こんにちは。松尾研究所 データサイエンティストの穴井です。
この記事は松尾研究所 Advent Calendar 2025の11日目の記事です。
はじめに
近年、VLM (Vision-Language Model) や TTS (Text-to-Speech)、VLA (Vision-Language-Action) など、複数のモダリティを扱うAI技術の研究が急速に進展しています。これらはデータの入力・処理方法によって大きく以下の2つに分類されます。
-
マルチモーダルモデル: 複数のモダリティを同時に入力として受け取り、推論を行うモデル(例:画像とテキストを入力する LLaVA)
-
クロスモーダルモデル: あるモダリティを入力とし、別のモダリティを出力(変換)するモデル(例:音声をテキスト化する Whisper)
いずれのモデル開発においても、学習には「画像とテキスト」「音声とテキスト」といった複数のモダリティがペアになった「マルチモーダルデータセット」が不可欠です。
本記事では、この「ペアデータ」をアノテーションフリーで構築する技術に焦点を当てて紹介します。
データ構築の主要アプローチ
アノテーションフリーなデータ構築は、大きく以下の5つに分類されます。
1. 検索・フィルタリング型 (Retrieval & Filtering)
Web上の膨大な未整理データ(例:画像とaltテキスト)に対し、共通の埋め込み空間での類似度を計算し、スコアが高いペアのみ抽出する手法。

2. クロスモーダル生成 + 品質評価型 (Generation & Filtering)
あるモーダルから別のモーダルを生成し、その整合性を評価モデルでスコア化する手法。
- 例: BLIP
Webから収集した画像に対し、キャプション生成モデルで説明文を生成し、CLIP等の評価モデルで「画像と生成文の整合性」をスコア化。閾値以下のペアを捨てて学習データとする(CapFilt戦略)

BLIP論文 Fig.1抜粋
3. ラウンドトリップ再構成型 (Cycle Consistency)
A→B→A のようにモーダル変換を往復させ、元のデータを再構成できるかを評価する手法。
- 例: Cycle Consistency as Reward
画像->テキスト->画像 のように変換し、再生成された画像が元画像と似ているかをDreamSimで評価。
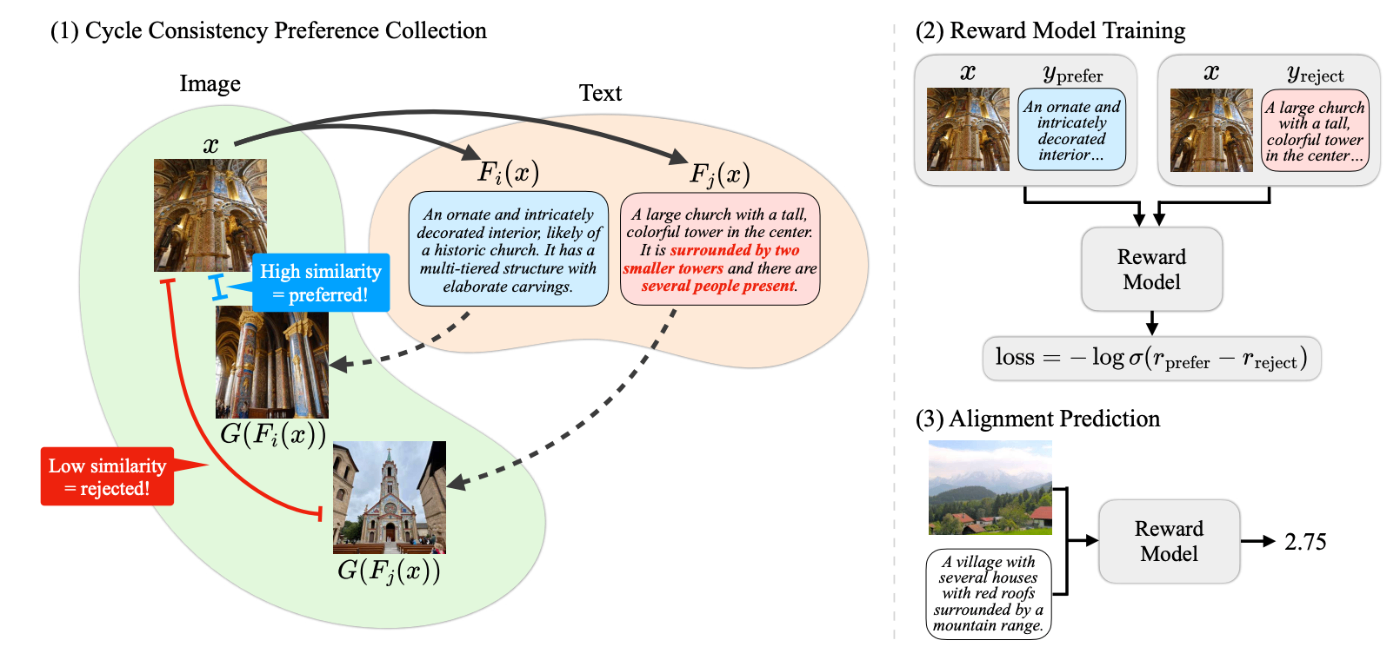
Cycle Consistency as Reward論文 Fig.1抜粋
4. 自己学習・蒸留型 (Self-training / Distillation)
高性能な基盤モデルを「教師」として、未ラベルデータに擬似ラベル(Pseudo-label)を付与。

5. 暗黙的な同期の活用 (Implicit Synchronization)
動画やセンサーなど時間軸を持つデータで「同時記録されている=対応している」とみなす手法。

モーダル別:基盤モデルとデータ構築方法
「Standing on the shoulders of giants(巨人の肩の上に立つ)」よろしく、各モーダルですでに確立された基盤モデルを評価・生成に活用します。各モーダルの代表例を以下に紹介します。
1. テキスト - 画像 (Text - Image)
- 基盤モデル:
- 使用例: Web収集データのCLIPスコアによるフィルタリングや、BLIP-2による詳細キャプション生成とLLM-as-a-judge(GPT-4等による整合性判定)の組み合わせ。
2. テキスト - 音声 (Text - Audio)
- 基盤モデル:
- 使用例: 大量の音声データをWhisperで文字起こしし、ペアデータを生成。環境音にはCLAPを用いて最適なタグを検索・付与。
3. テキスト - 動画 (Text - Video)
- 基盤モデル:
- 双方向 / 共通埋め込み (Video <-> Text)
- InternVideo / X-CLIP: 動画全体やフレームごとの埋め込みとテキストの意味的整合性を学習。検索やフィルタリングに利用。
- 動画 -> テキスト (Video -> Text)
- Video-LLaVA: 動画を入力し、行動の順序や詳細な説明文を生成。
- 双方向 / 共通埋め込み (Video <-> Text)
- 使用例: 人間の作業動画からキーフレームを抽出し、VLMに説明させてロボット学習用データにする(LLM-Trainer等のアプローチ)。
4. 画像 - 音声・動画 (Any-to-Any / Non-text)
- 基盤モデル:
- 使用例: ImageBindを用いたゼロショット分類(例:音声を入力して、対応する動画を検索する)。
5. テキスト/映像 - センサー・行動ログ (Sensor/Action)
- 基盤モデル:
- 使用例: センサログをSensorLLMやGPT-4で言語化してデータセット化。RoboCLIPを用いて人間のデモ動画とロボットの行動をアラインメント。
注意点:基盤モデルのバイアス
アノテーションフリー手法は強力ですが、「アノテーションフリー = 人手確認が不要」ではありません。
フィルタリングや生成に使用する基盤モデル(CLIPやLLM)のバイアスが、そのままデータセットに混入するリスクがあるためです。
完全な自動化を目指すのではなく、構築したデータセットからランダムにサンプリングし、人間が整合性を確認するなど、人手のデータセット評価も取り入れながら進めましょう。
まとめ
Cycle Consistencyの考え方面白いなーと感じたのをきっかけに、マルチモーダル目線のデータセット構築や基盤モデルを調査してみました。
AudioCLIPやRoboCLIPといったCLIPの派生モデル、SensorLLMのようなセンサー用モデルなど、自分が知らない基盤モデルが数多く見つかり新鮮でした。
特定ドメインのデータ構築は依然として難易度は高いものの、今後も基盤モデルを積極的に活用して効率化していければと思います。
本記事がデータセット作成に困っている方の参考になれば幸いです。

Discussion