こんにちは、松尾研究所シニアデータサイエンティストの浮田です。
松尾研究所では、多種多様な機械学習プロジェクトを進めています。これらのプロジェクトの中には、本番環境に近い開発が必要なものもあり、開発した機械学習アルゴリズムを推論用にどのように提供するかについて検討することがしばしばあります。この記事では、私たちがプロジェクトで実際に採用した、機械学習の推論APIの実装例を紹介します。
機械学習アルゴリズムの推論パターン
機械学習モデルの学習やLLMのプロンプトエンジニアリングなどの開発が完了すると、次に考えるのはそのアルゴリズムをどのように提供するかです。提供方法にはいくつかのパターンがありますが、以下の「AIエンジニアのための機械学習システムデザインパターン」の書籍に網羅的にまとまっています。
実際には、特にディープラーニングモデルやLLMを使ったアルゴリズムでは、非同期で推論することが多いと思います。これらのアルゴリズムは推論に時間がかかるため (数秒〜数十秒)、同期処理を行ってしまうとクライアント側の他の処理を長時間待たせてしまうことになります。
私が担当していたプロジェクトでも、推論処理が重いことから非同期での推論を採用しました。またAPIの開発には、慣れ親しんだFastAPIを用いることになりました。
非同期処理の結果の返し方のパターン
非同期処理では、クライアント側が推論結果を取得する方法として、主に以下の2パターンが考えられます[1]。
A. サーバーが推論結果を保持し、クライアントが問い合わせ (ポーリングし) て取得する
B. サーバーからクライアントに対してHTTPコネクションを張り、POSTで推論結果を返却する[2]
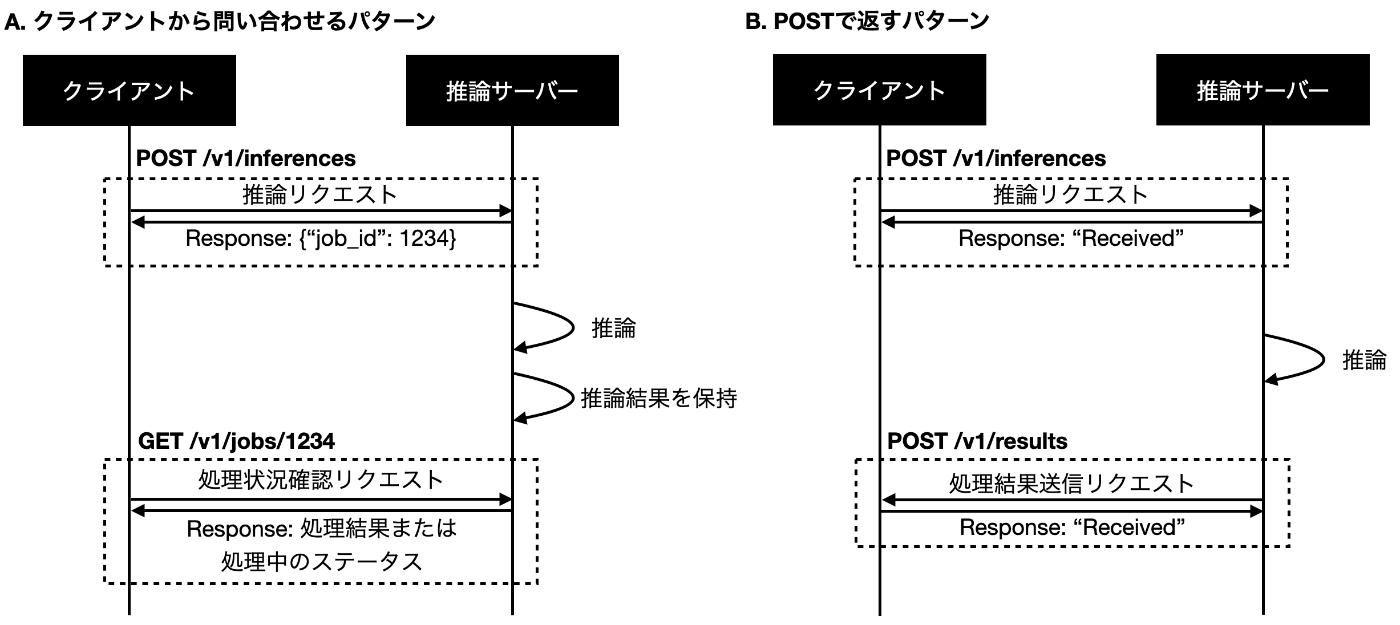
今回のプロジェクトでは、B.のPOSTで返すパターンを採用することとなりました。しかし、A.のクライアントから問い合わせるパターンに関しては書籍「AIエンジニアのための機械学習システムデザインパターン」などで実装例が多く紹介されている一方、B.のパターンの実装例はあまり見つかりませんでした。そこで、この記事ではB.のパターンでの実際の実装方法を紹介します。
実装例
ここでは例として、以下のような非常に簡単なAPIを考えます。
- Step1. クライアントからサーバーに
idとcallback_urlを送信する - Step2. サーバーで重い処理が走る (本来ここで機械学習の推論が走りますが、この記事では「5秒間待つというだけ」という単純な処理とします)
- Step3. サーバーからクライアントに
idとresultを送信する
なおStep1のリクエストは本来idのみで十分ですが、「Step3でクライアントに送信するときの送信先のURL (callback_url)」も追加しておきます。これは、Step3の送信先はクライアント側が決めるものであるため、クライアント側が送信先を指定するほうが、サーバー側のコードに直接書くよりも自然な実装と考えたためです。
サーバー側の実装
main.pyにサーバーを実装します。
リクエスト型を定義する
まずFastAPIで用いるリクエスト型を定義します。上記の通り、リクエストはidとcallback_urlからなります。
from pydantic import BaseModel
class Request(BaseModel):
id: str
callback_url: str
重い処理を実装する
先述の通り、「5秒間待つだけ」というとても単純な処理を行います。
import asyncio
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def process(request: Request):
try:
await asyncio.sleep(5)
await send(request.callback_url, {"id": request.id, "result": "OK"}) # ここの中身は後述
except Exception as e:
logger.error(f"Error processing for request ID {request.id}: {e}")
raise
サーバー側のAPIを実装する
APIとしては、/v1/inferencesというendpointに対してPOSTするものを作成します。リクエストを受け取った後は上述のメインの処理であるprocess関数にリクエストを受け渡したいわけですが、これはFastAPIのbackground_tasksを用いて実装できます。
from fastapi import BackgroundTasks, FastAPI
app = FastAPI()
@app.post("/v1/inferences")
async def inference(request: Request, background_tasks: BackgroundTasks) -> dict[str, str]:
background_tasks.add_task(process, request)
return {"message": "Received"}
サーバーからクライアントに結果を返却する
httpxライブラリを使って以下のようにPOSTリクエストを実装できます。
import httpx
async def send(url: str, data: dict[str, str]):
async with httpx.AsyncClient() as client:
response = await client.post(url, json=data)
response.raise_for_status()
return response
なお今回、サーバーからクライアントにHTTPコネクションを張っているわけですが、万が一この接続に失敗する可能性があります。この場合を考慮すると、retryを含めることでより確実に結果を返却できるでしょう。retry方法としては、代表的なExponential backoffを使用します。
+import backoff
import httpx
-async def send(url: str, data: dict[str, str]):
+@backoff.on_exception(backoff.expo, (httpx.RequestError, httpx.HTTPStatusError), max_tries=5)
+async def send_with_retry(url: str, data: dict[str, str]):
async with httpx.AsyncClient() as client:
response = await client.post(url, json=data)
response.raise_for_status()
return response
これでサーバー側の実装は完了です。次にクライアント側も実装していきます。
クライアント側の実装
ここでは、クライアント側の受け口を作りつつ、1つだけリクエストを送信するプログラムを作成します。request.pyに実装していきます。
ちゃんと作るなら、結果返却用の受け口はリクエストの送信とは別のマイクロサービスとして立てるのが良いかもしれませんが、この記事では簡易的に両者を同じコードで行っています。
リクエストを送信する
まずはサーバーにリクエストを送信する関数send_requestを実装します。
import logging
import httpx
url = "http://localhost:8000/v1/inferences"
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def send_request(data: dict[str, str]):
async with httpx.AsyncClient() as client:
response = await client.post(url, json=data)
logger.info(f"Response from server: {response.json()}")
結果返却用の受け口を作る
結果返却用の受け口は、サーバー側と同様にFastAPIで作成します。/v1/resultsというendpointに対してPOSTリクエストを受けつけるようにします。またこの受け口をたてる関数start_serverも作ります。
import uvicorn
from fastapi import FastAPI
client_app = FastAPI()
@client_app.post("/v1/results")
async def callback(result: dict[str, str]):
logger.info(f"Result received: {result}")
def start_server(host: str, port: int):
config = uvicorn.Config(client_app, host=host, port=port, log_level="info")
server = uvicorn.Server(config)
loop = asyncio.get_event_loop()
loop.run_in_executor(None, server.run)
クライアントに受け口をたてつつリクエストを送信する
最後に、これまで作成した関数を用いて、クライアントに受け口をたてつつリクエストを送信します。
import asyncio
if __name__ == "__main__":
host = "localhost"
port = 8001
start_server(host, port)
data = {"id": "1234", "callback_url": f"http://{host}:{port}/v1/results"}
asyncio.run(send_request(data))
全体のコード
以上をまとめると以下のコードになります。
サーバー側の実装 (main.py)
import asyncio
import logging
import backoff
import httpx
from fastapi import BackgroundTasks, FastAPI
from pydantic import BaseModel
app = FastAPI()
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class Request(BaseModel):
id: str
callback_url: str
@backoff.on_exception(backoff.expo, (httpx.RequestError, httpx.HTTPStatusError), max_tries=5)
async def send_with_retry(url: str, data: dict[str, str]):
async with httpx.AsyncClient() as client:
response = await client.post(url, json=data)
response.raise_for_status()
return response
@app.post("/v1/inferences")
async def inference(request: Request, background_tasks: BackgroundTasks) -> dict[str, str]:
background_tasks.add_task(process, request)
return {"message": "Received"}
async def process(request: Request):
try:
await asyncio.sleep(5)
await send_with_retry(request.callback_url, {"id": request.id, "result": "OK"})
except Exception as e:
logger.error(f"Error processing for request ID {request.id}: {e}")
raise
クライアント側の実装 (request.py)
import asyncio
import logging
import httpx
import uvicorn
from fastapi import FastAPI
url = "http://localhost:8000/v1/inferences"
client_app = FastAPI()
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@client_app.post("/v1/results")
async def callback(result: dict[str, str]):
logger.info(f"Result received: {result}")
async def send_request(data: dict[str, str]):
async with httpx.AsyncClient() as client:
response = await client.post(url, json=data)
logger.info(f"Response from server: {response.json()}")
def start_server(host: str, port: int):
config = uvicorn.Config(client_app, host=host, port=port, log_level="info")
server = uvicorn.Server(config)
loop = asyncio.get_event_loop()
loop.run_in_executor(None, server.run)
if __name__ == "__main__":
host = "localhost"
port = 8001
start_server(host, port)
data = {"id": "1234", "callback_url": f"http://{host}:{port}/v1/results"}
asyncio.run(send_request(data))
動作確認
以下のコマンドを実行してサーバーを立てます。
uvicorn main:app
サーバーとは別のターミナルで以下のコマンドを実行して、クライアント側の処理を行います。
python3 request.py
結果無事、サーバー側にPOSTリクエストを送ることができ、また約5秒後に結果を受け取ることが出来ました。クライアント側のターミナルのログは以下の通りでした。
INFO:httpx:HTTP Request: POST http://localhost:8000/v1/inferences "HTTP/1.1 200 OK"
INFO:__main__:Response from server: {'message': 'Received'}
INFO:__main__:Result received: {'id': '1234', 'result': 'OK'}
INFO: ::1:54352 - "POST /v1/results HTTP/1.1" 200 OK
最後に
本記事では、「サーバーからクライアントにPOSTして推論結果を返却する」という方法で、機械学習の推論結果を非同期的に返却する実装を紹介しました。この記事では、ミニマムにリクエストを送信して結果を受け取るだけを実装しましたが、キューを設置するなど、作り込む要素はまだまだありそうです。
松尾研究所では、ディープラーニングモデルの学習やLLMのプロンプト開発のみならず、この記事のように推論の提供方法を考えるなど、エンジニアリング要素の強いプロジェクトも多数進めています。もし興味を持っていただけましたら、ぜひ下記のリンクからご応募やカジュアル面談の申込みをお待ちしています!

Discussion