1. はじめに
こんにちは、松尾研究所でデータサイエンティストをしている力岡です。本記事は、松尾研究所 Advent Calendar 2025 の記事になります。
GPT や Gemini などの LLM を活用した AI エージェントは急速に普及し、複数ツールを組み合わせた複雑なタスクも自律的に実行できるようになりました。その一方で、「なぜエージェントが失敗したのか分からない」「推論コストが想定以上に膨らむ」「複数エージェントを連携させる際のボトルネックが特定できない」といった、これまでにない運用上の課題が浮き彫りになっています。
こうした高度なエージェントシステムは、従来の LLMOps だけで管理することが難しくなりつつあります。本記事では、その解決策として注目される AgentOps を取り上げ、その概念から実践方法までを詳しく解説します。
2.AgentOps とは
2.1 AgentOps が必要とされる背景
LLM の登場により、AI システムの開発パラダイムは大きく変化しました。単純な予測モデル中心のアプローチから、複雑な推論や意思決定を担う自律エージェントへと進化が進む一方で、従来の運用管理手法では扱いきれない新たな課題が浮上しています。
- 複数ツールを連携させるエージェントでは、障害発生箇所の特定が難しい
- エージェント同士の協調プロセスにおいて、想定外の振る舞いが起こる
- コスト増大やパフォーマンス低下の要因が把握しづらい
- エージェントの判断過程がブラックボックス化しやすい
こうした課題に体系的に対処するために生まれたのが、AgentOps という新しい運用管理の考え方です。
2.2 AgentOps の定義
そもそも AgentOps とは何なのでしょうか。簡単に言えば、AI エージェントを安全かつ効率的に運用するための包括的な仕組みです。
2024年11月に公開された論文 AgentOps: Enabling Observability of LLM Agents では、AgentOps を次のように定義しています。
AgentOps とは、AI エージェントシステムの開発、デプロイメント、監視、最適化を包括的に管理するための運用フレームワークである。モデルの管理にとどまらず、エージェントの振る舞い、相互作用、意思決定プロセス全体を可視化・制御することを目的とする。
論文では、AgentOps が備えるべき要素を次の7項目に整理しています。
① Customization(カスタマイズ)
エージェントをニーズに合わせて柔軟に調整するための仕組み
| 主な機能 | 内容 |
|---|---|
| エージェントのプロビジョニング、カスタム、デプロイ | スケーラブルな自律エージェントの構築 |
| ツールキットによる能力拡張 | マーケットプレイスからツールを追加してワークフローに組み込む |
| 複数ベクトル DB との接続 | 複数 DB を活用しエージェント性能を向上 |
| ファインチューニングモデルの利用 | ビジネス固有のユースケースに最適化 |
② Prompt Management(プロンプト管理)
プロンプトの変更管理・品質確保・セキュリティを担保する仕組み
| 主な機能 | 内容 |
|---|---|
| プロンプトのバージョン管理 | 使用するプロンプトを体系的に管理 |
| 比較可能なプロンプトプレイグラウンド | 異なるプロンプト・モデルを事前にテスト |
| プロンプトインジェクション検知 | コードインジェクションや情報漏洩の兆候を検出 |
③ Evaluation(評価)
エージェントの品質を定量的に測定・改善するための仕組み
| 主な機能 | 内容 |
|---|---|
| ベンチマーク・リーダーボード評価 | データセット作成、指標定義、評価実行、比較、経時分析 |
| 多段階のエージェント評価 | 最終応答評価: エージェントの最終応答を評価 単一ステップ評価: 特定ステップの適切性を評価 軌跡評価: 期待された手順に沿っているかを評価 |
④ Feedback(フィードバック)
ユーザー行動から改善に必要な情報を収集する仕組み
| 主な機能 | 内容 |
|---|---|
| 明示的フィードバック収集 | ユーザーから直接回答を取得 |
| 暗黙的フィードバック収集 | ページ滞在・クリックなど行動ログを活用 |
⑤ Monitoring(モニタリング)
運用状況をリアルタイムに可視化する仕組み
| 主な機能 | 内容 |
|---|---|
| エージェント分析ダッシュボード | 多様な指標を一元的に可視化 |
| LLM コスト管理 | モデル利用コストを詳細に追跡 |
⑥ Tracing(トレーシング)
エージェントの思考・行動の全プロセスを記録する仕組み
| 主な機能 | 内容 |
|---|---|
| LLM/エージェントトレース | 推論・行動の流れを可視化 |
| 評価スパンのトレース | 評価プロセス全体を追跡 |
| フィードバックのトレース | 収集したユーザーフィードバックの経路を記録 |
⑦ Guardrails(ガードレール)
エージェントの安全性・制御性を維持する仕組み
| 主な機能 | 内容 |
|---|---|
| ルール・制約の事前定義 | エージェントの行動を制限し、安全で予測可能な振る舞いを確保 |
| フォールバック・エスカレーション | 不確実な状況で人間に引き継ぐなど安全策を確保 |
2.3 MLOps から AgentOps への変遷
AgentOps の背景を理解するには、まず従来の運用手法が抱える限界を押さえる必要があります。
これまで私たちは、機械学習モデルに対して MLOps を、LLM に対して LLMOps を整備してきました。そして現在、自律的に計画・行動し、ツールを活用するエージェントが主役となり、AgentOps が不可欠な段階へと移行しています。
下表は、それぞれの運用体系の違いを簡潔にまとめたものです。
| 特徴 | MLOps | LLMOps | AgentOps |
|---|---|---|---|
| 概要 | 予測モデルの学習〜デプロイ〜監視を自動化し、品質と継続運用を保証する仕組み | LLM の振る舞い・コスト・データパイプラインを管理し、生成品質を安定化するための運用体系 | エージェントの思考・行動・ツール実行を安全かつ制御可能に管理するための運用基盤 |
| 対象 | 決定論的な ML モデル(分類、回帰など) | LLM・RAG・ファインチューニングモデル | マルチステップで計画し、状態を保持しながらタスクを進めるエージェント |
| プロセス | データ準備 → 学習 → 評価 → デプロイ → 監視・再学習 | プロンプト/コンテキスト設計 → RAG/FT → 評価 → 推論最適化 | 目標設定 → 計画生成 → ツール実行 → 反省 → 再計画 |
| 焦点 | 再現性、スケーラビリティ、ドリフト検知、安定デプロイ | 生成品質管理(ハルシネーション抑制)、コンテキスト最適化、コスト/遅延制御 | 思考ログ追跡、安全なツール操作、マルチステップ推論の制御性 |
| 主なアーキテクチャ構成要素 | データパイプライン、特徴量/モデル管理、CI/CD、監視基盤 | ベクトルDB、プロンプト管理、RAG パイプライン | メモリ管理、ツール/API 実行レイヤー、オーケストレーション、ガードレール |
LLMOps は LLM の生成品質管理やコスト最適化に有効ですが、複数ステップで計画し、行動し、ツールを使って結果を導くエージェントを安定運用するには不十分です。このような複雑な意思決定やツール実行を伴うシステムを安全かつ継続的に管理する枠組みとして、AgentOps の必要性が高まっています。
背景や構成要素をより体系的に整理した資料として、ARISE analytics 様の以下のスライドも参考になります。
3. AgentOps の実践
ここまで、AgentOps の概念と必要性を整理してきました。では実際に、エージェントシステムを本番環境で安全かつ安定的に運用するには、どのような取り組みが必要なのでしょうか。
Google Cloud が公開しているホワイトペーパー Prototype to Production では、AI エージェント実用化のための具体的なガイドラインが示されています。同資料によれば、エージェントの「頭脳」に相当するモデル開発は全体の約 20% に過ぎず、残りの 80% はインフラ、セキュリティ、評価・検証などの運用基盤の構築に費やされるとされています。
つまり、優れたエージェントを開発するだけでは不十分で、それを安全に、継続的に、想定どおりに稼働させ続ける仕組みこそが成功の鍵になります。ここからは、ホワイトペーパーの内容を踏まえつつ、実運用に必要な具体的な取り組みを見ていきます。
3.1 エージェント評価の必要性
従来のアジャイル開発では「まずリリースしてフィードバックを見る」という方針も取り得ました。しかし、自律的に判断・行動するエージェントにそれを適用すると、予期せぬツール実行やハルシネーションによる誤情報の提示など、深刻な問題につながる可能性があります。
そこで AgentOps では、Evaluation-Gated Deployment(評価駆動型デプロイ) という原則を採用します。これは、あらかじめ設定した品質基準をクリアしない限り、エージェントを公開しないという考え方です。
従来テストとの違い
一般的なソフトウェアテストは「エラーなく実行されるか」を中心に確認します。一方、エージェントは振る舞いが確率的であるため、それを加味した評価を実施する必要があります。
例えば、「ユーザーの質問に答える」というタスクで考えてみましょう。
- 通常のテスト: エラーなく回答を返すか?
- エージェントのテスト: 回答は正確か?礼儀正しいか?不適切な内容を含んでいないか?
このような振る舞い評価を行うため、期待される理想的な応答例をまとめた "ゴールデンデータセット" を用意します。いわばエージェントの「お手本集」であり、品質基準の基盤となります。
評価基準に基づくデプロイ判断
ホワイトペーパーでは、チームの成熟度に応じて次の2つの方法が提示されています。
-
初心者向け: 手動ゲート
開発者がコードをプッシュする前にローカルで評価テストを実行し、その結果を PR に添付します。レポートがなければレビューを受け付けないルールとすることで、明確な品質劣化を未然に防ぎます。 -
上級者向け: 自動ゲート(CI/CD)
チームが成熟した段階では、評価をパイプラインに組み込み自動化します。CI/CD パイプラインの中で評価を実行し、「ツール呼び出しの成功率や有用性などの主要な指標が、事前に定義した閾値を下回った場合はデプロイを即時停止する」といった厳格なガードを設けます。これにより、人間の判断を介さずに品質を担保できます。
3.2 CI/CD パイプライン
評価体制が整ったら、その仕組みをどのようにパイプラインへ組み込み、安全に本番リリースまでつなげるかを設計する必要があります。
エージェントシステムは「ソースコード」だけでなく、「プロンプト」「ツール定義」「設定ファイル」など多様な要素が密接に依存しており、プロンプトを少し変更しただけで特定のツール呼び出しが破綻することもあります。
この複雑性を扱うため、ホワイトペーパーでは3段階のパイプライン構成を推奨しています。テスト強度を段階的に高めることで、問題を早期に検知しつつ安全に本番へ届ける構成です。
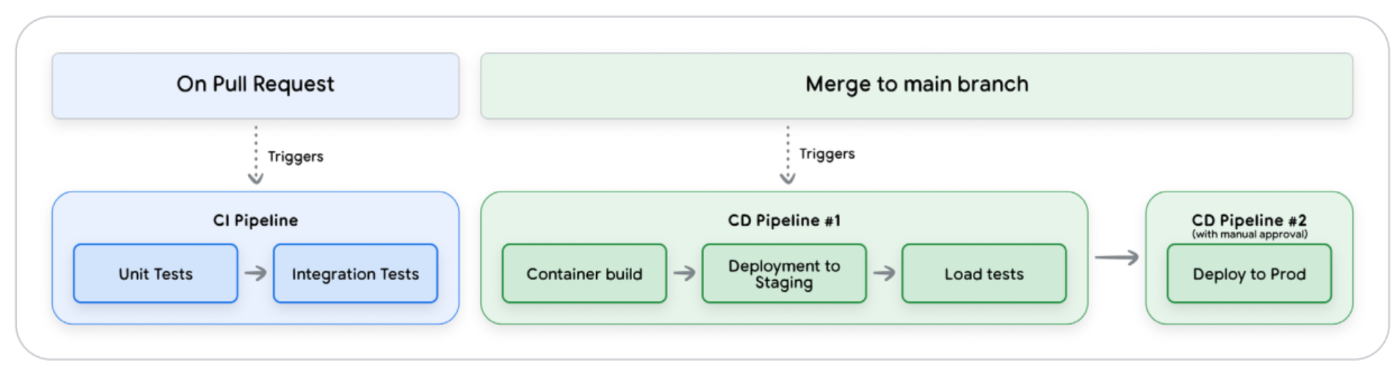
Whitepaper Figure3: CI/CD パイプラインの各ステージ
Phase 1: Pre-Merge Integration (CI)
- 目的: プルリクエスト時に即時フィードバックを得る
- 内容: コードの Lint チェックや単体テストに加えて、軽量な評価セットを実行します。プロンプト変更やツール呼び出しの副作用による性能劣化を早期に検知し、メインブランチへの影響を防ぎます。
- 参考テンプレート: pr_checks.yaml
Phase 2: Staging (CD)
- 目的: 運用環境への移行可否を確認
- 内容: 本番環境を模したステージング環境へデプロイし、外部 API 連携や負荷テストを実施します。また、社内ユーザーによるテストを通じて、自動テストでは気づきにくい使い勝手の違和感や対話フローの問題を洗い出します。
- 参考テンプレート: staging.yaml
Phase 3: Production (本番展開)
- 目的: リスクを最小化しつつ本番リリースする
- 内容: ステージングで十分に検証されたものを本番環境へ段階的に展開します。カナリアリリース(1% から始める小規模公開)や、新旧環境の並行稼働による段階的切り替えを用い、問題発生時には即座にロールバックできる状態を担保します。
- 参考テンプレート: deploy-to-prod.yaml
3.3 継続運用サイクル
無事に本番リリースができても、エージェント運用はそこで終わりではありません。エージェントは自律的に判断・行動するため、ユーザー入力によって予期せぬ挙動を起こす可能性があります。
そのため、静的な監視だけではなく、「Observe(観測) → Act(対処) → Evolve(進化)」 のサイクルを継続的に回し、システムを動的に改善し続ける必要があります。
① Observe(観測)
従来の CPU 使用率などのインフラ監視だけでは、エージェントの判断理由を理解することはできません。「エージェントがなぜその回答をしたのか」を理解するための可観測性(Observability)が不可欠であり、これは次の3つの柱から構成されます。
-
Logs
- ツールの実行時刻・種類や使用モデルなど、事実ベースの詳細記録
-
Traces
- 1回の問い合わせに対する「思考 → ツール実行 → 結果 → 再思考 → 回答」の流れ紐づけ、因果関係を追跡
-
Metrics
- 応答時間、トークン使用量、タスク成功率などを指標でシステム全体の状態を把握
② Act(対処)
異常検知後に人間が対応していては間に合わないケースがあるため、システム自身が自律的に防御・回復できるような 自動介入メカニズム をあらかじめ組み込み、迅速に問題を封じ込めます。
ここでは、その自動介入を支える2つの軸として「システムの健全性管理」と「リスク管理」について整理します。
システムの健全性管理
1つ目の軸は、「落ちない・詰まらない・高くなりすぎない」ための基盤としての健全性管理です。エージェント特有の動的でステートフルな負荷に耐えるには、スケール性と自動回復を前提にした設計が書かせません。
-
水平スケーリングで負荷分散
- エージェント本体はステートレス化し、会話履歴やセッション情報は外部ストアに保持することで、どのインスタンスでも任意のリクエストを処理でき、自動スケールしやすくなります。
-
非同期処理で応答性を確保
- レポート生成など重い処理は、イベント駆動でバックエンドへオフロードし、フロントのエージェントはすぐにレスポンスを返します。
-
スピード・信頼性・コストのバランスを意識した設計
- スピード: 並列実行・キャッシュ・軽量モデルでレイテンシを削減
- 信頼性: 指数バックオフ付きリトライが可能になるよう、ツールをべき等に設計
- コスト: プロンプトを短く保ち、タスク難易度に応じたモデル使い分けやバッチ処理で推論コストを抑制
リスク管理
2つ目の軸は、エージェントの暴走や外部からの攻撃を迅速に封じ込めるための仕組みです。エージェントは自律的にツールを呼び出せるため、異常時の対応手順を プレイブック(対応手順書) として用意しておくのがポイントです。ホワイトペーパーでは、次の「封じ込め → トリアージ → 恒久対策」という3段階の流れが推奨されています。
-
封じ込め: サーキットブレイカーで即時停止
- 特定ツールでエラーが多発したり、不審なリクエストパターンが検知されたりした場合に、そのツール機能だけを瞬時に無効化する。
-
トリアージ: HITL レビューによる影響評価
- 疑わしいリクエストやセッションを Human-in-the-Loop(HITL) のレビューキューに送り、人間のオペレーターが内容を精査します。
-
恒久対策: パッチ適用と CI/CD による再発防止
- 入力フィルタの強化、システムプロンプトの見直し、ツール側の権限・バリデーション改善など、恒久的なパッチを実装します。
③ Evolve(進化)
ここが、従来の運用との最大の違いです。本番環境での失敗や低評価は、単なるバグではなく、エージェントを賢くするための もっとも価値の高い教材 と捉えます。
ホワイトペーパーでは、次の継続的ループを「進化のエンジン」と呼んでいます。
-
Analyze(分析)
- 本番ログから、「ユーザーが離脱した会話」や「失敗したタスク」を抽出する。
-
Update Dataset(データセット更新)
- 抽出した失敗事例をそのまま「評価用ゴールデンデータセット」の新しいテストケースとして追加する。
-
Refine & Deploy(修正と再デプロイ)
- プロンプト、参照ドキュメント、ツール定義などを修正し、追加したケースをクリアできる形で改善を適用する。
このサイクルを継続して回すことで、エージェントは初期設計を超えて実際のユーザーニーズに適応し、運用を通じて進化し続けるようになります。
3.4 マルチエージェントへの拡張: A2A と MCP
単体のエージェント運用が安定してくると、次は複数のエージェントを連携させたくなります。組織内に散在するエージェント同士をつなぐために、ホワイトペーパーでは2つのプロトコルを使い分ける方針が示されています。
-
MCP (Model Context Protocol)
- 「エージェント ↔ ツール」をつなぐための標準プロトコル
- データベース接続、計算処理、外部 API 呼び出しなど、明確な入出力を持つ「ツール」を共通仕様で扱うために用いる
-
A2A (Agent-to-Agent Protocol)
- 「エージェント ↔ エージェント」をつなぐためのプロトコル
- MCP が単機能のツール実行を扱うのに対し、A2A は「来期の解約率を分析して、改善案を提案して」のような、複雑で抽象度の高いゴールを別のエージェントへ依頼する用途を想定
これらを組み合わせることで、たとえば
「受付エージェント(A2A で依頼)」 → 「専門分析エージェント(MCP で社内 DB を操作)」
という流れを構成できます。各チームが自分たちの得意分野に特化したエージェントを作り、それらが連携して動くエコシステムを構築できるようになります。
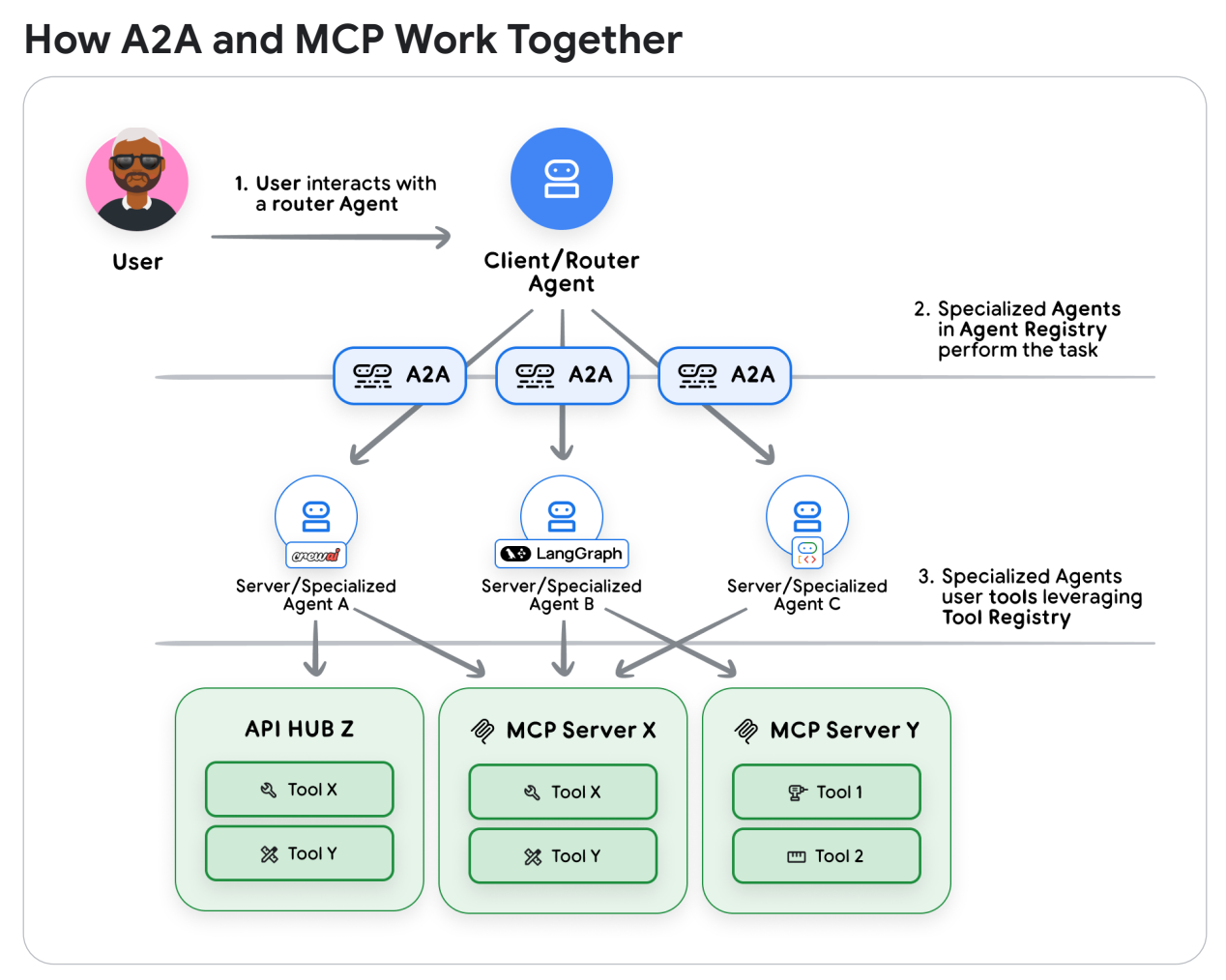
Whitepaper Figure4: A2AとMCPの連携例
4. AgentOps の実装
理論的な概要を確認したところで、ここからは実際に AgentOps を実装・活用する方法を紹介します。本章では、AgentOps を手軽に導入できるオープンソースライブラリ agentops を用いて、具体的な実装例を示します(概念としての AgentOps と区別するため、ライブラリは agentops と表記します)。
agentops の特徴は、わずか数行の追加でエージェントの動作ログを可視化できる点にあります。OpenAI Agents SDK、AutoGen、LangChain など主要なフレームワークに対応しており、用途に応じて柔軟に利用できます。ここでは OpenAI Agents SDK を例に説明しますが、他のフレームワークでも同様に利用できます。
OpenAI Agents SDKとは
OpenAI Agents SDK は、OpenAI のLLMを中心に、外部ツールや関数、API を統合して自律的にタスクを遂行するエージェントを構築するためのフレームワークです。ここでは詳細は割愛しますが、様々なツールが事前に用意されており、複雑なタスクをこなすエージェントなども簡単に作成することができます。
4.1 環境構築
まず、uvを利用して必要なライブラリをインストールします。
uv add agentops==0.4.21 openai-agents python-dotenv
uvとは?
uvは、Python開発に必要な機能を統合した高速なオールインワンツールで、仮想環境・依存関係・Python本体のバージョン管理を一括で扱えます。pip、venv、poetryの役割を包括し、再現性の高い環境構築とシンプルな操作性を実現します。
入門資料としてこちらの資料がとても分かりやすいので、ぜひご参照ください。
次に、agentops のダッシュボードで API キーを取得し、.env に保存します(無料枠あり)。
AGENTOPS_API_KEY="ダッシュボードで取得したAPIキー"
OPENAI_API_KEY="OpenAIのAPIキー" # OpenAI Agents SDK用
4.2 基本的な使い方
初期設定
最も簡単な導入方法は、以下のコードを追加するだけです。これだけで主要な AI エージェント呼び出しが自動的に記録されます。
import agentops
from dotenv import load_dotenv
load_dotenv()
# agentops の初期化
agentops.init(api_key=os.getenv("AGENTOPS_API_KEY"))
セッションの開始と記録
agentops の中心となる概念はセッション(Session)です。セッションとは、エージェントが実行する一連の作業(例えば「顧客対応」「レポート生成」「市場調査」など)をまとめた単位です。
セッション内では、次の情報が自動で記録されます。
- LLM 呼び出し内容: モデル、プロンプト、レイテンシ、エラーなど
- トークン使用量: 入力/出力トークン、コスト
- 処理フロー: どの順序で処理が行われたか
- ツール実行: Web 検索など外部ツールの呼び出し状況
初期化だけでも基本的なトレースは自動化されますが、より細かく制御したい場合は以下のように明示的にセッションを開始・終了できます。
# セッションの開始
agentops.start_trace(
trace_name="Customer Workflow",
tags=["customer-query", "high-priority"]
)
try:
# --- エージェントの処理 ---
# 成功を記録
agentops.end_trace(trace, "Success")
except Exception as e:
# 失敗を記録
agentops.end_trace(end_state="Error")
デコレータを用いた関数単位でのトレースなど、より高度な利用方法も用意されています。詳細は公式ドキュメントをご参照ください。
4.3 エージェントシステムへの組み込みと可視化
ここでは、実際のエージェントシステムに agentops を組み込み、動作を可視化する例を紹介します。
例として、3つのエージェントが協力して調査レポートを作成するシステムを構築します。
- 計画エージェント: 検索すべき内容を計画
- 検索エージェント: 計画に基づき Web 検索を実行
- レポートエージェント: 取得した情報を整理しレポートを生成
このコードは OpenAIの公式サンプル をベースに、一部簡略化して agentops を組み込んだものになります。
実装コード
初期化と agentops セッション設定
必要なライブラリの読み込みと環境変数の設定を行い、agentops を初期化します。auto_start_session=False を指定することで、明示的にトレースを開始・終了できるようにしています。
import asyncio
from pydantic import BaseModel
from openai.types.shared.reasoning import Reasoning
from agents import Agent, ModelSettings, Runner, WebSearchTool
import agentops
# 環境変数の読み込み
from dotenv import load_dotenv
load_dotenv()
# agentops の初期化
agentops.init(auto_start_session=False, tags=["research-bot", "multi-agent", "agentops-example"])
計画エージェント(検索計画の生成)
与えられたクエリに対して、「どのキーワードで検索すべきか」を3〜5件提案するエージェントを定義しています。
# 計画エージェント
class WebSearchItem(BaseModel):
reason: str
query: str
class WebSearchPlan(BaseModel):
searches: list[WebSearchItem]
planner_agent = Agent(
name="計画エージェント",
instructions=(
"あなたは有用な研究アシスタントです。クエリが与えられたら、そのクエリに最適に答えるための"
"ウェブ検索のセットを考案してください。3〜5個の検索語を出力してください。"
),
model="gpt-5",
model_settings=ModelSettings(reasoning=Reasoning(effort="medium")),
output_type=WebSearchPlan,
)
検索エージェント(Web 検索と要約)
計画エージェントが提案した検索語を使って Web 検索を行い、その結果を簡潔に要約するエージェントです。openai-agents のWebSearchTool をツールとして設定することで、Web検索を実現しています。
# 検索エージェント
search_agent = Agent(
name="検索エージェント",
model="gpt-4.1",
instructions=(
"あなたは研究アシスタントです。検索語が与えられたら、その語でウェブを検索し、"
"結果の簡潔な要約を作成してください。要約は2〜3段落で300語未満にする必要があります。"
"主要なポイントをキャプチャしてください。簡潔に書き、完全な文や良い文法は必要ありません。"
"これはレポートを統合する人が使用するので、本質をキャプチャして無駄を無視することが重要です。"
"要約以外の追加のコメントは含めないでください。"
),
tools=[WebSearchTool()],
model_settings=ModelSettings(tool_choice="required"),
)
レポートエージェント(最終レポートの生成)
検索結果をもとに Markdown 形式のレポートを生成するエージェントです。
# レポートエージェント
class ReportData(BaseModel):
short_summary: str
markdown_report: str
follow_up_questions: list[str]
writer_agent = Agent(
name="レポートエージェント",
instructions=(
"あなたは研究クエリのためのまとまりのあるレポートを書く任務を負った上級研究者です。"
"元のクエリと研究アシスタントによって行われた初期調査が提供されます。\n"
"まず、レポートの構造と流れを記述するアウトラインを作成する必要があります。"
"次に、レポートを生成し、それを最終出力として返してください。\n"
"最終出力はMarkdown形式である必要があり、詳細で包括的である必要があります。"
"5〜10ページのコンテンツ、少なくとも1000語を目標としてください。"
),
model="gpt-5-mini",
model_settings=ModelSettings(reasoning=Reasoning(effort="medium")),
output_type=ReportData,
)
ResearchManager(全体のオーケストレーション)
3つのエージェントを組み合わせて "検索計画 → Web検索 → レポート生成" という一連のワークフローを実行します。ここで agentops.start_trace() を呼び出し、処理全体を1セッションとして記録します。成功/失敗に応じて end_state も切り替えられます。
# 研究マネージャー
class ResearchManager:
def __init__(self):
pass
async def run(self, query: str) -> None:
# AgentOpsトレースセッションを開始
tracer = agentops.start_trace(
trace_name=f"研究タスク: {query}",
tags=["research-manager", "multi-agent", "web-search", "report-generation"]
)
try:
search_plan = await self._plan_searches(query)
search_results = await self._perform_searches(search_plan)
report = await self._write_report(query, search_results)
print("\n\n=====レポート=====\n\n")
print(f"レポート: {report.markdown_report}")
print("\n\n=====フォローアップ質問=====\n\n")
follow_up_questions = "\n".join(report.follow_up_questions)
print(f"フォローアップ質問: {follow_up_questions}")
# 成功時のトレース終了
agentops.end_trace(tracer, end_state="成功")
except Exception as e:
print(f"\nエラーが発生しました: {e}")
# 失敗時のトレース終了
agentops.end_trace(tracer, end_state="失敗")
raise
async def _plan_searches(self, query: str) -> WebSearchPlan:
result = await Runner.run(
planner_agent,
f"クエリ: {query}",
)
return result.final_output_as(WebSearchPlan)
async def _perform_searches(self, search_plan: WebSearchPlan) -> list[str]:
tasks = [asyncio.create_task(self._search(item)) for item in search_plan.searches]
results = []
for task in asyncio.as_completed(tasks):
result = await task
if result is not None:
results.append(result)
return results
async def _search(self, item: WebSearchItem) -> str | None:
input = f"検索語: {item.query}\n検索理由: {item.reason}"
try:
result = await Runner.run(
search_agent,
input,
)
return str(result.final_output)
except Exception:
return None
async def _write_report(self, query: str, search_results: list[str]) -> ReportData:
input = f"元のクエリ: {query}\n要約された検索結果: {search_results}"
result = Runner.run_streamed(
writer_agent,
input,
)
async for _ in result.stream_events():
pass
return result.final_output_as(ReportData)
実行(エントリポイント)
最後に、任意のクエリを入力して ResearchManager を実行します。実行中のすべての LLM 呼び出しやツール実行は agentops により可視化されます。
# レポート生成を実行
query = "AgentOpsについて"
await ResearchManager().run(query)
実行結果
=====レポート=====
レポート: # AgentOps に関する総合レポート
## レポート構成(概要)
1. はじめに — AgentOpsとは何か、位置づけ
2. コア概念とアーキテクチャ概要
3. SDK と実装(Python / TypeScript): インストールと基本操作の例
4. トレーシングとデコレータ設計: 典型的なトレース構造とサンプルコード
5. 主な機能とユースケース(コスト管理、デバッグ、ベンチマーキング、監視)
6. 料金プランと導入モデル(フリー/Pro/Enterprise、セルフホストの考え方)
7. 運用上のベストプラクティス、メトリクス設計、モニタリング項目
8. セキュリティ・コンプライアンス・データ保持の注意点
9. 制約、リスク、他ツールとの比較(DevOps/MLOpsとの関係)
10. 今後の展望と研究/開発上の課題
11. まとめと推奨ステップ
12. 参考情報とリンク
---
## 1. はじめに — AgentOpsとは何か
AgentOpsは、自律的に動作するAIエージェント(複数のLLM呼び出しやツール連携を含むワークフロー)を、開発から本番運用まで包括的に観測・管理・最適化するためのフレームワークおよび商用サービスです。DevOpsやMLOpsの延長線上に位置し、特に「エージェントのライフサイクル運用(Agent lifecycle operations)」に特化した観測性(observability)、コスト管理、デバッグ機能を提供します(参考: IBM/AgentOps解説、docs.agentops.ai)。
主な目的は以下の通りです。
- エージェント実行の階層的トレーシング(セッション→エージェント→ワークフロー→タスク→LLM/ツール呼び出し)
- レイテンシ/コスト/成功率などの可視化によるパフォーマンス管理
- タイムトラベル型のデバッグ、リプレイ解析、ベンチマーク
- アラート/異常検知による運用自動化とSLA達成支援
## 2. コア概念とアーキテクチャ概要
AgentOps SDKはOpenTelemetryに準拠した設計で、観測データをスパン/トレース構造に整理してダッシュボードへ送信します。主要な抽象概念は次のとおりです。
- セッション(session): ユーザあるいは呼び出し単位の最上位コンテキスト。
- エージェント(agent): エージェントロジックやエージェントクラス全体を示すコンテキスト。
- ワークフロー(workflow): 複数タスクを組み合わせた高レベルのプロセス。
- オペレーション/タスク(operation/task): 個々の処理単位(関数、API呼び出しなど)。
- LLM呼び出し(llm call): トークン使用、応答時間、応答のメタデータ、コストなどを記録する特別なスパン。
- ツール(tool): 外部サービスや内部ユーティリティ呼び出しもトレースされる。
アーキテクチャの流れ(概念的):
1. SDKが既存のLLMクライアントやエージェントフレームワーク(LangChain、Autogen、OpenAI Agents SDK等)を自動検出しフックする。
2. 実行中に自動でスパンを生成し、メトリクスとイベントを収集。
3. SDKはこれらをAgentOpsのバックエンド(クラウド)へ送信し、ダッシュボードで可視化・解析できる(Enterpriseではセルフホストも可)。
## 3. SDK と実装: インストールと基本操作(例)
主にPython SDKとTypeScript/JavaScript SDKが提供されています(GitHub: AgentOps-AI/agentops, agentops-ts)。
Pythonの最小導入手順(概略):
1. インストール
pip install agentops python-dotenv
2. 環境変数(.env)にAPIキーなどを設定
3. 初期化
import agentops
agentops.init(api_key="YOUR_API_KEY")
初期化後、対応するLLMクライアントや主要エージェントフレームワークとのやり取りが自動的にトレースされます(自動インストルメンテーション)。
TypeScriptの場合は npm パッケージがあり、同様に
npm install agentops
で始められ、agentops.init() により動作します。
## 4. トレーシングとデコレータ設計(詳細)
より細かいコントロールを行うには、デコレータや明示的な start/end API を用います。代表的なデコレータ例:
- @session: セッション単位の開始/終了を管理
- @agent: エージェントクラスや関数をエージェントコンテキストに紐づける
- @operation / @task: 個々の処理をトレース
- @workflow: ワークフローをまとめる
- @tool: 外部ツール呼び出しの記録
サンプル(Python、簡易):
from agentops import operation, agent, init
init(api_key="...")
@agent()
class MyAgent:
@operation(name="fetch_data")
def fetch(self, url):
# この関数はOperationスパンとして記録される
return requests.get(url)
@operation(name="process")
def process(self, data):
# 引数・戻り値・例外も記録される
pass
明示的なトレース開始終了APIもあり、非同期やジェネレータにも対応します。
## 5. 主な機能とユースケース
代表的な機能:
- 自動インストルメンテーション(主要LLM/フレームワークの自動検出)
- 階層的トレース(セッション→…→LLM呼び出し)
- LLMコスト追跡(トークン数、金額など)
- タイムトラベルデバッグ / リプレイ
- ベンチマーキングツール(エージェント比較)
- カスタムメタデータ/タグ付け、アラート連携
ユースケース:
- プロダクトで複数のエージェントが実行される環境でのコスト最適化
- 本番での不具合再現(リプレイ・タイムトラベル)
- SLA監視とアラート発火
- A/Bテストやエージェント比較(ベンチマーク)
- セキュリティ/コンプライアンス目的での操作ログ取得
## 6. 料金プランと導入モデル
公開情報によれば、AgentOpsはフリー/Pro/Enterpriseの階層を提供しています(外部まとめ情報)。
- Free/Basic: 毎月一定のイベント(1,000〜5,000イベントの記述あり)まで無料。基本的な監視、SDK、コスト追跡等を含む。
- Pro: 月次で定額(多数の情報源で約40ドル/月と報告)で、イベント上限増加(例: 10,000イベント/月)、タイムトラベル、無制限ログ保持(あるプランでは)、カスタムテスト等を提供。
- Enterprise: 個別見積もり。無制限のエージェント数、セルフホスティング、専用インフラ、SLA、SSO、コンプライアンス(SOC‑2/HIPAAなど)対応が可能。
導入モデルとしてはクラウド型が標準ですが、Enterprise向けにセルフホスティング(AWS/GCP/Azure)や専用データ保持ポリシーが提供されます。
## 7. 運用上のベストプラクティス
導入検討/運用時に押さえるべきポイント:
1. メトリクス設計
- 必須: リクエスト/セッション数、LLMトークン数、コスト($)、平均レスポンスタイム、成功率、エラー率
- 推奨: ワークフロー別のレイテンシ、外部ツール呼び出しのSLA、ユーザ影響度指標
2. サンプリングとデータ保持
- 全トレース保管はコストがかかるため、完全保存・サンプリング・重要度ベース保持を組み合わせる。
3. セキュリティとPii管理
- 入力・出力に個人情報が含まれる場合はマスキング/トークン化を徹底する。
4. テスト/ステージング環境の分離
- 本番トラフィックとテストトラフィックを区別して計測/コスト見積もりする。
5. アラート設計
- コスト急増、LLMエラー増、外部サービス遅延に対するしきい値を設定する。
## 8. セキュリティ・コンプライアンス・データ保持
- AgentOpsはEnterprise向けにSOC‑2やHIPAAなどコンプライアンス支援を提供する旨の記述がある(個別契約)。
- 機密データを扱うワークフローでは、クラウド送信前にログマスキングや差分送信を行うか、セルフホスティングを検討する。
- APIキー管理は環境変数/シークレットマネージャーを推奨。SDKの通信暗号化(TLS等)を確認する。
## 9. 制約、リスク、他ツールとの比較
- 依存性: 自動インストルメンテーションは便利だが、フレームワークやバージョンの不整合で想定外の動作が出る可能性がある。運用前にステージングで十分な相互作用テストを行うこと。
- コスト: イベント数・トレース長に応じた課金があるため、サンプリング戦略やログ削減設計が必要。
- ベンダーロックイン: クラウドサービス利用時は長期的なデータ移行や独自解析の必要性を評価する。
比較(概念的):
- DevOps: システム/インフラのCI/CDや監視が中心。AgentOpsは特にLLM/エージェントワークフロー特有の観測性を補完。
- MLOps: モデルの学習・デプロイ・モニタリングを扱う。AgentOpsはランタイムのLLM呼び出し・複雑ワークフローの監視に重心があるため、MLOpsツールと補完関係になる。
## 10. 今後の展望と研究課題
- 自律エージェントの増加に伴い、複雑なワークフローの可視化・原因分析の自動化(RCA自動化)やインテリジェントなコスト最適化アルゴリズムの需要が高まる。
- 学術的には、異常検知や根本原因分析(RCA)のフレームワーク化も進行中で、AgentOpsのような実運用データが研究の基盤になる可能性がある(参考: arXiv論文例)。
- プライバシー保護やオンプレミスでのトレーシング、標準化(OpenTelemetry拡張など)の進展が鍵。
## 11. まとめと推奨ステップ
まとめ:
- AgentOpsは自律エージェント運用の可観測性を強力に支援するツール群であり、短い導入ハードルで有意義な洞察(コスト、レイテンシ、失敗分析)を得られる。
導入推奨ステップ(実務):
1. ステージング環境でSDKをインストールし、自動インストルメンテーションの挙動を確認する。
2. 主要メトリクス(トークン数、コスト、応答時間、エラー率)を定義し、ダッシュボードで可視化する。
3. サンプリング/データ保持ポリシーを決め、個人情報マスキングを実装する。
4. 必要に応じてProのトライアル/Enterprise相談を行い、セルフホスティングやコンプライアンス要件を詰める。
5. 運用運用で得られたデータを基にルールや自動化(コストアラート、フォールバックなど)を設定する。
## 12. 参考情報とリンク
- AgentOps ドキュメント(Quickstart / Core concepts): https://docs.agentops.ai
- GitHub - AgentOps-AI/agentops (Python SDK): https://github.com/AgentOps-AI/agentops
- GitHub - AgentOps-AI/agentops-ts (TypeScript SDK)
- AgentOps 料金概要まとめ(サードパーティ): trendingaitools.com, agentspool.ai
- 解説記事(AgentOpsとAgentOps概念): IBM Think記事, ai.reinforz.co.jp
- 関連研究: arXiv(AgentOps/運用に関する理論検討)
---
もし必要であれば、次の内容を追加で作成できます:
- あなたの既存リポジトリに対する具体的なインストルメンテーション手順(コード差分)
- サンプルログ・ダッシュボード例のモックアップ
- 導入コスト見積もりと保守フロー
=====フォローアップ質問=====
フォローアップ質問: AgentOpsを評価する目的は何ですか?(例: 本番コスト管理、デバッグ強化、SLA監視、研究用途など)
どの言語/フレームワークでの導入を想定していますか?(Python, TypeScript, LangChain, Autogen など)
機密データやコンプライアンス要件(HIPAAやSOC‑2)が関係しますか?セルフホスティングの必要はありますか?
既にエージェント運用をされていますか?もしあれば、1日あたりのセッション数や推定トレースイベント数の規模を教えてください。
実際にサンプルコードの差分やステップバイステップの導入ドキュメントが必要ですか?どのリポジトリ/アーキテクチャを対象にしますか?
ポイントは、既存のコードにわずか 4行追加するだけ で可視化ができる点です。
-
agentops.init()- 初期化 -
agentops.start_trace()- トレース開始 -
agentops.end_trace("成功")- 成功時の終了 -
agentops.end_trace("失敗")- 失敗時の終了
この4行を加えるだけで、次に紹介する詳細なダッシュボードが自動的に生成されます。
4.4 ダッシュボード分析
先ほどのコードを実行すると、agentops のダッシュボード上でエージェントの動作が自動的に可視化されます。ここでは、どのような情報が確認できるかを紹介します。
セッション一覧
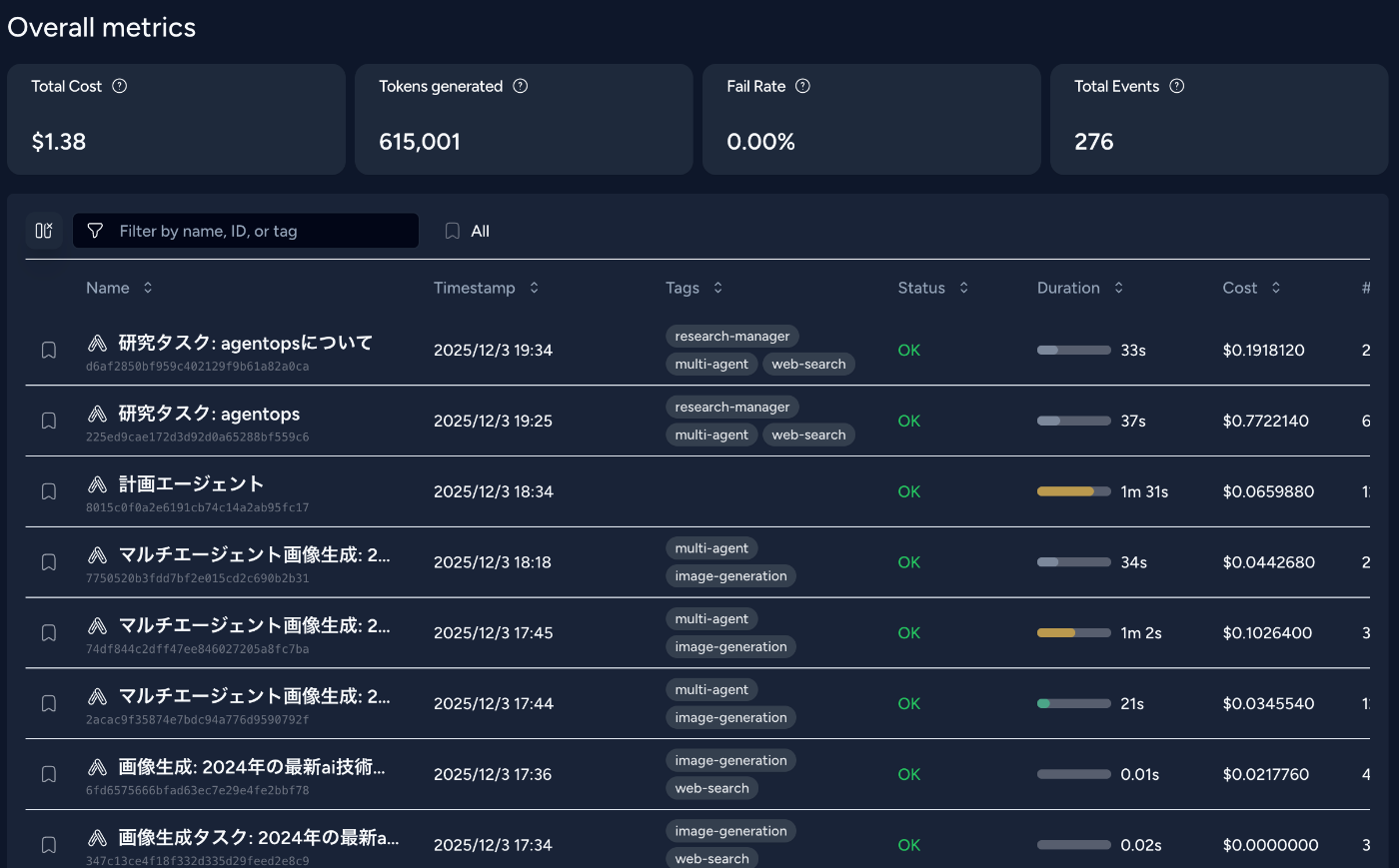
最初に表示されるのがセッション一覧です。各セッションの成功/失敗が一目でわかり、問題のあるセッションをすぐに特定できます。
コストとパフォーマンス

各セッションに関しても、実行時間、トークン使用量、API コストなどがリアルタイムに可視化され、パフォーマンスとコストの把握が容易になります。
実行フローの可視化

WaterFall View

Tree View
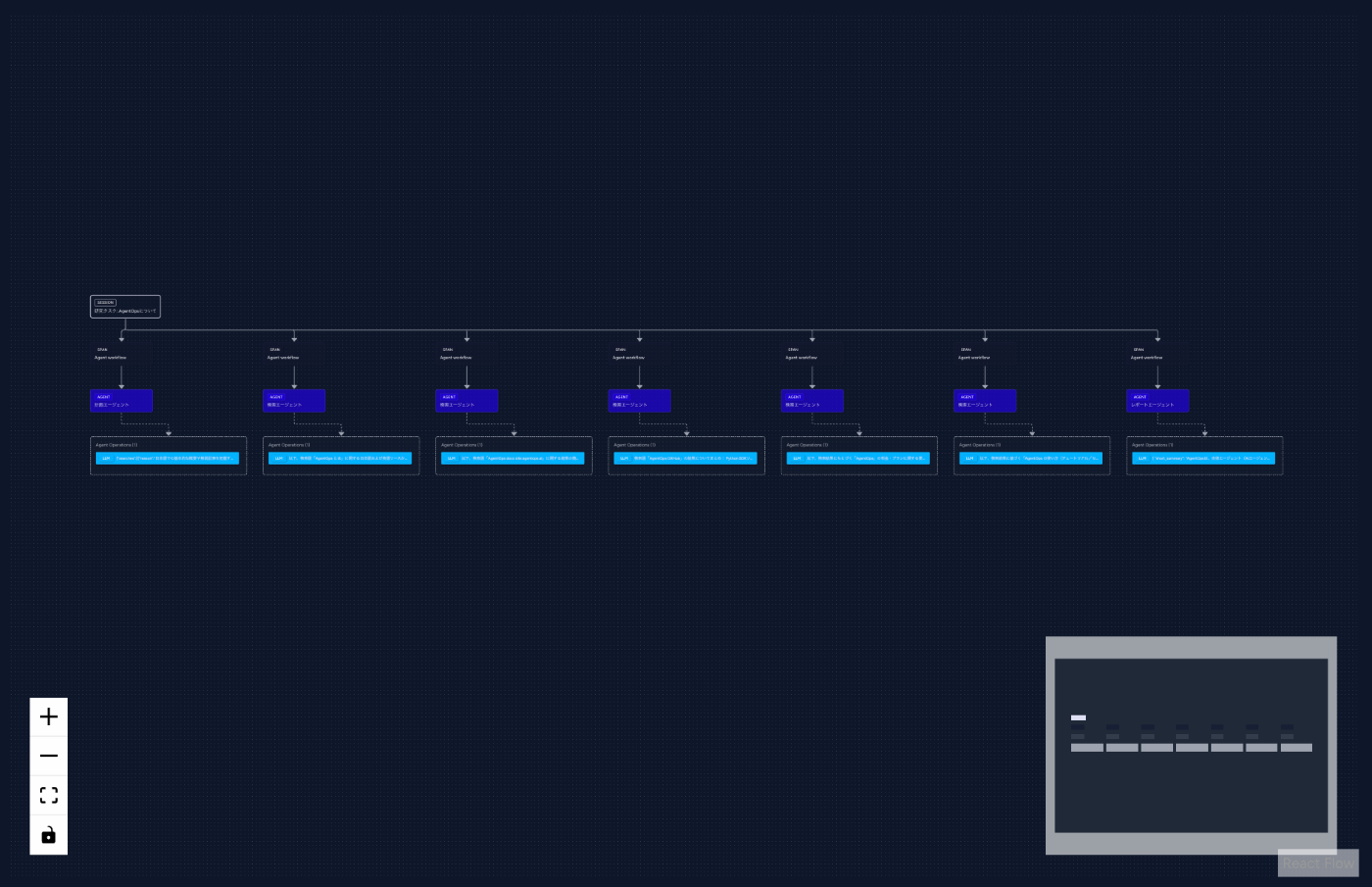
Graph View
エージェントがどの順序で処理を進めたかを複数のビューで確認できます。処理の遅延箇所やボトルネックも直感的に把握できます。
詳細ログ
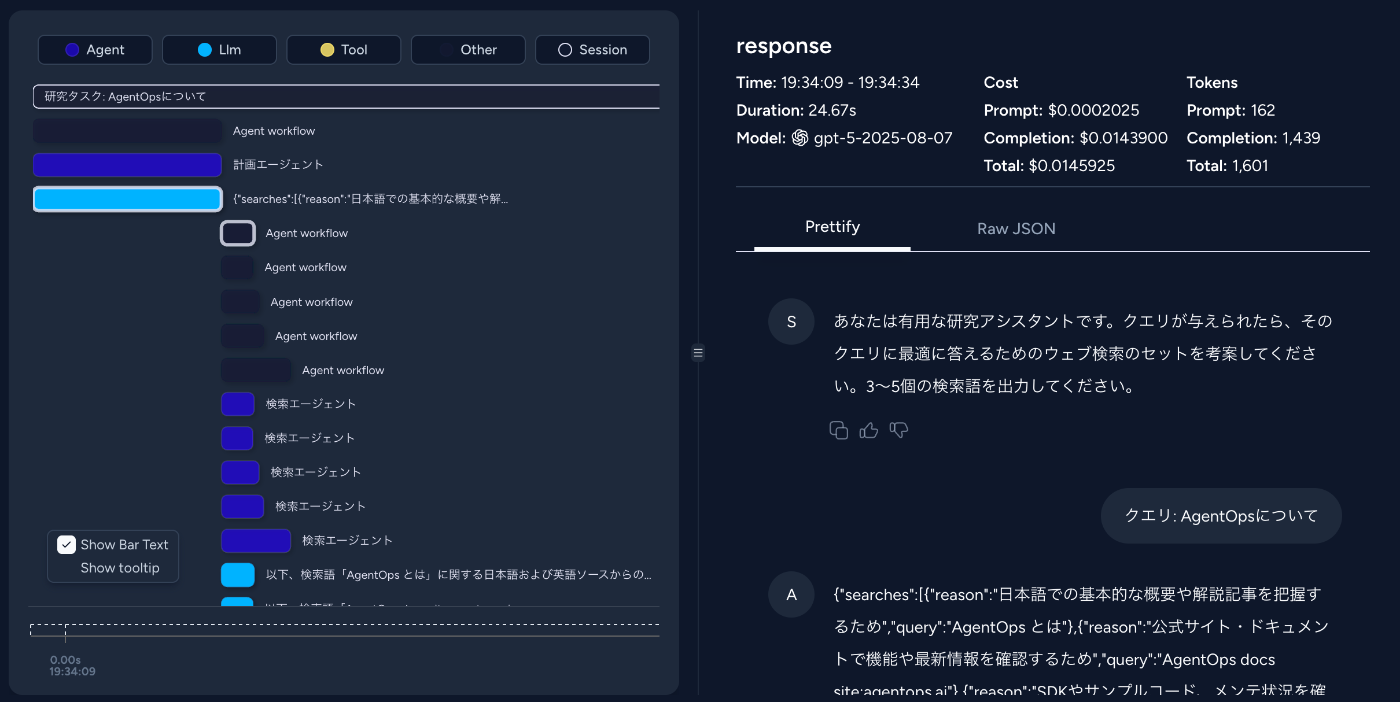
各ステップの入力・出力が完全に記録されており、「なぜこの結果になったのか」を容易に追跡できます。
統計ダッシュボード
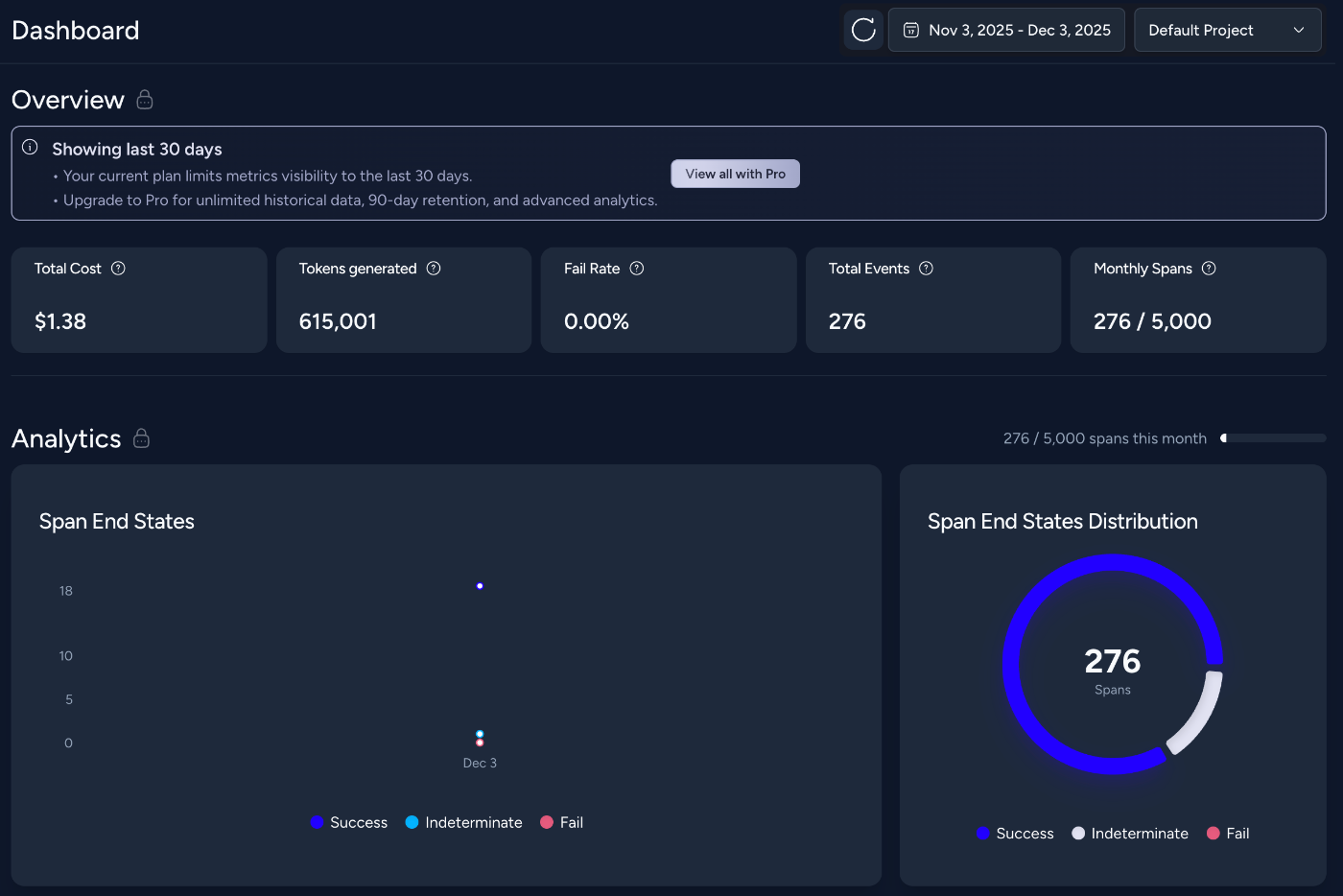
時間帯別の利用状況、エラー率の推移、累積コストなど運用に必要な統計がまとめられ、システム全体の健康状態を継続的に把握できます。
5. おわりに
本記事では AgentOps の概要と、実際にエージェントへ組み込む方法を紹介しました。agentops のようなモニタリングツールは他にも存在し、利用するフレームワークによって標準機能として提供されている場合もあります。重要なのは、エージェントの目的やシステム構成に応じて適切な仕組みを選ぶことです。また、本記事で触れた内容にとどまらず、評価、ガードレール、CI/CD、可観測性などの仕組みを総合的に整備することが、エージェントの安定運用には欠かせません。
エージェントを本番運用する予定がある場合、早い段階から観測基盤を構築しておくことで、後のデバッグや品質改善、コスト最適化が大幅に容易になるのでおすすめです。これから私自身も、今後より実践的な My AgentOps 基盤を整えていきたいと考えています!
最後までお読みいただき、ありがとうございました。

Discussion