉強しようと思います。
明日の松尾研究所 Advent Calendar 2024は、清水さんの「arXivからトレンドの変化を追ってみた」です。
-
https://www.kaggle.com/competitions/eedi-mining-misconceptions-in-mathematics/discussion/533870 ↩︎
-
https://sbert.net/examples/applications/retrieve_rerank/README.html ↩︎
-
https://huggingface.co/Salesforce/SFR-Embedding-2_R#how-to-run ↩︎
-
https://www.guruguru.science/competitions/24/discussions/21027ff1-2074-4e21-a249-b2d4170bd516/ ↩︎

Discussion