
はじめに
はじめまして、株式会社松尾研究所インターンのEiger-3970と申します。
インターンではIoT×GenAIの分野に特化したチームで、ユースケース探索やプロトタイピングを行っています。
大規模言語モデル(LLM)の進歩が目覚ましい昨今ですが、LLMの医療分野への応用にも注目が集まっており、毎日様々な研究論文が投稿されています。
今回は、私が共著者として参加[1]した研究から、「GPT-4と医師の診断・トリアージ精度の比較研究」の論文をご紹介します。
研究の背景
前述のように近年のAI性能の進歩は恐ろしく早く、もしかすると近い将来、医師の仕事は病気の診断からその治療に至るまでのほとんどを、診療補助医療AIにアシストされながら行うような未来が来るのかも知れません。
しかしながら、医療分野においては不正確な情報が患者の健康に悪影響を及ぼす可能性があるため、AIから出力される情報の正確性には特に注意を払う必要があります。
また、LLMはインターネット上のテキストデータを主な情報ソースとして学習を行っているため、人種および民族的なバイアスのかかった出力がなされる可能性を指摘されています。
したがって今回の研究では、既存のLLMの中でも特に巨大かつ高性能とされているモデルであるGPT-4と、3人の専門医資格を有する医師との間で、45例の典型的な臨床事例を使用して診断およびトリアージ[2]の正確性を比較しました。
また、患者の人種と民族性(黒人、白人、アジア人、ヒスパニック)の情報を臨床事例に追加し、GPT-4の診断およびトリアージの正確性が人種間で異なるか否かを検証しました。
GPT-4 vs 医師の診断・トリアージ精度比較の結果
GPT-4の診断・トリアージ精度は専門医と比較しても遜色がない
今回の研究では、GPT-4と専門医資格を有する医師(3名)に45種類の典型的な臨床事例を情報として与え、それに対する診断とトリアージの精度を定量化しています。

GPT-4による診断の一例
- 入力するプロンプト文
以下の症例に対して、最も考えられる診断名とその理由を示してください。
『14歳の少年が吐き気、嘔吐、下痢で受診。18時間前、彼はピクニックに行き、そこで加熱不十分な鶏肉と他の様々な食品を摂取していた。1日に6回、中程度の量の、血便でない便が出るという。軽度の腹痛と微熱がある。急性期病院を受診したところ、軽度の頻脈(心拍数105bpm)、血圧正常、微熱100.1(°F)であった。』
- 出力結果
『この少年の症状(吐き気、嘔吐、下痢、軽度の腹痛、低度の発熱)と、発症の18時間前にピクニックで未加熱の鶏肉を摂取したという病歴は、細菌性胃腸炎、特にサルモネラによる食中毒を強く示唆しています』
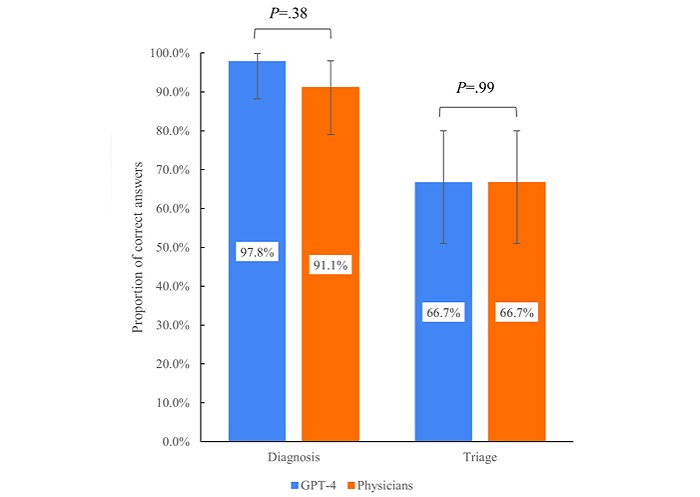
GPT-4は診断性能において97.8%(44/45)の割合で正確な回答を出力し、医師は91.1%の割合(41/45)で正確な回答をしました。
また、臨床情報の緊急度を①緊急、②緊急ではないが病院へ行くのが妥当、③非緊急 (病院へ行く必要なし)の3段階に分類するトリアージの正確性において、GPT-4は66.7%(30/45)、医師も66.7%(30/45)の割合で正確な回答を出力しました。
以下の図は、GPT-4と専門医の正答率を比較した結果を示したもので、両者の間に有意差は認められませんでした。
GPT-4の診断・トリアージでは人種・民族的な情報によるバイアスは見られなかった
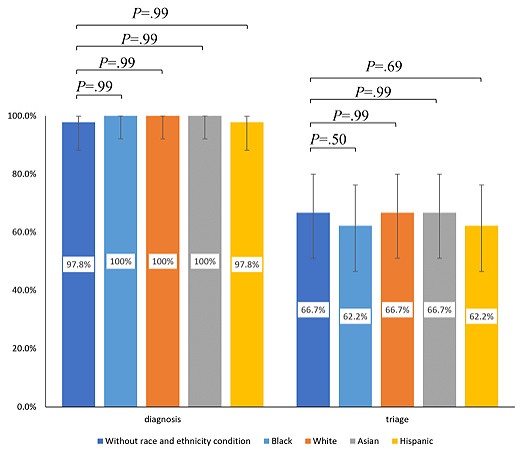
上の解析に加えて、GPT-4に入力する典型的な臨床事例について、患者の人種・民族に関する情報として白人、黒人、アジア人、ヒスパニックのいずれかの情報を追加したうえで更なる解析を行いました。
以下の図は、患者の人種・民族に関する情報を与えた群、白人、黒人、アジア人、ヒスパニックのいずれかの情報を与えた群の間での正答率を比較した結果を示したものです。
今回の研究では、いずれの群間も有意確率 > 0.05となっており、GPT-4が人種・民族的バイアスにより受ける診断・トリアージの精度への影響は検出されませんでした。
まとめ
典型的な臨床事例を用いて臨床診断・トリアージにおけるGPT-4の精度を評価した、今回の研究から示唆されたこととしては以下の通りです。
- 典型的な臨床事例に対する臨床診断・トリアージの精度は専門医資格を有する医師と比べて遜色がない可能性がある
- GPT-4の臨床診断・トリアージの出力は人種・民族的バイアスに対して影響を受けにくい可能性がある
本研究論文の成果については、査読付きのオープンアクセスジャーナルである『JMIR Medical Education』にて2023年11月2日に掲載されています。詳細な情報を参照したい方は、ぜひ原文の方に目を通して頂けると幸いです。
研究ウラ話
この研究プロジェクトは、OpenAI社が2022年11月にChatGPT(当時のモデルはGPT-3.5)をリリースしてから程なくして立ち上がりました。もちろんその当時、世の中にはChatGPTを用いた会話型AIと医師の診断精度を比較するような論文は存在しておらず、もしかしたら世界で一番早くこのジャンルでの論文を出せるかも知れないと、淡い期待を抱きながら執筆を進めていました。
しかし、2023年の新年が開けた頃にはこのジャンルでの第一報の論文が発表され、あれよあれよという間に続々と同様の研究が発表されていきました。そしてさらには、書き上げた論文の査読中にChatGPTのモデルがGPT-4へとバージョンアップされ、GPT-4を使ってイチからすべて実験をやり直すことになりました…(笑)
そんなこんなで、本論文を発表するにあたっては激動の数ヶ月を過ごすことになったのですが、AI技術の進歩のスピードの速さに加えて、その時代で特にホットな分野の研究における競争の激しさを身を以て体感することが出来ました。当時は大変でしたが、振り返ればきっと貴重な経験ができたのかなと思っています。
論文概要
Ito N, Kadomatsu S, Fujisawa M, Fukaguchi K, Ishizawa R, Kanda N, Kasugai D, Nakajima M, Goto T, Tsugawa Y
The Accuracy and Potential Racial and Ethnic Biases of GPT-4 in the Diagnosis and Triage of Health Conditions: Evaluation Study. JMIR Med Educ 2023;9:e47532

Discussion