松尾研究所シニアデータサイエンティストの太田です。先日AIの年末最大の式典とされるNeurIPSが終わりました。欧米で最も注目を浴びるこのカンファは、アカデミックだけでなくスタートアップ始めとした企業にとっても注目の場であり、この時期に大きなアナウンスメントをする企業が多々あります。
この記事ではそうしたAI渦中の直近一月(2025年11月下旬-12月上旬)に発表されたオープンウェイト(広義にはオープンソース)の大規模言語モデル(LLM) 特に欧米のものに絞って簡単に紹介したいと思います。
近年DeepSeekやQwenといった中国のモデルがオープンソースのフロンティアに立つなか、追従する欧米。果たしてその性能は?発表の時系列にてお届けします。
なおこの記事では各モデルや論文の詳細には入らずに簡単な説明とモデルが体現する開発元の「思想」を読み解くことに注目します。 モデル内部の詳細が知りたいかたはリンク先のテックレポート等をNotebookLMにぶち込んでください!
モデル紹介
AllenAI Olmo 3
2025/11/20
概要
米国のオープンソースといえば、真っ先に思い浮かぶのがAllen Institute for AI。HuggingFaceでも公開モデル・データ数世界一に輝く彼らのミッションは単純明快。「AIの民主化」。本記事で紹介するモデルの多くは厳密なオープンソースではなく、オープンウェイト(誰でも使えるようモデルの重みを公開)であるのに対し、AllenAIは学習に利用されたデータに加えてコードも全公開しています。
AllenAIはその思想のもと実にさまざまなモデルやデータを公開しているのですが、今年11月には彼らのフラグシップラインである「Olmo」の最新版となるOlmo 3を公開しています。
Olmo 3の特徴は7B/32B級のDense型[1]Reasoning[2]モデルであり、AllenAIとしてはReasoningモデルを手がけるのはこれが初の試みです。
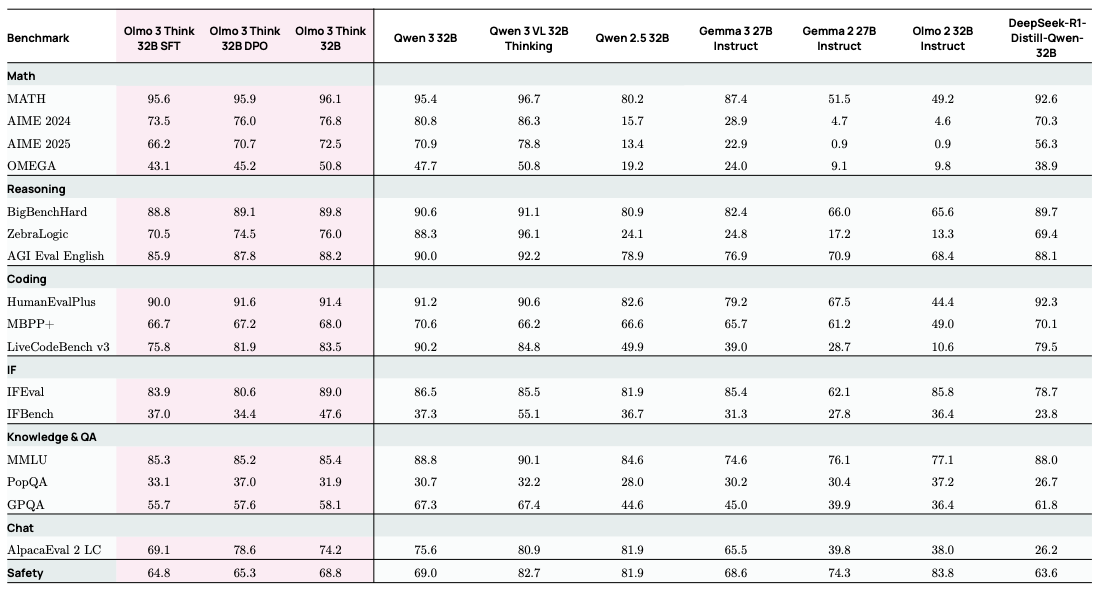
Olmo3の最大の特徴はモデルそのものよりも、そのオープンネスにあると言えます。前項にも記載したとおり、ことオープンモデルに関してはAllenAIはどこよりも先進的であり、モデルのウェイト、学習評価コード、学習データ、さらには中間チェックポイントまでも公開しており、Reasoningモデル構築における全ノウハウをリッチなレポートとともに公開しています。
Takeaway Message
AllenAIはAIの民主化をミッションにした組織であり、それを体現した初の思考モデルである Olmo 3を完全オープンな形で公開。
Prime Intellect INTELLECT-3
2025/11/27
概要
個人的に最近一番推しているのが米国のPrime Intellectです。彼らもまた「AIの民主化」を掲げていますが、前述のAllenAIとは本質的に違うアプローチをとってます。それは 「計算リソースの民主化」。現在、大規模モデルの学習がGPUリソースを過剰に持ったビッグテックの特権であるなか、Prime IntellectはGPUの卸屋としてLambda, Runpod等各種IaaSのGPUを安価で提供しています。Prime Intellectは世界中のGPU ーベンダーのものも個人のものもー 繋げて誰もがつかえる巨大なクラスタを構築することを夢に掲げています。そのため彼らの研究分野はもっぱらインフラや分散学習・連合学習の領域であり、INTELLECTシリーズもまたSoTAを取るためでなくPrime IntellectのインフラのPoCとして生まれました。

INTELLECT-3で使われている学習フレームワークは全てPrime Intellectがオープンソースで開発しているものであり、特にprime-rlは分散基盤で実施するうえでの強化学習のコードを、verifiersは近年LLMの強化学習を実施する上で欠かすことの出来ない environment(オンライン強化学習においてポリシーモデルが報酬を獲得するうえで作用する環境)を提供しています。
ベースモデルは事前学習済みのZ.aiのGLM 4.5 Air Base(106BA12B)[3]であり事後学習が難しいとされるMoE系のモデルの構築に成功しています(本家事後学習済みGLM 4.5 Airを凌駕し同サイズ帯OSモデルにおけるSoTA級)。
Takeaway Message
世界中のGPUを繋げるPrime Intellectは最新モデルINTELLECT-3を通じて独自の開発スタックの可能性を裏打ち。
Arcee Trinity
2025/12/1
概要
モデルマージの愛好者にはお馴染みMergekitの開発元である米国Arcee。前述のオープンソースをミッションとした二社とは異なり、彼らは明確にビジネスをミッションとしています。ArceeはVertical AI(横串の汎用AIではなく縦串の領域特化型AI)の構築を売りにしており、企業向けの事後学習を提供しているTraining as a Serviceの一つです。
今までは既存ベースモデルの事後学習を主軸に開発を進めていたなか、「既存モデルの事後学習だけでは特化性に限界がある」という必要性と「事前学習やったことがないくせにAIエンジニアを語れるか」という熱い思いで、今回アーキテクチャならびに事前学習からゼロベースでTrinityと呼ばれる6BA1B/26BA3B MoEモデル(nanoとmini。なおlargeもこれから来る模様)を開発しています。

「誰でも学習を回せる」Prime Intellectが事前学習ではなく事後学習のみに着目したことに対して、「企業にどこまでも特化可能なAIを提供する」 Arceeが事前学習まで手を出したことは象徴的と言えるでしょう。ビジネスを対象としたArceeがなぜモデルをオープンウェイトにしたか、ですがそこは日本のPlamo (PFN) や Sarashina (SoftBank Intuition) 同様、技術力の発信と(学習)プラットフォーマーとしての動き、オープンソースへの還元があるのでしょうか。
Takeaway Message
ビジネス特化型Vertical AIの提供を売りとするArceeは学習ノウハウの構築とそのアピールのためにTrinityを提供。
Mistral Mistral 3
2025/12/2
概要
「欧州のオープンソースモデルと言えば」のMistralですが、最近はプラットフォーマーとしての立ち位置を確立しているのに勤しんでいるのかOS界隈でのプレゼンスは大人しめの印象でした(超主観。実際はCodestralやVoxtralなど直近半年発表しているので)。僕自身欧州の出身なのですが、Mistralはフランスからの期待値が圧倒的に高い印象であり、国内でも多額の支援を得ています。今回、MoE系モデルの普及に大きく貢献したMixtral以降初の大規模なOS MoEモデル(675BA41B)となるMistral 3とより軽量なDenseモデルであるMinistral 3(3B/8B/14B)のマルチモーダル4種を発表しています。

これは僕の印象の話ですが、Mistralは1~2年前はパイオニアとなるMixtralのApache2.0での提供や、X(Twitter)でのモデルウェイトのステルスドロップ(ツイートにトレントのリンクだけ貼る)など、OSの先駆者として走っていたのが、いつの間にかクローズドなモデルばかり公開したり、DeepSeekからのDistill疑惑が浮上したりと、イケてないイメージになっています。今回のMistral 3で名誉挽回してほしいものの、今回もやはりテックレポートの公開等はなく、時期も(後述の)DeepSeek 3.2と被ったこともあり、なかなか厳しそうです(パリっ子の自分としては応援したい気持ちも、、いや特にないな。なんでだろう)。
なお、Mistralは先月のW&B主催のFully Connected TokyoにもKeynoteセッションで来日しており「なぜ言語特化モデルが必要か」と言う話を熱弁していたのが印象的でした。
Takeaway Message
欧州のフロンティアとしてOSモデルのパイオニアに返り咲きたいMistral。果たして近年生まれてしまったコミュニティとのギャップを埋められるか。
PleIAs Baguettotron
2025/11/10
概要
こちらは載せるか迷いましたが、思想が最近の流行を体現しているのと、欧州のプレイヤーの中でも少し特殊な立ち位置にいるので最後に紹介します。これまたフランスのモデルです(名前の「バゲット」を見れば一目瞭然)。
PleIAsはCommon Corpusと呼ばれる今現在最も大規模な真にオープンソースの事前学習用データセットを構築している研究機関です。彼らの強みは大規模学習データの構築であり、11月に発表された SYNTH プロジェクトでは、野心的な試みとして事前学習データコーパスを完全に合成データで構築しています。BaguettotronならびにMonadはそんなSYNTHデータセットで学習されたDenseモデルです(0.3B/57M)。

最近は強化学習をはじめとした事後学習に関する研究の関心が非常に高い印象ですが、PleIAsは「事前学習データを完全にコントロールすることでモデルの能力を完全にコントロールできる」と謳っています。これは彼らに限った話ではなく、今現在フロンティアであるGemini 3でも緻密に設計された事前学習がモデルの大幅な精度向上に寄与していると言われています(よりタイムリーな例だとtransformersの親によるEssential AIのRnj-1なども事前学習にコミット)。
なお学習データの特異性とは別に、アーキテクチャにおいて非常に深いネットワークを採用しているという観点でも、Baguettotronは他のSLM (Small Language Model)とは一線を画すと言えましょう。
Takeaway Message
人手による良質な学習データが枯渇すると言われている今、データは経験と合成の時代に。Common CorpusからSYNTHへと受け継がれていく。
その他
その他今回の記事では詳細に取り上げなかったモデルを簡単に紹介します。
-
Essential AI
rnj-1(2025/12/5) : transformersの生みの親が立ち上げたEssential AIの初の公開モデルです。前述の通り、事前学習に注力した8B級モデルとなっています。 -
Nous Research
Hermes 4.3-seed/Nomos 1(2025/12/3, 9) : 米国のOS研究機関であるNous Researchのフラグシップ Hermes 4のアップデート(比較的珍しいBytedance Seedをベースモデルにインハウスの Psyche 分散学習を実施)と、数学最難関Putnam Benchを同パラメタサイズ帯でSoTAをとったNomos 1を展開しています。 -
Zyphra
Zaya 1(2025/11/24) : 知名度はまだ低いZyphraですが、今回初めて発表したモデルである Zaya 1 はIBMとの共同研究のもと9B級MoE系モデルをAMDチップで学習という偉業を成し遂げ、絶対王者であるNvidiaに牙をむいています。
番外編
DeepSeek DeepSeek 3.2
2025/12/1
DeepSeek 3.2は控えめな少数点とは裏腹に、DSA (DeepSeek Attention)を始めとして、様々な技術要素を導入しています。ここでモデルの技術的内容を深掘りするのは避けますが、注目すべきはDeepSeekがまぎれもない 「先駆者」 であることです。DeepSeekの論文はいまや例外なく注目を浴びる。読むことで 「ワクワク」 する。
本記事で紹介したモデルや開発機関はいずれも(ベンチマーク上では)何かしらのSoTAを出しています。彼らは難易度が高いことは間違いなくやっている、アカデミアとビジネスに還元している。悲しいかなその一方で、DeepSeekやあるいはQwen, Kimiにある「ワクワク」は弱く感じるのです。
これはモデルの開発元が「LLM一本でビジネスをする」スタートアップ企業で構成される欧米と、「LLMの研究をする」大学発スタートアップ(Z.ai)や「主ビジネスの側研究する」大企業R&D部門(Alibaba, Bytedance, Longcat)で構成される中国の、文化の違いから生じているものかもしれません。
とはいえ中国プレイヤーのなかでもDeepSeekは異彩を放っています。自分達だけは本気でOpenAIやAnthropic、GoogleとAGIの座をかけて戦い勝てると信じている、と言わんばかりのオーラを。それを体現しているのが創始者であるLiang Wenfengのこの言葉でしょう。
China's AI can't be in the position of following forever. We often say that there is a gap of one or two years between China's AI and the United States, but the real gap is the difference between originality and imitation.
Meta LLaMA
欧米OS LLMの躍進の影の勝者がDeepSeekであるとすれば、敗者はMetaじゃないでしょうか。
去年の今頃はLLama3.3がアナウンスされていたのに、今年は2025年4月の波乱のあったLLaMa4以降音沙汰なしです、、
まとめ
タイムラインを今一度見返すと、改めて12月上旬は欧米のオープンソース界にとって怒涛の数週間であったと言えましょう。この記事を締めるにあたって、今回の一連の発表から見える一つのトレンドに最後に触れたいと思います。
それは Training as a Service つまり、特化型モデルの学習そのもののサービス化です。最もわかりやすいArceeはもちろん、Mistralも実は今回Mistral 3の発表と共にFine-Tuning Serviceというモデル学習ビジネスを始めています。広義には学習スタックをオープンで提供しGPUを卸すPrime Intellectも通ずるものがあるでしょう。
またこのTaaSを地で行っているのがMira Murati率いるThinking Machinesや同じくOpenAIの元エンジニアが立ち上げたApplied Computeです。
正直今の段階では、特化型モデル構築の道と完全万能なAGIをプロンプティングする道、どちらが勝利するかまだ見えていません。あるいはNLPがそうであったようにデカいモデルが全てをかっさらうかもしれません。
モデルそのものでなく学習対象を、すなわち学習データあるいはモデルが学習する環境を緻密に設計するSynth Post-Trainingは、従来の機械学習と比較しても理に適っているように思えます。Vertical AIの導入が滞っていると言われているいま、特化型モデルの構築は(エンジニアにとってもVCにとっても)魅力的に見えるでしょう。その一方学習はコストがかかるのも事実です。
結局のところ汎用LLMでカバーできるタスク・出来ないタスクの見極めが重要だと考えています。我々松尾研究所でもまた、様々な社会課題に柔軟にそして画期的に対応すべく、技術に縛られず双方のアプローチを日々模索し実践しています。詳しくは松尾研究所が公開したブループリントをぜひご覧ください。
立ちあがる欧米。
今後世界の研究機関が、LLMの情勢が、どう進化するのか楽しみです。
Bonus: Why RL Env..?
この記事で軽く触れた Environment についてPost Scriptumとして最後に少しお話します。ここでいうEnvironmentとはオンライン強化学習を実施する上で、報酬を獲得する環境を指します。
従来LLMの事後学習というのは、それがInstruction-Tuning(質問に正しく回答できるよう学習)であれ Reinforcement Learning from Human Feedback (回答時に人間の嗜好に沿うようアラインメント)であれ、「データセットから学ぶ」というのが常識でした。[4] これはここ一年流行しているReasoningモデル [2:1] についても基本例外ではなく、数学やSTEM系データセットを対象にGRPO等の高効率の強化学習手法を使って論理能力を鍛えています。
しかし近頃、いくつかの要素をきっかけにLLMにおける強化学習のあるべき姿が変化しています。特に重要な要素として
- 自律的にタスクをこなすAgentの台頭
- 人手で構築した「良質な」言語データの枯渇
の二つが挙げられますが、これらは「データセットから学ぶ時代」の終了を意味しています。今年の4月に強化学習の父であるRichard Suttonが予言した通り、これからは「経験の時代(The Era of Experience)」が到来すると言われています。LLMが人と同じ環境の中で自律的に行動し自ら学ぶ、そのようなパラダイムが今のLLMないしAIが進化するには求められています。
この「人と同じ環境」ですが、これはロボットを野に放つことを必ずしも意味しているわけではありません。環境はタスクによって異なります。例えばコーディングタスクであればプログラムを実行するサンドボックスが必要ですし、検索タスクであれば自由に検索できるWebブラウザが必要です。このように「AIが特定のタスクを(強化学習を用いて)学ぶ場」を RL Environment と呼んでいます。
そして実を言うと強化学習を環境ファーストで考えるのは特に目新しいことはなく、むしろ原点回帰の側面が強いです。しかし「データセットから学ぶ」が常識であったLLMの学習スタックにおいては「環境起点で考える」という視点は今年に入って本格化した印象です(前述のDeepSeek 3.2もまた、訓練の過程で数千もの強化学習用環境を構築しています)。
また、そうした意味ではRLの環境構築を抽象化した Prime Intellect の verifiers は理に適っている言えます。さらに革新的なのが、これらの環境がPrime Intellect の Environment Hub を通じて共有できることです。「学習データ」という概念が「学習環境」で置き換わるのであれば、今現在HuggingFaceがOSデータセットのハブとなっている通り、OS RL Envのハブがあってもいいのではないか、という思想です。
ここまで来たら僕がなぜPrime Intellectを推しているかについても少し伝わったかと思います、、!
そしてまとめのTraining as a Serviceでも触れた通り、今世界のさまざまなプレイヤーが特化学習の奥深い世界に乗り出しており、今後さらに発展すると信じています。
-
この記事ではDense/MoE型モデルを区別しています。Dense型モデルとは従来の、内部パラメタ全てを使って推論をするLLMを指しており、MoE (Mixture of Experts) モデルとはクエリに対して、特定のパラメタ(=エキスパートと呼ばれるニューラルネットのユニット)のみを利用して推論します。 ↩︎
-
ReasoningモデルとはOpenai o1やDeepSeek R1で台頭した最終出力前に「思考」をするモデルです。思考とは特殊トークンである
<think>..</think>内で生成された文章を指しており、モデルは思考という名の下書きを通じて、</think>のあとに最終回答をだします。商業モデルの場合この「思考」はユーザーに意図的に見せないことが多いです。 ↩︎ ↩︎ -
前述の通りMoEモデルは全体パラメタのうち、クエリに応じて特定のパラメタのみが利用されます。これを「全体ではXパラメタ数あるうち、特定のYの数のパラメタが利用される」ということを表して
XBAYB(Aは Activated から、Bは Billion から)と書きます。 ↩︎ -
RLHF (Reinforcement Learning from Human Feedback) についてはデータセットではなく、「人の反応」ではないかと思われるかもしれません。しかしRLHFも予め準備された質問・複数回答のペアに対して人が好みを出力しデータセットを構築しています。RLHFで広く利用されているPPO等の手法ではこの「好み」を報酬モデル(あるいは
Critic)として学習し、最終的なモデルの訓練に活用しています。学習モデルに報酬を与えているのは報酬モデルであるものの、こちらは静的でありデータセットの縛りは受けている、という意味で「データセットから学ぶ」にここでは入れています。 ↩︎

Discussion